Claude Opus 4.6 is Anthropic’s newest “smartest” Claude model, and it’s not a cosmetic refresh. It’s a pragmatic upgrade aimed at the work that usually breaks large language models: long-horizon coding, messy knowledge work, and tool-driven workflows that need to stay coherent for more than a few minutes.
Anthropic’s own launch post, Introducing Claude Opus 4.6, is unusually specific about where the model improved: deeper planning, longer agentic task endurance, stronger code review/debugging, and most importantly for real production workflows: a 1M token context window (beta) for the Opus tier.
This article breaks down what Claude Opus 4.6 is, what changed, what the benchmark claims do and do not imply, and how to evaluate it with a sober checklist instead of vibes.
Quick facts (for scanning)
| Item | What Anthropic says |
|---|---|
| Model name | Claude Opus 4.6 |
| API model ID | claude-opus-4-6 per Claude Opus 4.6 announcement |
| Context window | 1M tokens (beta) for Opus-class for the first time, via Introducing Claude Opus 4.6 |
| Output limit | Up to 128k output tokens, per the “Product and API updates” section in Introducing Claude Opus 4.6 |
| Pricing | “Pricing remains the same at $5/$25 per million tokens,” with premium pricing beyond 200k tokens, per Claude API pricing page and the launch post |
| Notable product features | Agent teams, context compaction, adaptive thinking, effort controls, Excel upgrades, PowerPoint preview—all described in Introducing Claude Opus 4.6 |
| Safety documentation | Anthropic references an “extensive system card,” available as Claude Opus 4.6 system card |
Table of contents
-
The headline change: 1M-token context, without the fairy tale
-
Agentic work: “long-horizon” isn’t a slogan, it’s a failure mode
-
Coding upgrades: what “better at code” should mean in practice
-
Benchmarks and claims: how to read them without self-deception
-
Tooling and control knobs: effort, adaptive thinking, compaction
What Claude Opus 4.6 is (and who it’s for)
Claude Opus 4.6 is positioned as Anthropic’s top-tier Claude model, intended for tasks where you pay for reliability: complex coding, multi-step research, document-heavy workflows, and “agentic” tasks where the model must keep a plan in its head while using tools.
The launch post is blunt about the focus. Opus 4.6 “plans more carefully, sustains agentic tasks for longer, can operate more reliably in larger codebases, and has better code review and debugging skills,” as stated in Introducing Claude Opus 4.6. That list reads like a bug report from people who tried to use models as junior engineers and got burned.
If your workloads look like any of the following, Opus 4.6 is aimed at you:
-
You have a real codebase, not a toy repo.
-
Your tasks exceed a single prompt-response exchange.
-
You need tool use (search, code execution, structured outputs, file manipulation).
-
You have large internal documents and want the model to cite and connect them, not summarize them into mush.
If you only need short copywriting or quick Q&A, Opus 4.6 may be overkill. Anthropic even notes the model can “think more deeply,” which can add latency and cost on simple tasks, and suggests lowering effort if it’s overthinking—see the “First impressions” section of Introducing Claude Opus 4.6.
The headline change: 1M-token context, without the fairy tale
A 1M token context window is a big number. It’s also easy to misunderstand.
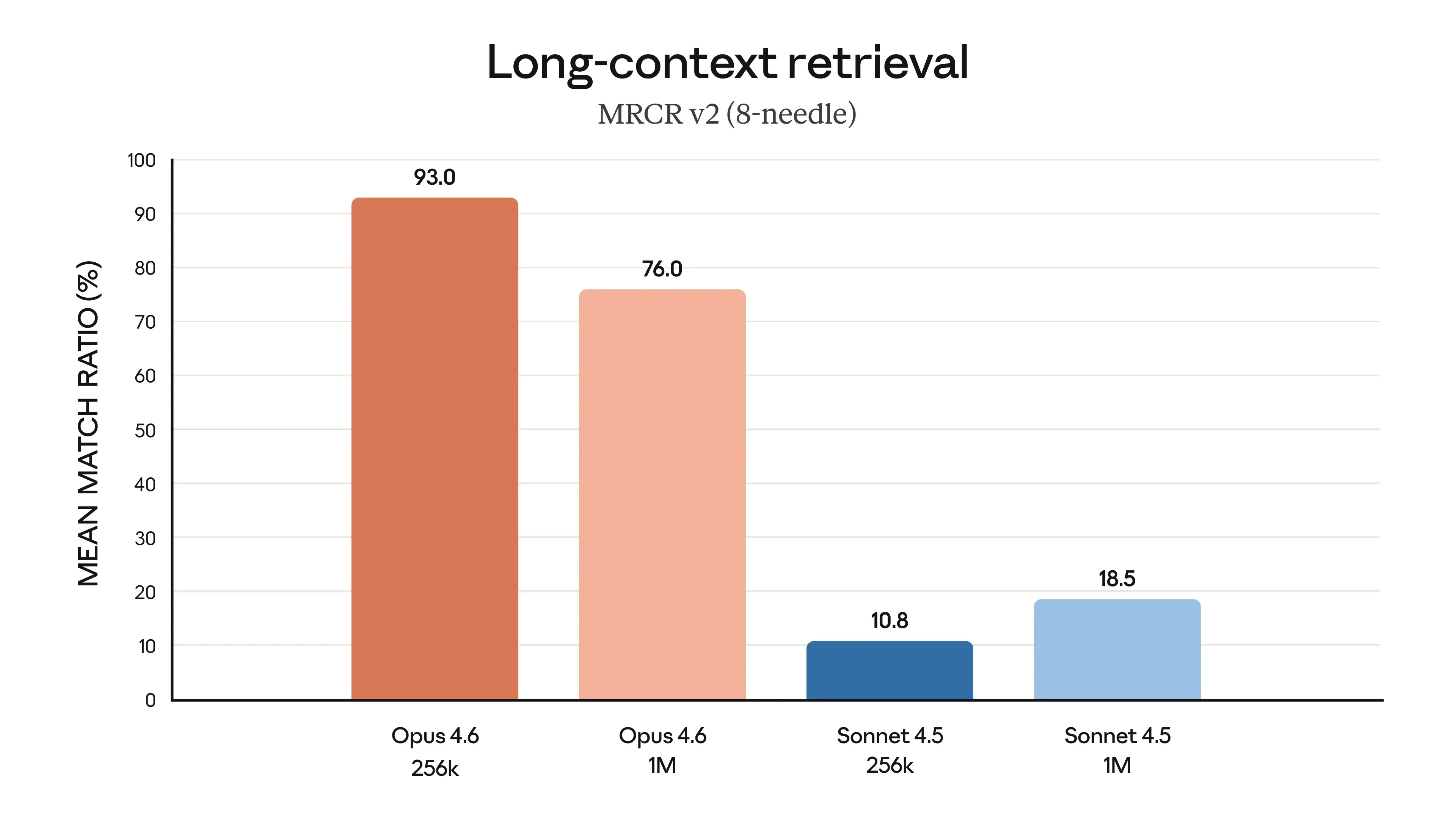
What 1M tokens enables
At a minimum, 1M tokens changes what’s feasible in a single run:
-
Large codebases can be loaded with more of their dependency surface intact.
-
Long technical docs can be included without aggressive truncation.
-
Multi-document workflows become less about “what did we drop?” and more about “what did we actually decide?”
Anthropic frames 1M tokens as a first for Opus-class models, “in beta,” in Introducing Claude Opus 4.6.
What 1M tokens does not guarantee
Long context is not the same as long attention. Models can still:
-
Miss details that are present but not salient.
-
Drift in assumptions over time.
-
“Remember” something incorrectly even when it’s in the input.
Anthropic directly addresses a related phenomenon—performance degrading as context grows—often called “context rot.” Their engineering write-up Effective context engineering for AI agents is worth reading because it’s about practice, not marketing.
If you want a clean way to pressure-test long-context retrieval, Anthropic cites MRCR v2 needle-in-a-haystack style evaluation and links to the underlying dataset at MRCR v2 on Hugging Face. The existence of a benchmark doesn’t make your use-case solved, but it helps you design tests that resemble reality.
The real question: can it stay consistent?
For most teams, the win is not “I can paste a million tokens.” The win is “I can keep a complex task alive without collapsing it into a lossy summary every 15 minutes.”
That’s why the 1M window is paired with context compaction, which Anthropic describes as a way for Claude to summarize and replace older context as the conversation approaches a threshold. The official docs are Context compaction. It’s not glamorous, but it is the kind of plumbing that separates demos from systems.
Agentic work: “long-horizon” isn’t a slogan, it’s a failure mode
When people say they want an “agent,” they usually mean: “I want the model to carry intent across steps, use tools safely, recover from errors, and not forget what it’s doing.”
Opus 4.6 is explicitly tuned for this, including:
-
“Sustains agentic tasks for longer,” per Introducing Claude Opus 4.6
-
Agent teams in Claude Code, documented at Agent teams
-
Compaction and control knobs on the API: Context compaction, Adaptive thinking, and Effort
What matters here is not whether the model can “act autonomously.” It’s whether it can:
-
State a plan you can audit.
-
Execute the plan with bounded tool use.
-
Detect when it’s off the rails.
-
Backtrack without rewriting history.
If your current model fails by confidently doing the wrong thing for 20 steps, this is the category of improvement you should be measuring.
Coding upgrades: what “better at code” should mean in practice
Anthropic claims Opus 4.6 is better at:
-
Operating “more reliably in larger codebases”
-
“Better code review and debugging”
-
“Plans more carefully”
Those are not abstract traits. They map to a few concrete developer pains.
1) Codebase navigation without hallucinated architecture
A strong coding model should be able to:
-
Identify where a feature logically belongs.
-
Respect existing patterns and conventions.
-
Avoid “new folder syndrome” where it invents structure because it can’t find the real one.
Opus 4.6 is designed for “larger codebases,” and the 1M context window is meant to support that, per Introducing Claude Opus 4.6. But you should still require evidence: file paths, symbol references, and explicit diffs.
2) Debugging that looks like debugging
Good debugging is hypothesis-driven. It’s not just a better guess.
If you test Opus 4.6, don’t ask it to “fix the bug.” Ask it to:
-
Reproduce the bug from logs.
-
Propose 2–3 plausible root causes.
-
Rank them with reasoning.
-
Make the smallest change that can falsify the top hypothesis.
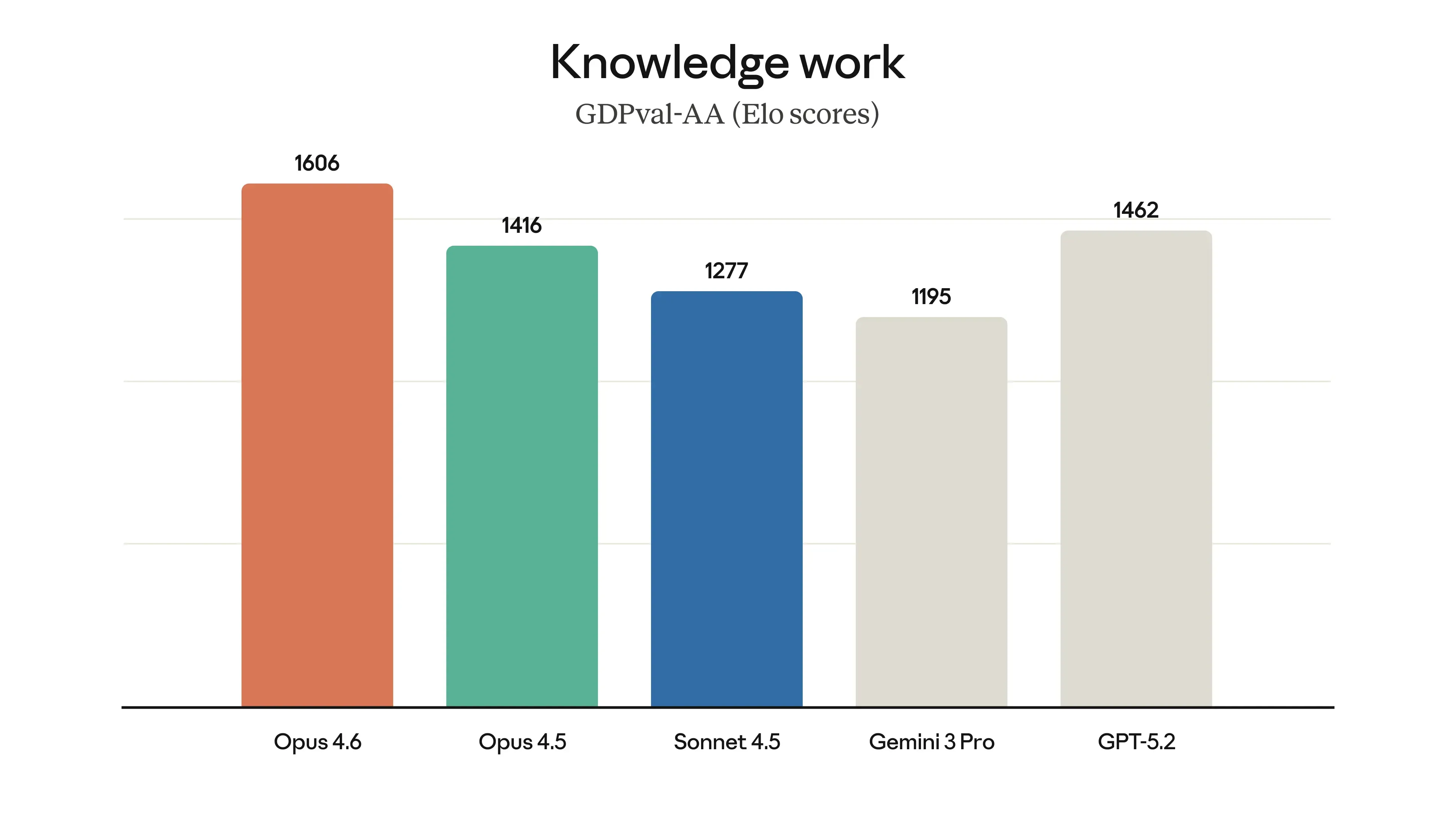
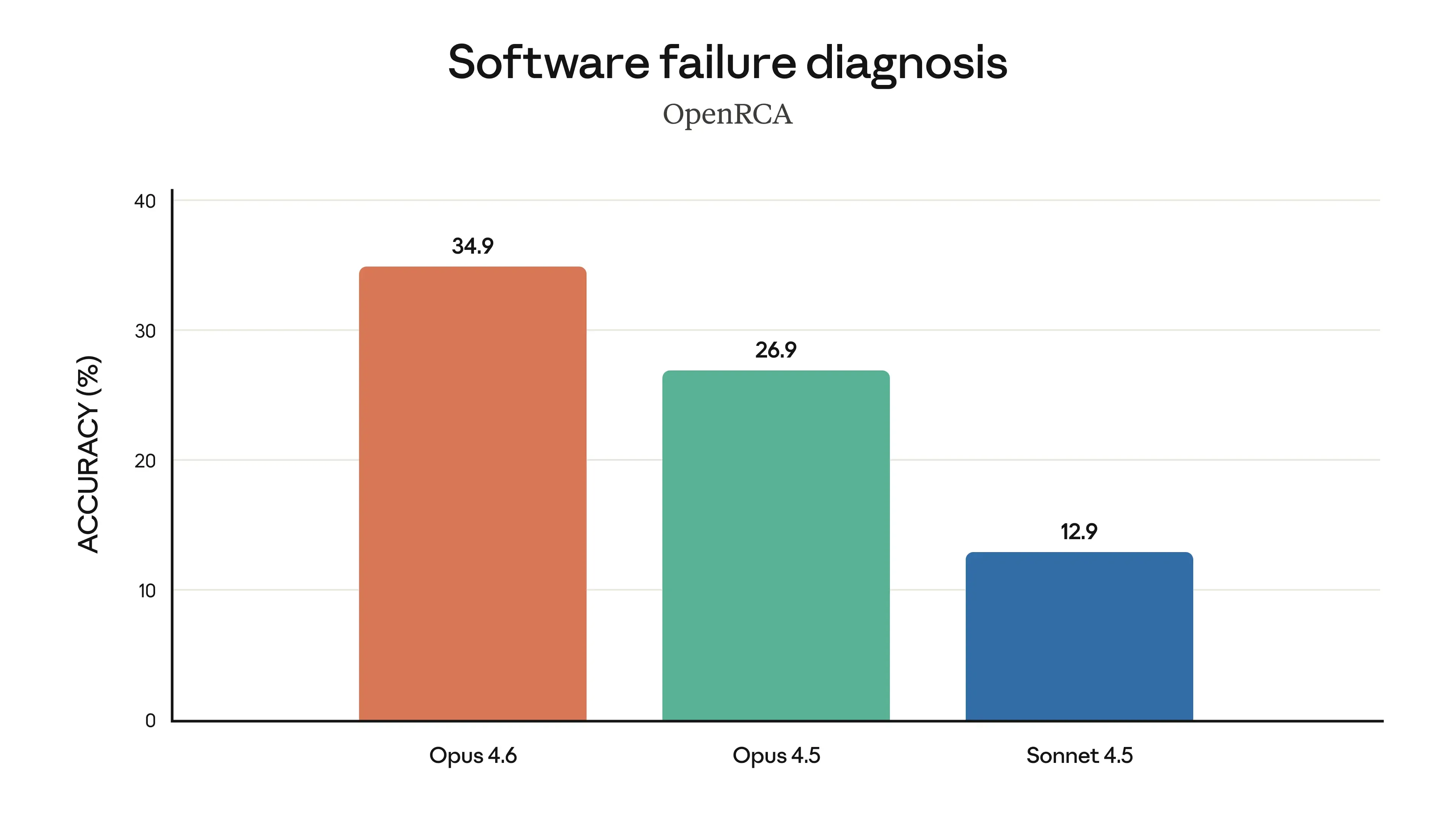
Anthropic highlights “root cause analysis” improvements and shows charts in the launch post, but the most responsible place to ground safety and evaluation context is the Claude Opus 4.6 system card.
3) Code review that catches mistakes, including its own
A model claiming better “code review” should:
-
Flag insecure defaults.
-
Notice race conditions and error-handling gaps.
-
Identify performance footguns.
-
Catch missing tests and mismatched assumptions.
This is where “sharp” matters: you want a model that says “this is wrong” and explains why, not one that politely rewrites your code into a different mistake.
Benchmarks and claims: how to read them without self-deception
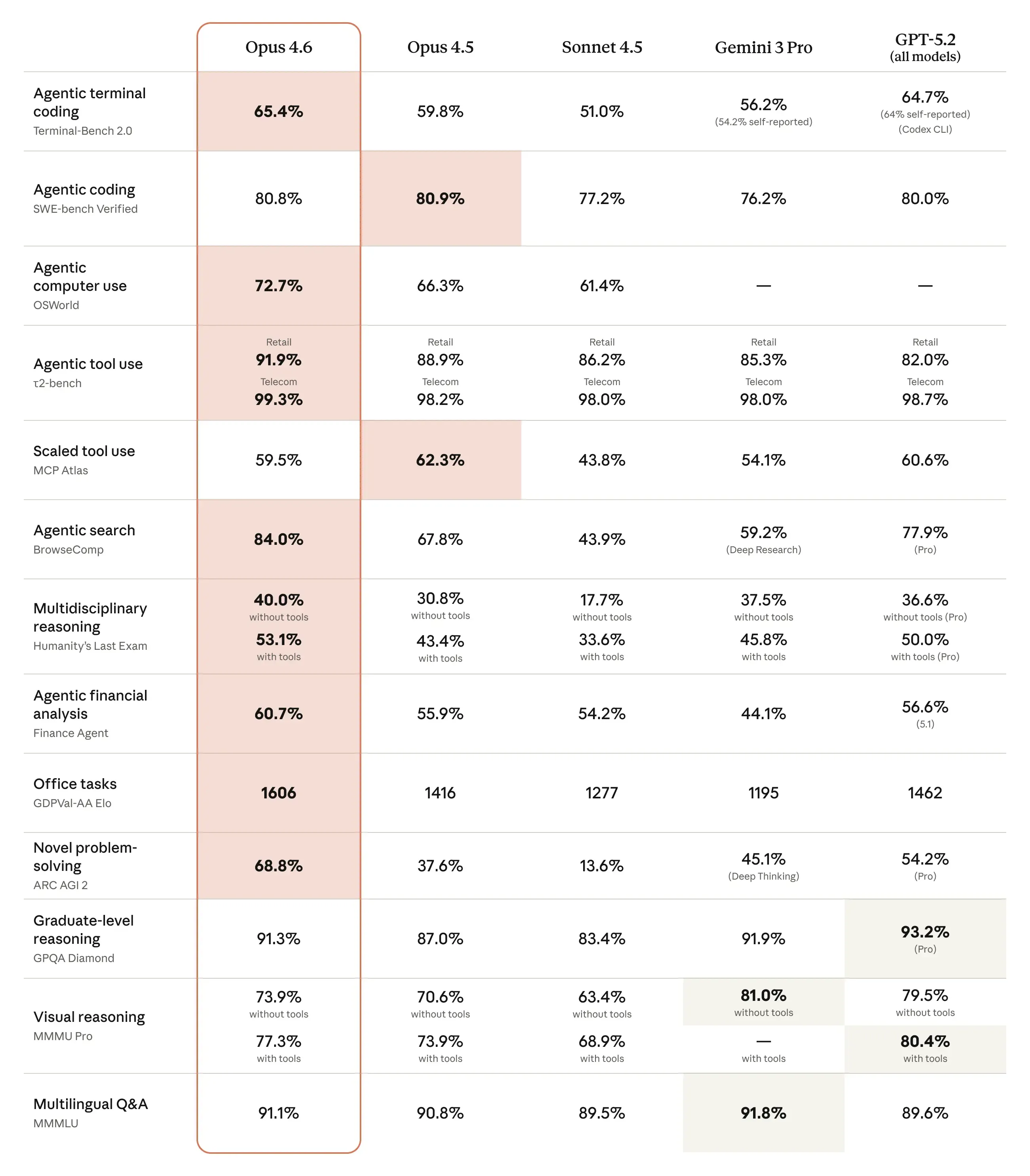
Anthropic’s announcement lists several evaluations where Opus 4.6 is described as state-of-the-art, including:
-
Terminal-Bench 2.0, linked as Terminal-Bench 2.0
-
Humanity’s Last Exam, linked as Humanity’s Last Exam
-
GDPval-AA by Artificial Analysis, linked as GDPval-AA evaluation and methodology details at Artificial Analysis methodology
-
BrowseComp, linked as BrowseComp
This is unusually helpful because it gives you direct references instead of vague “we lead on benchmarks” claims.
A sane way to interpret these results
Benchmarks can be useful if you treat them as:
-
A way to predict relative strengths
-
A tool to design your own internal evals
-
A signal about tooling (web search, tool calling, constraints) rather than raw IQ
They are not proof your workflow will succeed.
Anthropic’s own footnotes in the launch post are a quiet admission of how sensitive benchmark outcomes are to harness choices, tool access, and settings. If you read the “Footnotes” section in Introducing Claude Opus 4.6, you’ll see details about “with tools,” compaction triggers, and reasoning effort. That is exactly the kind of context you need before you map benchmark scores to your product.
The part most people skip: the harness is the product
If Opus 4.6 beats other models on an agentic benchmark when run “with tools,” the practical takeaway is not “the model is smarter.” The takeaway is: “the model plus a good harness can search, retrieve, and execute reliably.”
That’s actionable. It tells you to invest in:
-
Tool APIs
-
Guardrails
-
Eval harnesses
-
Logging and replay
-
Versioned prompts
Without those, you’re just buying a larger engine and driving it without brakes.
Tooling and control knobs: effort, adaptive thinking, compaction
Anthropic’s Opus 4.6 release is as much about control surfaces as it is about raw capability. Three features matter if you’re building real systems.
Effort controls
Anthropic introduced effort levels (“low, medium, high, max”) so developers can trade cost/latency for deeper reasoning, documented at Effort.
This is important for one reason: it acknowledges that “more thinking” is not always better. For many production endpoints, you want consistent, bounded behavior—not an essay.
Adaptive thinking
Previously, you might have had to choose between enabling or disabling extended thinking. Now Anthropic describes “adaptive thinking,” where Claude decides when deeper reasoning is useful, documented at Adaptive thinking.
If you’ve ever watched a model waste tokens on an easy question, you understand why this exists.
Context compaction
Long-running tasks die on context limits. Compaction tries to keep them alive by summarizing older context at a threshold, documented at Context compaction.
You should treat compaction summaries as a potential source of silent error. The fix is not to avoid compaction; it’s to require:
-
A “decisions log” the model must maintain explicitly
-
A “facts we are assuming” section
-
Periodic checks where the model must cite the exact source text (or exact file path / line range) for key claims
Excel and PowerPoint: why this matters more than it sounds
It’s easy to dismiss “Claude in Excel” and “Claude in PowerPoint” as office-feature fluff. That’s a mistake.
Most enterprise work is not code. It’s spreadsheets, decks, docs, and the friction between them.
Anthropic says Opus 4.6 can “use and create documents, spreadsheets, and presentations,” and highlights upgrades to these products in Introducing Claude Opus 4.6. The product pages are:
Here’s what’s strategically interesting:
-
A model that can read layouts, fonts, and slide masters can preserve a house style, which is the difference between “draft” and “usable.”
-
A model that can plan multi-step changes in a spreadsheet can do real analysis, not just produce formulas.
In other words: this is about reducing the number of handoffs, not adding a novelty feature.
Safety: what you can trust, and what you still must verify
Anthropic claims Opus 4.6’s “overall safety profile” is as good as or better than other frontier models, and points to the system card in Introducing Claude Opus 4.6. The primary source is the Claude Opus 4.6 system card.
Two practical notes for teams:
-
A system card is documentation, not a warranty. It tells you what was tested and how, not what your users will do.
-
As models get better at cybersecurity tasks, the risk surface expands. Anthropic explicitly mentions new “cybersecurity probes” and defensive work, and links to a cybersecurity post at Zero days (Anthropic security blog).
If you’re deploying Opus 4.6 in a product, “safety” should include:
-
Prompt injection resistance if you use web fetch/search
-
Data boundary enforcement if you use internal docs
-
Tool permissioning and rate limits
-
Human-in-the-loop for high-impact actions
How to evaluate Opus 4.6 for your team (a hard checklist)
If you want an honest answer to “should we adopt this model,” don’t start with benchmark charts. Start with your failure cases.
Step 1: Define three workflows that currently hurt
Pick workflows that have:
-
Multiple steps
-
Multiple documents
-
A need for correctness, not just fluency
Examples:
-
“Triage a bug from logs, identify root cause, propose fix, write tests.”
-
“Read a 30-page spec, find inconsistencies, produce an implementation plan with risks.”
-
“Generate a board-ready deck from a spreadsheet model while keeping brand formatting.”
Step 2: Turn each workflow into an eval with scoring
Score these dimensions:
-
Correctness (ground truth)
-
Traceability (can it cite sources / file paths?)
-
Robustness (does it recover from tool errors?)
-
Cost/latency (does it stay within budget?)
-
Edit distance (how much human cleanup is required?)
Step 3: Force the model to show its work in artifacts
Don’t accept “it seems right.” Require outputs like:
-
A change list with file paths and reasons
-
A test plan with coverage justification
-
A “risks and unknowns” section
-
A final summary that cites sources (documents, URLs, repo locations)
Step 4: Stress test context length, not just capability
If you plan to use 1M tokens, simulate it. Insert:
-
Conflicting requirements
-
Duplicate definitions
-
Old assumptions that should be superseded
Then see whether the model:
-
Detects conflict
-
Requests clarification
-
Updates the decision log
This is where long-context claims become real.
Practical prompts and workflows that test the right things
Below are patterns that tend to separate “a smart chat model” from “a usable work model.” Use them as scaffolding when testing Opus 4.6.
The “plan-first, then execute” structure
Ask for:
-
A plan with explicit steps and acceptance criteria
-
A list of required tools
-
A stop condition (“If X is missing, ask me”)
This aligns with Anthropic’s emphasis on planning and long-horizon work in Introducing Claude Opus 4.6.
The “two-pass review” structure
Have Opus 4.6 produce a draft, then force a second pass:
-
“List the top 10 ways this could be wrong.”
-
“Which assumptions would break this?”
-
“What would you test first?”
Models that improved on “code review and debugging” should benefit here.
The “compaction resilience” test
If you use compaction, you want the model to survive summarization without losing critical constraints. Use the official mechanism described in Context compaction, then ask the model to restate:
-
Requirements
-
Decisions made
-
Open questions
-
Non-goals
Any drift here is a red flag.
Common pitfalls (and how to avoid them)
Pitfall 1: Treating 1M context as a license to stop curating inputs
More context can mean more noise. A model can still drown.
Fix:
-
Pre-chunk docs into sections with headings
-
Provide an index
-
Require citations for claims
Pitfall 2: Overpaying for thinking
Anthropic explicitly warns Opus 4.6 may “overthink” some tasks and suggests lowering effort, per Introducing Claude Opus 4.6.
Fix:
-
Use Effort controls to match task difficulty
-
Default low/medium for routine operations
-
Reserve high/max for tasks with real ambiguity or high cost of error
Pitfall 3: Confusing “tool use” with “reliability”
A model can call tools and still make bad decisions.
Fix:
-
Add guardrails on tool calls
-
Log every call and response
-
Add replayable traces
-
Implement “approve before act” on destructive operations
BrowseComp is a good reminder that tool-augmented retrieval is a different skill class, and the benchmark overview at BrowseComp helps frame what’s being tested.
Pitfall 4: Shipping benchmark claims instead of user outcomes
“Highest score” is not a KPI.
Fix:
-
Measure human time saved
-
Measure error rates
-
Measure how often users accept output without edits
-
Track regressions across model versions
If you want a more independent angle on “economically valuable knowledge work” evaluation, Anthropic points to GDPval-AA with methodology at Artificial Analysis methodology. Use it as context, not as gospel.
Conclusion
Claude Opus 4.6 is a serious release because it targets the ugly parts of real work: long context, long tasks, tool-driven execution, and codebases that punish guessing. The 1M-token window (beta) is the obvious headline, but the quieter story is the control and workflow infrastructure—effort settings, adaptive thinking, compaction, and agent teams—that makes longer tasks survivable.
If you evaluate it with discipline—failure cases, artifacts, traceability—you’ll quickly learn whether Opus 4.6 is a genuine upgrade for your workflows or just a larger model doing the same old tricks with more words.
You can already use Claude Opus 4.6 in Atoms.
