Meta description: Claude Opus 4.6 and GPT-5.3-Codex just shipped. This deep technical guide compares their specs, long-context behavior, agent workflows, and published evaluation results—then gives a practical decision framework.
1) Two releases, one real shift: models that execute work, not just answer questions
Most “model comparisons” are noise: vague claims, cherry-picked demos, and conclusions that don’t survive a single week in production.
These two launches are different for one reason: both vendors are explicitly pushing toward long-running, tool-using workflows—models that can plan, operate across many steps, and stay coherent while you supervise.
OpenAI describes GPT-5.3-Codex as Codex expanding “across the full spectrum of professional work on a computer,” and emphasizes that you can steer it while it is working without losing context in the middle of execution, per their own release post titled Introducing GPT-5.3-Codex on the official OpenAI product announcement.
Anthropic frames Opus 4.6 as an upgrade to its smartest model with better planning, longer sustained work, and stronger performance across several evaluations, as stated on the official Introducing Claude Opus 4.6 announcement.
If you build software, the important question is not “Which model is smarter?” It’s this:
Can the model take a real task from “unclear” to “done,” while producing artifacts you can verify?
That is the bar. Everything else is decoration.
2) GPT-5.3-Codex: what OpenAI claims, and what it means in practice
OpenAI’s statement is direct: GPT-5.3-Codex is “the most capable agentic coding model to date,” it merges frontier coding performance from GPT-5.2-Codex with reasoning/professional knowledge capabilities associated with GPT-5.2, and it is “also 25% faster,” enabling longer-running work that involves research, tool use, and complex execution, as described in Introducing GPT-5.3-Codex.
Two technical implications follow from that positioning.
First: OpenAI is optimizing the “loop,” not just the response
If the model is built for tool use and long-running execution, the critical path becomes:
-
fewer clarifying turns to get started,
-
fewer wasted steps mid-run,
-
and fewer failures that require a human reset.
A model that is slightly better at writing functions but worse at maintaining state across a multi-hour debugging session will lose in real work. OpenAI’s own emphasis on interactivity and steering mid-task is a tell: the vendor believes supervision and control are now as important as raw generation.
Second: GPT-5.3-Codex is being evaluated as an operator
OpenAI states GPT-5.3-Codex performs strongly on benchmarks measuring coding, terminal competence, computer use, and knowledge work (they name SWE-Bench Pro, Terminal-Bench, OSWorld, and GDPval), per Introducing GPT-5.3-Codex.
Whether those benchmarks match your workload is another matter. But the evaluation target is clear: the model is supposed to handle end-to-end workflows, not isolated snippets.
OpenAI also repeats a striking internal claim: GPT-5.3-Codex was “instrumental in creating itself,” used to debug training, manage deployment, and diagnose evaluations. That claim appears both in OpenAI’s own announcement and in mainstream reporting like NBC News. You don’t have to take the narrative literally to extract the useful point: OpenAI is asserting that early versions were trusted on real engineering operations, not just toy examples.
3) Claude Opus 4.6: what Anthropic claims, and what changed in the API
Anthropic’s Opus 4.6 announcement is unusually dense with details. They claim the model:
-
improves coding skills,
-
plans more carefully,
-
sustains long agent-style tasks,
-
operates more reliably in larger codebases,
-
and improves code review/debugging to catch its own mistakes, as stated in Introducing Claude Opus 4.6.
The headline technical differentiator Anthropic emphasizes is long context: Opus 4.6 features a 1M token context window in beta (first time for Opus-class models), also stated in Introducing Claude Opus 4.6.
Anthropic also provides concrete API-level updates:
-
“adaptive thinking,” where the model decides when deeper reasoning is needed,
-
“effort” controls (low/medium/high/max),
-
“context compaction” (server-side summarization to extend long sessions),
-
and expanded output length support, which are described in both their announcement and the official documentation page What’s new in Claude 4.6.
That matters for production. You can’t adopt a long-running model without:
-
a cost/performance control surface,
-
predictable behavior at different thinking depths,
-
and a plan for sessions that run long.
Anthropic is explicitly productizing those constraints.
4) Spec sheet comparison: context, output length, controls, availability
Here is what is explicitly stated in vendor materials.
Comparative Benchmark Performance: Claude Opus 4.6 vs. GPT-5.3 Codex (As of Feb 5, 2026).
Claude Opus 4.6 (as published by Anthropic)
-
API model id:
claude-opus-4-6, per What’s new in Claude 4.6 -
Context: 200K standard, 1M context in beta, per What’s new in Claude 4.6 and Introducing Claude Opus 4.6
-
Max output: up to 128K tokens, per What’s new in Claude 4.6
-
Controls: adaptive thinking + effort levels + compaction, per What’s new in Claude 4.6
-
Availability: claude.ai, API, and “all major cloud platforms,” per Introducing Claude Opus 4.6
GPT-5.3-Codex (as published by OpenAI)
-
Speed: “25% faster,” per Introducing GPT-5.3-Codex
-
Availability: paid ChatGPT plans, across Codex app, CLI, IDE extension, web; API access “soon,” per Introducing GPT-5.3-Codex
-
Workflow: steer mid-task, frequent updates, interactive supervision, per Introducing GPT-5.3-Codex
OpenAI’s post is rich in evaluation results and workflow framing, but it is lighter on explicit token-window specs in the release text shown above. Don’t fill that gap with guesses. In a technical comparison, “unknown” is better than “probably.”
5) Published evaluation data: what we actually know (and what we don’t)
If you want data, you need to be strict about provenance.
GPT-5.3-Codex: OpenAI’s published benchmark numbers
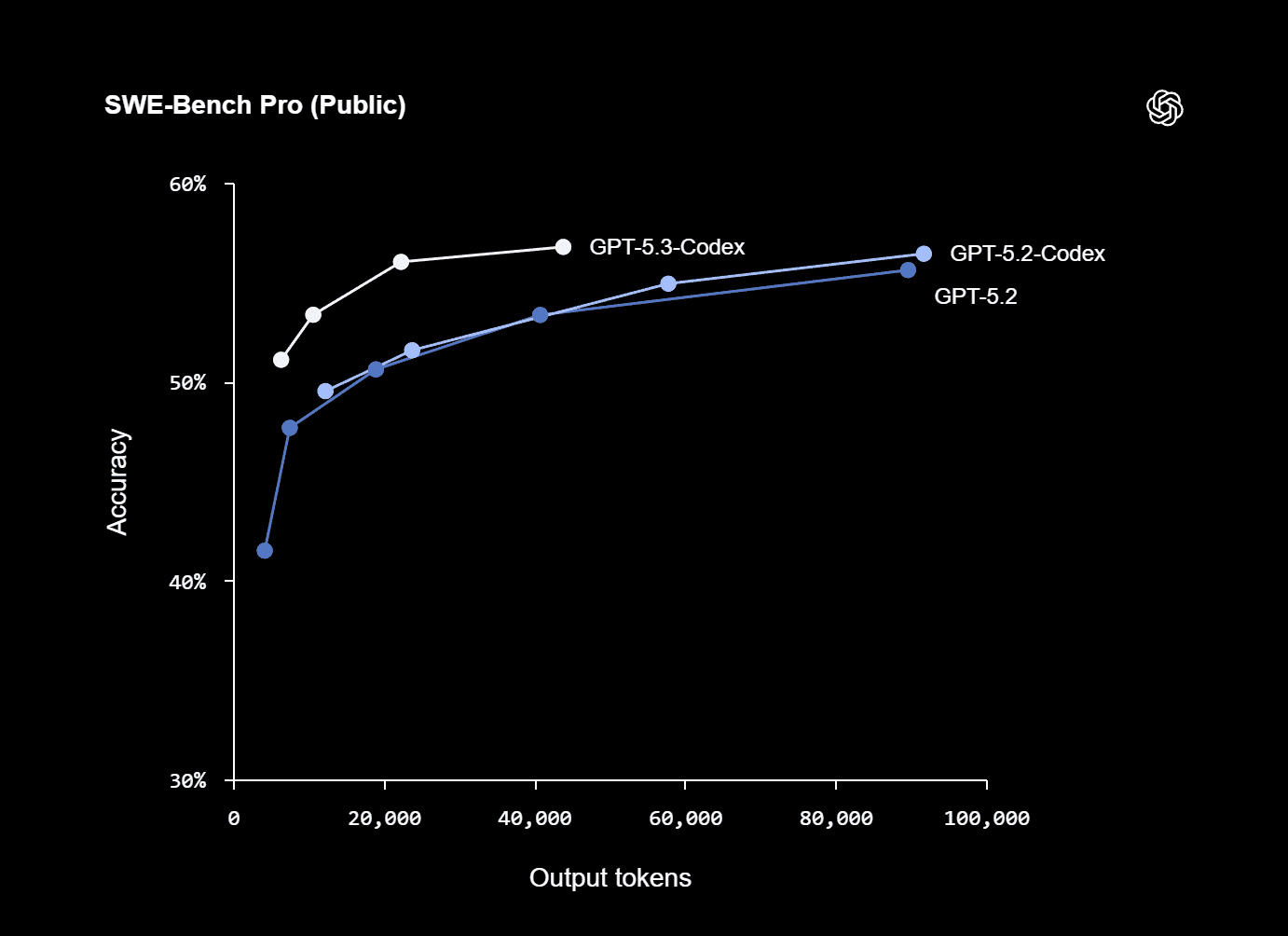
OpenAI includes an appendix table with specific results (run with “xhigh reasoning effort”), per Introducing GPT-5.3-Codex. Selected figures:
-
SWE-Bench Pro (Public): 56.8% (GPT-5.3-Codex) vs 56.4% (GPT-5.2-Codex)
-
Terminal-Bench 2.0: 77.3% (GPT-5.3-Codex) vs 64.0% (GPT-5.2-Codex)
-
OSWorld-Verified: 64.7% (GPT-5.3-Codex) vs 38.2% (GPT-5.2-Codex)
-
Cybersecurity CTF challenges: 77.6% (GPT-5.3-Codex) vs 67.4% (GPT-5.2-Codex)
Those jumps are not subtle. The OSWorld-Verified delta in particular suggests OpenAI sees “computer-use competence” as a core capability, not a side quest.
But be careful: one vendor’s benchmark framing can overfit the narrative they want to sell. Your job is to run your own harness.
Claude Opus 4.6: Anthropic’s published evaluation claims and figures
Anthropic asserts Opus 4.6 is state-of-the-art on several evaluations. They provide some concrete numbers and comparative statements in Introducing Claude Opus 4.6:
-
They claim Opus 4.6 achieves the highest score on Terminal-Bench 2.0 (no number provided in the excerpt above, but the directional claim is explicit).
-
They claim it leads frontier models on Humanity’s Last Exam (again, directional claim).
-
On GDPval-AA, they claim Opus 4.6 outperforms the “next-best model” (they identify OpenAI’s GPT-5.2) by around 144 Elo points, and they add an interpretation: that maps to a higher score about 70% of the time.
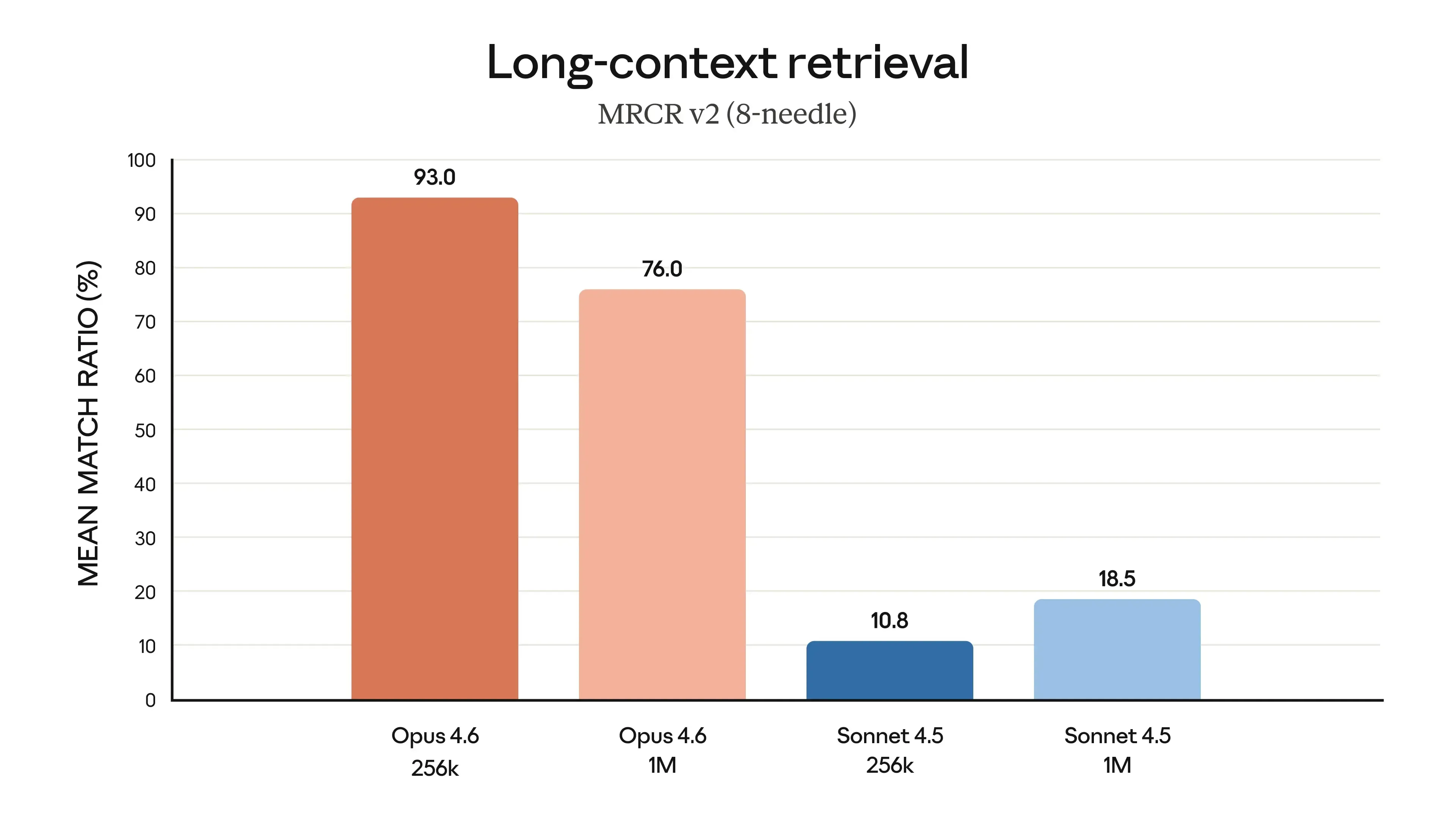
-
On MRCR v2 (8-needle 1M variant), they report Opus 4.6 scoring 76%, versus Sonnet 4.5 at 18.5%.
Anthropic also points readers to methodology for GDPval-AA via a note referencing “Artificial Analysis” in their footnotes, as shown in the same announcement page Introducing Claude Opus 4.6. That matters: third-party methodology references are a credibility signal, even if you still need to inspect the details.
The honest conclusion on data
From vendor-published materials alone:
-
OpenAI publishes a clear table for GPT-5.3-Codex across several named benchmarks, with numbers.
-
Anthropic publishes several strong comparative claims for Opus 4.6 and includes specific figures for long-context retrieval and Elo differences on GDPval-AA, but not a single unified table in the excerpted text above.
Neither replaces a real-world evaluation. Both are still useful.
6) Long context that still works: retrieval, “context rot,” and why it matters
Large context windows are easy to advertise and hard to use well.
The core issue is not “Can the model accept 1M tokens?” The issue is:
Can it reliably find the right 30 lines out of 30,000, then reason correctly over them, without drifting?
Anthropic directly attacks this with both product and data.
-
Product: Opus 4.6 supports 200K context (1M in beta) and includes context compaction, per What’s new in Claude 4.6.
-
Data: Anthropic reports a major MRCR v2 retrieval gain (76% for Opus 4.6 on the 8-needle 1M variant), per Introducing Claude Opus 4.6.
This is not academic. If you do any of the following, retrieval quality becomes a first-order constraint:
-
large monorepo migrations,
-
legacy system debugging,
-
compliance-heavy change review,
-
or multi-document research where citations and provenance matter.
OpenAI’s GPT-5.3-Codex announcement emphasizes tool use and computer-use capability (OSWorld-Verified) and claims strong performance on professional knowledge work (GDPval), per Introducing GPT-5.3-Codex. That suggests a different emphasis: less “massive context window as the hero,” more “execute and operate across tools to get what you need.”
In practice, that can be a real trade:
-
One approach: stuff the world into context and retrieve precisely.
-
Another approach: use tools to fetch, search, and narrow the world, then act.
Neither is universally better. The right choice depends on your environment and constraints.
7) Agent workflows: steering vs teams, compaction, effort controls
Agent workflows fail in predictable ways:
-
They overrun cost.
-
They overrun time.
-
They drift off-task.
-
They “complete” the task without producing verifiable artifacts.
Both vendors are shipping controls designed to prevent that.
OpenAI: interactive steering while the model works
OpenAI frames GPT-5.3-Codex as “an interactive collaborator,” with frequent updates and the ability to steer mid-task without losing context, per Introducing GPT-5.3-Codex.
That matters when you care about:
-
human-in-the-loop control,
-
mid-course corrections,
-
and staying aligned with intent rather than just delivering a final blob of output.
It’s a workflow bet: fewer “submit prompt, pray, and review,” more “drive the process as it runs.”
Anthropic: controllable thinking depth, and explicit long-session mechanics
Anthropic’s API surface is unusually explicit about control:
-
thinking: {type: "adaptive"}is recommended; older “enabled + budget_tokens” is deprecated, per What’s new in Claude 4.6. -
The effort parameter is GA with levels including
max, per What’s new in Claude 4.6. -
Compaction is server-side summarization for long-running work, per What’s new in Claude 4.6.
Anthropic also highlights “agent teams” in Claude Code (multiple agents working in parallel), per Introducing Claude Opus 4.6. Parallelism is not a toy feature; it is a way to reduce wall-clock time on tasks that split cleanly (for example: one agent maps the codebase, another writes tests, a third audits dependencies).
The key technical difference in philosophy
-
OpenAI’s emphasis reads like: “the model can operate across a computer and you supervise it live.”
-
Anthropic’s emphasis reads like: “the model can think and run longer, and you control cost/effort/context mechanics explicitly.”
They are compatible philosophies. But if you are choosing tooling, you are choosing which failure modes you want to spend your time on.
8) Coding reality: debugging, code review, and large codebases
Most coding comparisons are trapped in a narrow test: can the model write a correct function from a clean prompt?
That’s not software engineering. Software engineering is:
-
reading someone else’s code,
-
isolating a bug with incomplete repro steps,
-
changing behavior without breaking invariants,
-
and proving you didn’t break anything.
Both vendors explicitly claim improvements in these areas.
OpenAI claims GPT-5.3-Codex supports the full lifecycle: debugging, deploying, monitoring, writing PRDs, user research, tests, metrics, and more, per Introducing GPT-5.3-Codex.
Anthropic claims Opus 4.6 plans more carefully, sustains agentic tasks longer, operates more reliably in larger codebases, and has better code review and debugging skills to catch its own mistakes, per Introducing Claude Opus 4.6.
Here’s how to translate those claims into practical evaluation tasks that will tell you something real:
-
Give each model a failing test with a stack trace and a medium-sized repo context, then require: “identify root cause, propose minimal fix, add regression test.”
-
Give each model an underspecified feature request, then require: “list assumptions, propose spec, implement only after confirmation.”
-
Give each model a performance regression report, then require: “suggest instrumentation changes, not just code changes.”
You are testing the model’s ability to behave like an engineer under constraints, not a code generator.
9) Security posture: capabilities are rising, so the operating model must too
Both releases include security framing. That is not optional. More capable coding agents increase both defensive and offensive potential.
OpenAI says GPT-5.3-Codex is the first model they classify as “High capability” for cybersecurity-related tasks under their Preparedness Framework, and the first they’ve directly trained to identify software vulnerabilities, as stated in Introducing GPT-5.3-Codex. The same release describes mitigations like monitoring and trusted access for advanced capabilities.
Anthropic claims Opus 4.6 shows a strong safety profile and mentions new cybersecurity probes and safeguards tied to enhanced cybersecurity abilities, plus references their system card in Introducing Claude Opus 4.6.
If you are implementing either model in an organization, treat “security” as an integration requirement:
-
Don’t paste secrets into prompts.
-
Use scoped credentials for tool calls.
-
Separate environments for untrusted code execution.
-
Log agent actions and require review for high-impact changes.
This is basic hygiene, and it becomes non-negotiable as models become better at multi-step execution.
10) Head-to-head: where Opus 4.6 tends to win, where GPT-5.3-Codex tends to win
A clean comparison needs to avoid fan arguments and anchor itself in what the vendors have actually published.
Claude Opus 4.6: likely strengths (based on published specs and claims)
-
Long-context workflows with retrieval demands
Anthropic’s explicit 1M context beta and the MRCR v2 retrieval figure (76% on the 8-needle 1M variant) in Introducing Claude Opus 4.6 are direct signals: they want Opus 4.6 to remain stable as context grows. -
Developer control knobs you can operationalize
Adaptive thinking, effort levels (includingmax), and compaction described in What’s new in Claude 4.6 are practical tools for balancing latency, cost, and accuracy. -
API availability as a first-class channel
Anthropic states Opus 4.6 is available on their API today, per Introducing Claude Opus 4.6. If your product depends on programmatic integration, this matters.
GPT-5.3-Codex: likely strengths (based on published data and framing)
-
Computer-use competence and terminal competence (as measured in their table)
OpenAI’s published deltas on OSWorld-Verified and Terminal-Bench 2.0 in Introducing GPT-5.3-Codex suggest strong performance in “operate and execute” style tasks. -
Interactive supervision as a workflow primitive
OpenAI’s emphasis on steering while the model works and frequent progress updates, per Introducing GPT-5.3-Codex, is aimed at reducing agent drift and improving outcomes in longer tasks. -
Speed as a practical advantage in iterative loops
OpenAI states the model is 25% faster, per Introducing GPT-5.3-Codex. Faster loops mean more verification cycles, which often matters more than raw generation quality.
The real PK: which failure mode do you want to manage?
-
If your work is dominated by massive context, document-heavy tasks, and stable retrieval across long sessions, Opus 4.6’s published focus is hard to ignore.
-
If your work is dominated by tool-using execution, terminal work, and interactive supervision loops, GPT-5.3-Codex’s published benchmark deltas and workflow framing are hard to ignore.
Both can be true. The “winner” depends on what you measure.
11) How to choose: a decision framework you can defend
Make the choice like an engineer, not like a spectator.
Step 1: Write down your top 10 tasks
Not categories—tasks. Examples:
-
“Upgrade dependency X across 12 services and keep CI green.”
-
“Diagnose intermittent production error from logs and traces.”
-
“Generate a migration plan and the actual PRs.”
-
“Rewrite a brittle test suite so it fails for the right reasons.”
Step 2: Define success criteria
If success cannot be tested, it cannot be compared. Require artifacts:
-
diffs,
-
tests,
-
commands run,
-
outputs observed,
-
assumptions listed.
Step 3: Run both models on the same harness
Use the vendor claims to pick what to stress:
-
For Opus 4.6: long-context retrieval, long sessions, compaction behavior, effort tuning.
-
For GPT-5.3-Codex: terminal workflows, multi-step execution, interactive steering, time-to-fix.
Step 4: Score what actually costs you time
Do not score “how impressive it sounded.” Score:
-
time-to-first-correct,
-
regressions introduced,
-
reviewer time,
-
and number of times a human had to reset the process.
If you do that, you won’t need a debate. The results will be boring and decisive.
12) Closing note
Claude Opus 4.6 and GPT-5.3-Codex are both serious releases, and their published materials show different technical priorities: long-context retrieval and explicit control surfaces on the Claude side, and strong computer-use/terminal benchmarks plus interactive supervision loops on the Codex side.
You can use both models in Atoms.
