Meta description: A practical, non-hyped look at Claude Opus agentic workflows, the MetaGPT open-source multi-agent framework, and how Atoms uses multi-agent collaboration to turn ideas into real products.
If you’ve been following AI products lately, you’ve probably seen the word “agent” attached to everything: coding agents, research agents, growth agents, and “AI employees.” Most of those systems are not agents in any useful technical sense. They’re a chat model wrapped in a UI, plus a handful of tools, and the rest is improvisation.
The shift that matters is not branding. It’s architecture: agentic workflows that can plan, call tools reliably, run for long horizons, and verify progress against something external (tests, data, a deployed app). Anthropic has been unusually explicit about this in their own framing of agentic systems, especially around Claude Opus 4.6 and agent teams (see Introducing Claude Opus 4.6 and Building effective agents).
On the other side, MetaGPT is one of the clearest “workflow-first” multi-agent systems: it hardcodes the boring parts—roles, handoffs, and structured outputs—so the model isn’t forced to invent process every time (see the MetaGPT paper and the MetaGPT GitHub repository). And now you can see a straight product line from framework → productized team → business builder in Atoms, which positions itself as a multi-agent system that ships full-stack apps, not just snippets.
This post is a blunt guide to what’s real in “agentic workflows,” what Claude Opus brings to the table, why MetaGPT’s SOP-driven approach still matters, and how Atoms packages the whole thing into something a non-specialist can actually use.
What you’ll learn
-
What “agentic workflow” means when you strip away marketing
-
Why Claude Opus 4.6 is tuned for long-horizon, tool-using work
-
Why multi-agent systems fail (most of the time) without process
-
What MetaGPT gets right: SOPs, roles, structured handoffs
-
How Atoms applies multi-agent collaboration to build and launch products
1) Agentic workflows: definition, not vibes
Anthropic makes a distinction that’s more useful than most: workflows vs agents. In their terms, workflows are orchestrated by predefined code paths; agents dynamically direct their own tool use and process (see Building effective agents). That’s a clean baseline.
To make it concrete:
-
A workflow is closer to a pipeline: step A → step B → step C. You can still call tools, but you know the path.
-
An agent is closer to a controller loop: observe → decide → act → observe → repeat, with changing plans.
What people call “agentic workflows” in practice usually sit between those extremes. The system is partly scripted (for reliability) and partly model-directed (for flexibility). The real question is not “Is it an agent?” but:
Does it have the four properties that make it productive?
-
Planning that survives contact with reality
A system that can break down a task and then revise its plan after tool results come back. -
Tool calling that is boringly reliable
Not “it can call a tool once,” but “it can call tools 30–200 times without derailing.” -
A verification surface
Tests, compilers, database constraints, web requests, lint rules, eval rubrics—anything that is not the model’s own self-confidence. -
Context hygiene
Long-horizon work is mostly about not drowning in your own logs. Anthropic calls out context limits and introduces compaction for longer-running agents (see Introducing Claude Opus 4.6).
If your system doesn’t have these, you don’t have an agentic workflow. You have a chat demo with extra steps.
2) What Claude Opus 4.6 changes for agentic workflows
Anthropic’s release notes for Opus 4.6 are unusually specific about why it matters for agentic work: better coding, more careful planning, longer sustained tasks, better behavior in larger codebases, and stronger review/debugging to catch mistakes (see Introducing Claude Opus 4.6).
A few points in that release are directly relevant if you care about workflows rather than one-off answers:
2.1 Longer horizon is a product feature, not a model “talent”
Opus 4.6 introduces or highlights several mechanisms meant to keep agents running longer without collapsing:
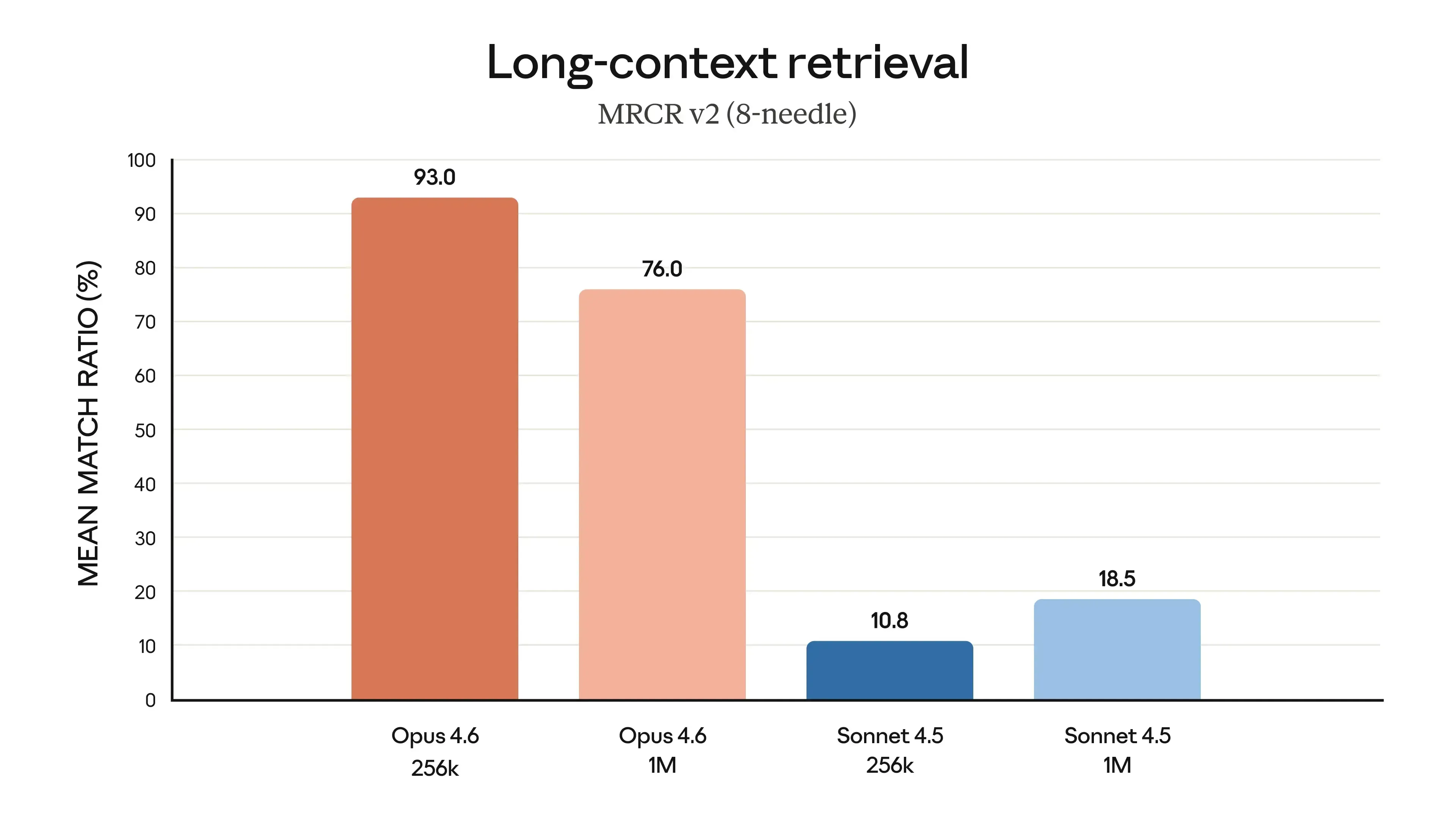
-
1M token context window (beta) (first for Opus-class in beta), which changes what “read the codebase” can mean in real projects (see Introducing Claude Opus 4.6).
-
Context compaction (beta): the model summarizes and replaces older context near a threshold, so long-running tasks don’t just end when the window fills (same source).
-
Effort controls and adaptive thinking: knobs to trade off cost/latency vs depth of reasoning (same source).
These aren’t cosmetic. Without them, agentic systems hit the same wall: they either stop and ask you what to do next, or they continue but lose the thread (“context rot,” as Anthropic describes elsewhere; the Opus 4.6 post links to their context engineering work).
2.2 Agent teams: parallelism is not optional at scale
Anthropic also talks about agent teams in Claude Code: multiple agents working in parallel on a shared codebase (see Introducing Claude Opus 4.6). And they published a detailed engineering write-up where they used agent teams to build a C compiler (see Building a C compiler with a team of parallel Claudes).
Two lessons from that compiler story are worth stealing even if you never build compilers:
-
The harness matters as much as the model. They describe looping execution, task locking, frequent merges, and the need for high-quality tests. The system’s reliability comes from the environment you build around the model, not “prompt magic.”
-
Parallel work amplifies both speed and coordination problems. You get specialization and throughput, but you also get collisions: agents overwrite each other, chase the same bug, and create merge conflicts. You need a synchronization mechanism (they used a simple “lock file per task” approach).
In other words: Opus 4.6 improves the model, but the key enabler for “agentic workflows” is still the scaffolding—tests, tool interfaces, progress tracking, and guardrails.
3) Why “agentic workflows” fail in the real world
Before we talk about MetaGPT and Atoms, it’s worth being explicit about failure modes, because they show why SOP-driven multi-agent systems exist at all.
3.1 The hallucination cascade problem is structural
The MetaGPT paper calls out a problem that every multi-step agent system hits: logic inconsistencies and cascading hallucinations when you naively chain LLM calls (see MetaGPT paper). It’s not just that the model can hallucinate; it’s that downstream steps treat upstream hallucinations as ground truth, and now the system is wrong with confidence and momentum.
Single-agent systems suffer too, but multi-agent systems make it easier to turn one mistake into a coordinated failure: one agent invents a constraint, another agent implements around it, and a third agent “documents” it as a design decision.
3.2 Tool use does not fix reasoning; it adds new ways to be wrong
Tool calling is a double-edged sword:
-
A web fetch tool can give you facts, or it can give you irrelevant pages that the model overfits to.
-
A code execution tool can validate an output, or it can validate the wrong test.
-
A database tool can enforce constraints, or it can cause the model to “work around” constraints by changing schema semantics.
This is why Anthropic emphasizes using ground truth and tests inside an agent loop (see Building effective agents) and why their compiler project stresses high-quality tests (see Building a C compiler with a team of parallel Claudes).
3.3 Multi-agent communication is often the biggest source of entropy
If agents communicate in free-form chat, you get:
-
drifting scope
-
repeated decisions
-
contradictions (“we decided X” / “we decided Y”)
-
bloated context that kills long-horizon performance
The fix is not “more intelligence.” The fix is structure.
That’s exactly what MetaGPT tries to enforce.
4) MetaGPT: SOPs as a control system for multi-agent work
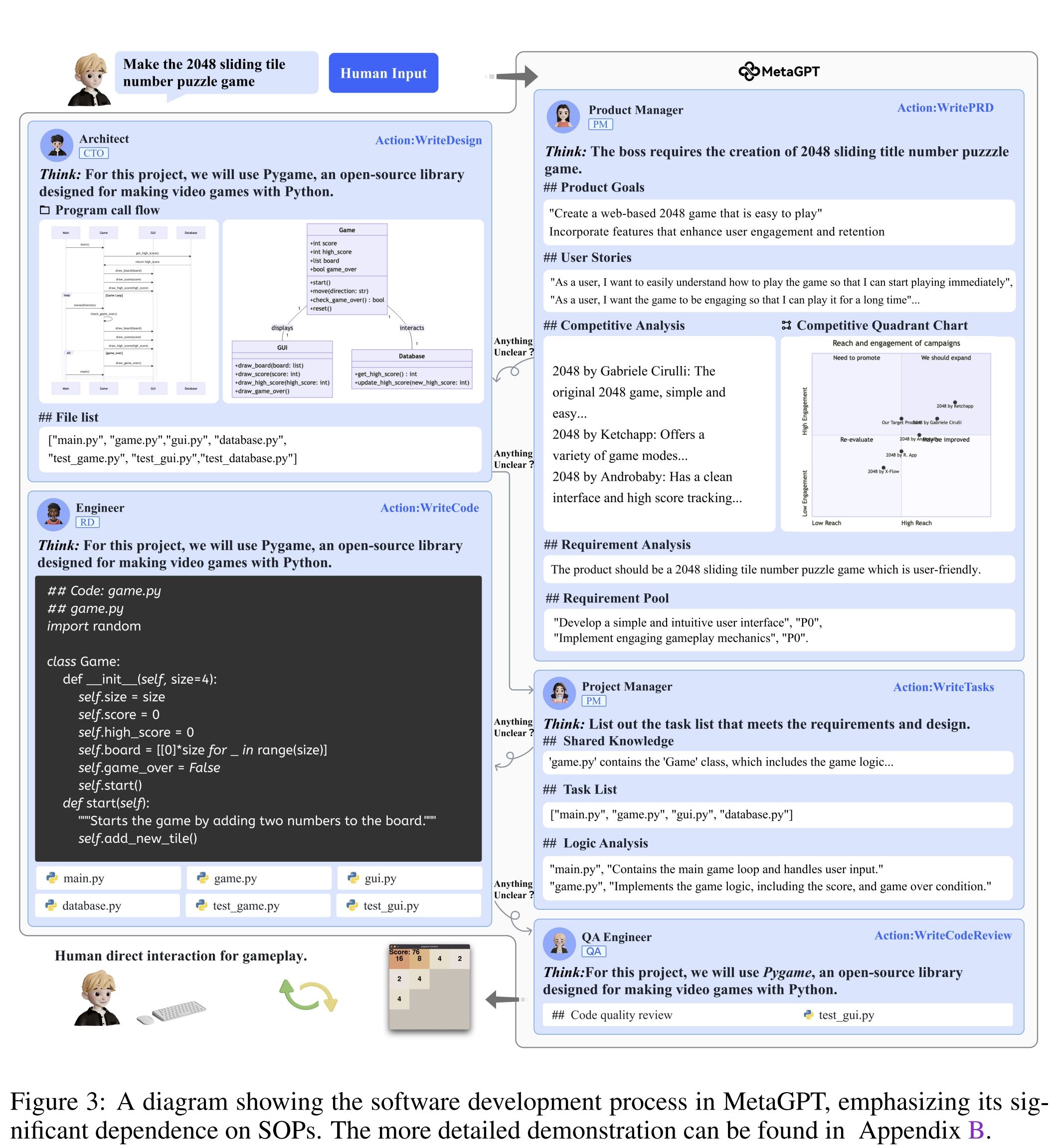
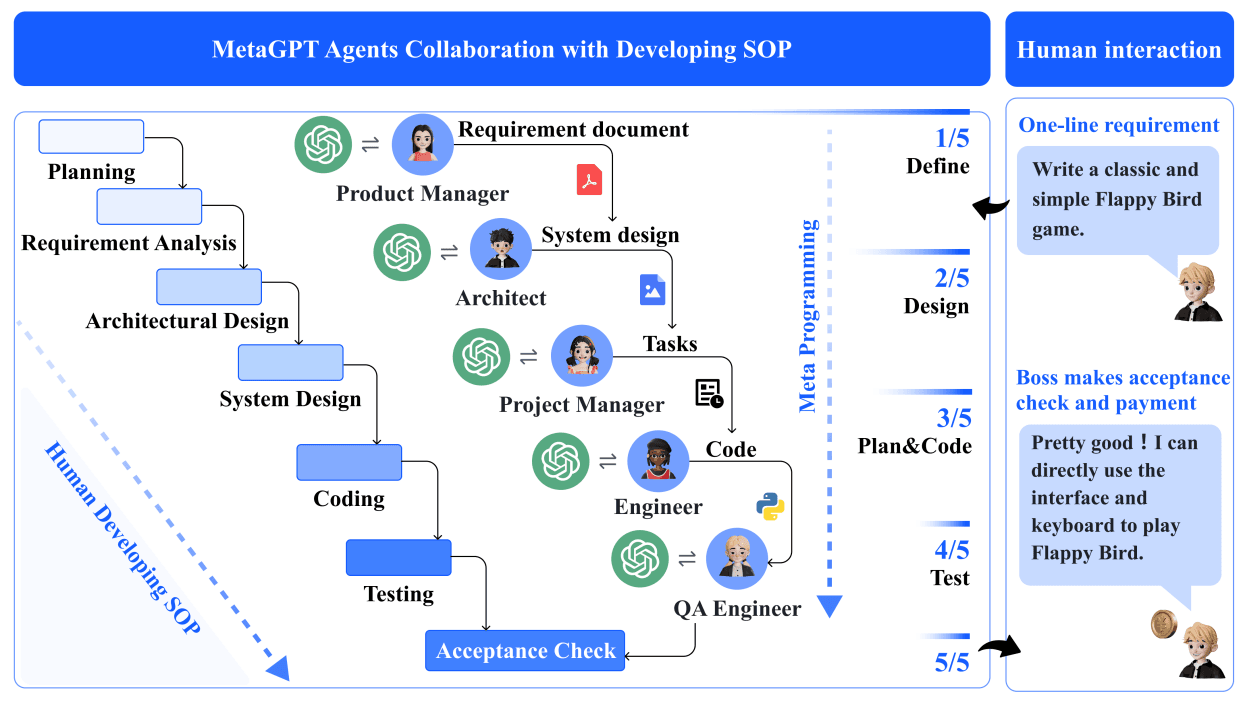
MetaGPT’s core idea is simple and old-fashioned: real organizations use process. So MetaGPT encodes a software-company SOP into a multi-agent system, with roles like product manager, architect, project manager, engineer, and QA (see the MetaGPT GitHub repository and the MetaGPT paper).
The paper describes MetaGPT as a meta-programming framework that:
-
encodes Standardized Operating Procedures (SOPs) into prompt sequences
-
uses an assembly line paradigm to assign diverse roles
-
produces structured intermediate outputs to reduce ambiguity and errors
-
aims to mitigate cascading hallucinations in multi-agent collaboration (see MetaGPT paper)
The repository distills the philosophy into a blunt line: Code = SOP(Team) (see MetaGPT GitHub repository).
If that sounds like bureaucracy, good. The point is to trade a little rigidity for a lot of predictability.
4.1 Why SOPs work (when they do)
SOPs do three things that matter for agents:
-
They reduce the decision space.
Instead of asking the model to invent a development process, you give it a process and ask it to execute. -
They enforce handoffs with artifacts, not vibes.
A PRD is an artifact. An API design is an artifact. A test plan is an artifact. Artifacts can be checked. -
They make review possible.
A human can review “PRD v1 → architecture → plan → code” far more easily than a 200-turn conversation.
This aligns with Anthropic’s recommendation to favor simple, composable patterns and explicit planning steps (see Building effective agents). MetaGPT’s bet is that for software and business-building tasks, a “company-shaped” workflow is one of the simplest patterns that still scales.
4.2 MetaGPT’s practical contribution: structured multi-agent collaboration you can run
MetaGPT is also open source under MIT, and it’s usable as a CLI or library (see MetaGPT GitHub repository). That matters because it makes the workflow inspectable. You can read the role prompts, see the intermediate files, and change the SOP.
For anyone building agentic products, this is a key point: you cannot debug what you can’t see. Frameworks that hide prompts and handoffs behind abstractions may speed up demos, but they slow down reliability work.
5) From MetaGPT (ICLR 2024) to AFlow (ICLR 2025): workflows become code you can optimize
Your prompt is not a workflow. It’s a request.
If you want reliable agentic performance, you eventually need something you can iterate on: a workflow that can be versioned, tested, compared, and improved. That’s where the AFlow line of work is interesting.
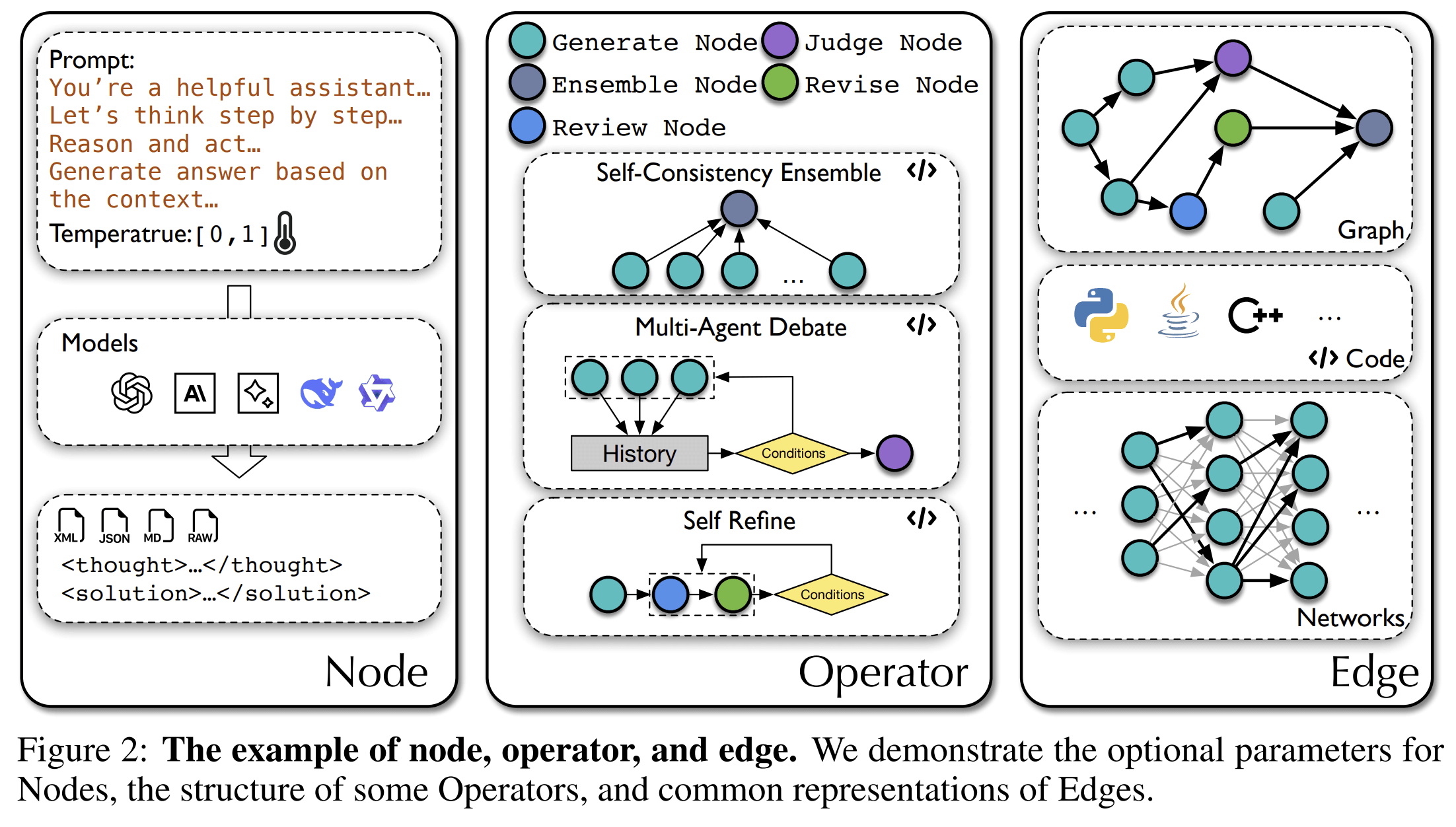
AFlow reframes workflow optimization as search in a code-represented workflow space, where “LLM-invoking nodes are connected by edges,” and uses Monte Carlo Tree Search plus execution feedback to refine workflows (see AFlow paper).
Even if you don’t use AFlow, the direction is clear:
-
workflows will be treated as programs
-
agent behavior will be tuned by search + feedback, not manual prompt edits
-
“best practice” will be less about clever prompting and more about measurable harness design
That matches what Anthropic describes in their compiler project: most effort went into harnesses, tests, and feedback loops (see Building a C compiler with a team of parallel Claudes).
This is the unglamorous truth of agents: the model gets better, but the decisive advantage comes from the loop you build around it.
6) Atoms: multi-agent collaboration packaged as a product that ships
Now to Atoms.
Atoms positions itself as a platform that turns ideas into “products that sell,” using a team of specialized agents that cover research, product, architecture, engineering, SEO, and analytics (see Atoms). The site is explicit about two things that most “AI app builders” stay vague on:
-
It aims to build real apps, not just demos—explicitly including login, data storage, and Stripe payments (see Atoms).
-
It treats the experience as a multi-agent workflow rather than a single assistant (same source).
Atoms also lists concrete “AI team” roles (e.g., Deep Researcher, Product Manager, Architect, Engineer, SEO Specialist, Data Analyst) and presents the flow as research → design → coding → growth in one place (see Atoms).
This is where the MetaGPT lineage matters. The product is implicitly making the same bet MetaGPT made in research form: role specialization and structured handoffs beat a single model doing everything in one voice.
6.1 What Atoms adds on top of the framework idea
From the product description, Atoms adds at least four “deployment-level” elements that research frameworks often hand-wave:
-
A hosted environment and deployment path (“publish a live URL instantly” and “Atoms handles hosting and server configuration”) (see Atoms).
-
Out-of-the-box backend: “user login, database, integrations, and scalable hosting” (same source).
-
Race Mode: running prompts across multiple models/attempts to pick the best version (same source).
-
Code ownership / escape hatch: export code and sync to GitHub (same source).
If you’ve built internal agent systems, you know why these are not minor details. Most agent demos fail at the last mile: auth, persistence, payments, deployment, and ongoing iteration.
Atoms is trying to make those “boring” parts default.
6.2 A practical example: what an Atoms-style workflow looks like
Let’s take a non-trivial prompt: “Build a subscription analytics dashboard for a niche SaaS, with paid tiers, onboarding, and SEO pages.”
A serious agentic workflow would need to produce:
-
an opinionated scope (what’s in/out)
-
a data model (customers, plans, events, churn, cohorts)
-
authentication and roles (admin vs user)
-
Stripe integration and webhook handling
-
a dashboard UI plus charts
-
deployment configuration
-
SEO pages and basic content scaffolding (at least landing pages + docs)
The Atoms page claims it can deliver full-stack applications with those components—login, database, Stripe payments—via chat, and also includes an SEO agent capability (some marked “coming soon”) (see Atoms).
Whether a given run succeeds will still depend on the harness quality, model quality, and the specificity of requirements. But the important shift is that the system is supposed to own the whole loop. That is the difference between “coding assistant” and “product builder.”
7) How to think about building agentic workflows (without fooling yourself)
If you’re building on Claude Opus, using MetaGPT, or using Atoms, the same rules apply. The model is not your product. The workflow is.
Here are principles that consistently separate systems that ship from systems that impress:
7.1 Make “done” machine-checkable
If your workflow can’t evaluate itself, it will drift.
-
For coding: tests, lint, type checks, build steps (Anthropic’s compiler work is basically an extreme version of this) (see Building a C compiler with a team of parallel Claudes).
-
For research: citation requirements, source diversity constraints, fact extraction rubrics.
-
For business building: deployed URL exists, auth works, payment flow completes in test mode, SEO pages render.
7.2 Use roles to reduce context entropy
MetaGPT’s role separation is not aesthetic; it prevents “everything everywhere all at once” prompts.
Even in a single-agent implementation, you can simulate roles by isolating contexts and outputs:
-
Research summary → frozen
-
PRD → frozen
-
Architecture → frozen
-
Implementation tasks → iterative
MetaGPT formalizes this; Atoms productizes it (see MetaGPT paper and Atoms).
7.3 Treat tools like APIs, not magic buttons
Anthropic’s guidance is blunt: invest in tool documentation and testing like you would in human-computer interfaces (see Building effective agents).
If your tool definitions are sloppy, the model will misuse them. Then you’ll blame the model for what is actually an interface design problem.
7.4 Prefer simple patterns; earn complexity
Anthropic’s “simple composable patterns” point is not theory; it’s a warning (see Building effective agents). Complex agent frameworks can hide the real failure: your task is underspecified, your eval is weak, or your tool surface is unclear.
MetaGPT is “complex” in the sense that it uses multiple roles, but it’s “simple” in the sense that the workflow is explicit and repetitive. That’s the kind of complexity you can actually debug.
8) Measuring success: what to track in agentic workflows
The most damaging lie in agent products is “it worked once in a demo.” Reliability is not a feeling. It’s a distribution.
If you want to evaluate agentic workflows realistically, track:
8.1 Completion rate on a fixed suite
Anthropic references agentic coding evaluations like Terminal-Bench 2.0 in their Opus 4.6 release (see Introducing Claude Opus 4.6). You don’t need those exact benchmarks, but you need the same concept: a stable set of tasks with scoring.
8.2 Cost and latency per completed task
Agents trade cost/latency for performance. Anthropic explicitly calls out this tradeoff in when to use agents vs simpler solutions (see Building effective agents).
If your workflow costs $50 in tokens to build a feature that a human could implement in 10 minutes, that might still be fine—if your user is non-technical and you own the whole deployment path. But you should know the economics, not guess.
8.3 Intervention rate
Count how often a human has to step in:
-
to clarify requirements
-
to fix tool misuse
-
to correct a wrong assumption
-
to unblock a stuck loop
Lowering intervention rate is usually more valuable than improving “IQ-style” benchmark scores.
8.4 Regression rate across iterations
The compiler story is instructive: as new features were added, old functionality broke, and they needed CI gates to stop regressions (see Building a C compiler with a team of parallel Claudes). Product workflows have the same problem. The more you automate, the more you need guardrails that prevent “fix one thing, break two.”
9) Where Atoms fits if you’re a builder (not a framework engineer)
Most people do not want to engineer harnesses. They want an output: a deployed app, a working payment flow, a landing page that ranks.
If you are that person, Atoms is aimed at collapsing the workflow into a single place: research, build, deploy, and iterate (see Atoms). The product claims:
-
chat-driven building (“vibe coding”)
-
one-click deployment
-
out-of-the-box backend (login, database, hosting)
-
Stripe payments
-
exportable code / GitHub sync
-
multi-agent role coverage for planning and execution
The key is that Atoms is not asking you to understand SOPs, orchestration patterns, or tool schemas. It’s trying to embed those decisions into the system. If it works, it’s because those decisions are correct often enough—and because the system can verify itself.
If it doesn’t work, the failure will usually be one of three things:
-
your requirements were too ambiguous
-
the workflow’s verification surface is weak for your task
-
the system’s tool interfaces don’t match your domain edge cases
Those are solvable problems, but they’re not solved by adding more adjectives to your prompt.
10) FAQ
What is an “agentic workflow,” in one sentence?
A system that can plan, call tools, verify progress, and iterate over multiple steps toward a goal—without needing constant human steering (see Anthropic’s workflow/agent distinction in Building effective agents).
Why does Claude Opus 4.6 matter specifically for agents?
Anthropic claims Opus 4.6 plans more carefully, sustains agentic tasks longer, works more reliably in larger codebases, and adds long-horizon enablers like 1M context (beta), compaction, and effort controls (see Introducing Claude Opus 4.6).
What is MetaGPT’s core idea?
Encode real-world SOPs (roles + handoffs + structured outputs) into a multi-agent system to reduce ambiguity and cascading errors (see MetaGPT paper and MetaGPT GitHub repository).
Why not just use a single “super agent”?
You can, and sometimes you should. But as tasks grow, a single context becomes noisy, plans drift, and verification gets weaker. Role separation and structured handoffs are a practical way to keep work legible and checkable—especially for software and business-building tasks.
Where does AFlow fit?
AFlow treats workflows as code that can be searched and optimized with execution feedback, aiming to reduce the manual effort of designing workflows (see AFlow paper).
What does Atoms do differently from a coding assistant?
Atoms positions itself as an end-to-end product builder: research + planning + full-stack build + deployment, with built-in backend pieces like login, database, and Stripe payments, plus code export/GitHub sync (see Atoms).
Closing: the sober view of “agents”
Agentic workflows aren’t a new kind of intelligence. They’re a new kind of software system: model + tools + loop + verification + memory management + (sometimes) parallelism.
Claude Opus 4.6 pushes the model side forward and adds platform features meant for long-horizon autonomy (see Introducing Claude Opus 4.6). MetaGPT shows why SOPs and structured intermediate outputs matter when you have multiple agents (see MetaGPT paper). And Atoms is a bet that packaging these ideas into a single product—where a “team” can take you from idea to deployed app—is what most builders actually need (see Atoms).
If you want a reliable agentic system, stop asking “how smart is the model?” and start asking:
-
What does it do when it’s wrong?
-
What does it check?
-
What does it remember?
-
What does it do in parallel?
-
What forces it to finish?
That’s where real progress lives.
