GLM-5 is now officially out, and it comes with the kind of technical disclosure that lets you reason about why it behaves the way it does: parameter scale, active parameters, pretraining token count, long-context attention choice, post-training RL infrastructure, benchmark suite, and evaluation settings are all published in the official materials.
The headline positioning is straightforward: Z.ai frames GLM-5 as a flagship model for “complex systems engineering and long-horizon agentic tasks,” explicitly comparing it against frontier closed models such as Claude Opus 4.5 across coding and agent benchmarks, while shipping open weights under an MIT license (Z.ai release post, Hugging Face model card).
What follows is a technical, data-first digest: specs, training scale, post-training design, benchmark results (including the exact decoding and context settings), and deployment/tooling details, plus a careful comparison to Claude Opus 4.5 using cited sources.
Quick facts: what GLM-5 is (and is not)
From Z.ai’s docs, GLM-5 is a text-in / text-out flagship LLM with long context and large outputs (so: not a “unified multimodal” model by default, even if the broader GLM family includes vision and image-generation siblings) (GLM-5 API docs).
Key published specs:
| Category | What’s published | Source |
|---|---|---|
| Weights / license | Open weights, MIT license | GLM-5 release post, HF model card |
| Architecture style | Mixture-of-Experts + DSA (DeepSeek Sparse Attention) | GLM-5 release post, HF model card |
| Parameter scale | 744B total parameters; 40B active | HF model card, GLM-5 API docs |
| Pretraining data | 28.5T tokens (up from 23T in GLM-4.5) | HF model card, GLM-5 API docs |
| Context length | 200K | GLM-5 API docs |
| Max output | 128K output tokens (docs), and eval settings show up to 131,072 max_new_tokens |
GLM-5 API docs, HF model card |
| RL post-training infra | “slime” asynchronous RL infrastructure | GLM-5 release post, slime repo |
| Primary targets | agentic engineering, long-horizon tasks, coding | GLM-5 release post, GLM-5 API docs |
Two immediate implications of those numbers:
-
744B total / 40B active suggests Z.ai is optimizing for “frontier-ish” capacity without paying the full inference cost of a dense 700B+ model on every token. That’s the basic MoE trade: keep a large total parameter pool, but activate only a subset per token.
-
200K context + 128K output puts GLM-5 in the “long-context, long-output” category where agent loops and codebase-scale tasks become practical—if the model’s attention and context-management strategy is stable.
Everything else (DSA and slime) is best understood as enabling those two goals: long context at manageable cost, and post-training that actually improves agentic reliability rather than just “style.”
1) Scaling: what changed from GLM-4.x to GLM-5
Z.ai provides an explicit scale comparison:
-
GLM-4.5: 355B parameters with 32B active
-
GLM-5: 744B parameters with 40B active
-
Pretraining data: 23T → 28.5T tokens (HF model card, also reflected in GLM-5 API docs)
This is a meaningful shift: active parameters rise modestly (32B → 40B), while total parameters more than double (355B → 744B). In plain terms, GLM-5 likely increases capacity via more experts (or larger experts), but keeps per-token compute closer to “~40B-dense-equivalent” rather than “744B-dense-equivalent.”
Z.ai’s framing here matters: they explicitly call out that scaling is still one of the most important levers for “intelligence efficiency,” and they tie it to “complex systems engineering and long-horizon agentic tasks” rather than to generic chat performance (GLM-5 release post).
2) Long context without blowing up inference: DeepSeek Sparse Attention (DSA)
Z.ai says GLM-5 “integrates DeepSeek Sparse Attention (DSA),” with the claim that it “reduces deployment cost while preserving long-context capacity” (GLM-5 release post, HF model card).
You can treat this as a practical design choice driven by 200K context:
-
Dense attention cost scales poorly with context length.
-
Sparse attention variants try to keep “enough” global connectivity for reasoning while reducing compute/memory.
-
The product goal is not “support 200K on paper,” but “support 200K in a way that doesn’t destroy throughput or cost.”
Z.ai doesn’t publish the full DSA implementation details in the release post, but the model tag on Hugging Face (glm_moe_dsa) and the explicit DSA mention are at least a clear sign that DSA is not an optional add-on: it’s a core part of GLM-5’s architecture identity (HF model card).
A key nuance: long context doesn’t automatically imply good long-context use. That’s why evaluation settings and context-management strategy matter (we’ll get to that under BrowseComp and the footnotes).
3) Post-training for agents: “slime” and asynchronous RL
Z.ai’s release post makes a strong claim that the gap between “competence” and “excellence” is largely post-training, but that RL at scale is bottlenecked by training inefficiency—especially for long-horizon, tool-using agent behaviors. Their answer is slime, described as “a novel asynchronous RL infrastructure” that improves throughput and iteration speed (GLM-5 release post, HF model card).
The slime GitHub repo provides more concrete structure:
-
It is “an LLM post-training framework for RL scaling” with two core capabilities: high-performance training (Megatron + SGLang) and flexible data generation workflows (slime repo).
-
It describes an architecture with three modules:
-
training (Megatron): main training process, syncs parameters
-
rollout (SGLang + router): generates new data and reward/verifier outputs
-
data buffer: manages prompt init, custom data, and rollout storage (slime repo)
-
This “decoupled/asynchronous” design is aimed at a real systems issue in RL for LLMs: rollouts are expensive and often dominate wall time, and naive pipelines become lockstep and slow. slime positions itself as a systems-and-algorithm response to that.
The slime README also highlights system-level optimizations like APRIL (Active Partial Rollouts), specifically to address long-tail generation bottlenecks that “typically consume over 90% of RL training time” (slime repo).
Why this matters for GLM-5:
-
Long-horizon agents fail in ways that look like “paper cuts” (forgetting goals, losing state, mishandling tools, inconsistent planning).
-
Fixing that isn’t only about bigger pretraining; it’s about post-training loops that expose the model to tool-feedback and multi-turn consequences, at enough scale to stick.
Z.ai’s own docs echo that narrative: they explicitly connect slime to “more complex reinforcement learning tasks” and “continuous learning from long-range interactions” (GLM-5 API docs).
4) Benchmarks: what GLM-5 reports, with the exact eval settings
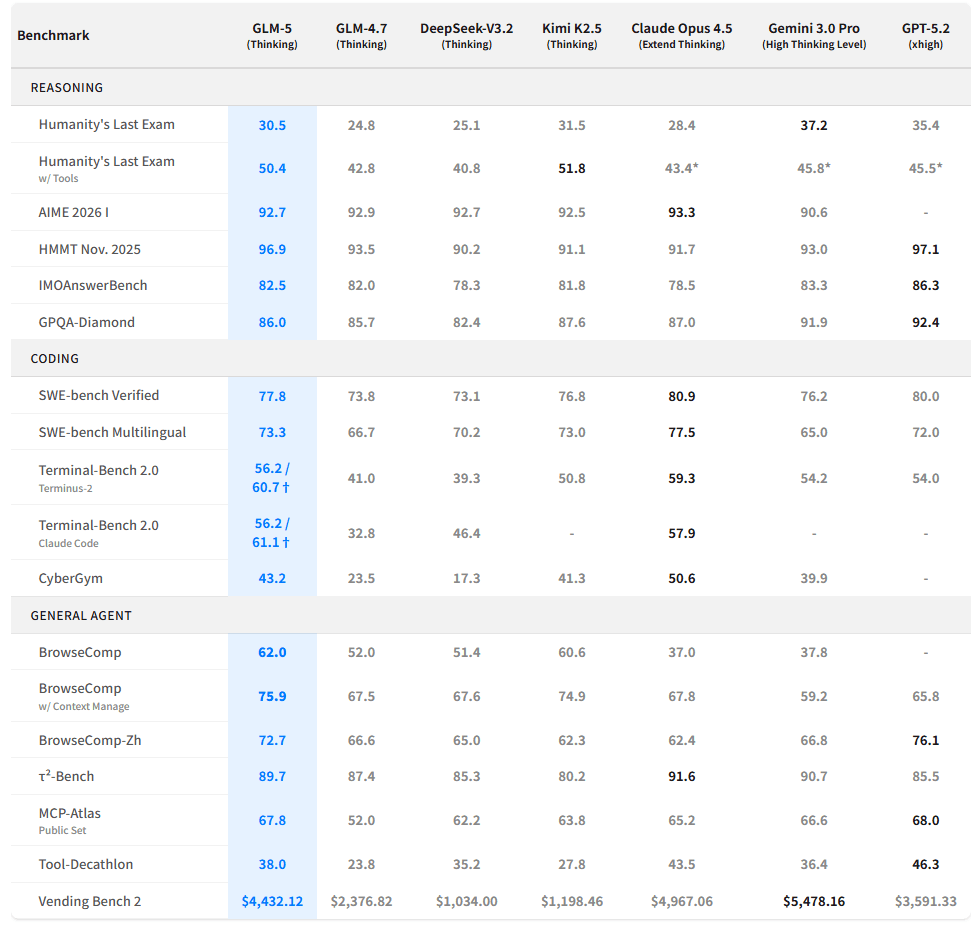
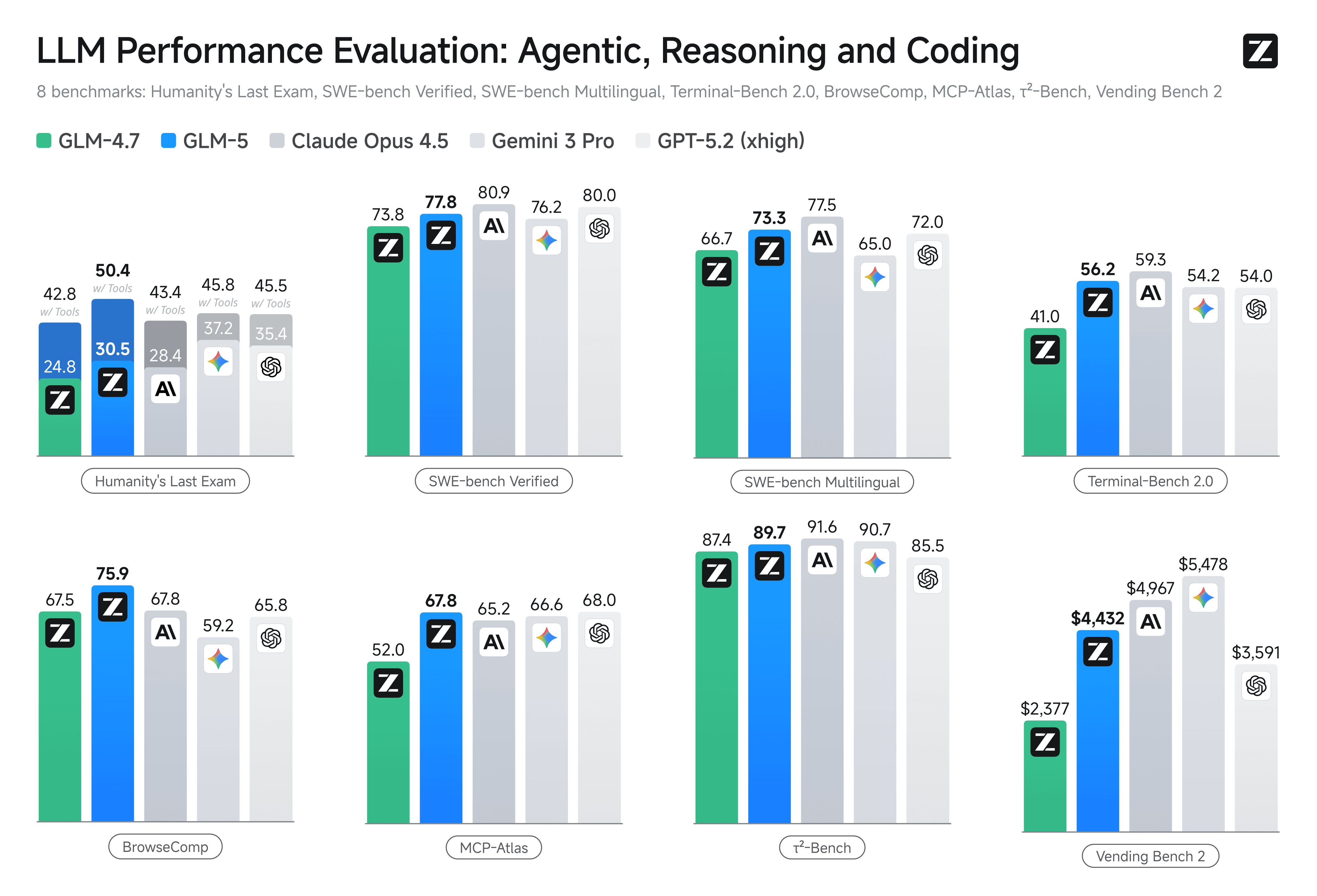
Z.ai and the HF model card provide a single consolidated benchmark table covering reasoning, coding, and agent tasks, including comparisons to Claude Opus 4.5 and other models (GLM-5 release post, HF model card).
Below are the key results that most directly support the “against Claude Opus 4.5” positioning.
4.1 Reasoning (HLE, GPQA, math olympiad-style)
Selected reported numbers:
-
Humanity’s Last Exam (HLE): 30.5 (GLM-5) vs 28.4 (Claude Opus 4.5)
-
HLE w/ Tools: 50.4 (GLM-5) vs 43.4* (Claude Opus 4.5, full-set score marked with
*) -
GPQA-Diamond: 86.0 (GLM-5) vs 87.0 (Claude Opus 4.5)
-
AIME 2026 I: 92.7 (GLM-5) vs 93.3 (Claude Opus 4.5) (HF model card)
What’s unusually useful here is the disclosed decoding settings for HLE and other reasoning tasks:
-
temperature=1.0, top_p=0.95, max_new_tokens=131072 -
HLE-with-tools max context length: 202,752 tokens
-
Judge model mentioned: “GPT-5.2 (medium)” as judge for some tasks (HF model card)
Even if you disagree with any single benchmark, this level of disclosure lets you evaluate whether the results are “short-answer,” “deep-thinking,” or “long-output” regimes—and GLM-5 is clearly evaluated in a long-output regime.
4.2 Coding (SWE-bench, Terminal-Bench 2.0, CyberGym)
Key reported coding numbers:
-
SWE-bench Verified: 77.8 (GLM-5) vs 80.9 (Claude Opus 4.5)
-
SWE-bench Multilingual: 73.3 (GLM-5) vs 77.5 (Claude Opus 4.5) (HF model card)
Terminal-Bench 2.0 is reported in two harnesses:
-
Terminal-Bench 2.0 (Terminus 2): 56.2 / 60.7†
-
Terminal-Bench 2.0 (Claude Code): 56.2 / 61.1†
-
Claude Opus 4.5 (Terminus 2): 59.3
-
Claude Opus 4.5 (Claude Code): 57.9 (HF model card)
The dagger † is important: it indicates a verified version of Terminal-Bench 2.0 that fixes ambiguous instructions.
Z.ai publishes that verified dataset as terminal-bench-2-verified on Hugging Face, with a detailed dataset card explaining:
-
environment fixes (e.g., ensuring
procpssopsexists to avoid agent runtime crashes), -
instruction fixes where tasks and tests didn’t align,
-
and an evaluation table showing how much those fixes change scores (Terminal-Bench 2.0 Verified dataset).
That dataset card also links to the public Terminal-Bench leaderboard (Terminal-Bench leaderboard).
If you care about “coding agents,” this is one of the most actionable parts of the GLM-5 release: it acknowledges that benchmark numbers can be dominated by harness/environment bugs, and it shows the fixes.
Z.ai’s GLM-5 API docs also summarize the “coding parity” claim directly, stating GLM-5 approaches Claude Opus 4.5 in real programming scenarios and calling out SWE-bench Verified and Terminal Bench 2.0 scores (77.8 and 56.2) (GLM-5 API docs).
4.3 Agent benchmarks (BrowseComp, τ²-bench, MCP-Atlas)
Agent tasks are where GLM-5’s numbers are more “directional” than “absolute,” because tool environments and context strategies matter a lot. Still, the table is explicit:
-
BrowseComp: 62.0 (GLM-5) vs 37.0 (Claude Opus 4.5)
-
BrowseComp (w/ Context Manage): 75.9 (GLM-5) vs 67.8 (Claude Opus 4.5)
-
τ²-Bench: 89.7 (GLM-5) vs 91.6 (Claude Opus 4.5)
-
MCP-Atlas (Public Set): 67.8 (GLM-5) vs 65.2 (Claude Opus 4.5) (HF model card)
There are two especially important footnotes here:
-
BrowseComp context management: Z.ai states that “without context management” they retain details from the most recent 5 turns; “with context management,” they use a discard-all strategy aligned with other models. That means BrowseComp results are not only “model capability,” but also “context policy” (HF model card).
-
τ²-bench domain fixes: Z.ai explicitly says that for the Airline domain they apply “domain fixes proposed in the Claude Opus 4.5 system card.” That links GLM-5’s reported τ²-bench setup to Anthropic’s published safety/eval documentation (HF model card, Claude Opus 4.5 system card, τ²-bench repo).
This is subtle but meaningful: it implies Z.ai is actively tuning the evaluation harness for fairness/robustness (or at least for avoiding avoidable failures), and it also means τ²-bench numbers are not purely “raw.”
4.4 Long-horizon operational capability: Vending-Bench 2
Z.ai heavily features Vending-Bench 2 as a long-horizon agent benchmark, reporting GLM-5’s final balance as:
-
$4,432.12 (GLM-5)
-
vs $4,967.06 (Claude Opus 4.5) (HF model card)
The key point: Vending-Bench is not a short interaction benchmark; it simulates running a vending machine business over a year.
Andon Labs—the benchmark authors—describe it as:
-
“measuring AI model performance on running a business over long time horizons,”
-
scoring by bank balance after a year,
-
with models using tools (web search, email ordering, inventory moves),
-
and producing 3,000–6,000 messages per run with ~60–100M output tokens per run (Vending-Bench 2).
Their public leaderboard lists GLM-5 in the top cluster:
-
Claude Opus 4.6: $8,017.59
-
Gemini 3 Pro: $5,478.16
-
Claude Opus 4.5: $4,967.06
-
GLM-5: $4,432.12 (Vending-Bench 2 leaderboard)
This is one of the cleaner “agent endurance” signals currently available, precisely because it’s hard to fake with shallow heuristics: the model must not go bankrupt, must restock, must negotiate, and must maintain coherence across long tool traces.
5) How “directly vs Claude Opus 4.5” does the comparison actually go?
There are two different comparisons happening in the GLM-5 narrative:
-
Capability comparison (benchmarks)
-
Product comparison (integration, cost structure, availability, licensing)
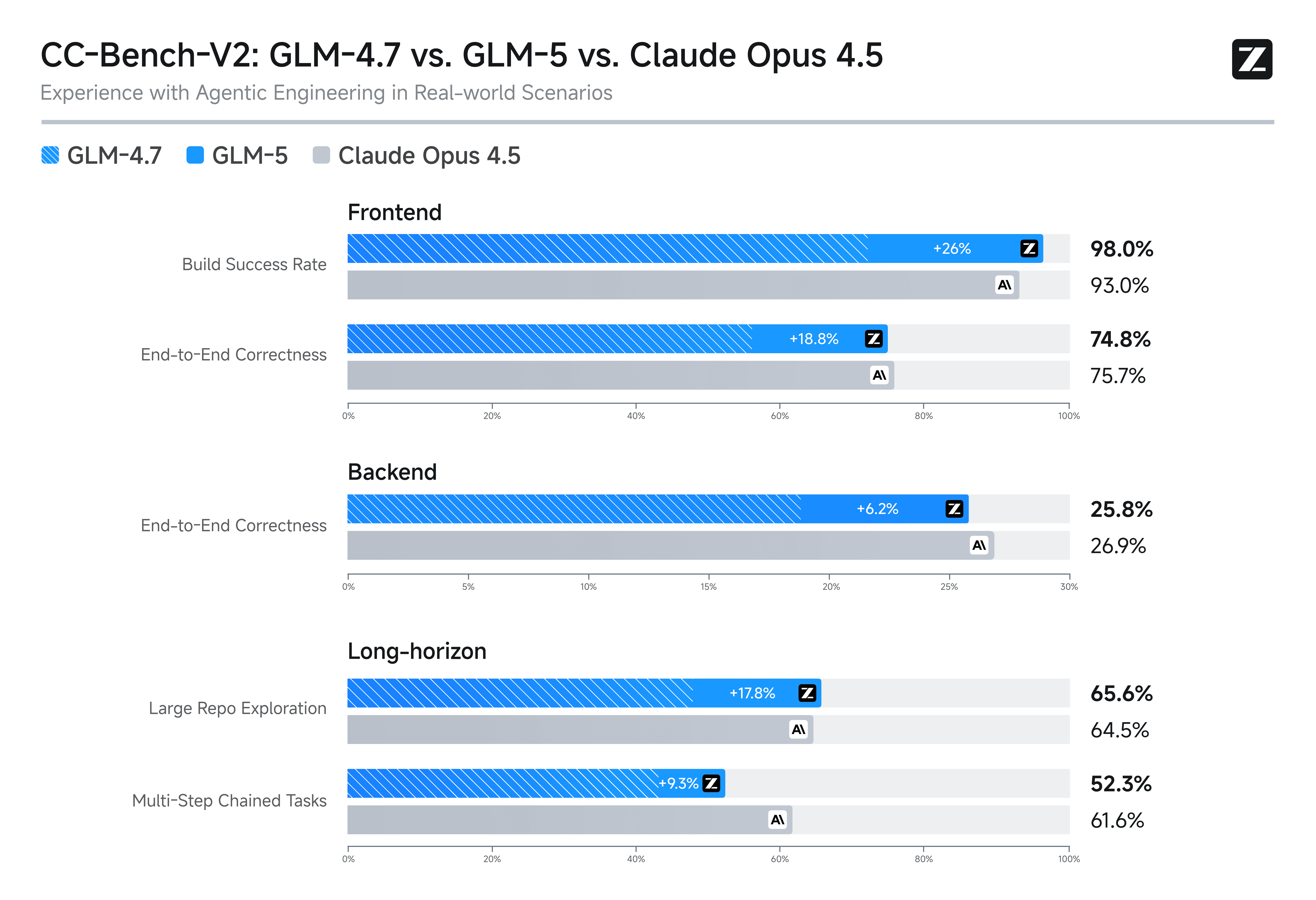
On the capability side, the Z.ai table shows a mixed picture (as you’d expect):
-
GLM-5 is close to Opus 4.5 on several coding/agent metrics but does not uniformly beat it.
-
SWE-bench Verified remains higher for Opus 4.5 in the published table (80.9 vs 77.8).
-
τ²-bench is higher for Opus 4.5 (91.6 vs 89.7).
-
BrowseComp with context management is higher for GLM-5 (75.9 vs 67.8). (HF model card)
On the product side, Opus 4.5 is a closed model available via Anthropic’s apps and API; Anthropic publishes the model name for API usage and lists pricing as $5 / $25 per million tokens (input/output) in the announcement (Introducing Claude Opus 4.5).
GLM-5’s product “point” is different:
-
open weights under MIT (HF model card),
-
local deployment recipes for vLLM and SGLang, including FP8 variants and tool/reasoning parsers (HF model card),
-
compatibility with popular coding-agent shells (Claude Code and others) via Z.ai’s “Coding Plan” flow and docs (GLM Coding Plan overview).
So if you mean “directly benchmarked against Opus 4.5,” the answer is yes: Z.ai’s table is explicitly comparative. If you mean “drop-in replacement,” it depends on whether your constraints favor open weights and self-hosting, or prefer managed closed APIs and a single vendor stack.
6) Getting and using GLM-5: API, chat, coding agents, local serving
Z.ai offers multiple surfaces, and the official docs are unusually direct.
6.1 API usage (Z.ai Open Platform)
The GLM-5 API docs provide:
-
context length 200K
-
max output 128K
-
and an OpenAI-compatible base URL example:
https://api.z.ai/api/paas/v4/(GLM-5 API docs).
They also show a raw endpoint call:
-
POST https://api.z.ai/api/paas/v4/chat/completions -
model name
"glm-5" -
optional
"thinking": {"type": "enabled"}(GLM-5 API docs)
This matters if you’re building agent systems: the model is designed to run with “thinking mode,” function calling, structured outputs, streaming, and context caching (all listed as capabilities) (GLM-5 API docs).
6.2 Chat surface
The Hugging Face model card links directly to GLM-5 chat at Z.ai (chat.z.ai).
6.3 “Coding Plan” and Claude Code integration
Z.ai’s Developer Docs for the GLM Coding Plan explicitly note:
-
GLM-5 is being rolled out first to Max tier (then Pro later),
-
it can be used inside tools like Claude Code / Cline / OpenCode, etc.,
-
there are usage limits and model mapping via config such as
~/.claude/settings.json(GLM Coding Plan overview).
This is less about raw model capability and more about meeting developers where they already work: agent shells with file access, terminal control, and multi-step execution loops.
6.4 Local deployment (vLLM, SGLang, Ascend NPUs)
The GLM-5 Hugging Face model card provides concrete deployment commands and points to recipes:
-
vLLM serve example using
zai-org/GLM-5-FP8 -
SGLang launch server example
-
Ascend / xLLM notes and a link to an Ascend deployment guide in the repo (HF model card, Ascend guide, vLLM recipe, SGLang cookbook)
Z.ai’s release post also claims GLM-5 can be deployed on non-NVIDIA chips (Ascend, Moore Threads, Cambricon, Kunlun, MetaX, Enflame, Hygon), and that kernel optimization + quantization are used to reach reasonable throughput on those chips (GLM-5 release post).
If you’re assessing enterprise deployability, that combination—open weights, multiple inference stacks, and explicit non-NVIDIA deployment messaging—is part of the core “why GLM-5 exists” story.
7) A note on methodology: why the footnotes are part of the product
If you strip away the marketing framing, what’s most operationally valuable in the GLM-5 release is the fact that Z.ai publishes:
-
decoding parameters (
temperature,top_p,max_new_tokens), -
context windows used per benchmark,
-
tool/context-management rules (BrowseComp),
-
and even the judge model used for some tasks (HLE judge) (HF model card).
This is not “nice-to-have trivia.” It’s how you avoid bad conclusions like:
-
“Model A beats model B” when one had 131K output budget and the other was constrained.
-
“Agent capability is low” when the harness environment was missing
psand the runtime crashed.
Terminal-Bench 2.0 is a good example: Z.ai’s verified dataset makes the case that harness/environment issues can create misleading impressions of agent strength, and it provides fixes plus updated eval numbers (Terminal-Bench 2.0 Verified dataset).
If you’re building your own agent evaluation suite, this release is effectively an argument for treating evaluation engineering as part of the model lifecycle.
8) What we still don’t have (yet): the technical report
The Hugging Face model card states: “Our technical report is coming soon” (HF model card).
So there are still unanswered questions that matter for deep technical scrutiny, for example:
-
exact MoE structure (number of experts, routing scheme, load balancing),
-
training compute, data mixture, filtering,
-
DSA implementation details and quality tradeoffs,
-
post-training recipe breakdown (SFT vs RL proportions, tool-use curricula),
-
safety and robustness evaluations beyond the benchmark suite.
Until the report lands, the most reliable “hard facts” are the ones above: published scale, context/output specs, the benchmark table, and the deployment/tooling surface.
Conclusion: what GLM-5 changes in practice
GLM-5 is best understood as a systems release rather than just “a new chat model”:
-
a scaled MoE foundation (744B total / 40B active; 28.5T tokens),
-
long-context support anchored by DSA,
-
an explicit RL post-training infrastructure (slime) aimed at agentic behaviors,
-
benchmark reporting with unusually detailed evaluation settings,
-
and a deployment story that spans managed API, coding-agent integration, and local serving stacks.
The “directly vs Claude Opus 4.5” claim is not empty: Z.ai publishes head-to-head numbers across widely referenced coding and agent benchmarks and links parts of their eval methodology to Opus 4.5 documentation (e.g., τ²-bench domain fixes) (GLM-5 release post, HF model card, Introducing Claude Opus 4.5).
Atoms already supports GLM 5—use it in Atoms.
