
We are excited to share that our team has five papers accepted to ICML 2026.
The International Conference on Machine Learning (ICML) is one of the most influential international conferences in machine learning, alongside NeurIPS and ICLR. It brings together leading research in machine learning, artificial intelligence, optimization, representation learning, reinforcement learning, and agent systems.
According to the official acceptance information, ICML 2026 received 23,918 submissions for review and accepted 6,352 papers, with an overall acceptance rate of 26.6%. The conference will be held in Seoul, South Korea, from July 6 to July 11, 2026.
This year, our team has five accepted papers at ICML 2026. These works study different but closely related problems in building better agents: user-centric interaction, research ideation, sub-agent orchestration, ambiguous-query search evaluation, and verifiable web-agent environments.
The accepted works were completed by members of our research team in collaboration with academic and industry partners, including [INSTITUTION / UNIVERSITY / COMPANY NAMES TO BE CONFIRMED].
Together, these five papers reflect a shared research direction: agents should not be fixed prompt chains. They should be adaptive systems that can ask useful questions, reason through open-ended problems, create specialized sub-agents, handle ambiguous user intent, and operate in environments where success can be verified.
1. AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
- Paper: AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
- Authors: Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, Yuyu Luo, Jiayi Zhang
- Institutions / Companies: DeepWisdom, The Hong Kong University of Science and Technology (Guangzhou), Renmin University of China, East China Normal University, Université de Montréal & Mila – Quebec AI Institute
AOrchestra focuses on agent orchestration. Complex, long-horizon tasks often cannot be solved well by a single monolithic agent. They require decomposition, specialization, tool use, and coordination.
Existing multi-agent systems often rely on manually predefined roles or static sub-agents. A developer decides in advance what agents exist, what tools each agent can use, and how they should interact. This limits adaptability because real tasks vary widely.
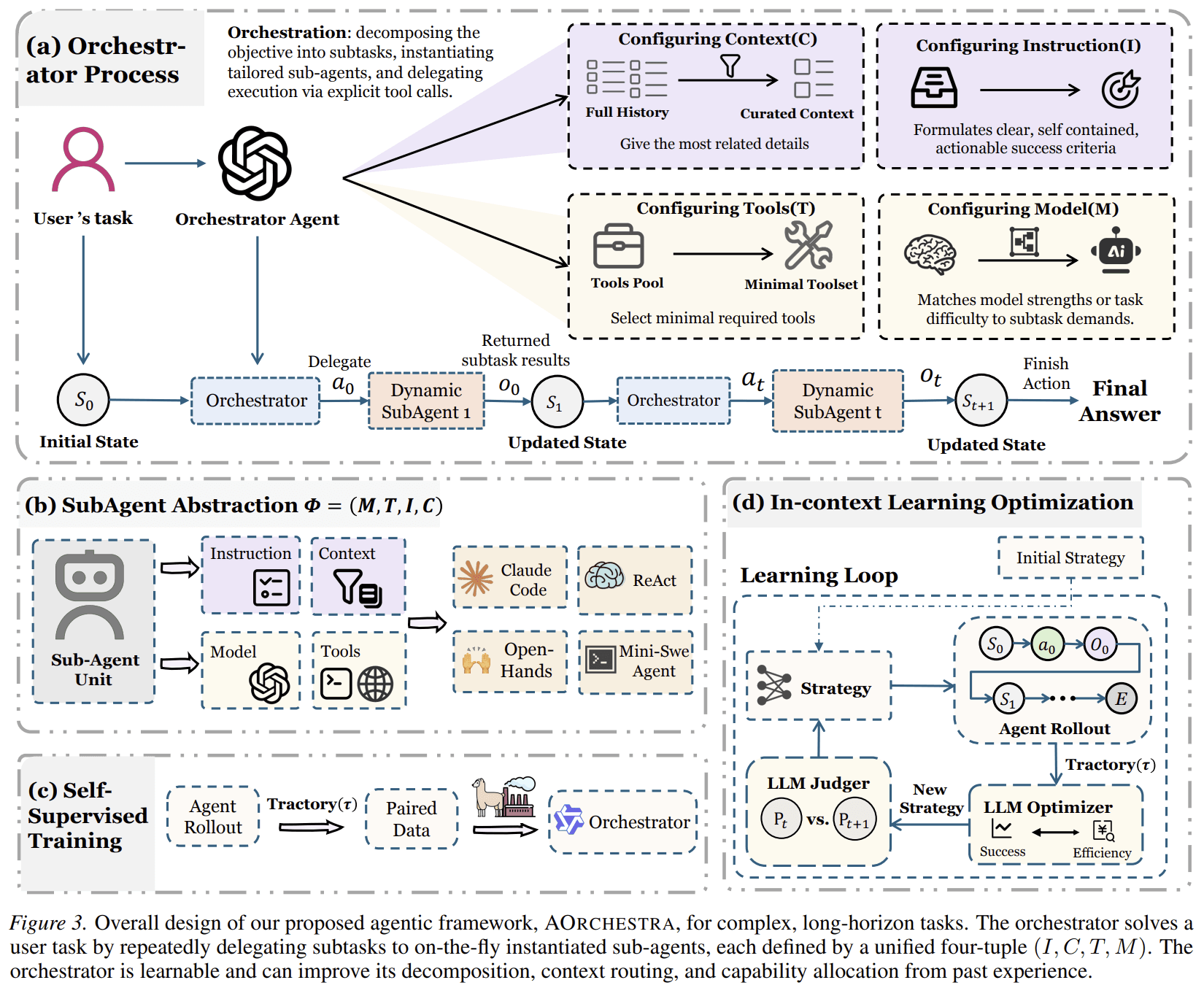
AOrchestra introduces a unified abstraction for agents. It models any agent as a four-tuple:
- Instruction;
- Context;
- Tools;
- Model.
This four-tuple acts as a compositional recipe for creating specialized sub-agents. Instead of using a fixed set of roles, AOrchestra allows a central orchestrator to create task-specific sub-agents on demand. For each subtask, the orchestrator decides what instruction to give, what context to pass, which tools to expose, and which model to use.
This design separates orchestration from execution. The orchestrator does not directly solve every task; it creates the right executor for each step.
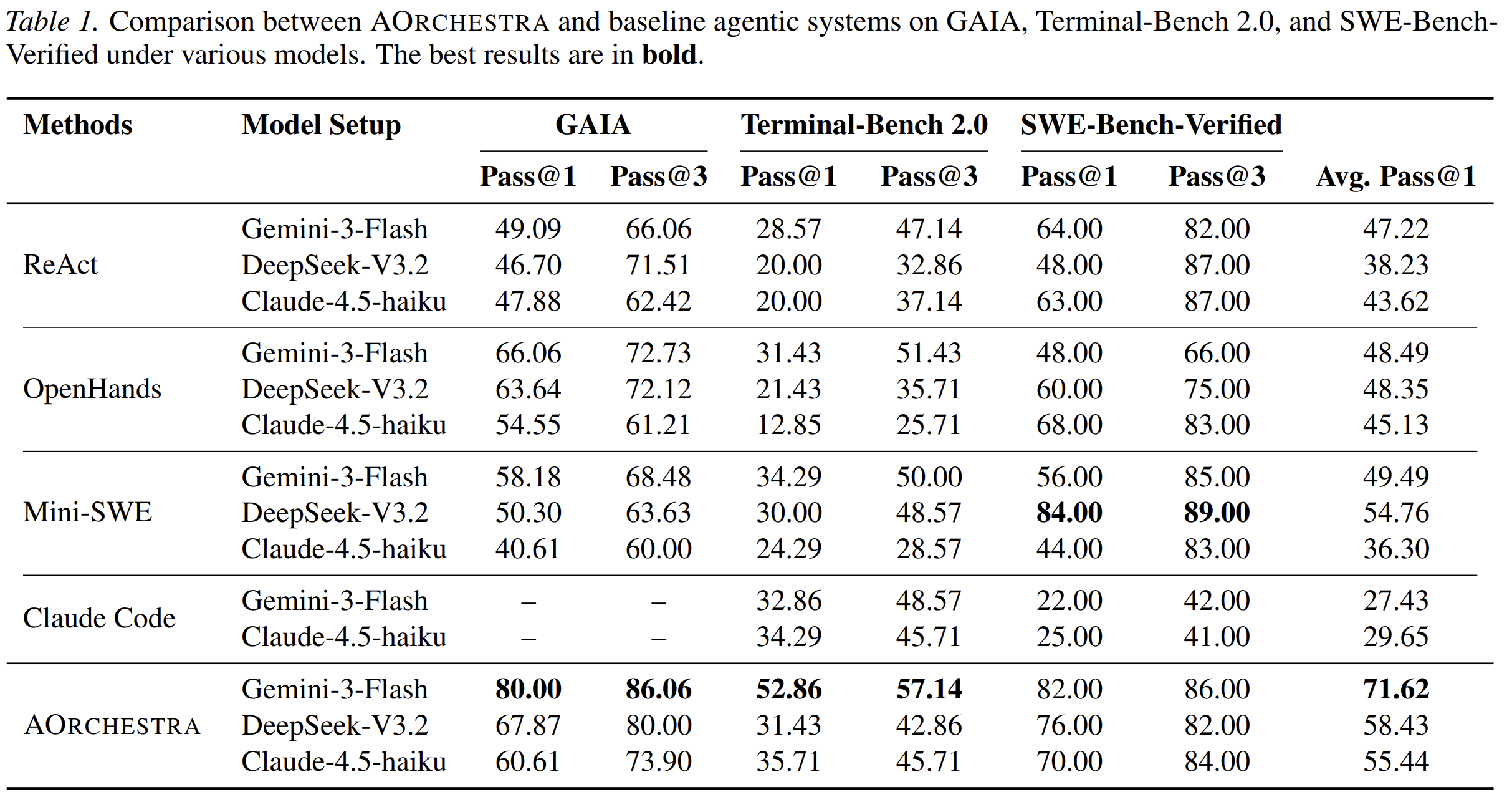
Across GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified, AOrchestra improves over representative agentic baselines. The paper also shows that orchestration can be learned through supervised fine-tuning and cost-aware in-context optimization.
In short: AOrchestra studies how agent systems can dynamically create specialized sub-agents instead of relying on fixed roles.
2. AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
- Paper: AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
- Authors: Yifan Wu, Yiran Peng, Yiyu Chen, Jianhao Ruan, Zijie Zhuang, Cheng Yang, Jiayi Zhang, Man Chen, Yenchi Tseng, Zhaoyang Yu, Liang Chen, Yuyao Zhai, Bang Liu, Chenglin Wu, Yuyu Luo
- Institutions / Companies: The Hong Kong University of Science and Technology (Guangzhou); DeepWisdom; Peking University; Université de Montréal & Mila
AutoWebWorld addresses a key bottleneck in training and evaluating web GUI agents: high-quality web interaction trajectories are expensive to collect and difficult to verify.
When agents interact with real websites, the true internal state of the website is usually hidden. The agent sees only rendered UI feedback, such as screenshots. This makes it difficult to know whether each step is correct. Existing pipelines often depend on human annotators or LLM judges, which are costly and inconsistent.
AutoWebWorld proposes a framework for synthesizing controllable and verifiable web environments using finite state machines. Each environment explicitly defines states, actions, transition rules, and goal conditions. Because the state transitions are known, task success can be verified programmatically rather than inferred from surface observations.
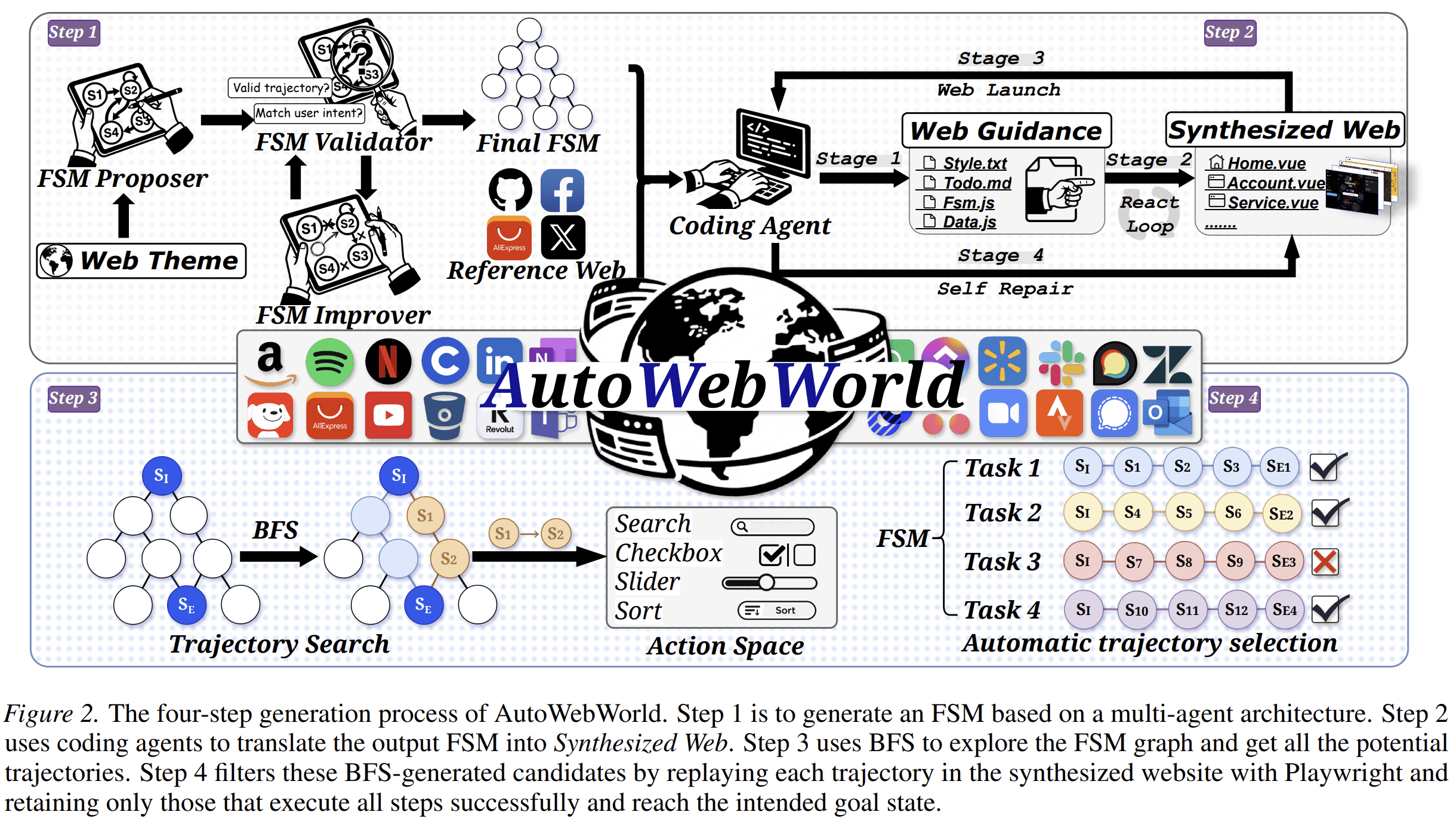
The framework uses coding agents to translate FSM specifications into interactive websites, then performs breadth-first search over the known transition graph to generate candidate trajectories. These trajectories are replayed and filtered through execution, producing verified GUI trajectories.
AutoWebWorld generates 29 diverse web environments and over 11,663 verified trajectories at a cost of only $0.04 per trajectory. Training on this synthetic data improves real-world web-agent performance. The paper also observes a scaling trend: as the amount of synthetic data increases, performance on WebVoyager and Online-Mind2Web improves consistently.
In short: AutoWebWorld creates scalable, controllable, and intrinsically verifiable web environments for training and evaluating web agents.
3. InfoPO: Information-Driven Policy Optimization for User-Centric Agents
- Paper: InfoPO: Information-Driven Policy Optimization for User-Centric Agents
- Authors: Fanqi Kong, Jiayi Zhang, Mingyi Deng, Chenglin Wu, Yuyu Luo, Bang Liu
- Institutions / Companies: Peking University, DeepWisdom, The Hong Kong University of Science and Technology (Guangzhou), Université de Montréal & Mila
InfoPO studies a fundamental problem in user-facing agents: real user requests are often underspecified. A user may provide an incomplete goal, omit key constraints, or express a preference only implicitly. In these cases, the agent should not immediately act on incomplete information. It should ask questions that reveal useful information for future decisions.
Most multi-turn reinforcement learning methods optimize agents using trajectory-level rewards. This creates a credit-assignment problem: if an agent eventually succeeds or fails, it is difficult to know which earlier interaction turns were actually useful.
InfoPO addresses this by introducing a turn-level counterfactual information-gain reward. The method measures how much a user’s feedback changes the agent’s next action distribution compared with a masked-feedback counterfactual. In other words, it asks whether a specific interaction turn produced information that meaningfully changed what the agent would do next.
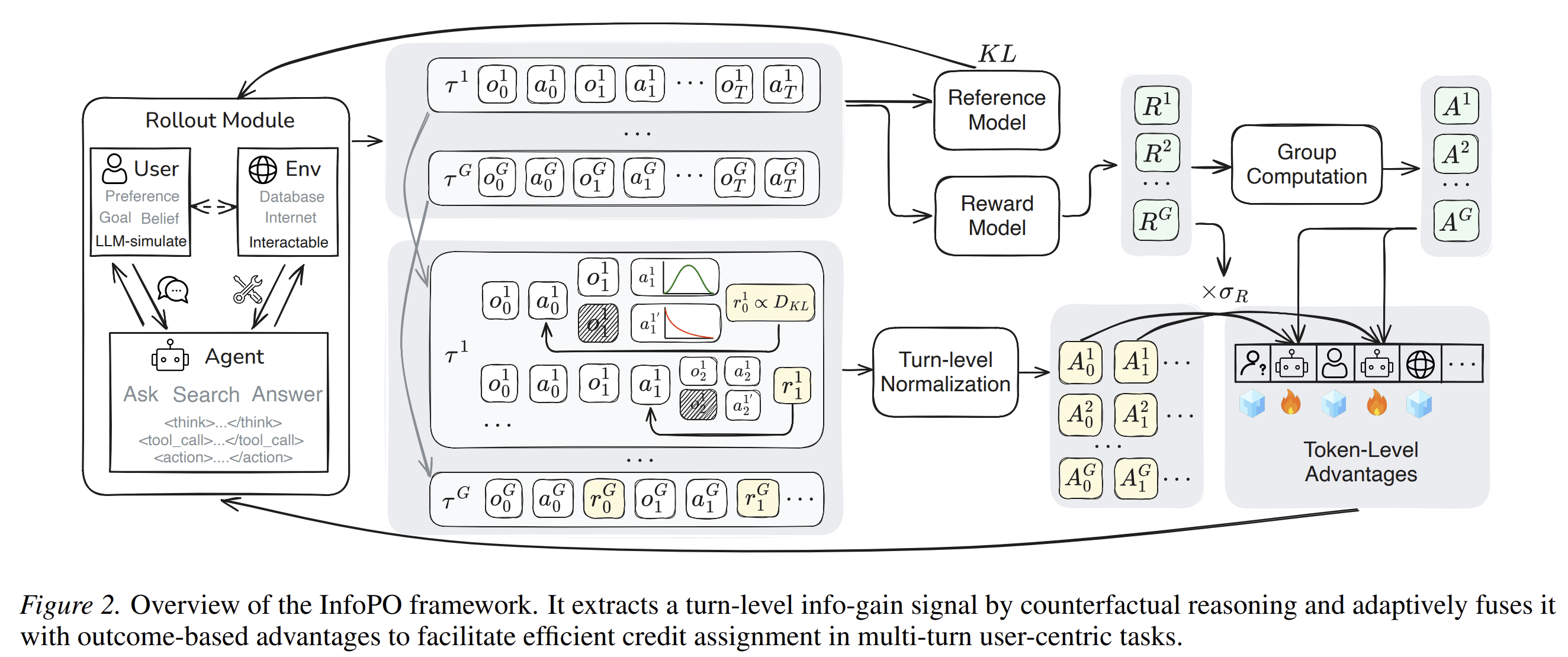
The paper further combines this information-gain signal with outcome-based rewards through an adaptive variance-gated fusion mechanism. This allows the agent to learn from useful intermediate interactions while still optimizing for final task success.
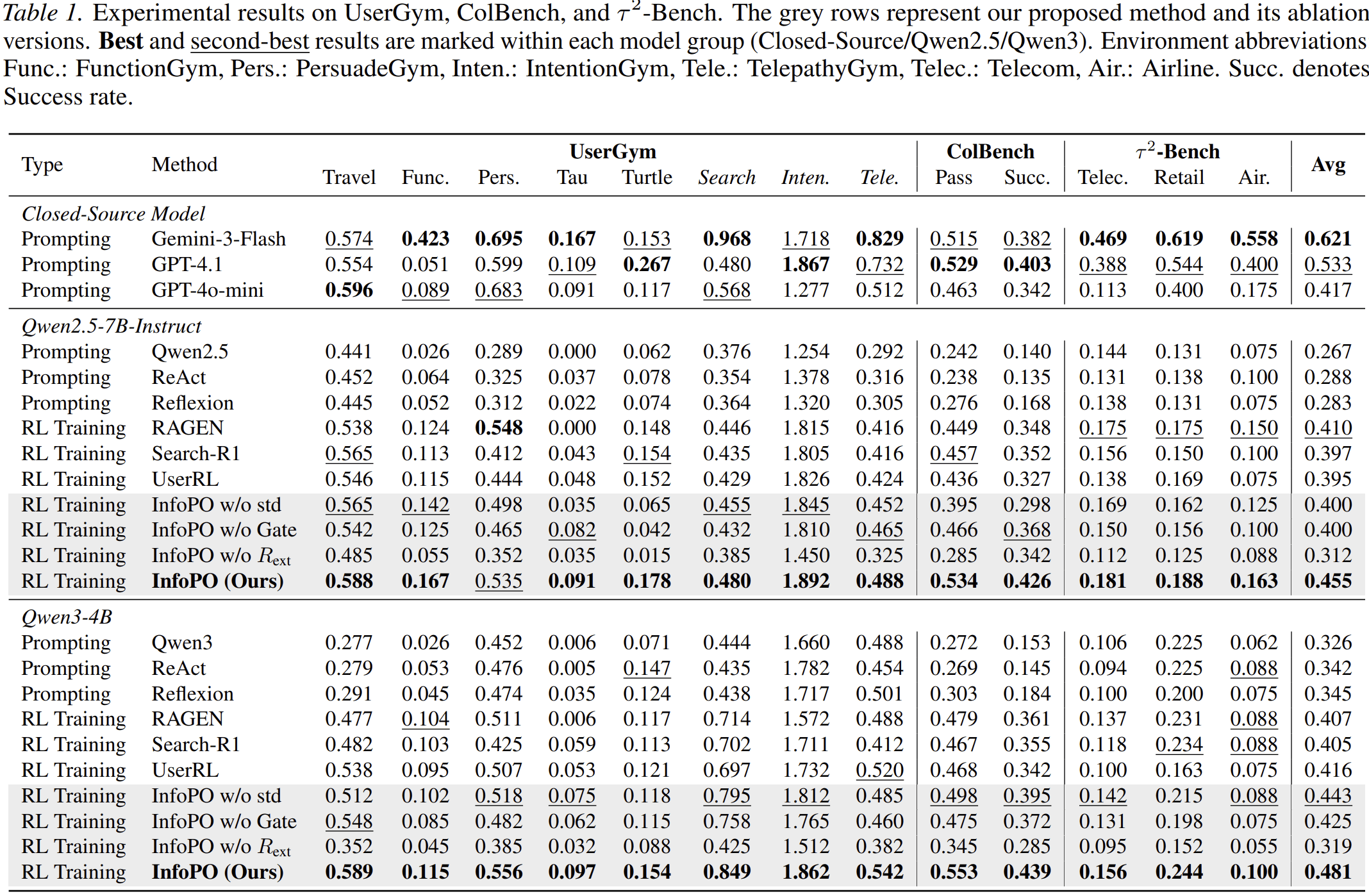
Across benchmarks including UserGym, ColBench, and τ²-Bench, InfoPO improves performance over prompting and multi-turn RL baselines. It also shows robustness under user-simulator shifts and generalization to environment-interactive tasks.
In short: InfoPO helps user-centric agents learn when and how to ask useful questions, rather than optimizing only for final answers.
4. InteractComp: Evaluating Search Agents With Ambiguous Queries
- Paper: InteractComp: Evaluating Search Agents With Ambiguous Queries
- Authors: Mingyi Deng, Lijun Huang, Yani Fan, Jiayi Zhang, Fashen Ren, Jinyi Bai, Fuzhen Yang, Dayi Miao, Zhaoyang Yu, Yifan Wu, Yanfei Zhang, Fengwei Teng, Yingjia Wan, Song Hu, Yude Li, Xin Jin, Conghao Hu, Haoyu Li, Qirui Fu, Tai Zhong, Xinyu Wang, Xiangru Tang, Nan Tang, Chenglin Wu, Yuyu Luo
- Institutions / Companies: DeepWisdom; The Hong Kong University of Science and Technology (Guangzhou); Renmin University of China; University of California, Los Angeles; Agent Universe; McGill University; Yale University
InteractComp studies a practical weakness in current search agents: they often assume that user queries are complete and unambiguous. In real use, this assumption is frequently false.
Users often begin with short, incomplete, or ambiguous queries. A search agent may need to ask a clarification question before it can retrieve the right information. However, most search benchmarks evaluate agents as if the user’s intent were already fully specified.
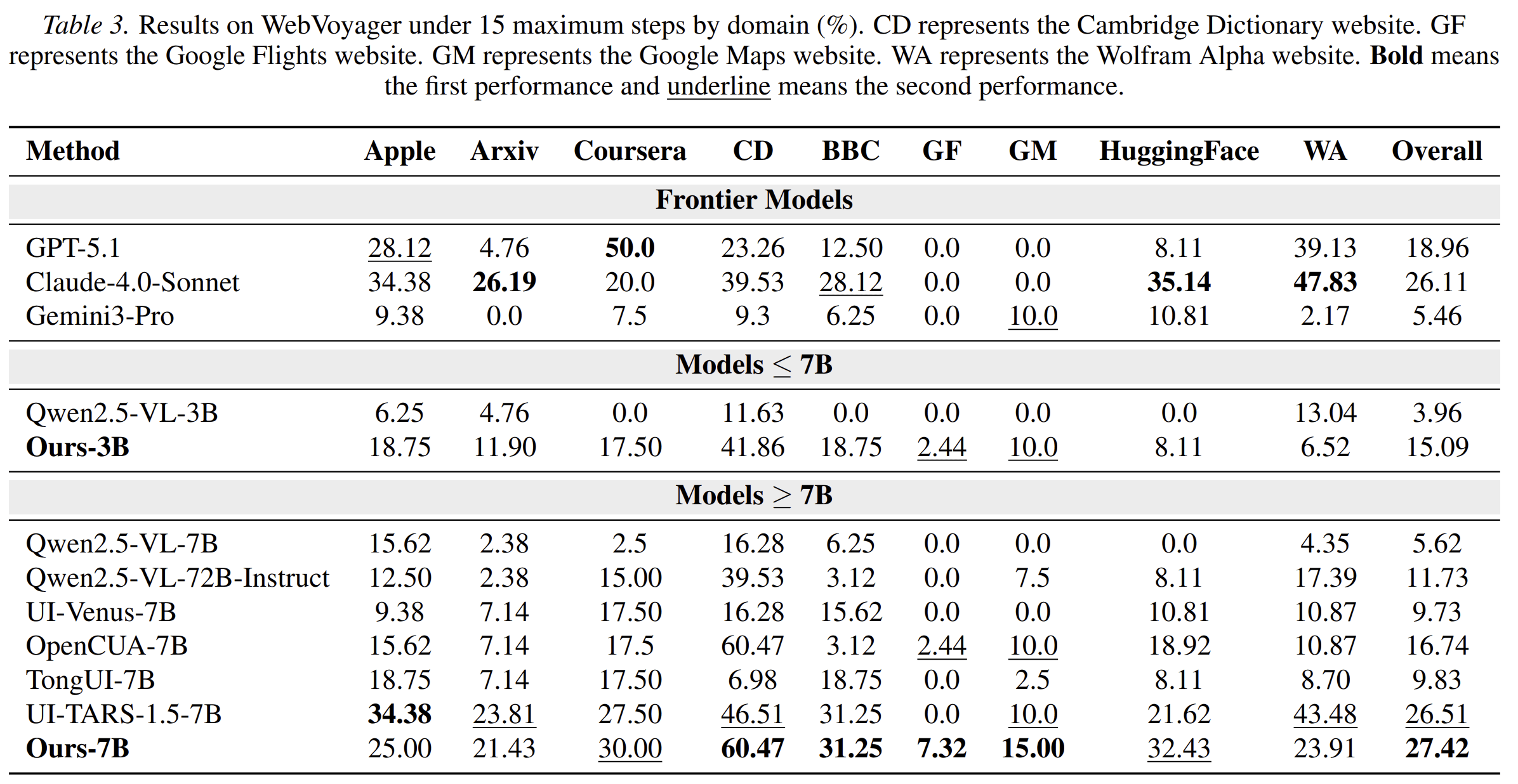
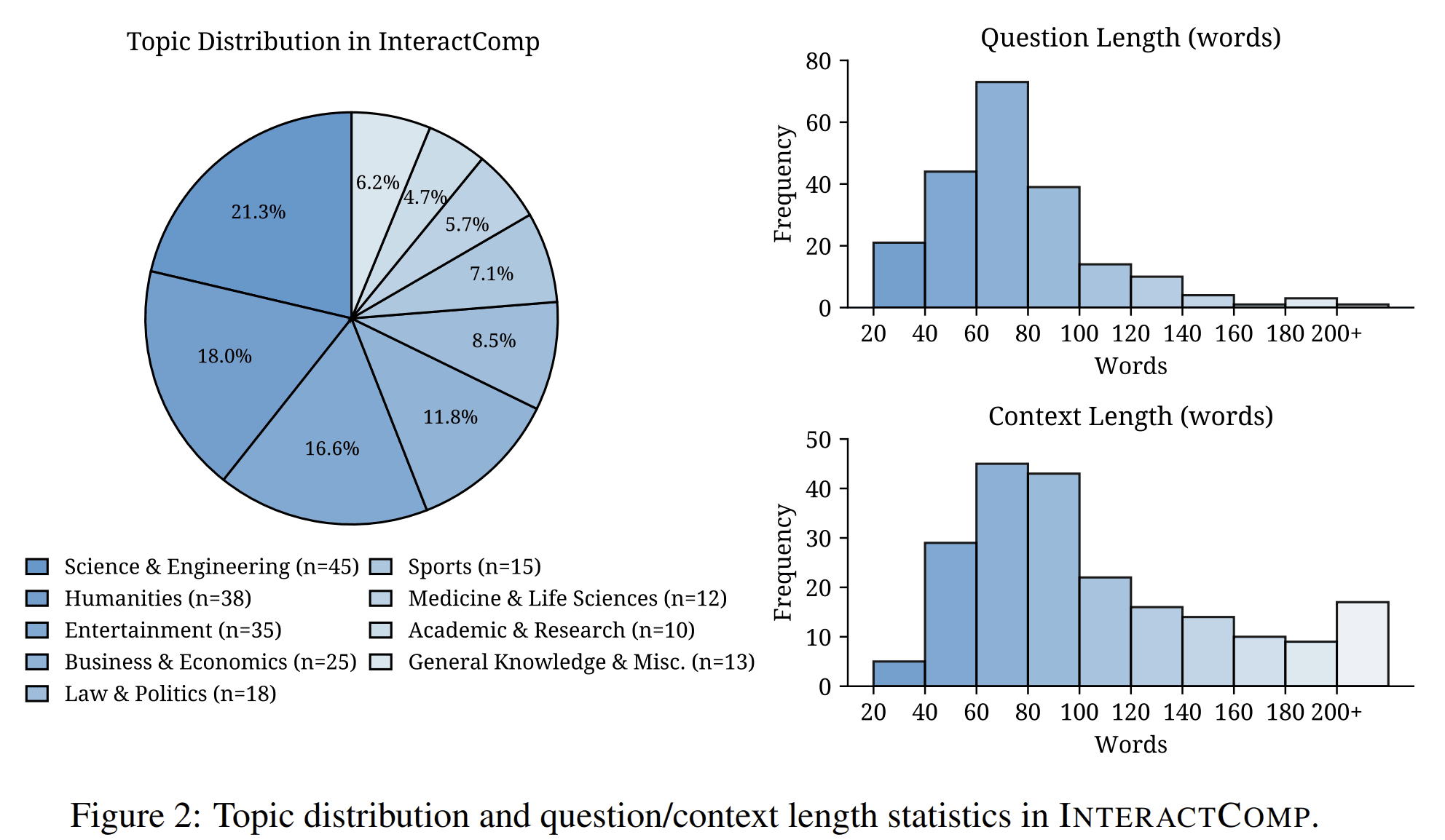
InteractComp introduces a benchmark for evaluating whether search agents can recognize ambiguity and interact to resolve it. The benchmark contains 210 expert-curated questions across 9 domains, constructed through a target-distractor methodology. Each question is designed so that ambiguity cannot be resolved reliably without interaction.
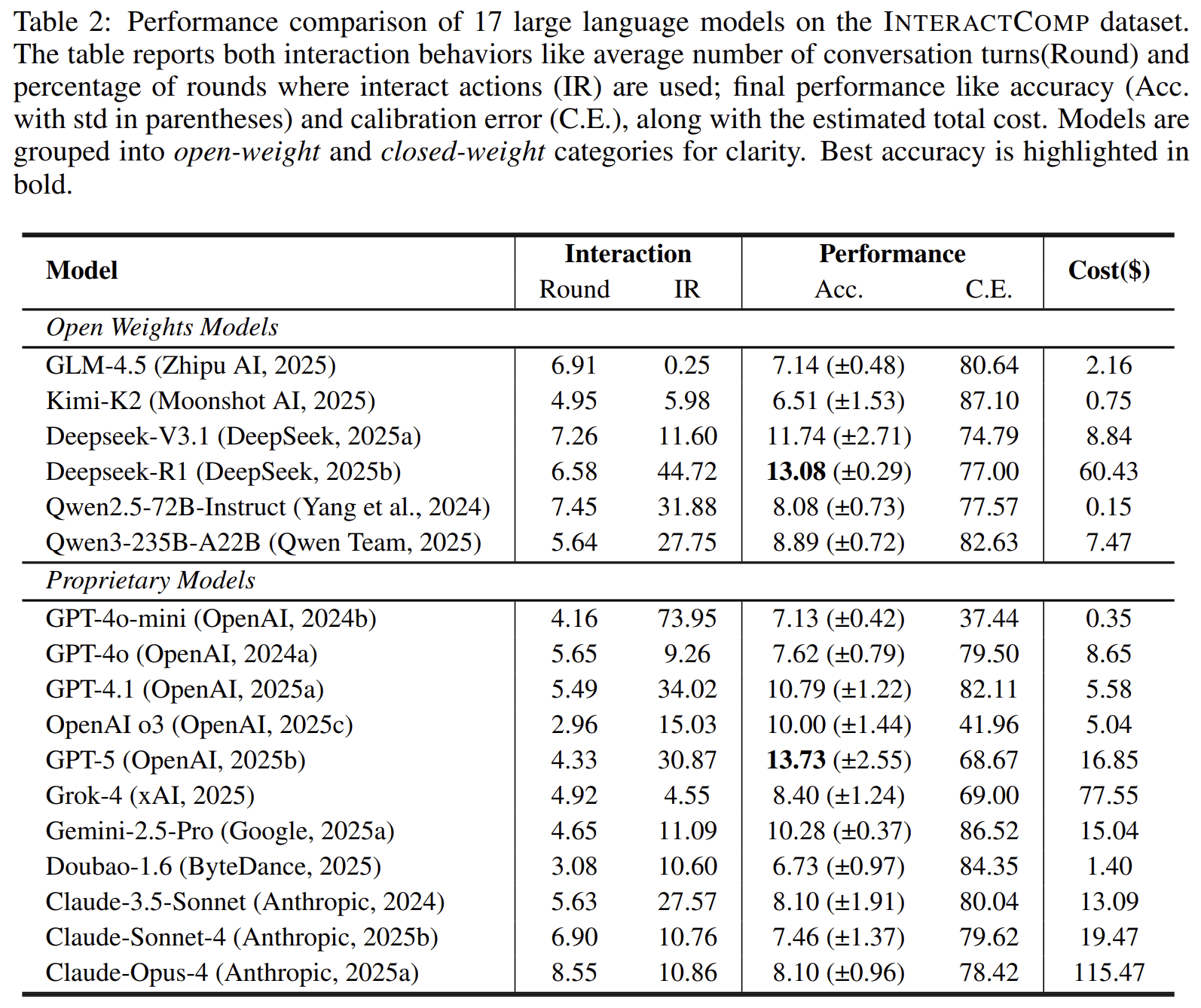
The evaluation reveals a sharp gap. The best model achieves only 13.73% accuracy under ambiguous queries, even though it reaches 71.50% accuracy when given complete context. This suggests that the problem is not simply lack of knowledge or reasoning ability. Instead, many agents are overconfident and fail to ask for clarification when they should.
The paper also shows that forced interaction can dramatically improve performance, indicating that current models may have latent interactive capability that their default strategies fail to use.
In short: InteractComp evaluates whether search agents can detect ambiguous user intent and ask useful clarification questions during search.
5. MindFlow: Mind Supernet Powered Thinking Flows for Research Idea Innovation
- Paper: MindFlow: Mind Supernet Powered Thinking Flows for Research Idea Innovation
- Authors: Mengdi Liu, Wenjue Chen, Wenyue Chen, Cheng Yang, Fanqi Kong, Zhangyang Gao, Xiaoxue Cheng, Yiheng Li, Yujian Yuan, Keliang Li, Hong Chang, Shiguang Shan, Chenglin Wu
- Institutions / Companies: Institute of Computing Technology, Chinese Academy of Sciences, University of Chinese Academy of Sciences, DeepWisdom, Peking University, Shanghai Artificial Intelligence Laboratory, Renmin University of China
MindFlow studies research idea generation, a task that is both open-ended and multi-objective. A good research idea must identify a meaningful problem, propose a plausible method, and balance novelty, significance, effectiveness, and feasibility.
Existing LLM-based ideation systems often rely on fixed prompting pipelines or manually designed agent workflows. These pipelines can work in narrow settings, but they are not flexible enough for different topics, domains, or evaluation objectives.
MindFlow proposes a different view: the thinking process itself should be explicit, controllable, and optimizable. It formulates research ideation as a graph-structured thinking flow composed of modular thinking operators, including divergent thinking, convergent thinking, critical thinking, analogical thinking, counterfactual thinking, and constraint-driven thinking.
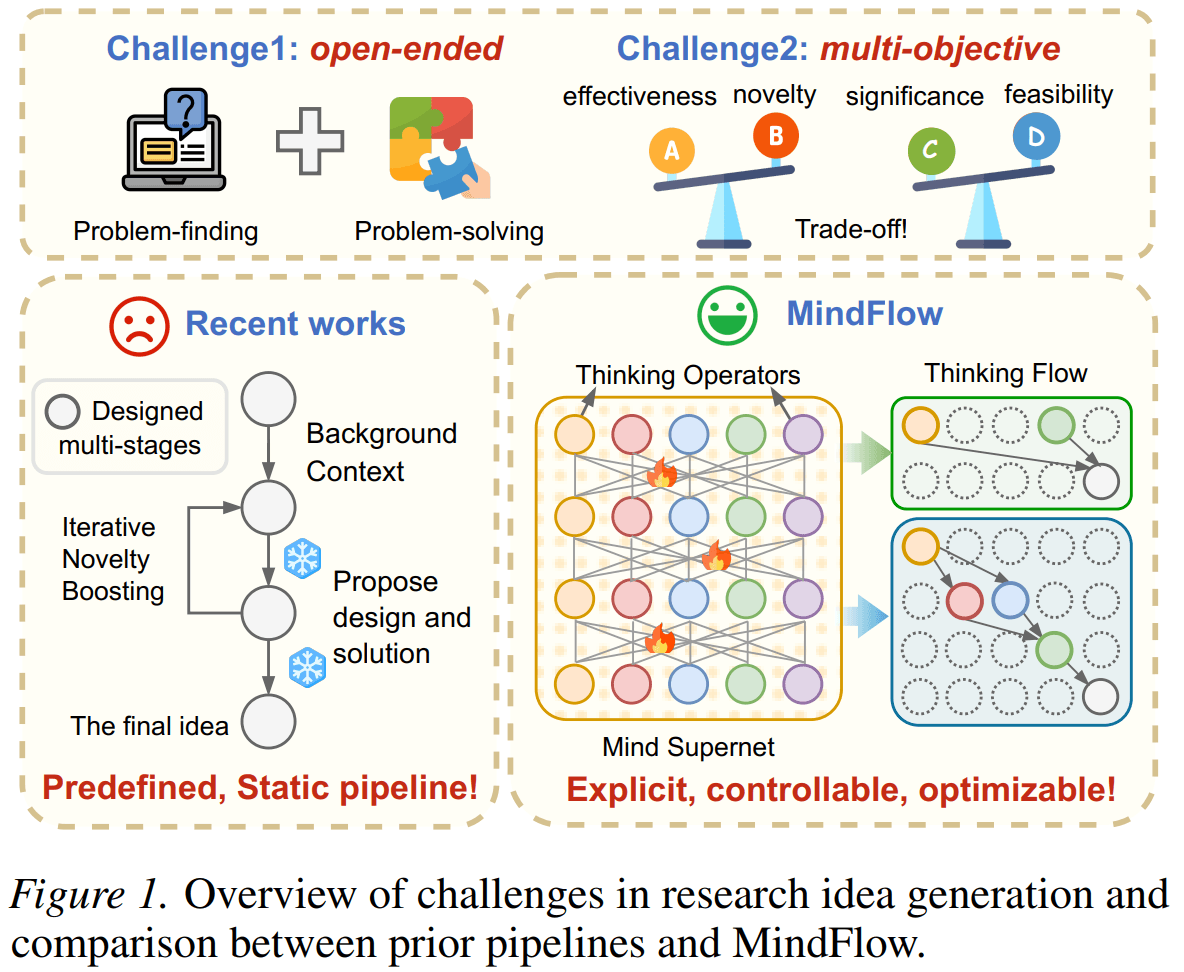
These thinking flows are modeled by a probabilistic mind supernet. Given a research topic, a controller dynamically samples a topic-specific flow and executes it to generate candidate research ideas. The controller is optimized through tournament-based relative ranking, which provides comparative feedback for open-ended idea generation.
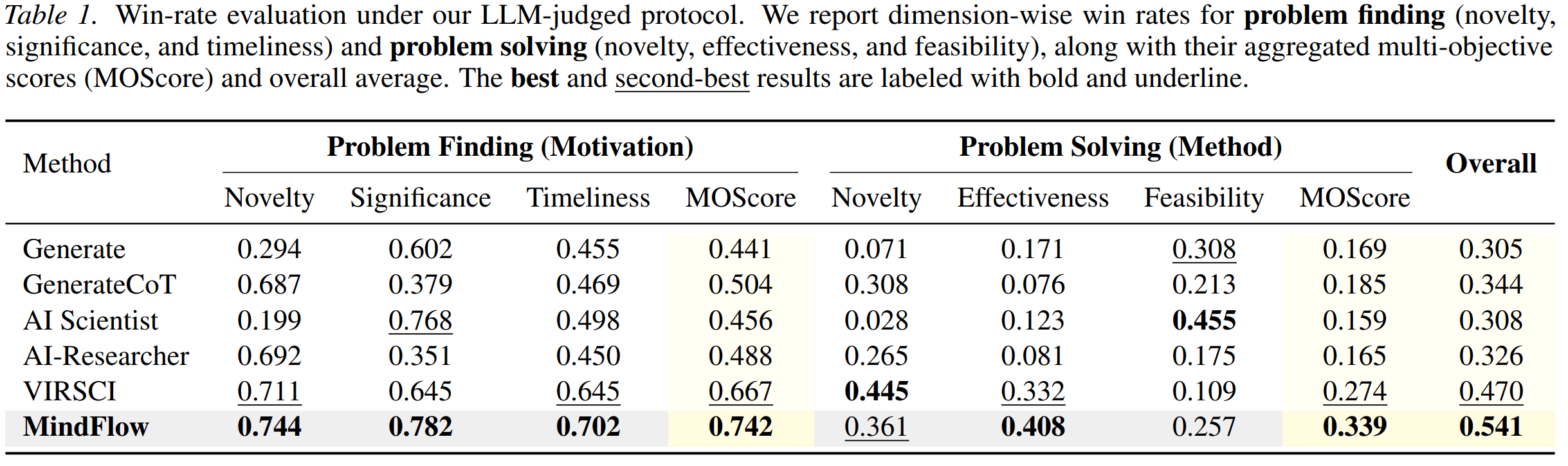
The paper also introduces an evaluation protocol that jointly assesses problem finding and problem solving. Experiments show that MindFlow improves idea quality across multiple dimensions, including novelty, diversity, effectiveness, and feasibility.
In short: MindFlow turns research ideation from a fixed prompt pipeline into an optimizable process over structured thinking flows.
A Shared Research Direction
Although these five papers study different problems, they are connected by a common goal: building better agent systems.
Each paper addresses a different layer of the agent stack:
| Paper | Main Problem | Agent Capability |
|---|---|---|
| InfoPO | How should agents learn from user interaction? | User-centric interaction |
| MindFlow | How should agents generate open-ended ideas? | Structured reasoning and ideation |
| AOrchestra | How should agents coordinate complex tasks? | Dynamic sub-agent orchestration |
| InteractComp | How should search agents handle ambiguity? | Interactive search evaluation |
| AutoWebWorld | How should web agents be trained and evaluated? | Verifiable web environments |
Together, these works suggest that future agents need more than stronger language models. They need better interaction policies, better reasoning processes, better orchestration mechanisms, better evaluation benchmarks, and better environments for training and verification.
In this view, an agent is not just a model that responds to prompts. It is a system that can manage uncertainty, gather information, decompose work, select tools, verify progress, and adapt its behavior to the task.
Looking Ahead
Having five papers accepted to ICML 2026 is an important milestone for our team.
More importantly, these papers reflect the direction we are pursuing: building agents that are adaptive, interactive, modular, and evaluatable.
We are grateful to all researchers, collaborators, institutions, universities, and industry partners involved in these works. We look forward to sharing more details at ICML 2026 in Seoul.
