MiniMax has officially released MiniMax-M2.5, positioning it as a “real-world productivity” model tuned for coding, tool use + search, and office deliverables—not just chat. The launch post is unusually dense with operational numbers: benchmark scores, end-to-end runtimes, token budgets per task, pricing down to “dollars per hour,” and a clear statement that two variants ship with identical capability but different throughput.
This article stays close to what’s measurable and documented. Where MiniMax provides hard data, we use it. Where third parties add context, we label it as such. Where information is missing (and some is), we call it out instead of filling the gap with guesswork.
If you want the source-of-truth starting point, read MiniMax’s own release note first, then come back: MiniMax’s announcement “MiniMax M2.5: Built for Real-World Productivity” lives at the official MiniMax News page.
What MiniMax-M2.5 is (in one sentence)
MiniMax-M2.5 is a long-context (204,800 tokens) text model optimized for agent-style work—planning, searching, calling tools, and producing deliverables—trained with large-scale reinforcement learning across hundreds of thousands of real-world environments as described in MiniMax’s release note.
MiniMax ships it in two throughput configurations:
-
M2.5 at ~50 tokens/sec throughput (per the release post’s pricing/throughput section)
-
M2.5-Lightning (also surfaced in docs as
MiniMax-M2.5-highspeed) at ~100 tokens/sec throughput
MiniMax states the two versions are “identical in capability” and differ only in speed, with both supporting caching.
The headline numbers (from MiniMax)
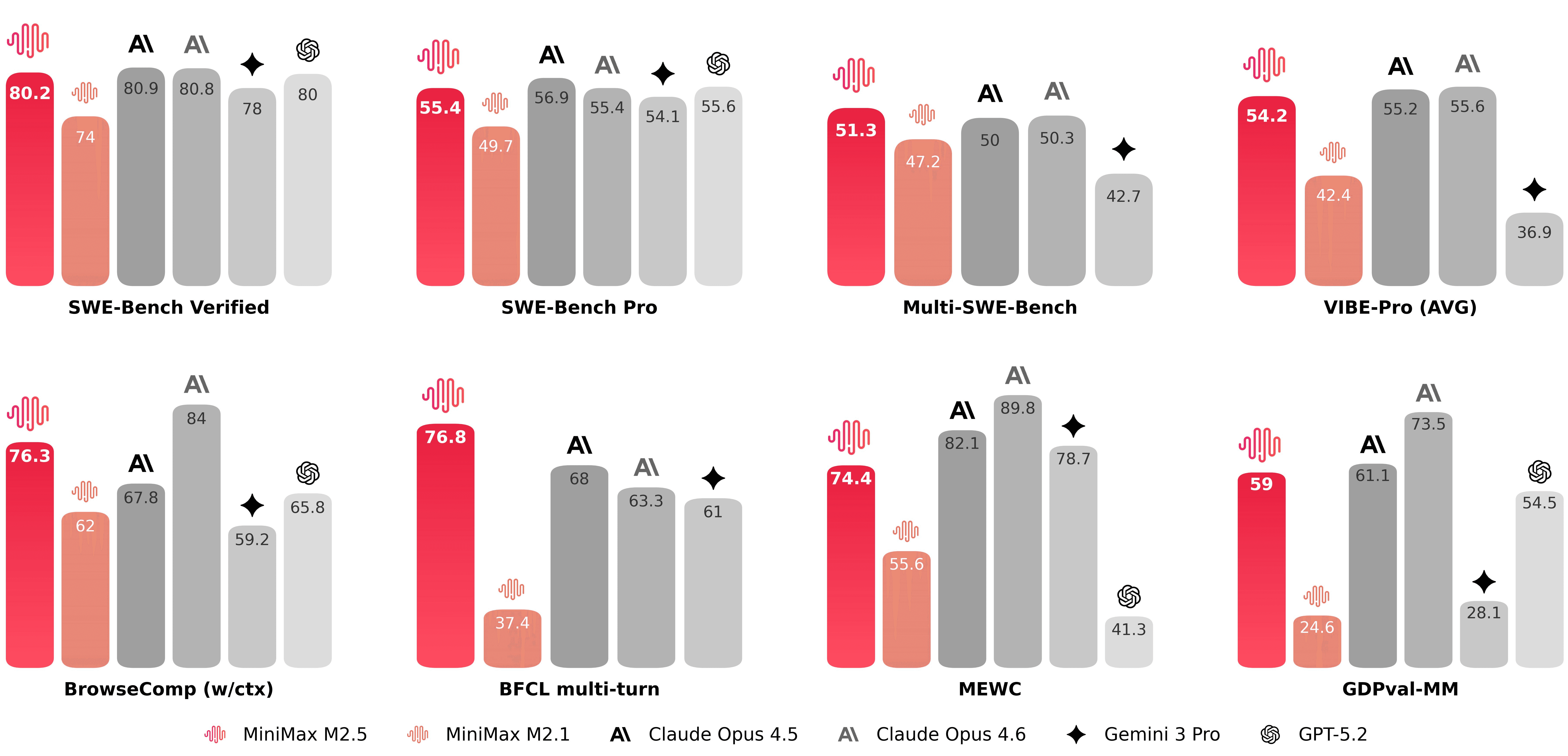
MiniMax leads with three benchmark scores and a runtime claim:
-
80.2% on SWE-Bench Verified
-
51.3% on Multi-SWE-Bench
-
76.3% on BrowseComp (with context management)
All three are explicitly stated in MiniMax’s release post.
MiniMax also claims M2.5 completes SWE-Bench Verified 37% faster end-to-end than M2.1, and says the runtime is roughly on par with Claude Opus 4.6 in their comparison.
Those are the claims. What makes this release different is that MiniMax provides the mechanics behind the “37% faster” statement instead of leaving it as a vague speed boast.
End-to-end runtime, token budgets, and what “37% faster” actually means
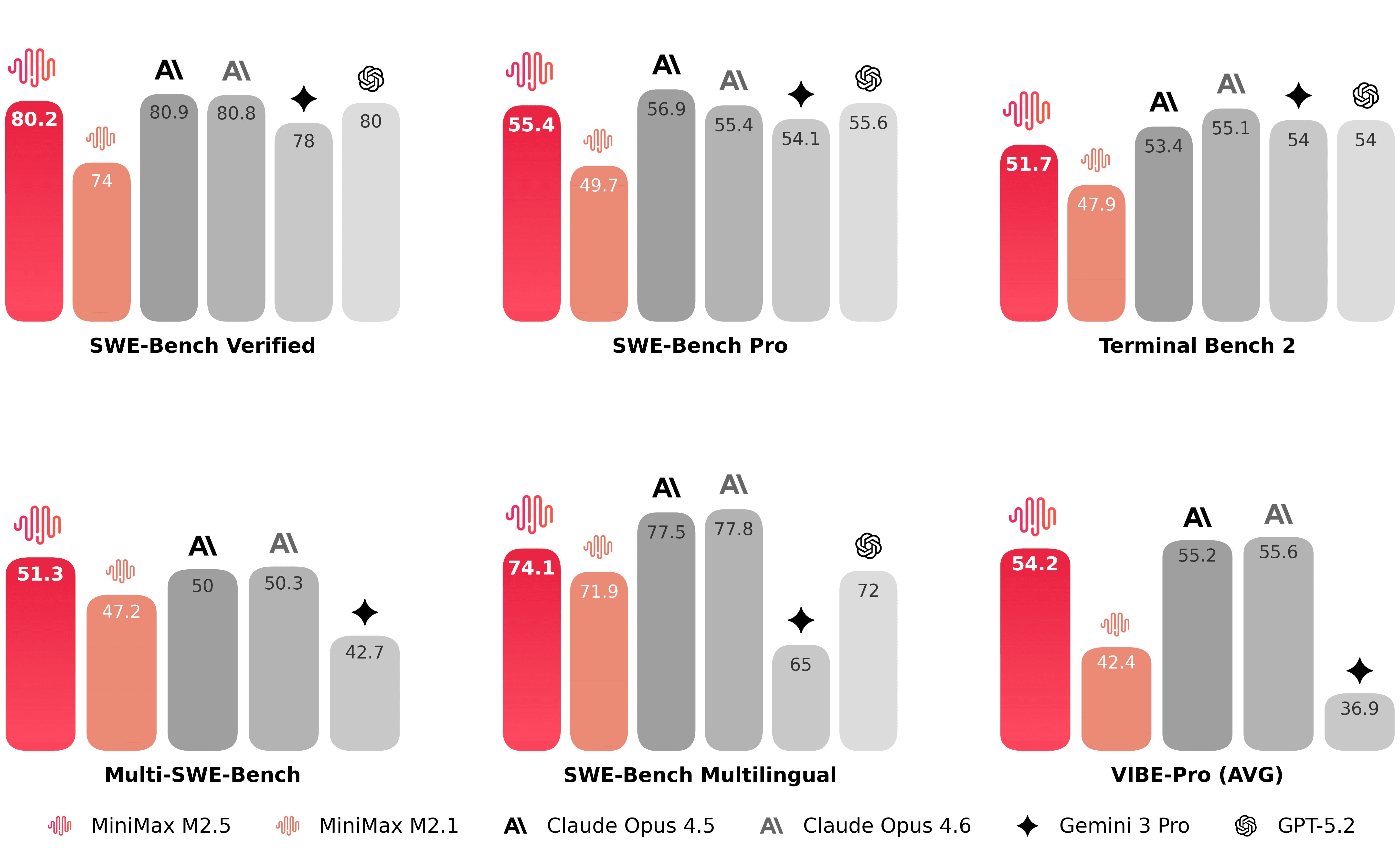
MiniMax reports (on SWE-Bench Verified, in their internal harness) that:
-
M2.5 uses 3.52M tokens per task on average
-
M2.1 used 3.72M tokens per task
-
Runtime fell from 31.3 minutes → 22.8 minutes
-
That runtime reduction is the cited 37% speed improvement
-
They attribute part of this to capabilities like parallel tool calling and more efficient decomposition
All of these values appear in the “Efficiency” section of MiniMax’s release note.
Two implications matter if you build agents for a living:
-
“Tokens per second” is not the real bottleneck once tool calls are involved; task decomposition and search/tool strategy dominates.
-
Token efficiency at the trajectory level is a first-order metric. MiniMax is explicitly training for it, then reporting it.
Context window and throughput: what’s documented in the API docs
MiniMax’s developer docs state a 204,800-token context window for the text lineup including M2.5. In the “Text Generation” guide, the supported models table lists:
-
MiniMax-M2.5: context window 204,800, output speed approximately 60 tps -
MiniMax-M2.5-highspeed: context window 204,800, output speed approximately 100 tps
That’s a clean, implementer-friendly spec you can actually use for sizing prompts and controlling truncation policies.
If you’re building workflows that depend on long-horizon state, 204.8k is not just “bigger context.” It changes your error modes:
-
You can afford to keep more raw evidence in-context before you need summarization.
-
You can push more of the retrieval problem into “context management” rather than “hard truncation.”
-
But you also increase the surface area for context rot if you don’t manage history aggressively.
MiniMax is explicitly aware of this and builds around it (more on Forge and context management later).
Pricing: the rare release that gives “dollars per hour” as a first-class unit
MiniMax doesn’t only list token prices; it also translates them into continuous-run costs:
-
M2.5-Lightning (100 tps): $0.30 / 1M input tokens and $2.40 / 1M output tokens
-
M2.5 (50 tps): “costs half that,” meaning $0.15 / 1M input tokens and $1.20 / 1M output tokens
MiniMax further states:
-
At 100 output tokens/sec, running continuously for an hour costs $1
-
At 50 tps, it drops to $0.30/hour
-
They claim both versions support caching
All of this is in MiniMax’s release post under “Cost.”
You don’t need to agree with their framing to appreciate the engineering message: MiniMax is pricing M2.5 as if they want it used as infrastructure, not as an occasional premium query. That changes what’s rational to build:
-
You can run longer agent loops without turning every retry into a budget discussion.
-
You can parallelize and explore more branches (with discipline).
-
You can do verification-heavy workflows (tests, evals, multiple scaffolds) without paying a “luxury tax” for being careful.
A note on provider pricing differences (don’t ignore this)
Third-party routers may present different price lines for “M2.5.” For example, the OpenRouter model card lists minimax/minimax-m2.5 at $0.30/M input and $1.20/M output with 204,800 context, and links to model weights on Hugging Face. That doesn’t match MiniMax’s own pairing for a single first-party variant (MiniMax’s official pairings are 0.15/1.20 or 0.30/2.40). This isn’t a scandal; it’s just a reminder: token economics are provider-specific. If cost is part of your design constraints, treat pricing as runtime configuration, not a blog-table fact.
Coding: what M2.5 is trained on, and how MiniMax is evaluating generalization
MiniMax makes two strong, testable statements about training coverage and coding behavior:
-
Language coverage and environments
-
M2.5 was trained on over 10 languages (MiniMax lists Go, C, C++, TypeScript, Rust, Kotlin, Python, Java, JavaScript, PHP, Lua, Dart, Ruby)
-
Training occurred across more than 200,000 real-world environments
-
MiniMax positions it as covering the whole lifecycle: from “0-to-1 system design and environment setup” through code review and system testing
-
This is all in the “Coding” section of the release post.
-
Spec-first behavior
- MiniMax claims M2.5 developed a “spec-writing tendency”: it decomposes and plans structure/UI/features before coding
Whether you like the framing or not, it’s a concrete behavior pattern you can check with prompts that demand architecture and acceptance criteria.
Harness sensitivity: MiniMax is explicitly testing across different agent scaffolds
MiniMax calls out a problem many teams learn the hard way: agent performance can be scaffold-sensitive. So they test SWE-Bench Verified under different harnesses and report:
-
On Droid: 79.7 (M2.5) vs 78.9 (Opus 4.6)
-
On OpenCode: 76.1 (M2.5) vs 75.9 (Opus 4.6)
These numbers appear in the “Coding” section. The important part is not “who is 0.2 points higher.” It’s that MiniMax is treating scaffold generalization as a first-class evaluation target, and they show their work.
VIBE-Pro: internal benchmark, but the methodology is described
MiniMax says they upgraded their VIBE benchmark to a “Pro” version, increasing complexity and evaluation accuracy, and states M2.5 performs “on par with Opus 4.5” on that internal benchmark.
Internal benchmarks are not inherently untrustworthy, but they are not independently verifiable. MiniMax does help by documenting evaluation methods in the Appendix: scaffold choice, averaging over multiple runs, and notes about harness overrides.
If you’re doing serious model selection, treat VIBE-Pro as directional evidence, then replicate with your own workload tests.
Search + tool calling: what MiniMax is optimizing for
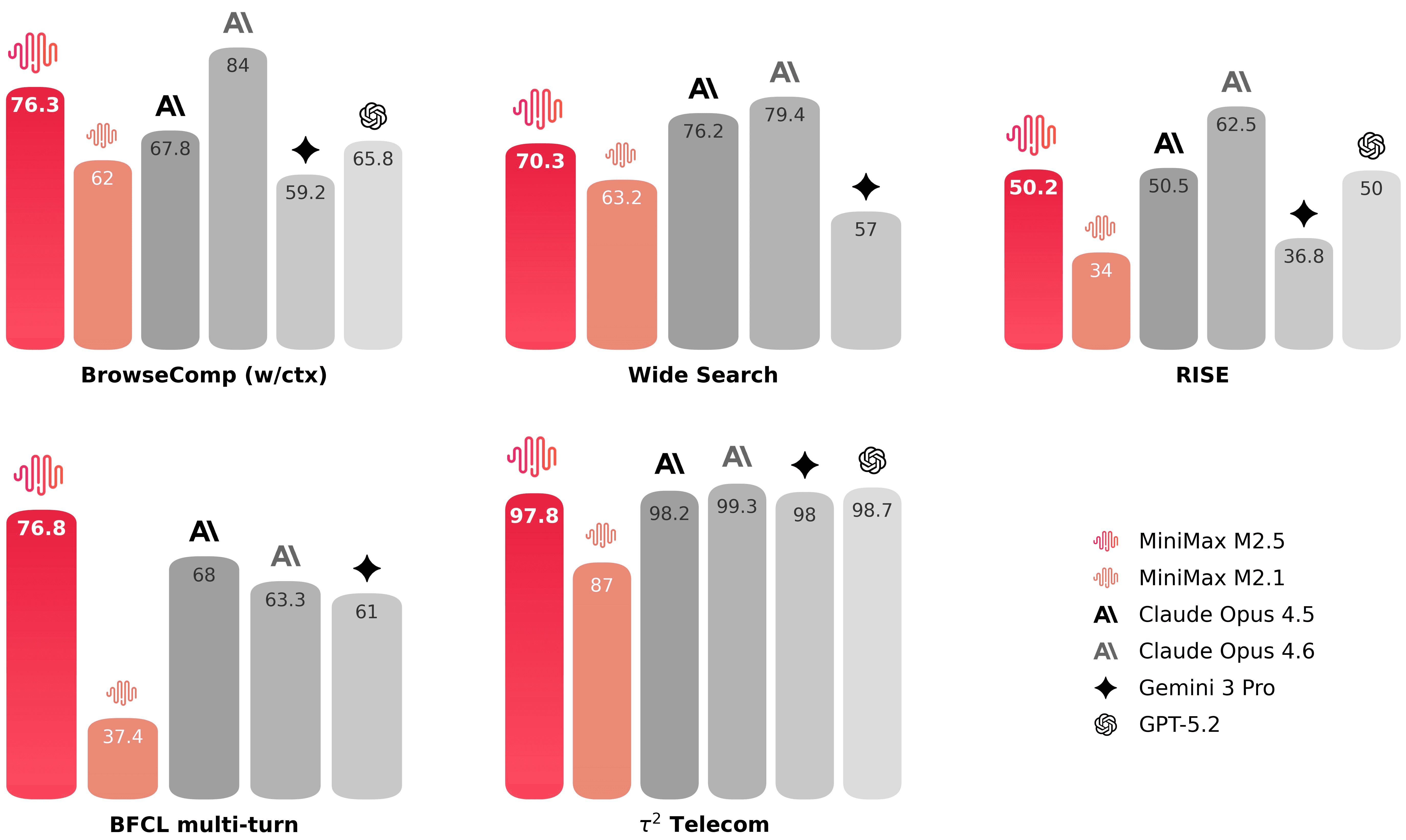
MiniMax’s release post frames tool use and search as prerequisites for autonomy, then makes three claims:
-
M2.5 achieves industry-leading performance on BrowseComp and Wide Search
-
They created an internal benchmark called RISE (Realistic Interactive Search Evaluation) for expert-level search tasks across dense webpages using Playwright tooling layered over a WebExplorer-style agent framework
-
Compared to M2.1, M2.5 uses ~20% fewer rounds across agentic tasks including BrowseComp, Wide Search, and RISE
All of these are in the “Search and Tool calling” section of the release post.
Two things to notice here if you’re building agents:
-
MiniMax is not just optimizing answer accuracy; they’re optimizing the path an agent takes (rounds, token efficiency, time).
-
They are building evaluation around “deep exploration across information-dense webpages,” which is closer to real work than “search a snippet and paraphrase it.”
This is the kind of evaluation shift that matters more than another point on a static QA dataset.
Office productivity: not “write an email,” but produce deliverables
MiniMax explicitly claims M2.5 was trained to output “truly deliverable” work products for office scenarios, with senior professionals in finance, law, and social sciences participating in data construction and evaluation criteria.
They then describe an internal evaluation framework:
- GDPval-MM, a cowork-agent evaluation using pairwise comparisons, tracking deliverable quality, professionalism of the agent trajectory, and token costs
MiniMax reports an average win rate of 59.0% vs other mainstream models in that setup.
Again: internal benchmark. But two parts are operationally useful even without full public replication:
-
They’re evaluating trajectories, not just final text.
-
They monitor token costs over the whole workflow, which is how you should evaluate agent systems if you’re not trying to fool yourself.
The training story: Forge, CISPO, and what “RL scaling” means here
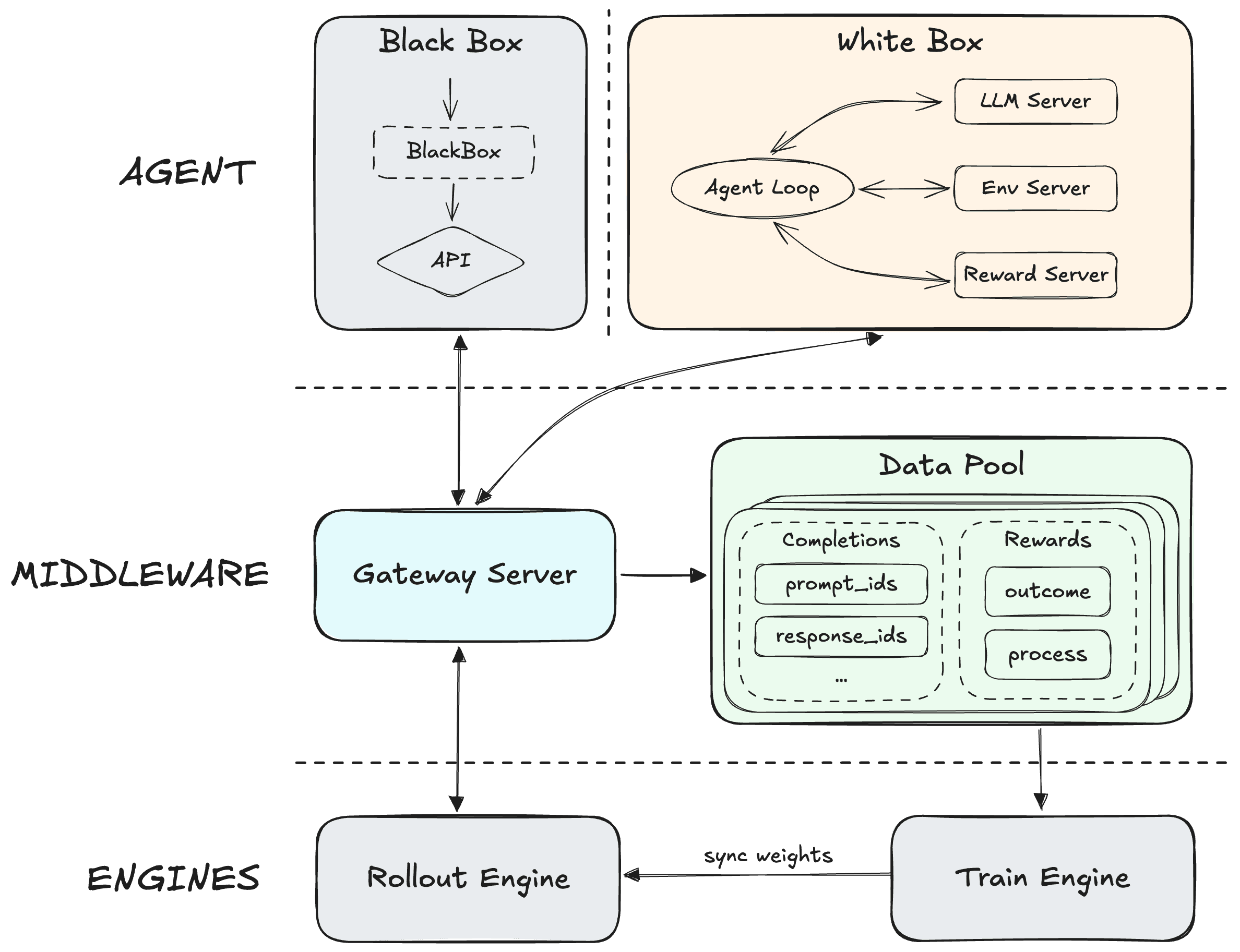
MiniMax’s release note states that M2.5 was trained with reinforcement learning in “hundreds of thousands” of environments, and that they’ve been turning much of the company’s tasks/workspaces into RL training environments. They also introduce Forge, their in-house “agent-native RL framework,” and mention:
-
decoupling the training-inference engine from the agent
-
optimizing asynchronous scheduling vs off-policyness tradeoffs
-
a tree-structured merging strategy for training samples yielding ~40x speedup
-
continued use of CISPO to stabilize MoE training
-
process rewards for long-context credit assignment
-
explicit reward components for task completion time
That’s already more detail than most releases provide. But MiniMax also published a full technical blog on Hugging Face: “Forge: Scalable Agent RL Framework and Algorithm.” If you care about how this model was made—not in marketing terms, but in systems terms—this is the document to read.
Here’s what Forge adds that is immediately relevant to practitioners.
Forge’s “impossible triangle”: throughput, stability, flexibility
Forge frames agent RL as a trilemma between:
-
system throughput
-
training stability
-
agent flexibility
This isn’t academic. At scale, agent rollouts have extreme runtime variance (seconds to hours). If you naïvely schedule rollouts, you either:
-
waste compute due to stragglers and head-of-line blocking
-
or you drift your training distribution (easy tasks finish first; the model learns on a skewed stream)
Forge introduces concrete engineering and algorithmic solutions: windowed scheduling, prefix merging, and reward shaping that accounts for completion time.
Context management as a first-class action (not a hack)
A notable Forge idea is treating Context Management (CM) as part of the RL interaction loop instead of a purely inference-time scaffold trick. Forge describes “context rot” and “inference-training mismatch” as real failure modes: when CM is applied only at inference time, the distribution shift can degrade performance.
Forge’s approach: embed CM into training so the model learns robust reasoning patterns under context transitions.
This directly matches MiniMax’s claims about BrowseComp “with context management” and about fewer search rounds: if CM is inside training, you can train for strategies that minimize tool/search calls and preserve task-critical state.
Prefix Tree Merging: 40x speedup by killing redundant prefills
Forge describes heavy redundancy in agent trajectories: shared prefixes across multi-turn samples, especially under context management. Their Prefix Tree Merging approach merges shared prefixes and claims ~40x training speedup while keeping mathematical equivalence to standard loss computation.
This is not a model-behavior claim; it’s a training-systems claim. But it matters because it partially explains how MiniMax can scale RL across very long contexts and many environments without drowning in compute waste.
Extreme inference acceleration: speculative decoding + KV cache pooling
Forge also discusses generation acceleration tactics:
-
Multi-Token Prediction (MTP)-based speculative decoding
-
Prefill/Decode disaggregation
-
global KV cache pool and cost-aware routing
If you’re thinking “that’s a serving stack story, not a model story,” you’re right—and that’s exactly why it matters. Agent performance is end-to-end. A strong policy trapped in a slow stack is a weak product.
Suggested image placement (training system)
Forge includes diagrams hosted on Hugging Face’s CDN; you can embed them in a blog without self-hosting.

If you want an architecture diagram or system figure, browse the same Forge post on Hugging Face and select a diagram that fits your layout.
API integration: Anthropic-compatible and OpenAI-compatible endpoints
MiniMax’s docs are unusually practical: they provide two compatibility layers so you can drop M2.5 into existing stacks.
Anthropic API compatibility (recommended by MiniMax)
MiniMax provides an Anthropic-format endpoint that works with the official Anthropic SDK. The docs specify:
-
ANTHROPIC_BASE_URL=https://api.minimax.io/anthropic -
models supported include
MiniMax-M2.5andMiniMax-M2.5-highspeed -
messages support text + tool calls, but no image/document input
-
crucial requirement: for multi-turn tool use, you must append the complete assistant content blocks (thinking/text/tool_use) to preserve reasoning continuity
This is documented in the “Compatible Anthropic API” reference page.
If you already have an Anthropic integration, the important part is not the environment variables—it’s the semantics: preserve the full assistant message including thinking/tool content blocks, or you will silently break tool-call continuity.
OpenAI API compatibility
MiniMax also supports an OpenAI-format endpoint:
-
OPENAI_BASE_URL=https://api.minimax.io/v1 -
It provides a way to split thinking into a structured field (
reasoning_details) via an extra body parameter (reasoning_split=True) -
The docs note constraints: temperature range (0.0, 1.0],
nonly supports 1, and image/audio inputs are not supported
This is on the “Compatible OpenAI API” reference page.
A small but important engineering detail: MiniMax notes that for “native OpenAI API” calls, the content may contain <think> tag content that must be preserved in conversation history. If you have middleware that strips tags or sanitizes content, you can degrade performance without noticing.
Using M2.5 in coding tools (Claude Code, Cursor, OpenCode, Droid, Zed)
MiniMax’s “M2.5 for AI Coding Tools” guide is a long, tool-by-tool integration list. What’s worth pulling into a technical overview is the pattern:
-
For Anthropic-ecosystem tools (Claude Code, Droid), you can point the base URL to MiniMax’s Anthropic-compatible endpoint and set the model to
MiniMax-M2.5. -
For OpenAI-ecosystem tools (Cursor, Zed, TRAE), you can point the base URL to MiniMax’s OpenAI-compatible endpoint and use
MiniMax-M2.5as the model name.
The guide includes concrete config snippets and also warns about environment-variable conflicts (ANTHROPIC_AUTH_TOKEN, OPENAI_API_KEY, etc.). Those warnings are not noise; they’re the difference between “it works” and “it fails in production with a phantom key.”
If you want a vendor-independent third-party confirmation that this model is being wired into mainstream infra, Vercel’s changelog notes that MiniMax M2.5 is available on AI Gateway, and shows the exact model identifier minimax/minimax-m2.5 for use with the Vercel AI SDK.
Open weights and local deployment: what MiniMax claims, and what’s linkable
MiniMax’s models page explicitly says model weights have been open-sourced on Hugging Face and recommends vLLM or SGLang for deployment. It also states M2.5 has been open-sourced on Hugging Face and GitHub for private cluster deployment and fine-tuning.
OpenRouter’s model card links directly to the M2.5 weights page on Hugging Face as “Model weights.”
We are not reproducing the full weights spec here because access to the Hugging Face model page may vary by region and automated scraping constraints, but the existence of the link is concrete and useful:
-
MiniMax’s product page: open weights claim
-
OpenRouter: model weights link target
If your decision depends on license terms, don’t rely on news coverage. Read the actual repository license and usage terms on the weights page you intend to download.
Independent measurement and market context (useful, but secondary)
A serious technical write-up should separate first-party claims from third-party measurement. Here are two credible third-party data points you can use as context:
-
Artificial Analysis lists MiniMax-M2.5 as an “open weights model,” provides an “Intelligence Index” score and a measured output speed, and reports a 205k context window in their format.
-
Vercel states M2.5 is available through AI Gateway and describes its “plan then build” behavior in a deployment context.
-
VentureBeat published a cost/performance summary and discusses MoE architecture and CISPO/Forge (as a report). Treat this as reporting, not as a primary spec.
Use these sources to triangulate, not to replace the MiniMax docs.
What MiniMax disclosed—and what it didn’t
MiniMax’s M2.5 release is unusually specific about:
-
benchmark scores and evaluation scaffolds
-
token budgets per task and runtime
-
throughput targets and pricing
-
the RL framework design goals and many of its components
But there are still gaps that matter for engineering due diligence:
-
Full public reproduction packages for the headline scores (code + exact harness configs + prompts) are not fully spelled out in one place. MiniMax does document evaluation methods in the Appendix, which is better than nothing.
-
The release focuses on text + tool calling. Multimodal input support is explicitly not supported in the Anthropic/OpenAI-compatible message formats (no image/document input in the Anthropic-compatible endpoint; no image/audio in OpenAI-compatible).
-
Practical output limits (maximum output tokens) are not emphasized in the M2.5 docs sections we reviewed, even though long-context models often have lower output caps than their context windows imply. If you need very long outputs, verify limits in the API console and run a hard test.
These aren’t criticisms; they’re engineering reality. A release post is not a model card, and a model card is not a deployment SLO.
Practical guidance: when M2.5 is the right tool (and when it isn’t)
M2.5 is a strong fit when your workload looks like this
You benefit most from M2.5 if your tasks are:
-
multi-step and tool-heavy (search rounds, terminal actions, web exploration)
-
long-horizon (lots of intermediate state, large context, context management)
-
codebase-scale (architecture planning, refactoring, tests, review)
-
deliverable-driven (Word/PPT/Excel-style outputs and structured artifacts)
MiniMax built and evaluated around these patterns, explicitly.
M2.5 is not magic when your workload looks like this
If your tasks are:
-
single-turn Q&A where latency-to-first-token dominates
-
image/document ingestion requiring native multimodal input
-
extremely strict function-call schemas that break if the model emits tool calls outside spec (you’ll need guardrails anyway)
Then M2.5 may still work, but its strengths are underused—and you should validate against smaller, cheaper models first.
The bottom line
MiniMax-M2.5 is a rare model release that treats agent performance as an engineering system problem rather than a leaderboard screenshot. The public story is consistent across their release note and their Forge technical blog: scale RL across many real environments, optimize for time/token efficiency, and build a serving/training stack that doesn’t collapse under long contexts.
If you build agentic products, the interesting part here is not a single benchmark. It’s the alignment between:
-
what they train for (trajectory efficiency under tools + long context),
-
how they measure it (rounds, runtime, token budgets),
-
and how they price it (continuous run economics).
And if you just want to try it in your product today: Atoms already supports MiniMax-M2.5.
