Anthropic Claude Sonnet 4.6: 下一代AI模型的突破与影响
引言:Claude Sonnet 4.6 震撼发布概览
Anthropic 已于2026年2月17日正式发布其最新模型 Claude Sonnet 4.6。这一重大发布距离其旗舰模型 Claude Opus 4.6 问世不足两周,此举显著加速了Anthropic在竞争激烈的AI市场中进军企业领域的步伐,并被视为重塑AI行业定价格局的关键一步。Anthropic官方博客文章“Introducing Claude Sonnet 4.6”对此发布进行了详细公告。
Claude Sonnet 4.6 的发布目标明确,旨在以中端模型的定价,提供接近旗舰级模型的智能水平。Anthropic期望通过这一模型,为更多用户带来“大幅改进的编程技能”,并为企业部署AI智能体提供变革性的成本性能比。
该模型被Anthropic描述为迄今为止最强大的Sonnet系列模型。其智能水平“接近Opus级别”,并在许多任务中能够与最新的Opus 4.6匹敌,甚至在某些方面实现超越。目前,Sonnet 4.6 已成为 claude.ai 和 Claude Cowork 上免费和专业计划用户的默认模型。
核心亮点:Sonnet 4.6 的突破性功能
Anthropic 官方将 Claude Sonnet 4.6 描述为迄今为止最强大的 Sonnet 模型 。它在多个核心领域进行了全面升级,旨在通过中端模型的定价,提供接近旗舰级模型的智能水平,并带来变革性的成本性能比 。此次发布不仅为企业部署AI智能体提供了前所未有的机遇,也预示着AI将成为处理复杂工作的真正伙伴 。以下是 Sonnet 4.6 最为“亮眼”的新功能和主要改进点:
1. 卓越的编码能力
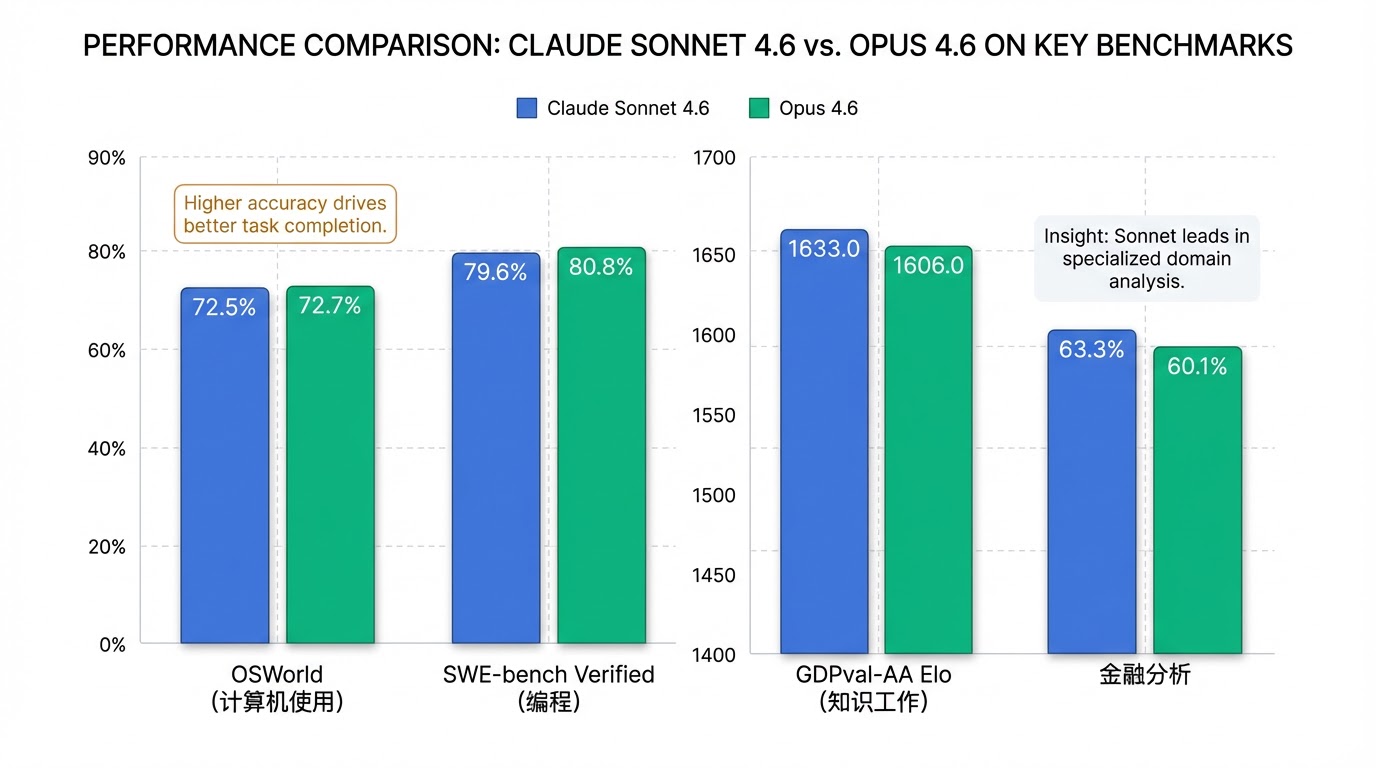
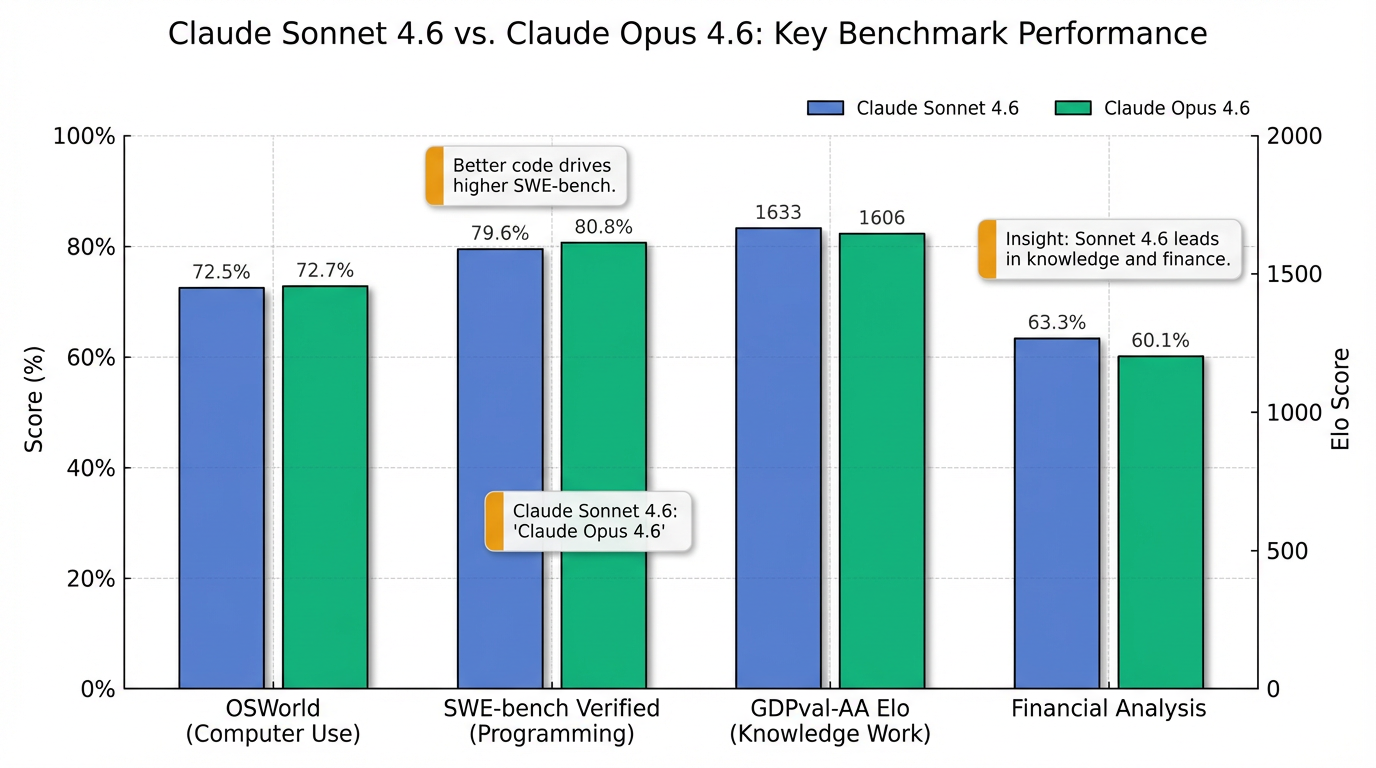
Claude Sonnet 4.6 的编码能力得到了大幅改进,为开发者带来了前所未有的效率提升 。Anthropic 报告称,在编程任务中,开发者在约70%的情况下偏好 Sonnet 4.6 优于 Sonnet 4.5,甚至在约59%的情况下偏好其优于更早的 Opus 4.5 模型 。这一显著提升体现在其能够更有效地读取上下文、整合共享逻辑、减少幻觉并更好地遵循指令 。在业界认可的 SWE-bench Verified 编程基准测试中,Sonnet 4.6 取得了79.6%的高分 ,表现接近 Opus 4.6 的80.8% 。
2. 革命性的计算机使用技能
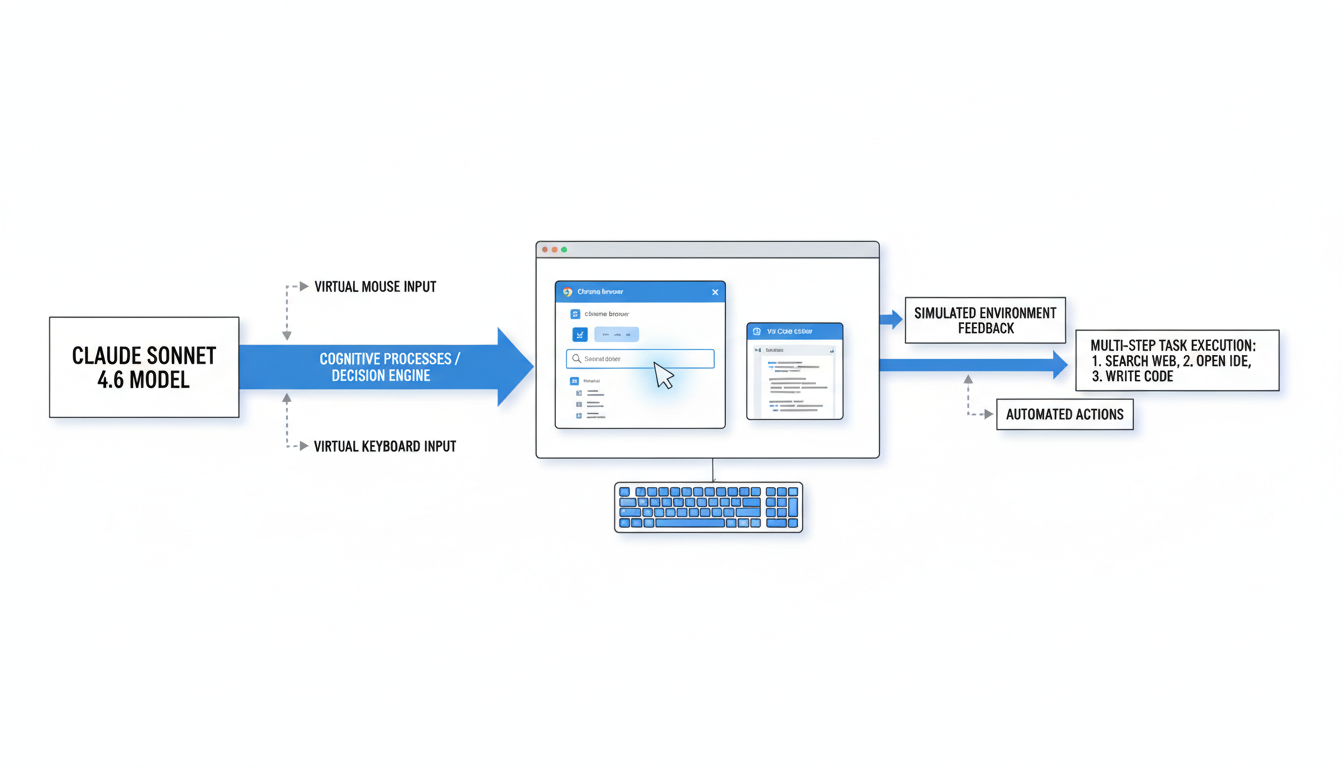
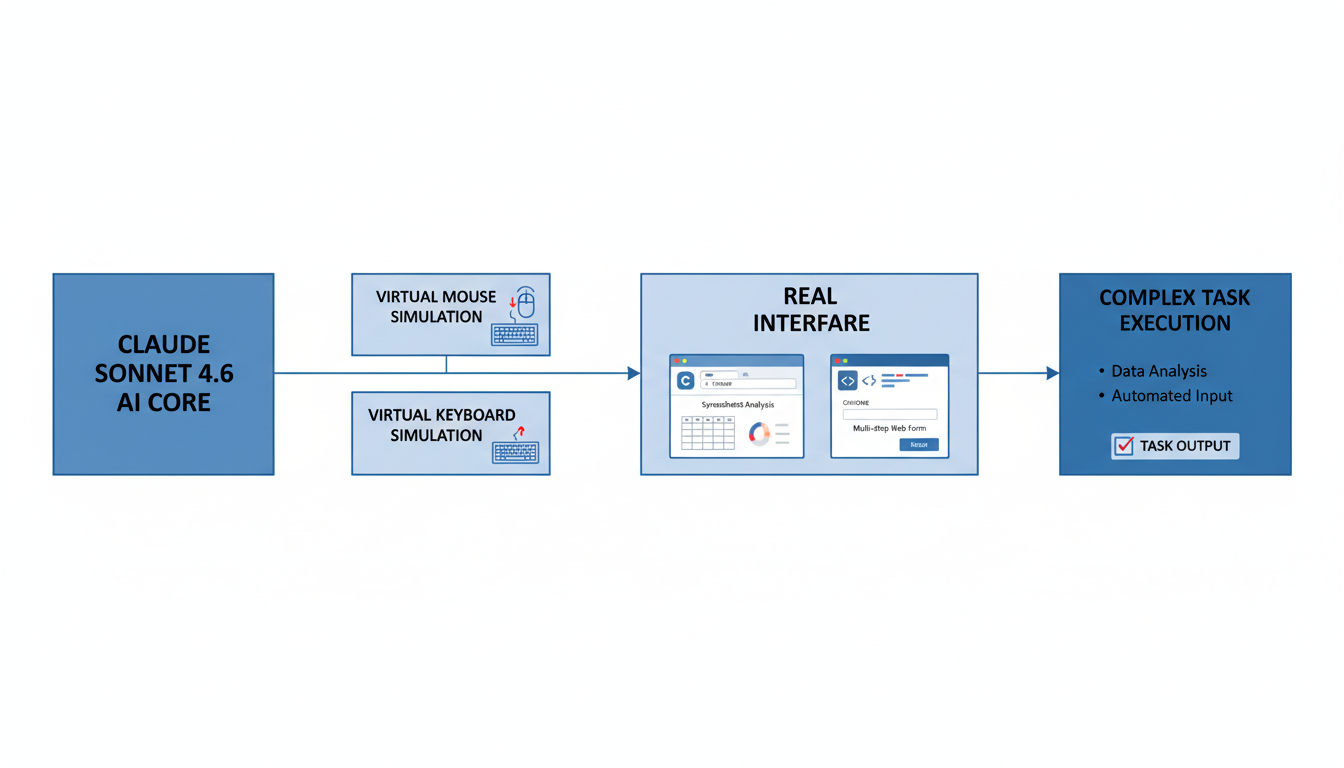
Sonnet 4.6 在计算机使用技能方面取得了突破性进展,使其能够像人类一样与真实软件进行交互 。通过模拟界面(例如虚拟鼠标和键盘),它能操作 Chrome 浏览器和 VS Code 编辑器等应用程序,处理复杂的电子表格和多步骤网页表单,而无需依赖特定的API或连接器 。在 OSWorld 计算机使用基准测试中,Sonnet 4.6 的得分高达72.5%,与 Opus 4.6 的72.7%几乎持平 ,标志着在短短16个月内,计算机操作能力提升了五倍 。
3. 超长上下文推理能力
该模型具备惊人的长上下文推理能力,提供了一个100万token的上下文窗口(测试版)。这意味着它能够在一个请求中处理海量信息,例如整个代码库、冗长的法律合同或数十篇研究论文 。这种能力使其能够有效地跨所有上下文进行深入的推理和分析,极大地拓展了其在知识管理和长文本处理中的应用场景 。
4. 卓越的智能体规划能力
Sonnet 4.6 还展示了卓越的智能体规划能力 。它能够自主执行多步骤任务并制定复杂的策略。例如,在 Vending-Bench Arena 评估中,Sonnet 4.6 能够展示出精密的商业投资和盈利策略,凸显了其在长时间任务执行和复杂策略制定方面的强大潜力 。
5. 强化的知识工作与设计能力
除了上述核心优势,Sonnet 4.6 还全面强化了知识工作能力 。在 GDPval-AA Elo 知识工作基准测试中,它以1633分远超 Opus 4.6 的1606分 。在金融分析领域,Sonnet 4.6 取得了63.3%的得分,成功击败所有对比模型,包括 Opus 4.6 的60.1% ,展现了其在数据分析方面的卓越实力。在保险领域任务中,其准确率更是达到了94%,是迄今测试过的所有 Claude 模型中表现最好的 。此外,模型的视觉输出也得到了显著提升,具有更精致的布局、动画和设计感 。
模型能力深度解析:为何称其“非常强”
Claude Sonnet 4.6 之所以被Anthropic官方评价为“非常强”,并能在中端模型定价下提供接近旗舰级模型的智能水平 [0-6],这主要得益于其在多个核心技术领域的全面突破和显著性能提升。本节将深入剖析其在编码、计算机使用、长上下文推理、智能体规划以及知识工作等方面的具体能力细节与技术优势,并结合权威基准测试数据,揭示其强大的内在逻辑。
编码能力的革命性提升及其基准表现
首先,Sonnet 4.6 在编码能力上实现了革命性提升,被Anthropic描述为“大幅改进的编程技能” [0-1]。开发者在约70%的情况下更偏好 Sonnet 4.6 优于 Sonnet 4.5,甚至在约59%的情况下认为其优于 Opus 4.5 [0-1]。它能够更有效地读取上下文、整合共享逻辑、减少幻觉并更好地遵循指令,从而提高代码生成与修复的效率和准确性 [0-2]。在业界认可的SWE-bench Verified编程基准测试中,Sonnet 4.6 的得分达到79.6% [0-0],这一成绩已非常接近旗舰模型 Opus 4.6 的80.8% [0-6],充分证明了其卓越的编程实力。
计算机使用技能的跨越式发展与OSWorld基准
其次,该模型在计算机使用技能方面取得了跨越式发展 [0-1]。Sonnet 4.6 能够像人类一样操作真实软件,例如 Chrome 浏览器和 VS Code 编辑器,通过模拟界面进行交互,从而处理复杂的电子表格操作和多步骤网页表单填写等任务 [0-2]。这一能力的实现,是通过模拟计算机接口,如虚拟鼠标和键盘,与真实软件进行交互,而无需特定的API或连接器 [0-2]。在衡量计算机操作能力的OSWorld基准测试中,Sonnet 4.6 获得了72.5%的得分,几乎与 Opus 4.6 的72.7%持平 [0-6],这表明在短短16个月内,其计算机操作能力提升了五倍之多 [0-6]。
100万token长上下文推理的突破性优势
第三,Sonnet 4.6 具备业界领先的100万token长上下文窗口(测试版) [0-1]。这意味着它足以在单个请求中容纳整个代码库、冗长的法律合同,或是数十篇研究论文,并能有效地在所有这些上下文信息之间进行推理,极大地扩展了其处理复杂信息和完成大规模任务的能力边界 [0-2]。
卓越的智能体规划能力与复杂策略制定
此外,模型还展现出卓越的智能体规划能力 [0-2]。例如,在 Vending-Bench Arena 评估中,Sonnet 4.6 能够展示出复杂的商业投资和盈利策略 [0-2]。这种能力体现在其能够自主地执行长时间任务和制定复杂的策略,使其在构建AI代理方面具有巨大潜力 [0-2]。
知识工作能力的全面强化:GDPval-AA Elo、金融分析与保险任务表现
最后,Sonnet 4.6 的知识工作能力得到了全面强化 [0-2]。在 GDPval-AA Elo 知识工作基准测试中,Sonnet 4.6 取得了高达1633分的成绩,远超 Opus 4.6 的1606分 [0-6]。在金融分析任务中,其得分达到63.3%,超越了包括 Opus 4.6 (60.1%) 在内的所有对比模型 [0-6]。在保险领域的任务中,Sonnet 4.6 的准确率高达94% [0-2],成为迄今测试过的所有 Claude 模型中表现最佳的 [0-6]。同时,在文档理解方面,OfficeQA 测试显示其性能与 Opus 4.6 相当,能够高效阅读和推理企业文档 [0-2]。
综合来看,Claude Sonnet 4.6 在保持与 Sonnet 4.5 相同成本效益的同时,实现了接近甚至在某些方面超越旗舰模型 Opus 4.6 的智能水平 [0-6]。这种通过技术创新和架构优化带来的强大能力,使其在快速响应任务中展现出卓越的性能与成本比,有效满足了企业在AI应用中的多重需求,重塑了AI市场定价格局 [0-6]。
市场反响与潜在影响
Anthropic 公司已于2026年2月17日正式发布其最新模型Claude Sonnet 4.6 [0-1]。此次发布是在其旗舰模型Claude Opus 4.6推出不到两周后进行的,被视为Anthropic在激烈竞争的AI市场中加速进军企业市场,并意图重塑AI行业定价格局的重大战略举措 [0-6]。
市场定位与成本效益重塑
Claude Sonnet 4.6 的核心市场定位是,以中端模型的定价,提供接近旗舰级模型的智能水平 [0-6]。Anthropic明确指出,该模型旨在为更多用户带来“大幅改进的编程技能” [0-6],并为企业部署AI智能体提供变革性的成本性能比 [0-6]。
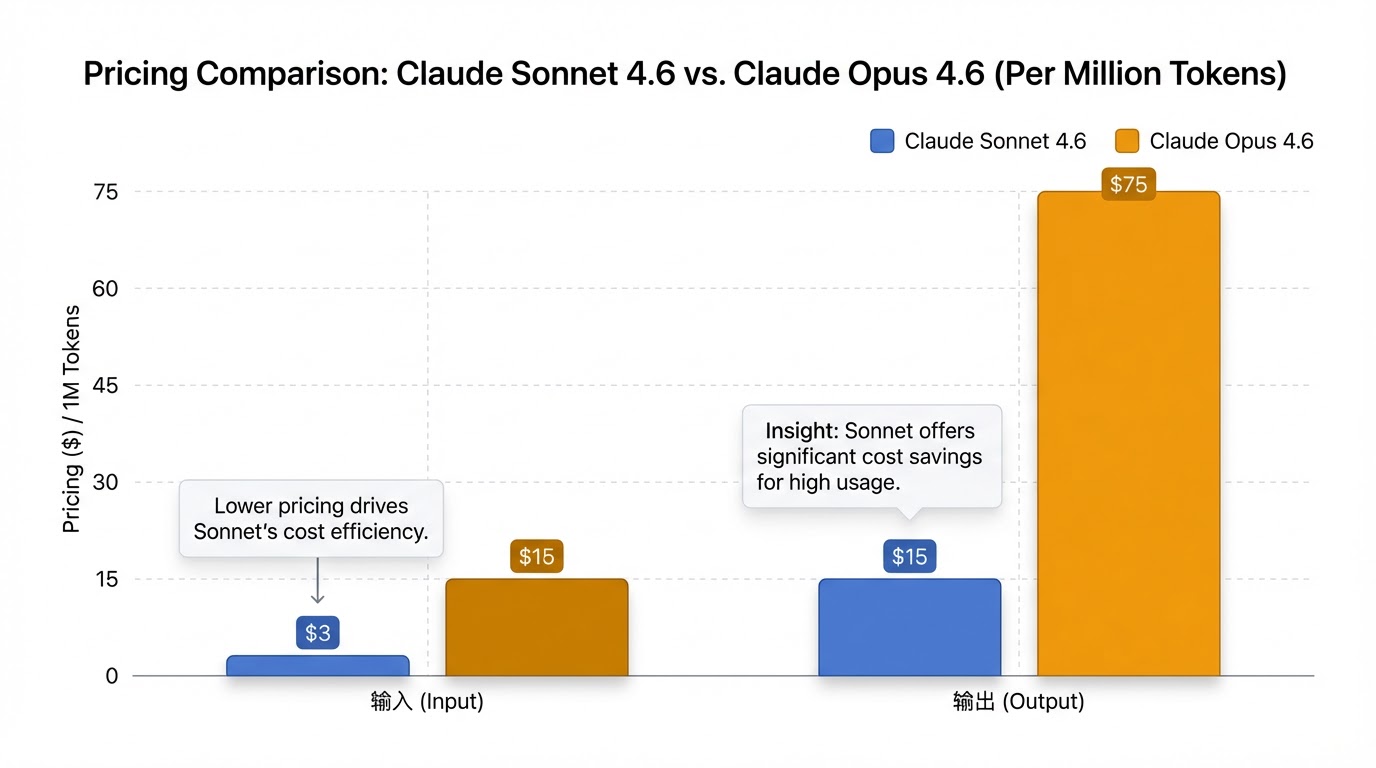
Sonnet 4.6 的定价策略极具竞争力,其输入每百万token收费$3,输出每百万token收费$15,这与Sonnet 4.5的定价相同 [0-1], [0-2], [0-6]。值得注意的是,这一价格仅为Opus模型成本的五分之一(Opus的定价为输入每百万token $15,输出每百万token $75) [0-6]。
| 模型 | 输入 (每百万token) | 输出 (每百万token) |
|---|---|---|
| Claude Sonnet 4.6 | $3 | $15 |
| Opus | $15 | $75 |
这种显著的成本优势,使得 Sonnet 4.6 能够在许多企业最关心的类别中,匹配甚至超越运行成本高出五倍的模型的表现 [0-6]。Anthropic 期望通过 Sonnet 4.6,消除企业在低成本低质量与高成本高质量AI方案之间的传统权衡,从而加速AI在企业中的广泛普及和应用 [0-6]。
在多项关键基准测试中,Sonnet 4.6 展现出令人印象深刻的性能,与旗舰模型不相上下:
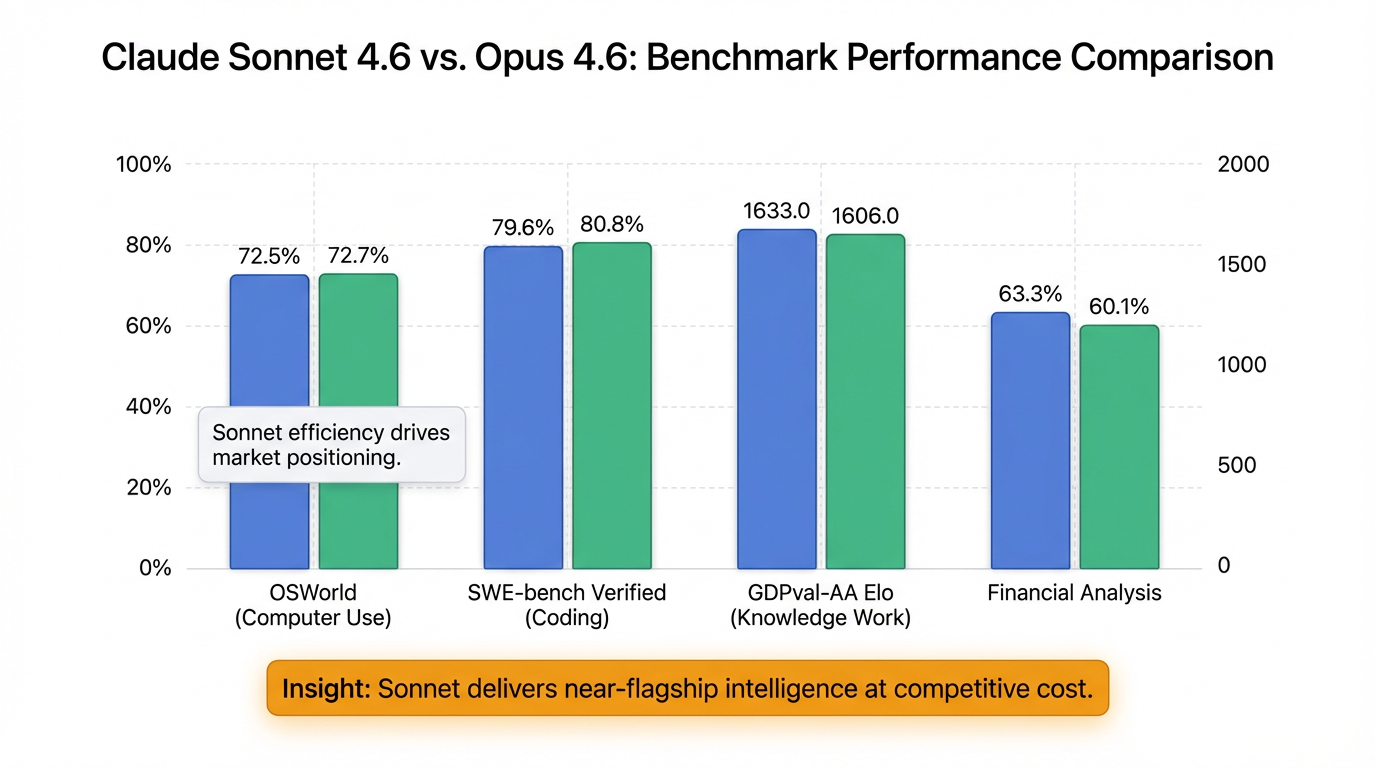
- OSWorld(计算机使用): Sonnet 4.6 得分72.5%,与 Opus 4.6 的72.7% 基本持平 [0-6]。 Anthropic 表示,在16个月内,其计算机操作能力提升了五倍 [0-6]。
- SWE-bench Verified(编程): 模型得分高达79.6% [0-0], [0-6],非常接近 Opus 4.6 的80.8% [0-6]。
- GDPval-AA Elo(知识工作): Sonnet 4.6 以1633分超越了 Opus 4.6 的1606分 [0-6]。
- 金融分析: 得分63.3%,击败了包括 Opus 4.6 在内的所有对比模型 [0-6]。
- 保险领域任务: 准确率达到94%,是迄今测试过的所有 Claude 模型中表现最好的 [0-2], [0-6]。
- 文档理解: 在 OfficeQA 测试中,Sonnet 4.6 匹配了 Opus 4.6 的性能,能够有效阅读和推理企业文档 [0-2]。
这些数据清晰表明,Sonnet 4.6 的智能水平已“接近 Opus 级别” [0-0],并在许多任务中能与最新的 Opus 4.6 匹敌,甚至在某些方面超越了 Opus 4.6 [0-6],而其成本效益比无疑将对AI市场格局产生深远影响。
企业市场渗透与用户采纳
Anthropic 将 Sonnet 4.6 定位为加速其在企业市场渗透的关键产品 [0-6]。作为 Sonnet 系列中迄今为止最强大的模型 [0-1], [0-2],其卓越的成本性能比使其成为企业部署AI智能体的变革性选择 [0-6]。Anthropic 已将其设置为 claude.ai 和 Claude Cowork 上免费和专业计划用户的默认模型 [0-1], [0-2]。这一策略将极大地提升 Sonnet 4.6 的用户采纳率,使其能够触达更广泛的用户群体。通过降低高质量AI的门槛,Sonnet 4.6 有望成为企业日常运营中不可或缺的AI工作伙伴 [0-4]。
目标应用领域的广阔前景
Sonnet 4.6 在多个核心领域进行了全面升级,为其在各种企业应用场景中提供了广阔的前景 [0-2], [0-6]。
- 编码和软件工程: Sonnet 4.6 的编程技能大幅改进,开发者在约70%的情况下偏好 Sonnet 4.6 优于 Sonnet 4.5,甚至在约59%的情况下偏好其优于 Opus 4.5 [0-1], [0-2]。这使得它能有效处理复杂代码修复、大规模代码库中的问题解决、新功能开发和全栈更新等任务 [0-1], [0-2], [0-6]。
- 企业自动化: 模型在计算机使用能力上取得了显著提升,能够像人类一样操作真实软件(如 Chrome 和 VS Code),通过模拟界面进行交互,处理复杂电子表格和多步骤网页表单,而无需特殊的API或连接器 [0-1], [0-2]。这为自动化操作传统遗留软件,如保险门户网站、政府数据库和企业资源规划(ERP)系统等提供了切实可行的解决方案 [0-1], [0-2], [0-6]。
- 知识管理: 具备100万token的上下文窗口(测试版),足以在单个请求中容纳整个代码库、冗长合同或数十篇研究论文,并能有效地进行推理 [0-1], [0-2], [0-6]。这使其在长文本处理、合同分析、研究摘要和报告生成方面具有巨大潜力 [0-1], [0-2], [0-6]。
- 代理应用: 其卓越的智能体规划能力,例如在 Vending-Bench Arena 评估中展示的复杂商业投资和盈利策略 [0-2],使其能够构建能够自主执行多步骤任务的AI代理 [0-1], [0-2], [0-6]。
- 数据分析与内容创作: 强化了金融分析和知识工作能力 [0-2], [0-6],同时视觉输出显著提升,具有更精致的布局、动画和设计感 [0-2]。这些优势为数据分析、商业智能、报告生成以及高质量文本和视觉内容创作(如前端代码、文案和设计输出)开辟了新的途径 [0-1], [0-2], [0-6]。
对AI领域与相关应用的变革影响
综上所述,Claude Sonnet 4.6 的发布,不仅为 Anthropic 在AI市场中巩固其地位奠定了基础,更通过其变革性的成本性能比,对整个AI领域及其相关应用产生了深远的变革影响 [0-6]。它打破了高质量AI必然高成本的传统认知,使得高性能AI智能体能够以更亲民的价格普及到更广泛的企业和个人用户手中。这无疑将加速AI技术在各行各业的深度融合,推动智能化转型的进程,并激发更多创新应用场景的涌现,最终促使AI真正成为人们日常工作和生活中的强大且无处不在的“工作伙伴” [0-4], [0-6]。
总结:展望 Sonnet 4.6 的未来
Anthropic 于 2026 年 2 月 17 日发布的 Claude Sonnet 4.6 模型,标志着 AI 领域的一次重大飞跃,尤其是在中端模型市场中树立了新的标杆 [0-1], [0-2], [0-6]。这款模型以其卓越的性能与成本效益比,旨在重塑 AI 行业格局,并加速 AI 技术在企业中的普及和应用 [0-6]。
Sonnet 4.6 在多个核心能力上实现了突破性进展 [0-2], [0-6]:
- 编码能力:编程技能大幅提升,开发者在约 70% 的情况下偏好 Sonnet 4.6 优于 Sonnet 4.5,甚至在约 59% 的情况下偏好其优于 Opus 4.5。它能更有效地阅读上下文、整合共享逻辑、减少幻觉并更好地遵循指令 [0-1], [0-2]。
- 计算机使用技能:模型在计算机操作上取得显著进步,能够像人类一样与真实软件(如 Chrome 和 VS Code)交互,处理复杂的电子表格和多步骤网页表单 [0-1], [0-2]。在 OSWorld 基准测试中,其得分高达 72.5%,与 Opus 4.6 的 72.7% 几乎持平 [0-6]。
- 长上下文推理:具备 100 万 token 的超大上下文窗口(测试版),足以在一个请求中处理整个代码库、冗长合同或数十篇研究论文,并能有效地进行跨上下文推理 [0-1], [0-2], [0-6]。
- 智能体规划:展现出卓越的代理规划能力,例如在 Vending-Bench Arena 评估中能够制定复杂的商业投资和盈利策略 [0-2]。
- 知识工作:知识处理能力得到显著强化,在 GDPval-AA Elo 测试中以 1633 分的成绩远超 Opus 4.6 的 1606 分 [0-6]。
- 设计能力:视觉输出显著提升,具有更精致的布局、动画和设计感 [0-2]。
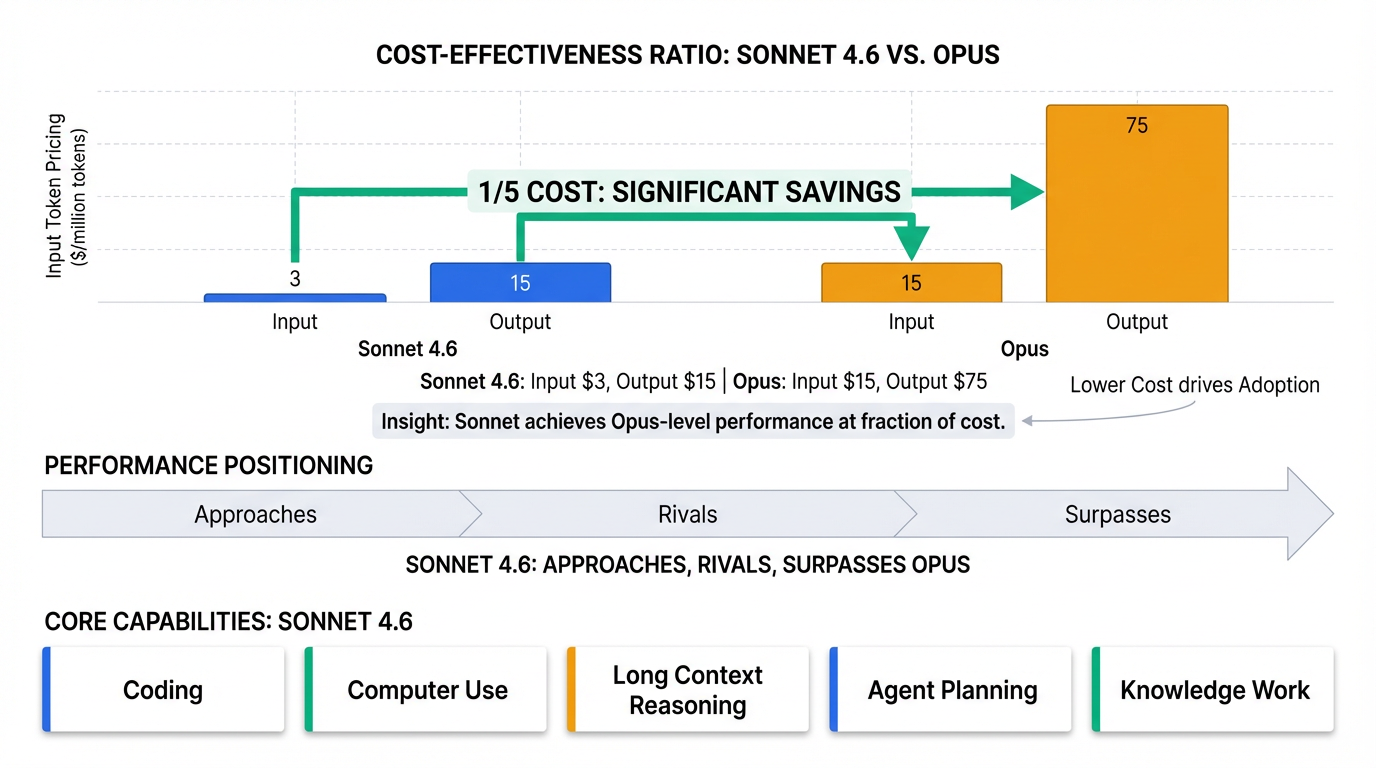
Sonnet 4.6 最引人注目的特点之一是其卓越的成本效益比。它以与 Sonnet 4.5 相同的定价(输入每百万 token 3 美元,输出每百万 token 15 美元)提供接近旗舰级模型的智能水平 [0-1], [0-2], [0-6],而其成本仅为 Opus 模型的五分之一 [0-6]。这使得企业无需在高成本高性能与低成本低性能之间进行权衡,为更广泛的用户带来了“大幅改进的编程技能”,并为企业部署 AI 智能体提供了变革性的成本性能比 [0-6]。在许多企业最关心的类别中,Sonnet 4.6 的表现匹配甚至超越了运行成本高出五倍的模型 [0-6]。
展望未来,Claude Sonnet 4.6 的应用前景广阔,将成为企业和开发者不可或缺的强大工具 [0-1], [0-2], [0-6]:
- 软件工程:在复杂代码修复、大规模代码库问题解决、新功能开发和全栈更新等方面发挥关键作用。
- 企业自动化:能够自动化操作传统的遗留软件,如保险门户网站、政府数据库和企业资源规划(ERP)系统。
- 知识管理:处理长文本、分析合同、总结研究和生成报告,极大地提高知识工作效率。
- AI 代理构建:赋能开发者构建能够自主执行多步骤任务的 AI 代理,例如进行商业模拟和任务规划。
- 数据分析:在金融分析、商业智能和报告生成领域提供强大支持 [0-6]。
- 内容创作与设计:生成高质量文本和视觉内容,如前端代码、文案和设计输出 [0-2]。
Anthropic 旨在通过 Sonnet 4.6 消除企业在选择 AI 解决方案时的困境,使其能够以中端模型的定价获得接近旗舰级的智能水平,从而加速其在企业市场的渗透 [0-6]。Sonnet 4.6 有望让 AI 真正成为处理电子表格、演示文稿和长文档的人们的工作伙伴 [0-4]。这一发布不仅是 Anthropic 在竞争激烈的 AI 市场中的一次战略性举措 [0-6],更是对整个 AI 行业定价格局的重大重塑,预示着 AI 技术将更快、更广泛地融入各个行业和日常工作流程,开启一个智能协作的新时代。