Building Enterprise RAG Systems for Accurate AI
Title: Building Enterprise RAG Systems for Accurate AI Description: CTOs, AI engineers, and product managers: learn to design, implement, and optimize Retrieval-Augmented Generation (RAG) systems for factual, context-aware enterprise AI.
Introduction
In the rapidly evolving landscape of enterprise AI, organizations grapple with pervasive hurdles that limit the true potential of their intelligent systems. Large Language Models (LLMs), while incredibly powerful, often suffer from significant drawbacks, including knowledge cutoff dates, an inability to access proprietary internal data, and the notorious problem of "hallucination"—generating factually incorrect or misleading information. These critical issues prevent AI from being truly mission-critical, especially when dealing with sensitive, current, or domain-specific business contexts that demand absolute accuracy and trustworthiness1.
This is precisely where Retrieval-Augmented Generation (RAG) systems emerge as an indispensable solution. RAG systems are critical for enterprise AI, moving beyond experimental phases into robust, mission-critical deployments serving numerous users2. They address the inherent limitations of LLMs by externalizing knowledge into continuously updated knowledge bases, thereby significantly reducing hallucinations and enabling use with current, proprietary, and domain-specific information1.
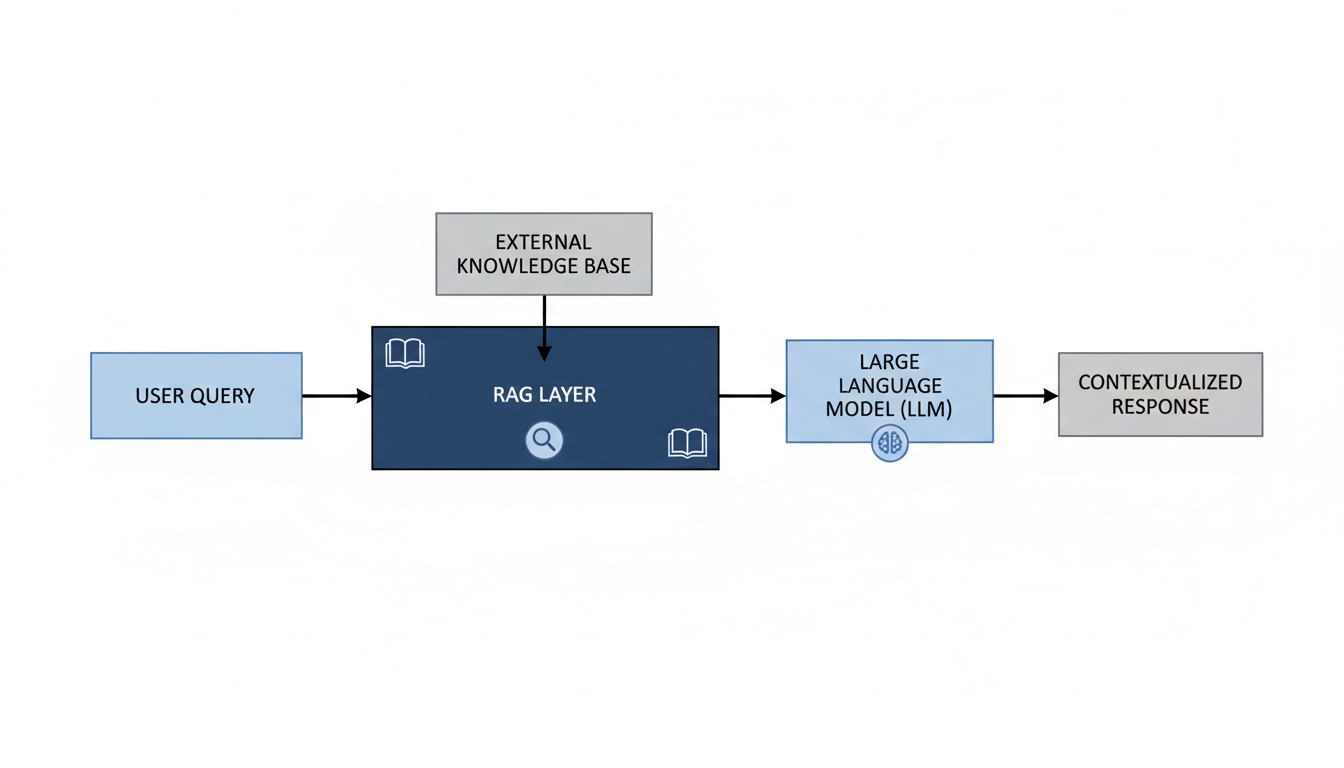
For CTOs, AI engineers, and product managers, mastering Retrieval-Augmented Generation is no longer optional; it is fundamental to deploying AI that delivers reliable and accurate business value. These systems inject factual accuracy, relevant context, and deep domain intelligence directly into AI applications, transforming them from general tools into strategic assets. Understanding the core architectural components, stringent security implications, and scalable performance considerations is paramount for successful enterprise adoption.
This report serves as a comprehensive guide, offering insights into designing, implementing, and optimizing robust RAG systems for real-world enterprise applications. We will explore best practices, delve into successful case studies, and highlight the role of leading open-source tools, providing a clear roadmap for leveraging RAG to enhance your organization's AI capabilities. For those looking to quickly build their own AI solutions, an AI App Builder can significantly accelerate your development, while our blog offers continuous insights and strategies.
Core Strategy: Designing & Implementing RAG for Business Impact
Enterprise AI has moved beyond theoretical discussions; it's now about mission-critical deployments serving vast user bases. For CTOs and product managers, this means building RAG systems that don't just work, but excel under real-world enterprise constraints. The core strategy revolves around a distributed, modular architecture, strategic data management, and a relentless focus on security, scalability, and performance to move beyond experimental phases into robust operational tools 2. This approach directly tackles the inherent limitations of Large Language Models (LLMs), such as their knowledge cutoff dates, ignorance of proprietary information, and tendencies to "hallucinate," by anchoring them to continuously updated external knowledge bases 1.
The foundational architectural pattern for an enterprise RAG system is a distributed system, comprising asynchronous components designed for independent scaling and resilience to distinct failure modes 1. At its heart lies the Knowledge Base/Storage Layer, which indexes information in specialized databases—often vector databases like Pinecone or Qdrant, alongside document stores such as Elasticsearch. This layer effectively houses documents, their segmented chunks, and their numerical vector embeddings 3. Data enters this system through an Indexing Pipeline, a critical process that ingests information from diverse sources, preprocesses it (e.g., converting PDFs, stripping markup, handling OCR), chunks it into manageable pieces (with strategies like adaptive chunking to preserve semantic meaning), generates embeddings for each chunk, and finally indexes this vectorized data with rich metadata for efficient retrieval 5.
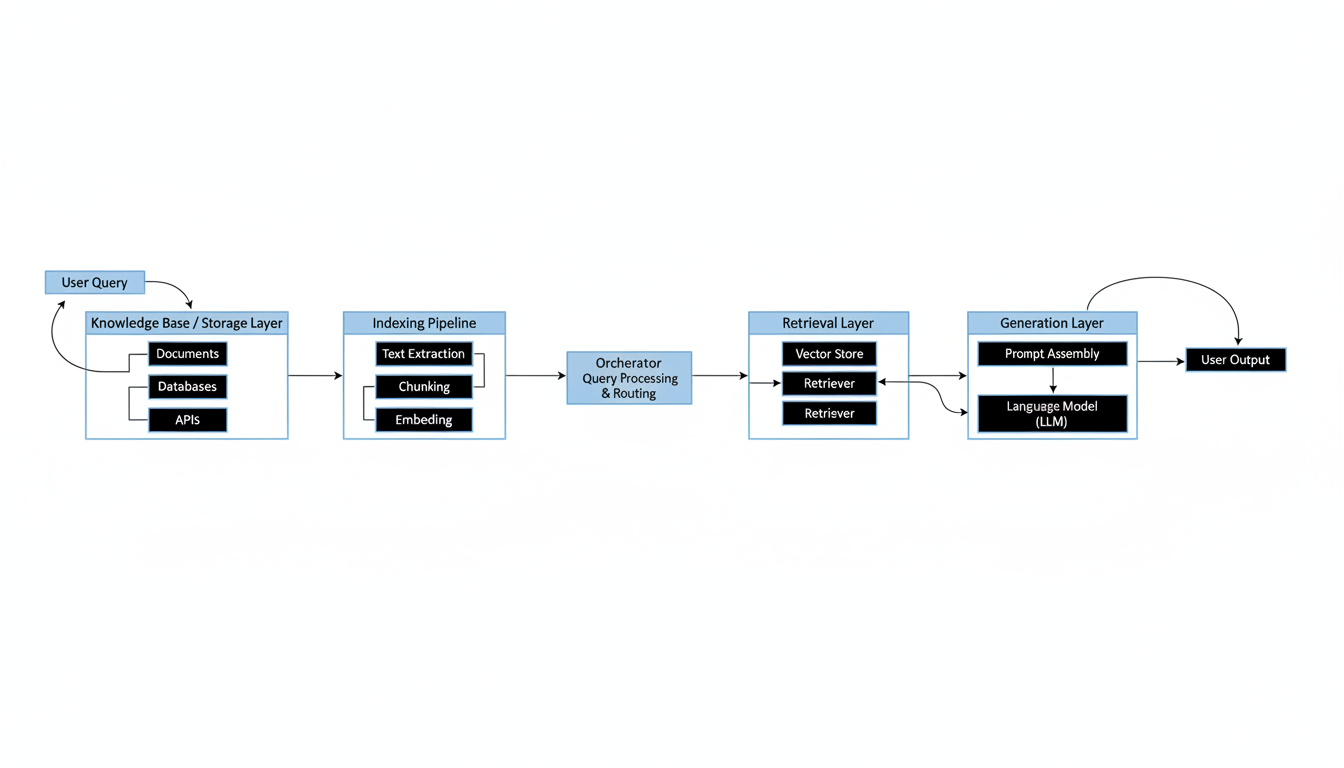
When a user poses a query, the Retrieval Layer translates it into an embedding and performs similarity searches against the knowledge base, often combining vector search with keyword search for enhanced accuracy 5. This retrieved context is then passed to the Orchestrator, which intelligently manages the workflow, ensuring efficient processing and implementing fallback strategies 4. Finally, the Generation Layer leverages an LLM with carefully crafted prompt engineering—often including role-based messages or Chain-of-Thought prompting—to synthesize a coherent and contextually appropriate answer based only on the provided context 3. This rigorous approach effectively reduces hallucinations and allows the LLM to provide answers grounded in current, proprietary, and domain-specific information 1.
Integrating RAG systems within an existing enterprise ecosystem demands careful planning, particularly with how they interact with established tools and workflows. These systems must seamlessly connect with CRM, ERP, and documentation repositories, drawing on diverse data sources to enrich context 7. Crucially, they must also integrate with corporate identity providers for robust authentication and access control, using systems like AWS Cognito or enterprise SSO 8. This modular component architecture is not merely a design preference but an operational imperative, allowing independent scaling, replacement of components (from embedding models to LLMs), and clear interfaces for debugging and monitoring, as shown in the example architectures from platforms like AI Chatbot Builder 2.
For high availability and performance, strategies include horizontal scaling through containerization and distributed vector databases, optimized data pipelines with incremental updates and parallel processing, and tiered retrieval systems for vast document collections 2. Performance optimization techniques are also vital, including multi-level caching (query results, embeddings, retrieved documents) and context compression, which involves summarizing, ranking, and deduplicating retrieved information to reduce prompt size and associated costs 2. Reliability engineering, with circuit breakers and graceful degradation paths, further bolsters system resilience, while a multi-LLM provider strategy offers flexibility and failover capabilities for critical operations 2. For those exploring advanced data ingestion and processing, concepts found in Deep Research can be particularly insightful.
Above all, security remains paramount, especially when handling sensitive enterprise data such as PII, PHI, or proprietary business intelligence. Robust access control mechanisms like Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC) are essential, often augmented by post-retrieval filtering that uses dedicated authorization services to verify user permissions after retrieval but before information reaches the LLM 2. Data protection further includes redaction and anonymization of sensitive information at ingestion, combined with encryption both at rest and in transit 14. Input and output guardrails prevent harmful queries and ensure generated responses comply with regulations and content policies 14. Comprehensive auditing and monitoring, combined with adherence to compliance standards like GDPR and HIPAA, establish a secure and accountable environment for enterprise RAG deployments 2.
Real Example: A RAG System in Action
One striking example of RAG's power in a demanding enterprise environment comes from Vanguard, a global investment firm that transformed its customer support operations 20. Before implementing RAG, Vanguard's support team grappled with several significant challenges. Agents wasted valuable time manually sifting through vast, complex financial documents using inefficient keyword-based search systems while customers waited on the line, leading to slow answer times 20. This inefficiency also forced Vanguard to incur substantial costs and management overhead through seasonal hiring to manage peak call volumes during periods like tax season 20. Perhaps most critically, in the heavily regulated financial sector, relying on keyword search often caused agents to miss critical details or provide outdated information, creating considerable compliance risks and potential regulatory issues 20.
To overcome these hurdles, Vanguard's Machine Learning engineering team developed a sophisticated hybrid RAG system built upon Pinecone's vector database 20. This system meticulously processed financial documents by splitting them into well-structured chunks to facilitate superior embedding 20. It employed a dual embedding strategy, utilizing dense embeddings to capture contextual and semantic meaning, alongside sparse embeddings (BM25) for precise matching of financial jargon and abbreviations 20. An alpha tuning parameter, set at 0.5, was instrumental in balancing semantic and keyword retrieval results, ensuring comprehensive and highly accurate responses 20. Pinecone's hybrid search capabilities, sub-second performance, and enterprise-grade security features were key factors in its selection for this critical infrastructure 20.
The implementation of this hybrid RAG system directly addressed Vanguard's core problems. It empowered agents with precise, up-to-date, and context-aware answers grounded in verified information, dramatically improving answer times and mitigating compliance risks 20. By automating and significantly enhancing information retrieval, the need for extensive manual research and associated labor costs was substantially reduced 20. This strategic shift not only streamlined operations but also bolstered the firm's regulatory adherence.
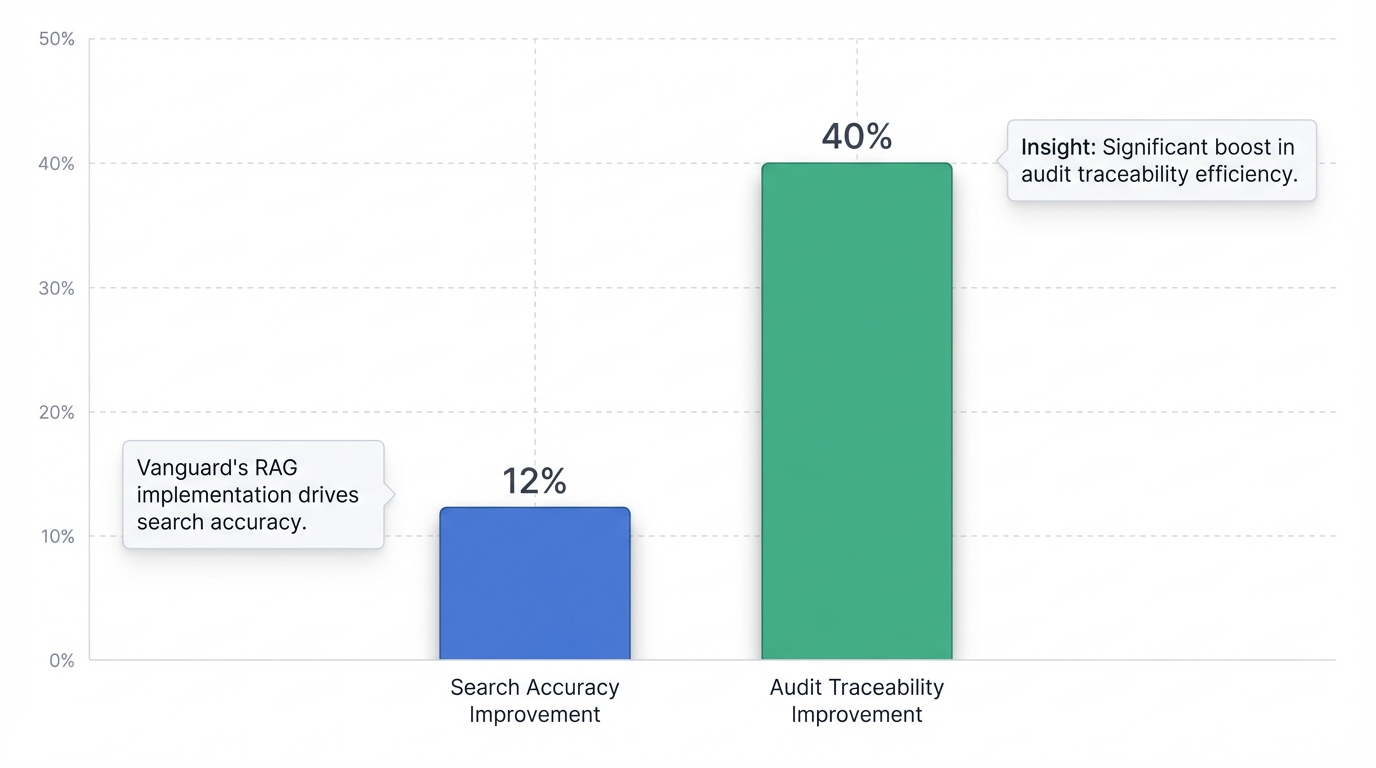
The quantifiable results of Vanguard's RAG implementation underscore its transformative impact. The firm saw a 12% improvement in search accuracy, providing agents with more reliable information 20. Critically, the elimination of seasonal hiring costs led to millions of dollars in annual savings 20. Compliance was also significantly strengthened, with a 40% improvement in audit traceability, directly reducing regulatory risk and the potential for multi-million dollar fines 20. Furthermore, the system led to reduced call handle times and increased first-call resolution, boosting overall efficiency and customer satisfaction 20.
Build It Yourself: Open-Source Tools for Enterprise RAG
Building your own Retrieval-Augmented Generation (RAG) system for enterprise applications increasingly involves robust open-source tools. RAGFlow stands out as a leading open-source RAG engine, meticulously designed to elevate AI-driven content generation and knowledge retrieval. It combines information retrieval with language generation, delivering accurate, verifiable, and contextually relevant responses, directly combating common AI hallucinations . Its rapid recognition among GitHub's fastest-growing open-source projects highlights its readiness for production-grade AI workflows 21.
RAGFlow offers a comprehensive suite of enterprise-grade features. Its scalable architecture handles growing demands, supporting horizontal scaling and Kubernetes integration . Data integration is extensive, processing diverse formats and employing deep document understanding for knowledge extraction . Template-based chunking and dynamic hybrid search ensure comprehensive indexing and real-time data access . Security is paramount, with encryption, RBAC, granular permissions, and adherence to certifications like SOC 2 and ISO 27001 . Built-in agent capabilities with Memory components enable continuous learning and automated workflows via webhooks . Critically, RAGFlow provides grounded citations, reducing hallucinations and enhancing trust through traceable answers . Being open-source ensures cost-effectiveness and offers easy customization of LLM and embedding models .
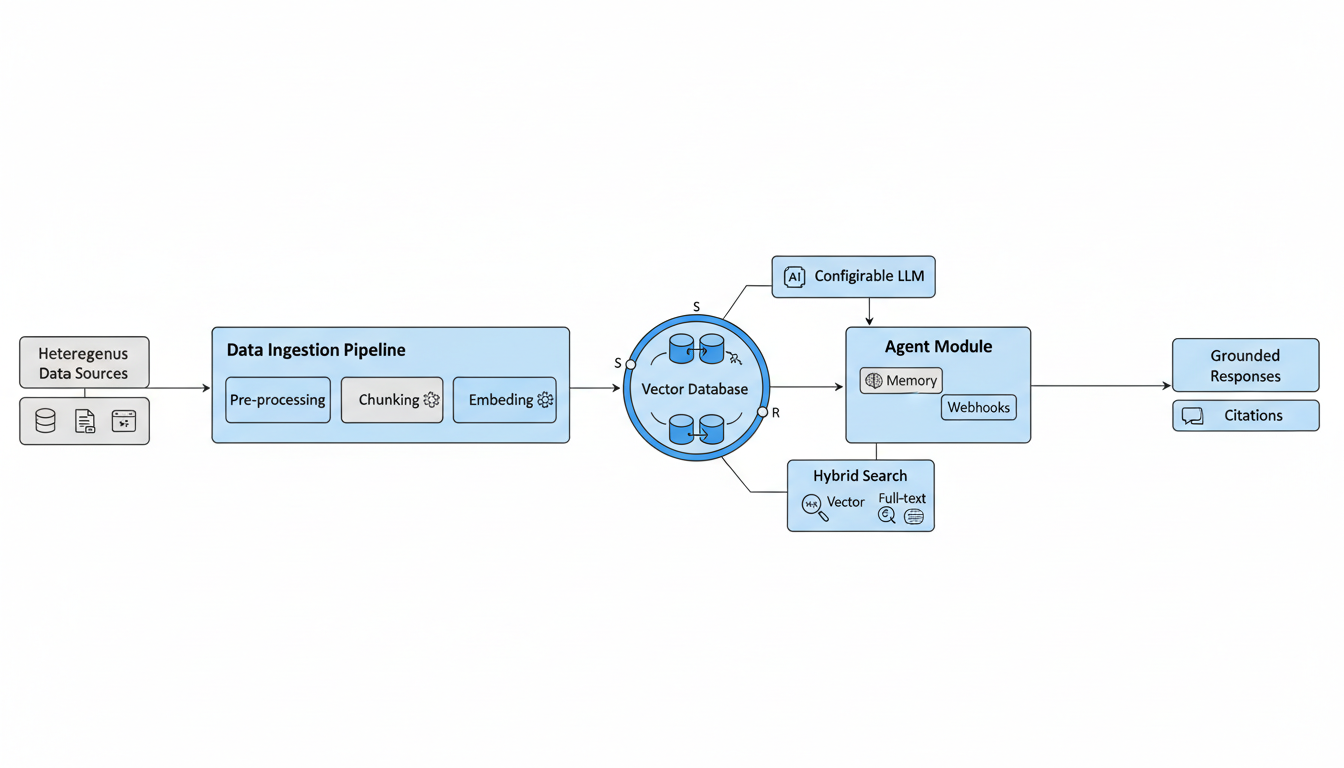
For practical implementation, ensure your environment meets Docker, CPU, RAM, and disk space prerequisites . Deployment involves cloning the RAGFlow repository, starting the server with Docker Compose, then configuring LLM APIs and uploading documents . A modular architectural design, built for scale, is essential from day one, integrating security early leveraging RAGFlow's features . Prioritizing data quality through pre-processing and continuous updates is critical . Optimizing performance with caching and hybrid search, alongside continuous monitoring using RAG-specific evaluation frameworks, ensures robust operation . For those looking to build advanced AI applications, understanding these foundational steps can be a game-changer AI App Builder.
Despite these powerful tools, common challenges persist. "RAG sprawl" can fragment AI landscapes and increase organizational costs 22. Scaling data volume against retrieval performance demands robust infrastructure, as large datasets strain memory and accuracy . Domain specificity means general RAG solutions often underperform in niche knowledge areas 23. LLMs may lack crucial organizational knowledge, leading to inaccurate internal documentation responses . Complex or ambiguous queries can be difficult for RAG systems to resolve, and maintaining scalability and low latency for intensive LLM inferences remains a challenge . For effective deep research and navigating complex data, these challenges must be thoughtfully addressed Deep Research.
Beyond RAGFlow, other open-source solutions like GraphRAG, a modular graph-based RAG system, excel at complex inferencing. Anything-LLM provides an all-in-one AI application with built-in RAG and a no-code agent builder for rapid prototyping. These tools offer diverse pathways for enterprises to tailor their RAG infrastructure to specific operational needs.
Next Steps: Your RAG Implementation Roadmap
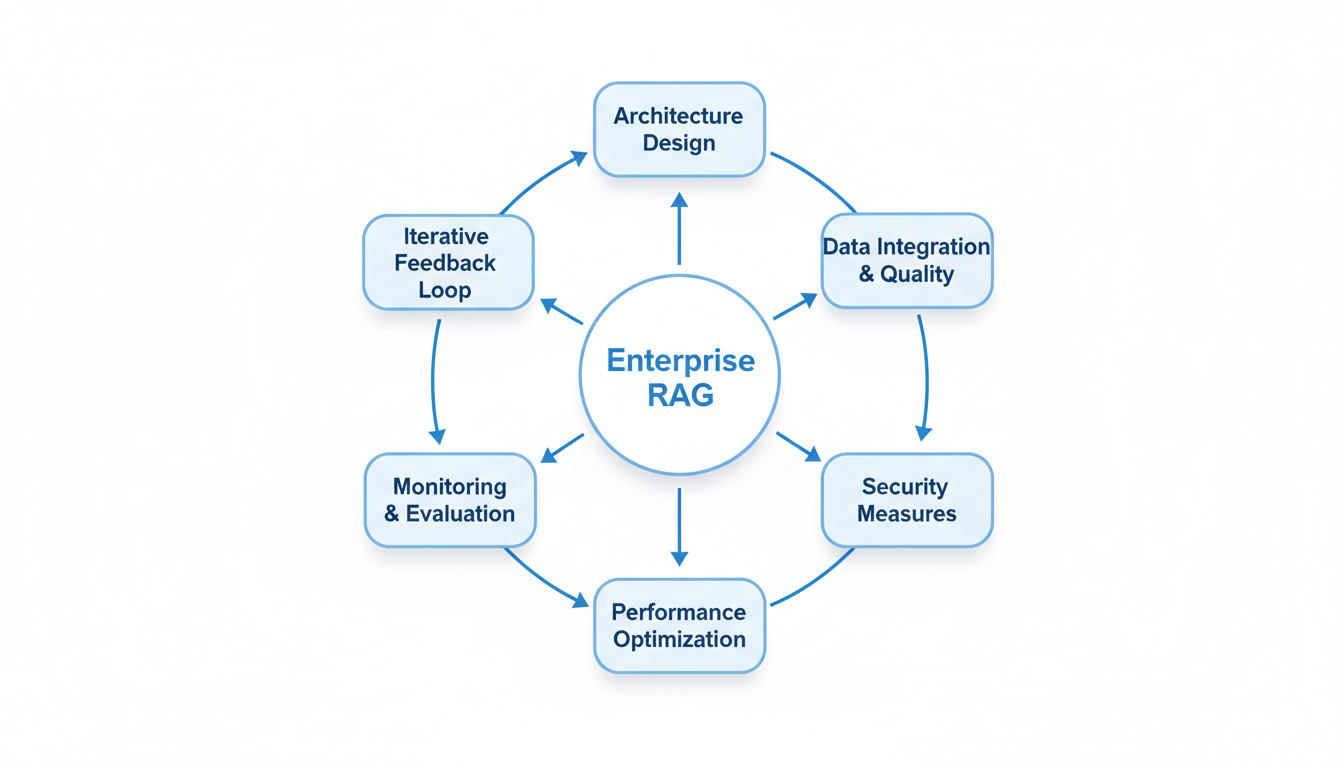
Having explored the foundational components, sophisticated features of tools like RAGFlow, and the enterprise-grade considerations for RAG systems, the critical question becomes: how do you translate this knowledge into a concrete action plan for your organization? For CTOs, AI engineers, and product managers, building an effective RAG system is not just about adopting a new technology; it's about architecting a robust, secure, and continuously improving knowledge-driven AI backbone. The journey begins with a strategic, phased approach, prioritizing foundational elements before scaling to complex use cases.
The first step on this roadmap is to prioritize foundational architecture and security from day one. Enterprise RAG systems are distributed and asynchronous, necessitating a modular design that allows for independent scaling and replacement of components like embedding models, vector stores, and LLMs 2. Security is not an afterthought; it must be ingrained in the initial design, especially when handling sensitive enterprise data such as PII and proprietary business content 15. Implement robust access controls like Role-Based Access Control (RBAC) and Post-Retrieval Filtering, which prevent unauthorized information from reaching the generation layer by verifying user permissions after retrieval 13. Additionally, ensure data protection through encryption at rest and in transit, and establish comprehensive auditing and monitoring for compliance 11.
Next, focus relentlessly on continuous data quality, processing, and management. The efficacy of any RAG system hinges on the quality of its underlying data. This involves meticulous data ingestion from diverse sources, rigorous preprocessing for cleaning and transformation, and intelligent chunking strategies to maintain semantic continuity 5. Implement incremental updates and Change Data Capture (CDC) to keep your knowledge bases fresh and relevant, avoiding the pitfalls of stale information 2. RAGFlow, for instance, supports deep document understanding and template-based chunking, enabling accurate knowledge extraction from complex formats like tables and images . This focus extends to ensuring your indexing pipeline is optimized for parallel processing across distributed computing frameworks 2.
An essential aspect of enterprise deployment is to implement robust performance optimization and observability strategies. As user demands and data volumes grow, scalability becomes paramount. This means leveraging horizontal scaling with containerized components, distributed vector databases, and load balancers 2. Performance optimization techniques such as multi-level caching, query planning, and context compression are vital for faster responses and reduced inference costs 9. Just as crucial is comprehensive observability: monitor latency across all components, track retrieval quality metrics (precision, recall), and log semantic failures to quickly identify and address issues 2. Without clear visibility into your system's performance, optimizing it efficiently is an impossible task.
Finally, adopt an iterative approach with continuous evaluation and feedback. Building an enterprise-grade RAG system is an ongoing journey, not a one-time project. Start with a simpler implementation, measure everything—accuracy, latency, generation quality—and then layer on more advanced patterns 6. Establish a robust feedback ecosystem, incorporating user feedback mechanisms and regular review cycles to drive continuous improvement 2. Use RAG-specific evaluation metrics like context precision, context recall, and faithfulness to ensure the generated answers adhere to the retrieved context 25. This iterative cycle of building, measuring, and learning ensures your RAG system evolves with your enterprise's needs and technological advancements.
Looking ahead, the future of enterprise RAG systems is exciting, pointing towards multi-modal RAG and deeper enterprise integration. Expect to see RAG systems moving beyond text to seamlessly process and retrieve information from images, audio, and video, offering a richer context for LLMs 7. The integration with existing enterprise tools and workflows—from CRM and ERP systems to documentation repositories—will become even more seamless, transforming how businesses leverage their internal knowledge 7. Open-source projects like RAGFlow with its agent capabilities and deep data integration are paving the way for these advanced applications, allowing developers to build and explore these possibilities. For those looking to dive deeper into building intelligent applications, resources like the AI App Builder can provide a starting point. Monitoring advancements in projects showcased in the AppWorld or through community updates in a technical blog will be key to staying at the forefront.
Key Takeaways:
- Security-First Design: Integrate robust access controls and data protection from the initial architectural phase.
- Data Quality is King: Prioritize meticulous data ingestion, preprocessing, and continuous updates for accurate retrieval.
- Optimize for Scale and Performance: Utilize horizontal scaling, caching, and efficient data pipelines, supported by comprehensive observability.
- Iterate and Evaluate: Implement feedback loops and rigorous metrics for continuous improvement and adaptation.
- Embrace Modularity & Future Trends: Design for flexible component replacement and prepare for multi-modal and deeper system integrations.