Claude Sonnet 4.6の革新的進歩とGLM-5との比較:次世代AIモデルの性能と競争環境
はじめに
Anthropicは、最新の大規模言語モデル「Claude Sonnet 4.6」を2026年2月17日(米国時間)、日本時間では2026年2月18日に正式にリリースしました 1。このリリースは、有料会員向けモデル「Opus 4.6」の発表からわずか2週間以内に行われ、AnthropicのAIモデル開発の急速なペースを示しています 2。
Claude Sonnet 4.6は「Sonnet」シリーズ最大のアップグレードとされており 1、特にPC操作能力、コーディング能力、コンテキストウィンドウの拡張において目覚ましい進歩を遂げています。具体的には、複雑なスプレッドシートの操作、マルチステップのWebフォーム入力、複数のブラウザタブ間の移動といったコンピューター操作において、人間に匹敵するレベルに達しています 1。また、ベータ版として最大100万トークンのコンテキストウィンドウを備え 1、大規模なコードベースや長文資料を一度に処理することが可能になりました 3。さらに、大幅に強化されたコーディングスキルを提供し 4、エージェント的なコーディングや検索操作において高い成功率を示しています 5。
これらの性能向上は、強力なベンチマーク結果によって裏付けられています。AIがOSをどれだけ適切に扱えるかを測るベンチマーク「OSWorld」では、人間の基準レベルのスコアを達成し 3、歴代のSonnetモデルで最高スコアを記録しました 6。そのコーディング性能は、従来の上位モデル「Opus」の旧バージョンに匹敵する水準に達しており 3、「OpusレベルのコーディングをSonnet価格で提供する」とAnthropicは謳っています 7。一部の「経済的価値を持つ実務タスク」においては、最上位モデルであるClaude Opus 4.6を上回る性能を示したケースも報告されており 7、その実用性にも期待が寄せられます。
本稿では、Anthropicが発表したこの最新モデル「Claude Sonnet 4.6」の画期的な性能と、それを裏付ける具体的なベンチマーク結果について詳細に検証することを目的とします。近年、AI技術の進化は目覚ましく、GLM 5やClaude 4.5といった競合モデルとの性能比較は、各モデルの強みと今後の発展性を見極める上で不可欠です。Sonnet 4.6の登場は、この競争環境に新たな局面をもたらし、特に費用対効果の面で注目に値します。
本記事では、まずSonnet 4.6の主要な特徴と前バージョンからの改善点を明らかにし、次に多様なベンチマークにおける具体的な性能評価を深掘りします。さらに、基盤となる技術的進歩、新しいユースケース、開発者への影響を探るとともに、現在の制限、トレードオフ、そして将来のロードマップについても考察を加えます。
Claude Sonnet 4.6の卓越した性能とベンチマーク結果
Anthropicは、2026年2月17日(米国時間)、日本時間では2026年2月18日に最新の大規模言語モデル「Claude Sonnet 4.6」を正式にリリースしました1。このリリースは、有料会員向けモデル「Opus 4.6」の発表からわずか2週間以内に行われ、AnthropicのAIモデル開発の急速なペースを示しています2。Sonnet 4.6は「Sonnet」シリーズ最大のアップグレードであり1、Sonnet 4.5から大幅な性能向上を果たしています1。その卓越した性能は、多岐にわたるタスクで顕著に現れています。
PC操作能力の画期的な向上とOSWorldベンチマークでの人間レベルの達成
Claude Sonnet 4.6は、コンピューターの操作(Computer Use)において画期的な進歩を遂げています1。複雑なスプレッドシートの操作、マルチステップのWebフォーム入力、複数のブラウザタブ間の移動といったタスクで、人間に匹敵するレベルに達しました1。AIがOSをどれだけ適切に扱えるかを測るベンチマーク「OSWorld」では、人間の基準レベルのスコアを達成し3、歴代のSonnetモデルで最高スコアを記録しています6。これにより、APIが提供されていないレガシーシステムや社内ツールでも、AIエージェントが画面を操作することで自動化の対象にできる可能性を広げています7。
拡張された100万トークンのコンテキストウィンドウと強化されたコーディング能力
Sonnet 4.6は、ベータ版として最大100万トークンのコンテキストウィンドウを備え1、大規模なコードベースや長文資料を一度に処理することが可能になります3。これにより、より複雑な情報処理や、長時間の対話においても一貫性を保つことができます。
また、コーディングスキルも大幅に向上しており4、特にエージェント的なコーディングや検索操作において高い成功率を示します5。より細かな指示にも忠実に従えるようになった点は特筆すべきです3。GitHub Copilot Pro, Pro+, Business, Enterpriseユーザー向けにも一般提供され5、コーディング性能は、従来の上位モデル「Opus」の旧バージョンに匹敵する水準に達しています3。Anthropicはこれを「OpusレベルのコーディングをSonnet価格で提供する」と謳っています7。
多様なタスク対応と安全性
Claude Sonnet 4.6は、コーディング、長文推論、エージェント計画、知識労働、デザインといった幅広い領域で性能が改善されています1。内部テストでは、幻覚や追従性を示す傾向が低いことが確認されており8、プロンプトインジェクションに対する耐性がSonnet 4.5と比較して大幅に向上し、Opus 4.6と同程度の耐性を備えています3。
印象的なベンチマーク結果
AnthropicはSonnet 4.6について、具体的なベンチマーク結果を公表しており、その性能の高さが裏付けられています。
- OSWorld: 人間基準レベルを達成し、歴代Sonnetモデルで最高スコア3。
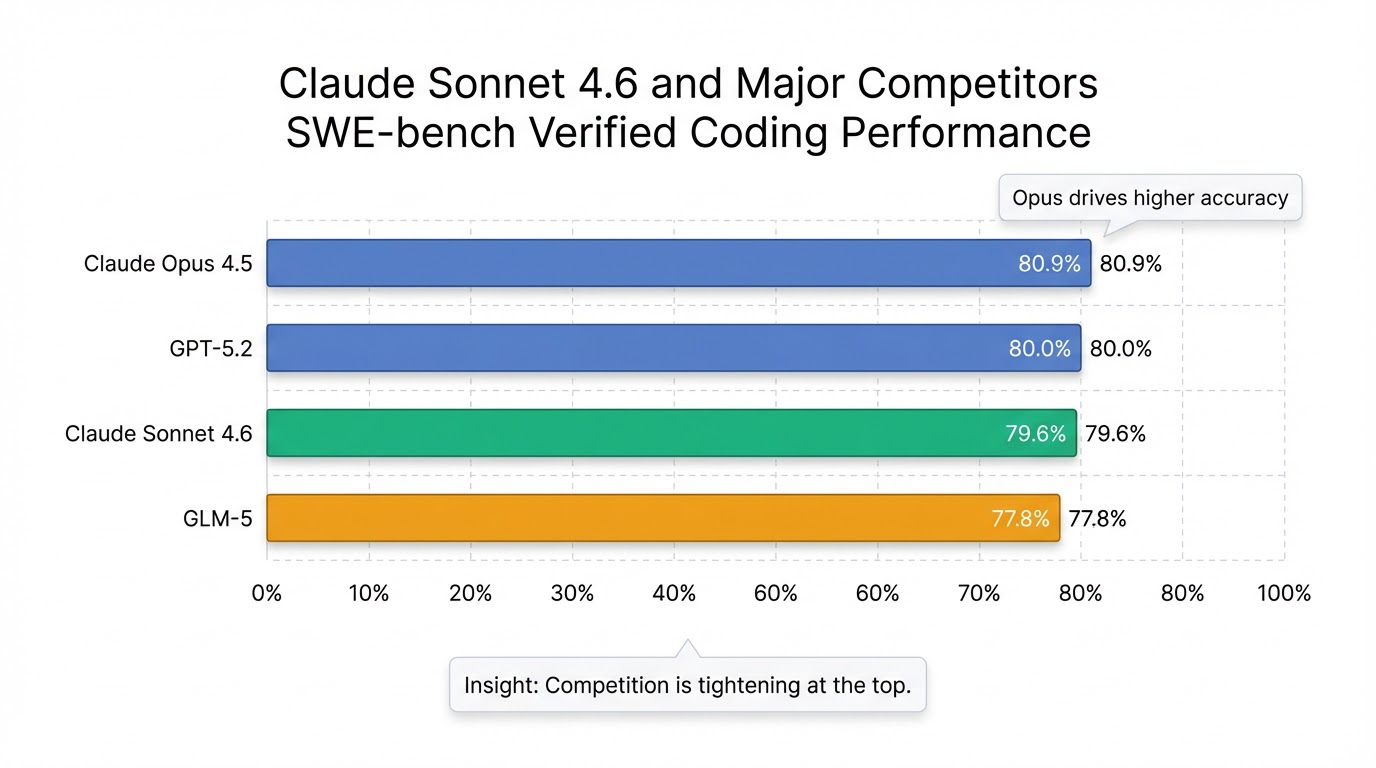
- SWE-bench Verified: コーディング性能は79.6%を記録し8、Claude Codeでの早期テストではSonnet 4.5より70%、Opus 4.5に対しても59%の確率で好まれました6。
- 経済的価値のある実務タスク: Agentic Financial AnalysisやOffice tasksにおいて、GoogleのGemini 3 ProやOpenAIのGPT 5.2を凌駕し、Anthropic自身のOpus 4.6をも上回る性能を発揮しています8。
- Vending-Bench Arena: 長期的な投資戦略を自律的に組み立て、Opus 4.6や従来のSonnet 4.5よりも高い利益を出す実績を示しました7。
- その他のベンチマーク: GPQA Diamondで89.9%、ARC-AGI-2で58.3%、MMMLUで89.3%、Humanity's Last Examでツール使用時49.0%、ツール不使用時33.2%のスコアを達成しています8。
以下のグラフは、Claude Sonnet 4.6の主要なベンチマーク結果を視覚的に示しています。
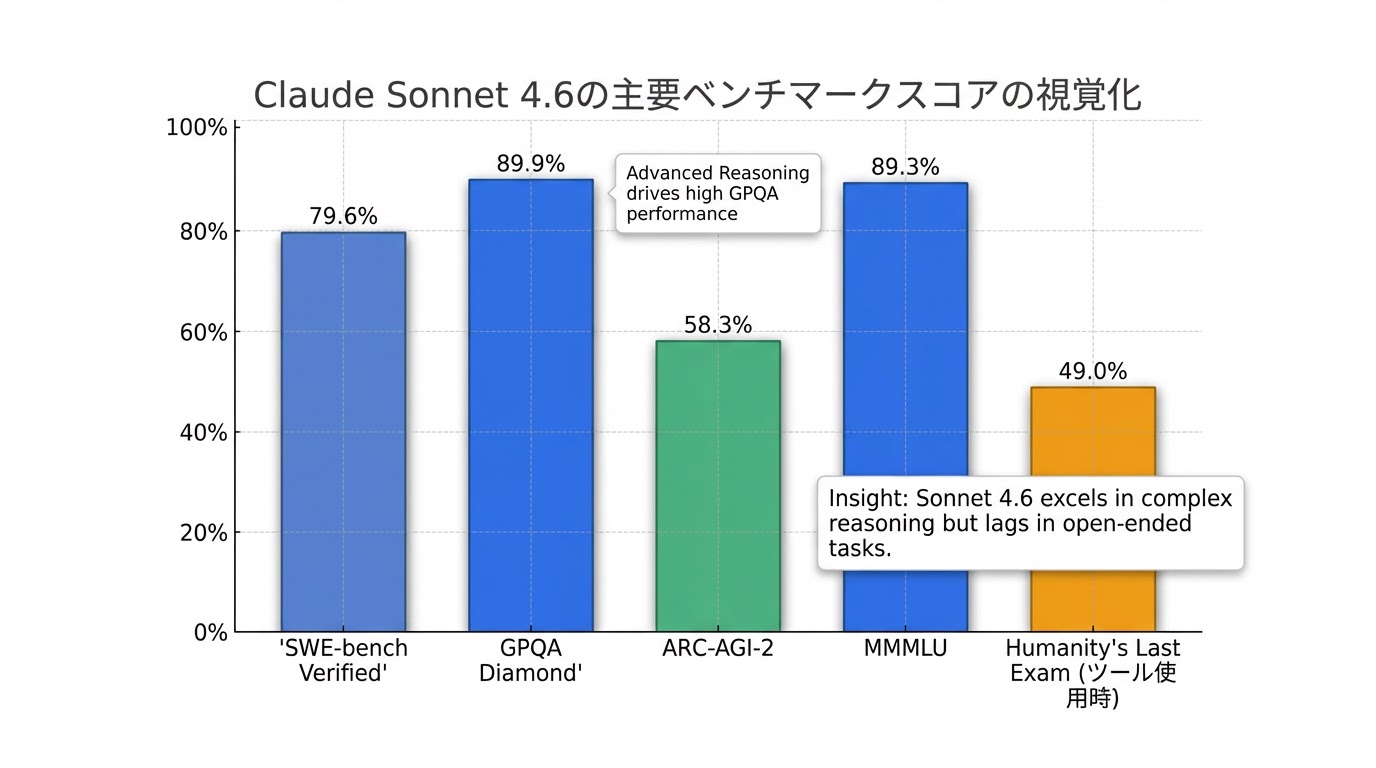
これらの結果は、Sonnet 4.6が幅広い分野で非常に高い性能を発揮することを示唆しており、特に実務タスクやコーディングにおいて優れた能力を持つことが証明されています。
| ベンチマーク項目 | スコア (Sonnet 4.6) | 比較対象 |
|---|---|---|
| OSWorld | 人間基準レベル | 歴代Sonnetモデル最高 |
| SWE-bench Verified | 79.6% | Sonnet 4.5より70%好評価、Opus 4.5より59%好評価 |
| GPQA Diamond | 89.9% | |
| ARC-AGI-2 | 58.3% | |
| MMMLU | 89.3% | |
| Humanity's Last Exam | ツール使用時 49.0% | Opus 4.6より低い |
| Humanity's Last Exam | ツール不使用時 33.2% | |
| Agentic Financial Analysis / Office tasks | Opus 4.6、Gemini 3 Pro、GPT 5.2を上回る | |
| Vending-Bench Arena | Opus 4.6、Sonnet 4.5より高い利益 |
競合モデルとの比較考察(GLM 5とClaude Sonnet 4.6の関連性)
Anthropicが最新の大規模言語モデル「Claude Sonnet 4.6」を2026年2月17日(米国時間)にリリースしたことは、AIモデル市場に大きな注目を集めています 1。このモデルは「Sonnet」シリーズ最大のアップグレードと位置づけられ 1、特にPC操作能力の向上や、ベータ版ながら最大100万トークンのコンテキストウィンドウを備えるなど、Sonnet 4.5から大幅な性能向上を果たしています 1。そのコーディング性能は、従来の上位モデル「Opus」の旧バージョンに匹敵する水準に達し、「OpusレベルのコーディングをSonnet価格で提供する」と謳われています 3。
一方で、Anthropicのリリースに先立つ2026年2月12日には、Z.ai(旧Zhipu AI)が大規模言語モデルの第5世代フラッグシップモデル「GLM-5」の提供を開始しました 。GLM-5は特に「Agentic Engineering」(長距離のエージェント作業や複雑なシステム開発)向けに設計されており、従来の「コードを書くAI」から「システムを構築するAI」への進化を目指しています 。
GLM-5の概要とアーキテクチャ
GLM-5は、Mixture of Experts(MoE)アーキテクチャを採用しており、総パラメータ数は約7,440億(744B)であるものの、推論時には約400億(40B)のみがアクティブ化されることで、大規模な知識容量を維持しつつ推論コストを削減しています 。コンテキスト長は20万トークン、最大出力は12万8,000トークンを実現し 、28.5兆トークンものデータで事前学習されています 。技術的な特徴としては、DeepSeek Sparse Attention(DSA)の初統合によるトークン効率の向上と 、非同期強化学習("Slime"フレームワーク)による実践的なタスク遂行能力の獲得が挙げられます 。また、MITライセンスの下でオープンウェイトが公開される予定です 。
GLM-5はエージェント用途を強く意識した機能群を備えており、思考モード(Thinking Mode)、ストリーミング応答(Streaming)、ツール呼び出し(Function Calling)、長会話向けキャッシュ(Context Caching)、構造化出力(Structured Output)に加え、ツール呼び出し引数の「生成途中」をストリームで受け取れるtool_stream機能を特徴としています 。API料金もフロンティアモデルの中ではリーズナブルな水準に設定されており、入力100万トークンあたり1.00ドル、出力3.20ドルです 9。
主要ベンチマークにおける性能比較
AnthropicはSonnet 4.6の性能向上をベンチマークで示しており、OSWorldベンチマークでは人間のベースラインに匹敵するスコアを達成し、歴代のSonnetモデルで最高スコアを記録しました 3。また、SWE-bench Verifiedでは79.6%を記録し 8、Agentic Financial AnalysisやOffice tasksといった一部の「経済的価値を持つ実務タスク」では、最上位モデルであるClaude Opus 4.6やGoogleのGemini 3 Pro、OpenAIのGPT 5.2を上回る性能を示したケースも報告されています 8。
一方、Z.aiはGLM-5がオープンソースモデルとして世界最高水準に到達したと主張し、主要ベンチマーク結果を公表しています 。特にコーディング性能は高く、SWE-bench Verifiedでは77.8%を記録し、Claude Opus 4.5の80.9%、GPT-5.2の80.0%に迫る水準です 。さらに、BrowseCompでは75.9%でClaude Opus 4.5(67.8%)やGPT-5.2(65.8%)を上回り、全モデル中1位の成績を主張しています 。Humanity's Last Exam (w/ Tools)でもGLM-5が50.4%を記録し、Claude Opus 4.5、Gemini 3 Pro、GPT-5.2を上回るスコアであると述べています 9。
以下のチャートは、主要ベンチマークにおけるGLM-5と主要競合モデルの比較を示しています。
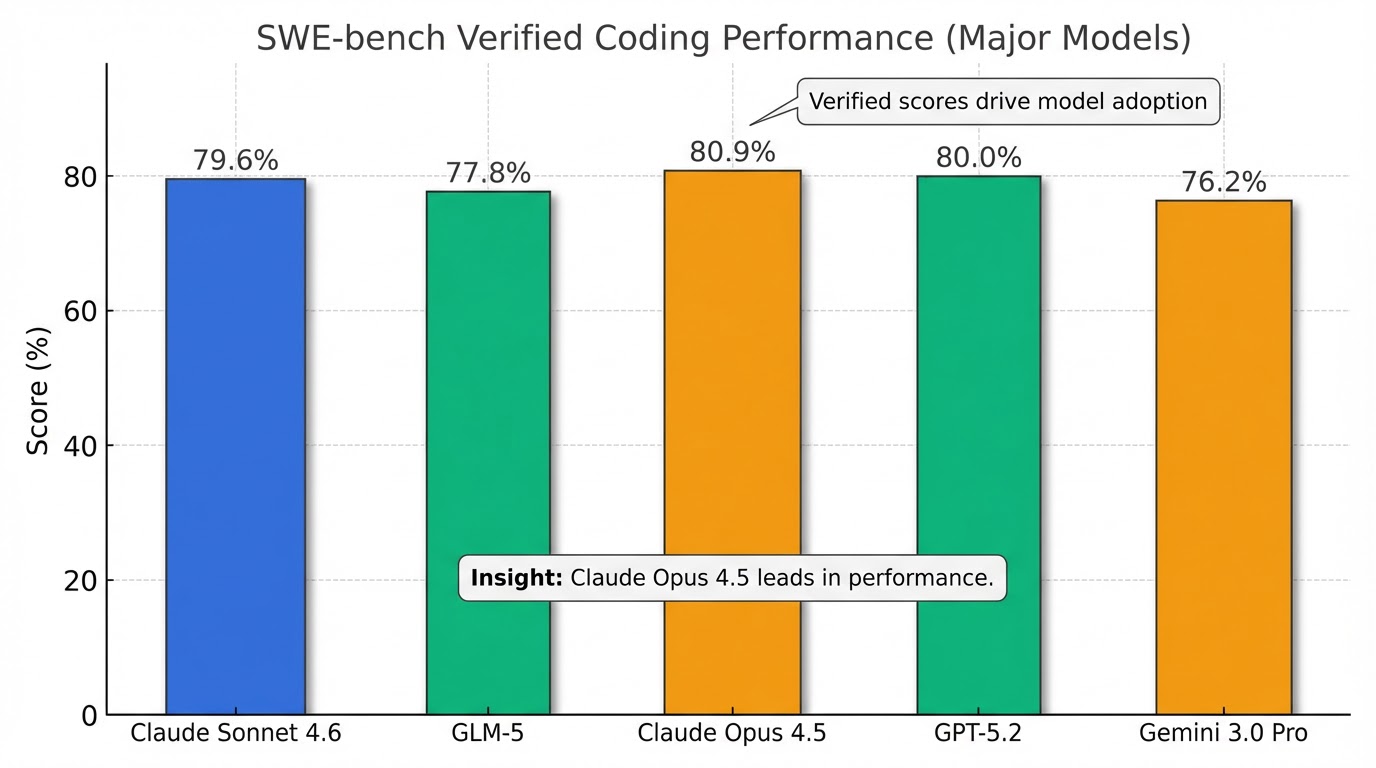
これらのデータから、GLM-5は特にBrowseCompやHumanity's Last Exam (w/ Tools)といったエージェント的タスクの領域で非常に高い性能を発揮し、コーディング能力においてもClaude Opus 4.5やGPT-5.2といった最上位モデルに肉薄していることが分かります。Claude Sonnet 4.6もSWE-bench Verifiedで79.6%とGLM-5を上回るスコアを達成しており、それぞれのモデルが特定の領域で強みを持っていることが見て取れます 。
コンテキスト長、最大出力、API価格の比較
モデルの利用コストと実用性を測る上で、コンテキスト長、最大出力、そしてAPI価格は重要な要素です。
| モデル名 | コンテキスト長 | 最大出力 | 入力料金(100万トークンあたり) | 出力料金(100万トークンあたり) |
|---|---|---|---|---|
| GLM-5 | 20万トークン | 12万8,000トークン | 1.00ドル | 3.20ドル |
| Claude Sonnet 4.6 | 100万トークン (beta) | N/A | 3.00ドル | 15.00ドル |
| GPT-5 | 40万トークン | 12万8,000トークン | 1.25ドル | 10.00ドル |
| Claude Opus 4.5 | 20万トークン | N/A | N/A | N/A |
| Gemini 3 | 100万トークン | 6万4,000トークン | N/A | N/A |
| GPT-4o | 12万8,000トークン | N/A | 2.50ドル | 10.00ドル |
| Gemini 1.5 Pro | 100万トークン | N/A | 3.50ドル | N/A |
上記の比較表から、GLM-5は入力100万トークンあたり1.00ドル、出力3.20ドルという価格設定で 9、Claude Sonnet 4.6の入力3.00ドル、出力15.00ドル やGPT-5の価格と比較して、非常に競争力のあるコストパフォーマンスを提供していることが明らかです 。また、GLM-5の最大出力12万8,000トークンは、長いコード生成や設計書、長距離エージェントのログを含む会話などで有利に働きます 。コンテキスト長では、Sonnet 4.6がベータ版で最大100万トークンを提供するものの 、GLM-5の20万トークンも実用上十分な長さであり、特にキャッシュ入力が安価であるため、大量のコンテキストを繰り返し参照するエージェント型ワークフローでコスト効率が高まります 。
GLM-5とClaude Sonnet 4.6の市場における強みと弱み、最適なユースケース
GLM-5の強みとユースケース: GLM-5は「Agentic Engineering」への特化が最大の強みであり、複雑なシステム工学や長距離エージェントの実行に最適な機能セットを備えています 。特に、コーディング性能の高さ 、DSAとMoEアーキテクチャによるトークン効率とコスト意識の高さ 、そして競合モデルと比較して低いAPI価格は、開発者にとって非常に魅力的です 。また、ハルシネーション率が低いことも報告されており 、信頼性を重視する用途に適しています。AIコーディングをプロジェクト単位で進めたい開発者や、最大12万8,000トークンという長い出力を活用したいユーザーにおすすめです 。
Claude Sonnet 4.6の強みとユースケース: Claude Sonnet 4.6は、PC操作能力の飛躍的な向上により、複雑なスプレッドシート操作やマルチステップのWebフォーム入力など、現実世界のオフィスワークタスクにおける人間の基準レベルに到達しています 。100万トークン(ベータ版)の拡張されたコンテキストウィンドウは、大規模なコードベースや長文資料の処理を可能にし 、Opusレベルのコーディング性能をSonnetの価格帯で提供することは、コストパフォーマンスに優れた選択肢となります 。プロンプトインジェクションに対する耐性の向上など、安全性にも配慮されており 、APIが提供されていないレガシーシステムや社内ツールをAIエージェントで自動化するといった新しいユースケースを解き放つ可能性があります 。無料版ClaudeのデフォルトモデルもSonnet 4.6にアップグレードされたことで、幅広いユーザーがその恩恵を受けられます 1。
課題とトレードオフ: GLM-5はテキスト単体モデルであり、マルチモーダル機能が必要な場合はGLM-4.6Vなどの別モデルとの組み合わせが必要です 。また、推論速度はGPT-5.2やClaude Opus 4.5に及ばない場合があります 。一方、Claude Sonnet 4.6もPC操作において「最も熟練した人間には依然として及ばない」という限界を認識しており 4、プロンプトインジェクションのようなセキュリティリスクへの継続的な対策が求められます 。
結論として、GLM-5とClaude Sonnet 4.6は、それぞれ異なる戦略と強みを持つ強力なモデルです。GLM-5はエージェント型開発やコスト効率の高い大規模言語モデル利用を目指す開発者に、Claude Sonnet 4.6は特にPC操作の自動化や広範なオフィス業務、そしてバランスの取れた高性能と安全性を求めるユーザーに適していると言えるでしょう。両モデルは、それぞれの市場領域で高い競争力を持つとともに、AI技術の進化を加速させる存在として注目されています。
まとめ
Anthropicは、Sonnetシリーズ最大のアップグレードとなる大規模言語モデル「Claude Sonnet 4.6」を2026年2月にリリースしました 。このモデルは、PC操作能力の大幅な向上、最大100万トークンに拡張されたコンテキストウィンドウ(ベータ版)、そしてエージェント的コーディングに強みを持つ強化されたコーディング能力を特徴としています 。特に、AIがOSをどれだけ適切に扱えるかを測るベンチマーク「OSWorld」では人間の基準レベルに匹敵するスコアを達成し 、コーディング性能は従来の上位モデルであるOpusの旧バージョンに匹敵すると謳われています 。これにより、「OpusレベルのコーディングをSonnet価格で提供する」という、極めて優れたコストパフォーマンスを実現しており 、一部の経済的価値を持つ実務タスクにおいては、最上位モデルであるClaude Opus 4.6をも上回る性能を示したケースも報告されています 7。
このリリースは、AIモデル開発の急速なペースを示すと同時に 、Z.aiが開発した「GLM-5」のような競合モデルとの市場競争を激化させています。GLM-5は、長距離のエージェント作業や複雑なシステム開発を目的とした「Agentic Engineering」に特化しており 、SWE-bench VerifiedベンチマークではClaude Opus 4.5に迫るコーディング性能を記録し、BrowseCompではOpus 4.5やGPT-5.2を上回るなど、特定の領域で高い競争力を示しています 。また、GLM-5のAPI料金は、Claude Sonnet 4.6と比較して入力で約3分の1、出力で約5分の1と非常にリーズナブルな水準に設定されており、価格競争力も高いです 。
このような激しい競争は、AIエージェントの進化と自動化の新たな可能性を広げています。Claude Sonnet 4.6は、APIが提供されていないレガシーシステムや社内ツールに対してもAIエージェントが画面操作で自動化の対象を拡大できる可能性を示唆し 7、開発者にとってはOpusモデルの約5分の1の価格で同等の性能を利用できるため、新しいユースケースを解き放つことが期待されています 10。しかし、AIの能力が高度化するにつれて、プロンプトインジェクションのようなセキュリティリスクも増加するため 、技術発展と安全性への継続的な取り組みが不可欠であると言えます。今後の大規模言語モデル市場は、性能、コスト、安全性、そして特定の用途への最適化という多角的な視点から、さらなるイノベーションが進むでしょう。