DeepSeek's New Frontier: Unveiling the 1 Million Token Context Window
Introduction: DeepSeek's Latest Innovation
DeepSeek is currently rolling out and preparing for the official launch of a new generation large language model, often referred to as DeepSeek V4 and specifically named MODEL1 in some announcements . A phased rollout test around February 11 brought a significant update to the DeepSeek app, with users reporting the update around the same time .
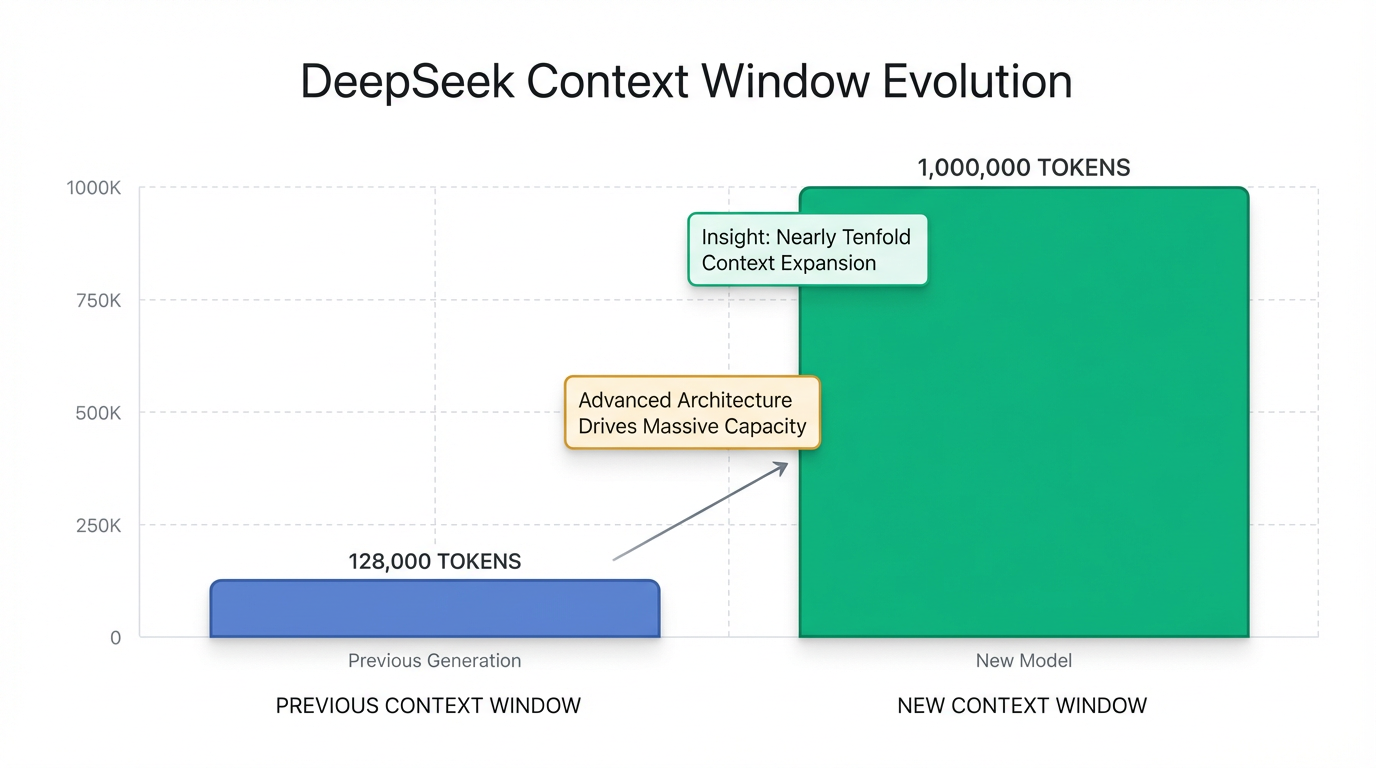
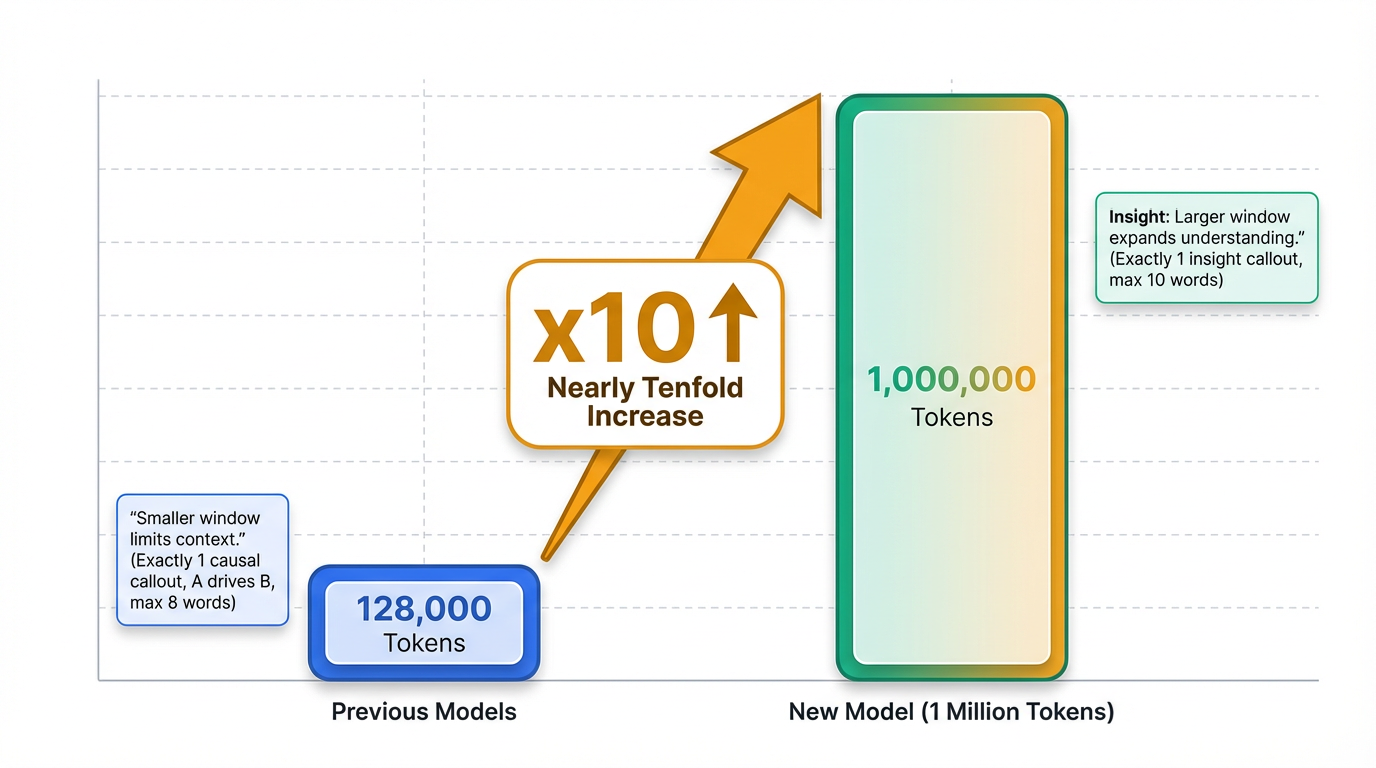
The core feature of this new model is a confirmed 1 million token context window 1. This represents a nearly tenfold increase from previous models, which generally supported 128K tokens 2. DeepSeek's chatbot itself confirmed this expansion 3. Additionally, the model's knowledge base has been updated to May 2025 2.
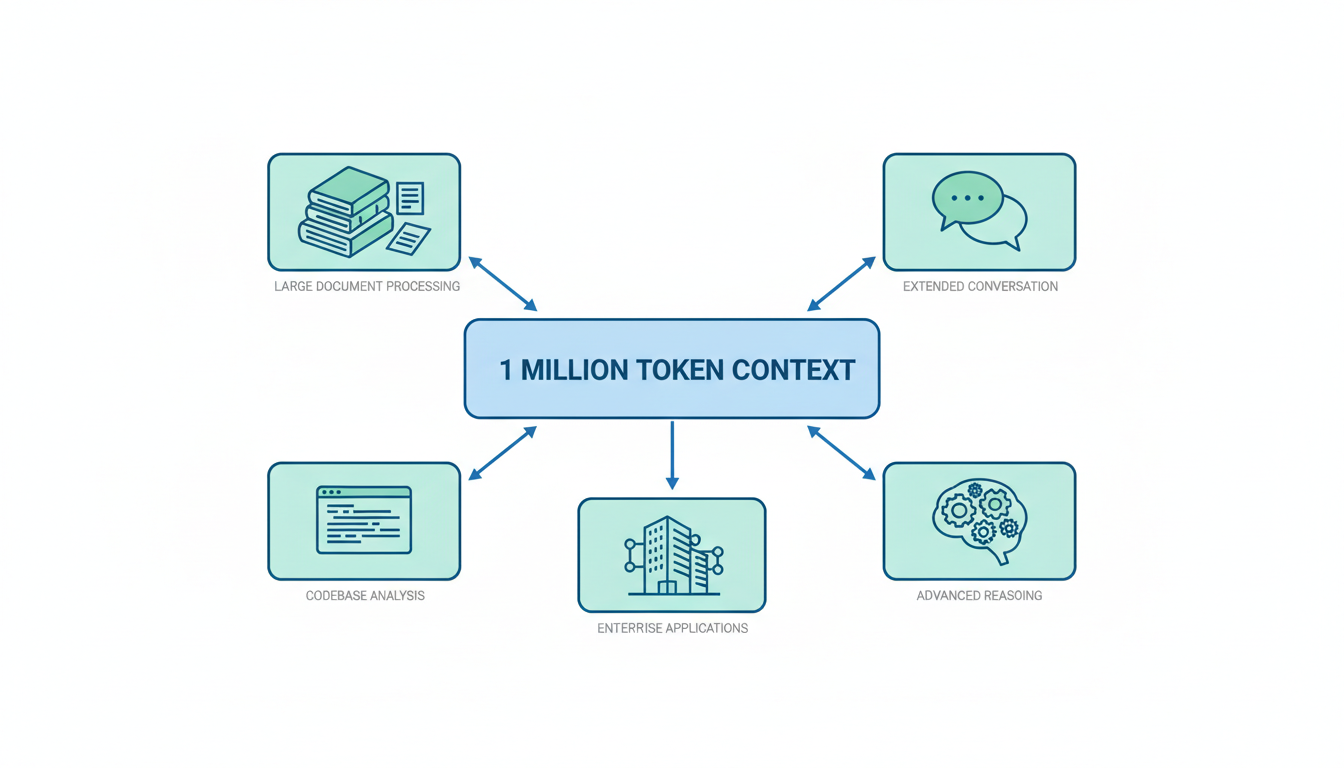
This expanded context window is highly significant, enabling the model to handle entire books and massive codebases in a single prompt . It also facilitates multi-file programming tasks, repository-level bug fixing , long conversations without memory loss, complex math, and reasoning 4. Furthermore, it supports enterprise-scale AI workloads and deep analysis of lengthy documents , with performance noted to be competitive with advanced closed-source models like Gemini 3 Pro and K2.5 2. These innovations are also expected to further compress training and inference costs, offering a pathway to alleviate capital expenditure pressure for LLM and AI application companies .
DeepSeek V4 is broadly expected to formally debut around mid-February 2026 . The current app update is described as either a pre-release version of V4 or the final evolutionary form of the V3 series before V4's official launch 2.
Feature Spotlight: The 1 Million Token Context Window
DeepSeek is rolling out an updated version of its large language model, often referred to as DeepSeek V4 or MODEL1, which features a confirmed 1 million token context window . This represents a significant leap, marking a nearly tenfold increase from previous models that typically supported 128K tokens 2. This update was initially observed by users around February 11 as part of a phased rollout test via the DeepSeek app, with the model's chatbot itself confirming the expansion . This extensive context capacity is a primary feature for DeepSeek's new generation model 1.
This unprecedented context window dramatically expands the capabilities of large language models. It allows the model to process entire books, massive codebases, or extensive legal documents within a single prompt, offering a comprehensive understanding previously unattainable . For developers, this translates to improved multi-file programming tasks and enhanced repository-level bug fixing . Users can engage in long conversations without loss of memory or context, and the model can tackle complex mathematical problems and reasoning tasks more effectively . Furthermore, this capability facilitates enterprise-scale AI workloads and deep analysis of lengthy documents, paving the way for stronger AI agents capable of handling complex, multi-step tasks . The knowledge base of the model has also been updated to May 2025, ensuring it works with the most current information available .
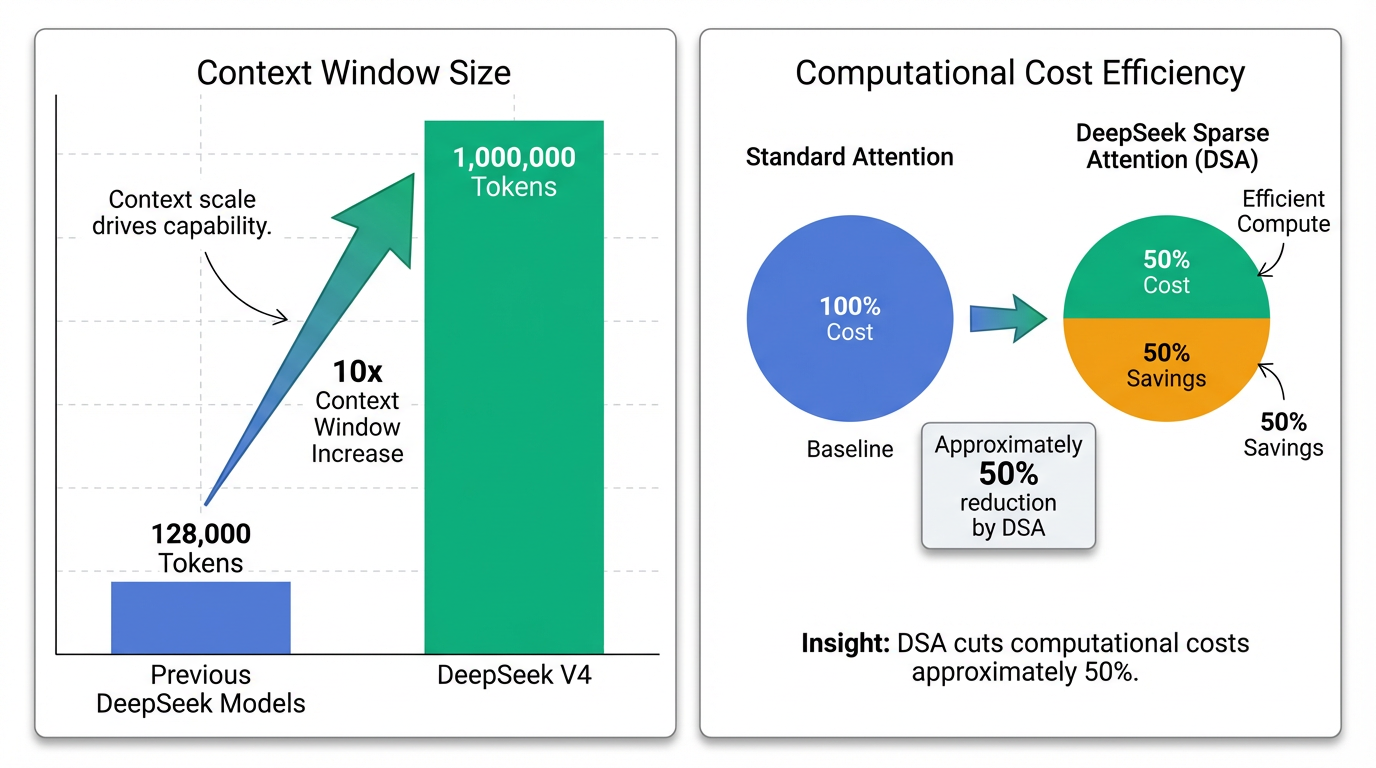
The enablement of this massive 1 million token context window is underpinned by several innovative architectural advancements:
- DeepSeek Sparse Attention (DSA): This attention mechanism allows for context windows exceeding 1 million tokens by reducing computational costs by approximately 50% compared to standard attention 5. DSA employs intelligent sparsity patterns, directing computational resources only to the most relevant parts of the context, enabling efficient processing of long sequences with near-linear scaling (O(N·k) instead of O(N²)) . DeepSeek-V3.2-Exp already incorporates DSA to manage long contexts up to 128K tokens efficiently .
- Engram Conditional Memory: This technology introduces conditional memory mechanisms that decouple memory from computation. Static knowledge, such as entities and fixed expressions, is stored in low-cost DRAM, thereby freeing up expensive GPU memory (HBM) for dynamic computational tasks. Engram is crucial for efficient retrieval from contexts exceeding one million tokens .
- Manifold-Constrained Hyper-Connections (mHC): Designed to optimize the flow of information through transformer networks, mHC improves training stability and convergence efficiency while also addressing computational chip and memory bottlenecks .
- Mixture-of-Experts (MoE): The model leverages an MoE architecture, building on DeepSeek's established expertise in this area for efficient scaling .
- Other Enhancements: The new model also features improvements in key-value cache layout, sparsity handling, FP8 decoding, and various memory optimization techniques, all contributing to its enhanced capabilities and efficiency 6.
These innovations are expected to compress both training and inference costs significantly, offering a pathway to alleviate capital expenditure pressure for companies developing and deploying large language models and AI applications . This makes the powerful capabilities of long-context AI more accessible and affordable.
Technical Breakthroughs Behind the 1 Million Token Context
DeepSeek's new generation large language model, frequently referred to as DeepSeek V4 and identified as 'MODEL1' in some announcements, represents a pivotal advancement in AI capabilities with its confirmed 1 million token context window . This represents an approximate tenfold increase over prior models, which typically supported 128K tokens 2. This significant expansion is made possible by a series of sophisticated architectural innovations designed to address the inherent computational and memory challenges of processing extremely long contexts.
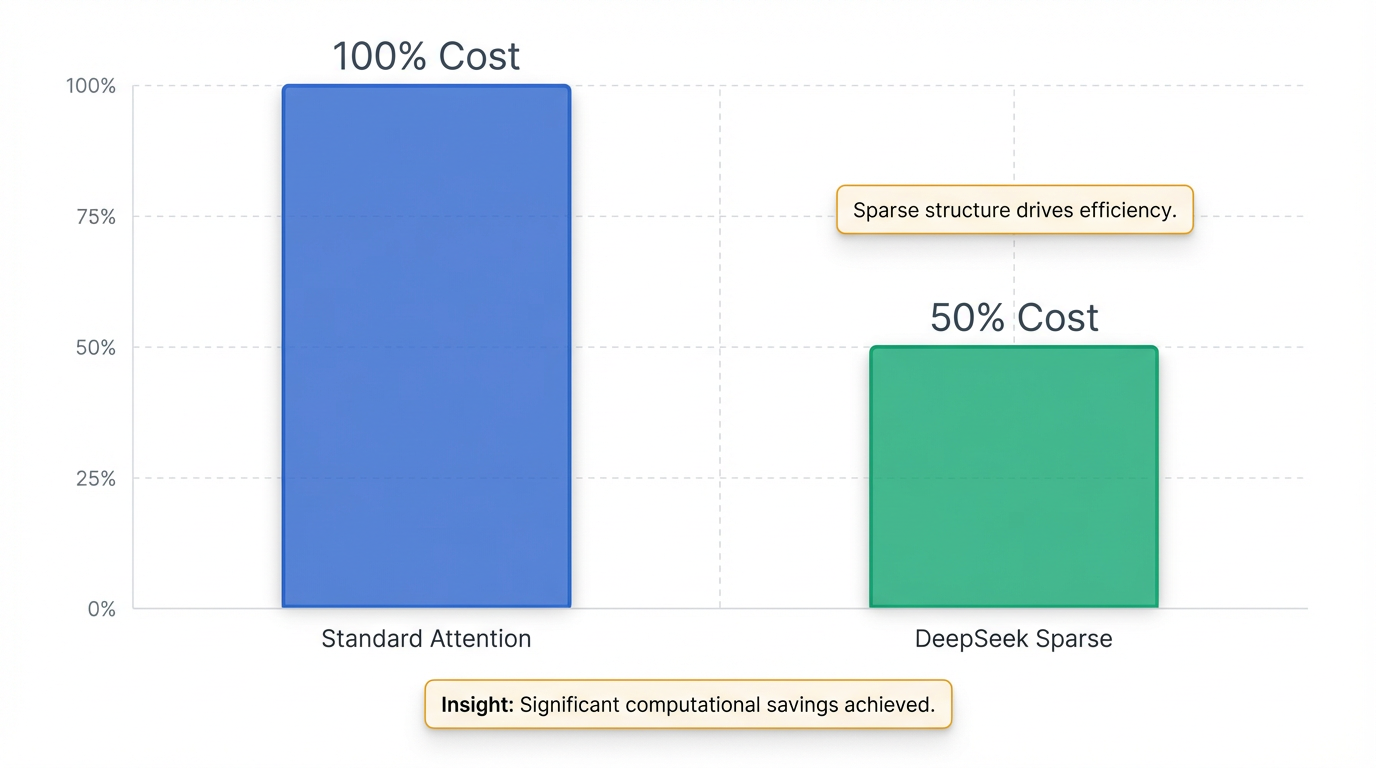
One of the cornerstone advancements is DeepSeek Sparse Attention (DSA). This attention mechanism is fundamental to enabling context windows that can exceed 1 million tokens 5. DSA intelligently employs sparsity patterns to concentrate computational resources on the most relevant parts of the context, effectively reducing computational costs by approximately 50% compared to traditional standard attention 5. This design strategy is also integrated into models like DeepSeek-V3.2-Exp, where it helps manage costs for its 128K token context limit 7.
Another critical innovation is Engram Conditional Memory. This technology introduces conditional memory mechanisms that effectively decouple memory from computation . It strategically stores static knowledge, such as entities and fixed expressions, in more economical DRAM, thereby liberating valuable High Bandwidth Memory (HBM) on GPUs for dynamic computational demands .
Furthermore, Manifold-Constrained Hyper-Connections (mHC) play a crucial role in optimizing the flow of information through transformer networks. This optimization leads to improved training stability and enhanced convergence efficiency . The model also continues to leverage a Mixture-of-Experts (MoE) architecture, an area where DeepSeek has established expertise, facilitating efficient scaling .
In addition to these primary architectural shifts, DeepSeek V4 incorporates several other supporting enhancements. These include advancements in key-value cache layout, refined sparsity handling, FP8 decoding capabilities, and a variety of other memory optimization techniques 6. Collectively, these innovations contribute to highly efficient long-context processing and are anticipated to reduce both training and inference costs, thereby easing capital expenditure pressures for companies developing LLMs and AI applications .
Beyond Context: Other Noteworthy Advancements
DeepSeek's new generation model, frequently identified as DeepSeek V4 or MODEL1, brings forth several crucial advancements that extend beyond its remarkable 1 million token context window . A significant update for this model includes its knowledge base being current up to May 2025, thereby ensuring access to recent information 2.
Further architectural and efficiency enhancements are also integral to the new model. These encompass improvements in key-value cache layout, enhanced sparsity handling, FP8 decoding capabilities, and a range of memory optimization techniques 6. These innovations are anticipated to reduce training and inference costs, offering a potential alleviation of capital expenditure pressure for companies involved with large language models and AI applications 2.
Implications and Potential Impact
The advancements introduced by DeepSeek, particularly the confirmed 1 million token context window, represent a significant paradigm shift in large language model capabilities. These innovations are poised to revolutionize how LLMs are utilized across various applications and industries.
Revolutionizing Long-Context Processing
The 1 million token context window fundamentally transforms how LLMs can be utilized, moving beyond previous limitations . This nearly tenfold increase from previous models, which typically supported 128K tokens, allows for unprecedented data processing within a single prompt .
Addressing Current LLM Limitations
This extended context window directly addresses long-standing limitations of LLMs. It enables the models to handle entire books and massive codebases, as well as sustain extended, complex conversations without memory loss . This significantly improves the model's ability to perform complex reasoning and deep data analysis over vast amounts of information . The architectural innovations effectively tackle the quadratic scaling problem inherent in traditional Transformer models, making such extensive context processing feasible .
Opening New Application Frontiers
The expanded context window unlocks a wide array of new application possibilities across various sectors:
- Code Analysis and Development: Facilitates multi-file programming tasks and repository-level bug fixing, allowing developers to process entire codebases within a single context .
- Enterprise Solutions: Enables enterprise-scale AI workloads and deep analysis of lengthy documents, such as legal contracts, scientific papers, or financial reports .
- Advanced Conversational AI: Allows for highly complex and long-duration dialogues, where the model maintains perfect context of the entire conversation 4.
- Enhanced AI Agents: The ability to process vast amounts of information leads to stronger AI agents capable of handling complex, multi-step tasks by interacting more frequently with underlying large models 2.
Economic and Efficiency Gains
DeepSeek's underlying architectural innovations, such as DeepSeek Sparse Attention (DSA) and Engram Conditional Memory, contribute significantly to efficiency and cost reduction. DSA reduces computational costs by approximately 50% compared to standard attention, allowing for efficient processing of contexts exceeding 1 million tokens 5. Engram Conditional Memory optimizes resource allocation by storing static knowledge in low-cost DRAM, thereby freeing up expensive GPU memory for dynamic computation . These innovations are expected to further compress training and inference costs, offering a pathway to alleviate capital expenditure pressure for LLM and AI application companies, making advanced AI capabilities more accessible and affordable .
Enhancing AI Agent Capabilities
By enabling LLMs to retain and process significantly more information, DeepSeek's new models pave the way for more sophisticated and robust AI agents. These agents can manage intricate, multi-step operations and maintain coherence over extended periods, leading to more reliable and powerful automated systems 2.
Competitive Landscape
This development positions DeepSeek's new models as strong contenders in the competitive AI landscape. The updated model's performance is noted to be competitive with mainstream closed-source models such as Gemini 3 Pro and K2.5 2. Furthermore, internal benchmarks for the upcoming DeepSeek V4 reportedly show it outperforming established models like Claude and GPT series in coding tasks, particularly those involving long code prompts 8. DeepSeek's commitment to releasing V4 as an open-weight model further aligns with its strategy of making powerful AI accessible, potentially fostering innovation across the AI ecosystem 5.
Conclusion: Pushing the Boundaries of LLMs
DeepSeek's new model introduces a confirmed 1 million token context window1, representing a nearly tenfold increase from previous models2 and a significant advancement in the LLM landscape. This expanded context is enabled by groundbreaking architectural innovations such as DeepSeek Sparse Attention (DSA)5, Engram Conditional Memory2, and Manifold-Constrained Hyper-Connections (mHC)2, allowing the model to handle unprecedented scale.
The practical implications of this advancement are vast, including the ability to process entire books and massive codebases in a single prompt4, facilitate multi-file programming tasks and repository-level bug fixing4, and sustain complex, long-form reasoning and conversations without memory loss4. DeepSeek's commitment to potentially releasing an open-weight model with such capabilities5 positions it as a key player in making powerful, long-context AI more accessible and cost-efficient for various applications, by compressing training and inference costs2. The model's potential to drive new applications in AI agents2, advanced code generation, and enterprise-scale analytics4 underscores its transformative contribution to the future of artificial intelligence.