DeepSeek新模型:百万Token上下文与AI新范式
引言:DeepSeek新模型重磅发布
DeepSeek 近期正在对其新一代大模型进行灰度测试,这款模型的核心亮点是支持百万 Token 上下文 1。这一里程碑式的突破,预示着人工智能在理解和处理超长文本方面将达到前所未有的高度。
本次灰度测试于2026年2月11日正式启动,面向部分用户开放 2。业界普遍推测,这可能是即将发布的DeepSeek V4或其V4 Preview/lite版本 3。
该模型的发布显著提升了AI在处理超长文本和复杂任务方面的能力,例如长文档分析、代码库审查以及复杂逻辑推理等 3。凭借百万级上下文处理能力,DeepSeek正在引领行业迈向新的标准,并为AI应用带来革命性的效率和完整性提升 4。
核心亮点解析:百万Token上下文能力
在DeepSeek最新模型的灰度测试中,最引人注目的核心亮点无疑是其突破性的百万Token上下文能力。这项技术被视为人工智能领域的一项重大飞跃,极大地拓展了模型的应用边界和智能化水平。
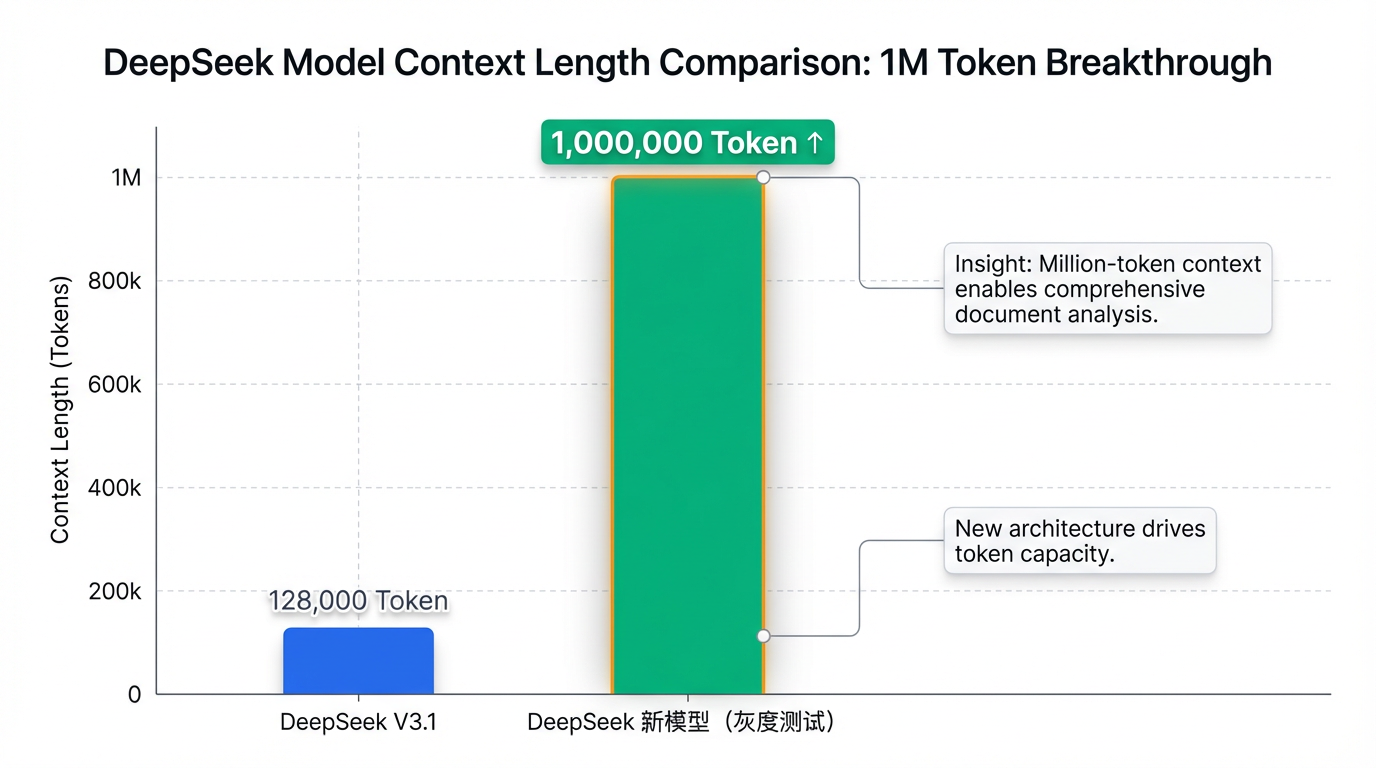
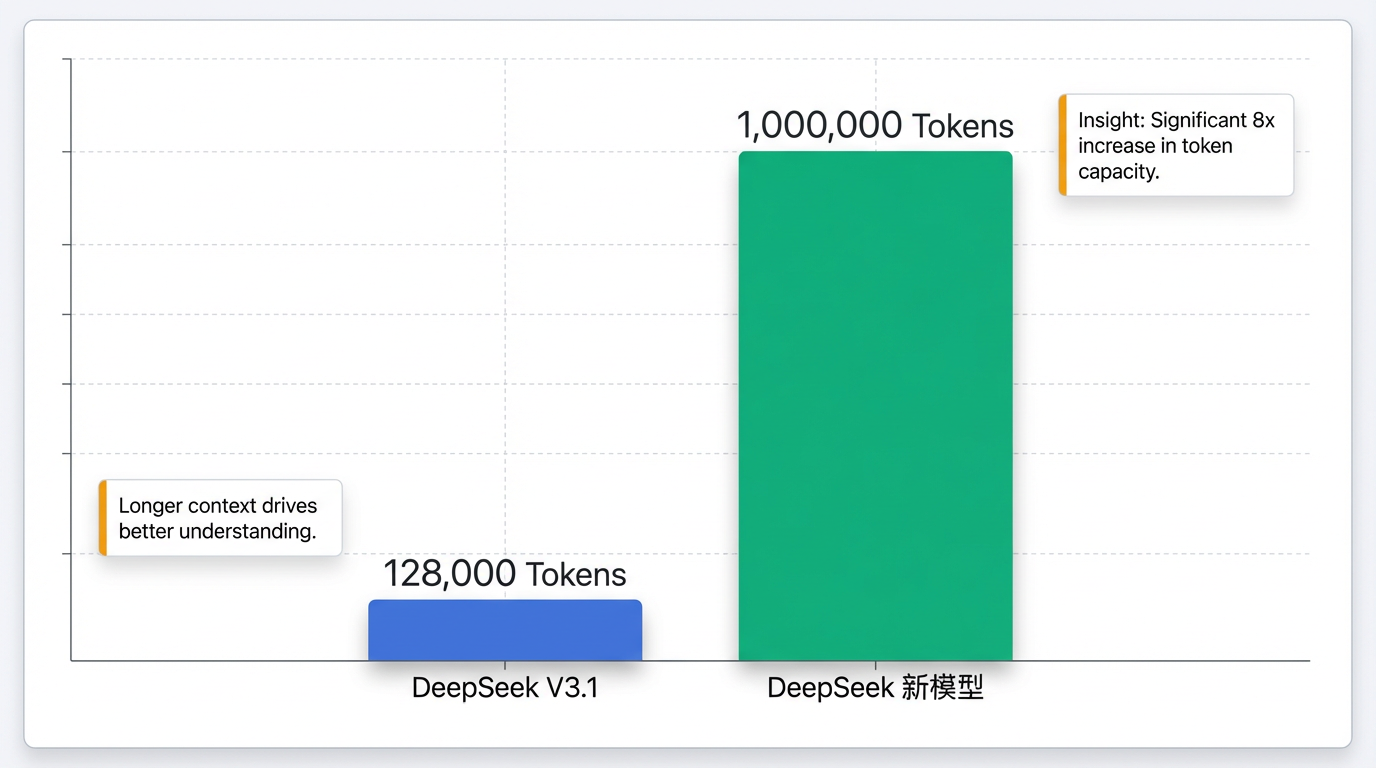
该模型官方描述支持高达1M(百万)Token的超长上下文长度,这一能力远超此前DeepSeek V3.1的128K上下文,这意味着模型能够一次性处理极其冗长复杂的文本信息 2。为了验证这一能力,媒体和用户进行了实测,例如通过上传《三体》全集(约67.8万tokens)等长篇文档,结果显示模型能够顺利解析文本内容并给出合理回应,充分证实了其百万级Token的处理实力 3。
实现这一突破性进展,可能得益于DeepSeek在底层架构上的技术创新。据推测,其可能采用了如mHC(流形约束超连接)和Engram(条件记忆模块)等先进技术。这些技术旨在优化深层Transformer的信息流动效率,并显著降低处理长上下文推理的计算成本 1。
百万Token上下文能力将对AI在多个专业领域的应用带来革命性的提升,显著增强其处理效率和信息完整性 3。
- 长文档处理: 用户可以一次性将整本电子书、复杂的法律合同或厚重的学术论文上传给模型进行分析。模型无需进行分段处理,极大地提高了工作效率和信息分析的连贯性 3。
- 代码分析: 开发者能够将整个项目代码库提交给模型进行审查、优化或调试。模型凭借强大的上下文理解能力,能够洞察跨文件间的代码逻辑关系,从而提供更精准的建议和更高效的错误检测 3。
- 复杂推理: 这种能力对处理长文本、复杂信息和理解具备时效性的信息而言,带来了革命性的提升 4。模型能够更好地理解和分析复杂叙述、多层级关系,并进行深入的逻辑推理。
这种对长文本处理、复杂任务理解和多轮对话能力的提升是全面的。模型能够保持更长时间的记忆和上下文连贯性,在进行多轮深度交互时,能够避免因上下文丢失而导致的逻辑断裂,使得对话更加自然、流畅和富有深度。
当前在全球范围内,能够将上下文处理能力推至百万级别的模型寥寥无几,主要包括Google的Gemini系列和Anthropic的Claude Opus 4.6等国际顶尖产品 1。DeepSeek此次新模型的发布,无疑使其在该领域跻身全球领先行列,彰显了其强大的技术研发实力。
其他引人注目的特性与技术创新
除了在长上下文处理能力上的突破外,DeepSeek新模型及其背后承载的DeepSeek系列技术,还在架构创新、训练效率、性能表现、以及市场策略等多个维度展现出引人注目的特性和领先优势。DeepSeek通过“架构优化+算法创新”的核心理念,成功在通用人工智能(AGI)领域构建了独特的竞争力 5。
一、极致的训练与部署成本优化
DeepSeek模型的一个核心亮点在于其在训练成本和部署效率上的极致优化,显著低于业界同级别模型,打破了传统Transformer架构对算力的高度依赖 。
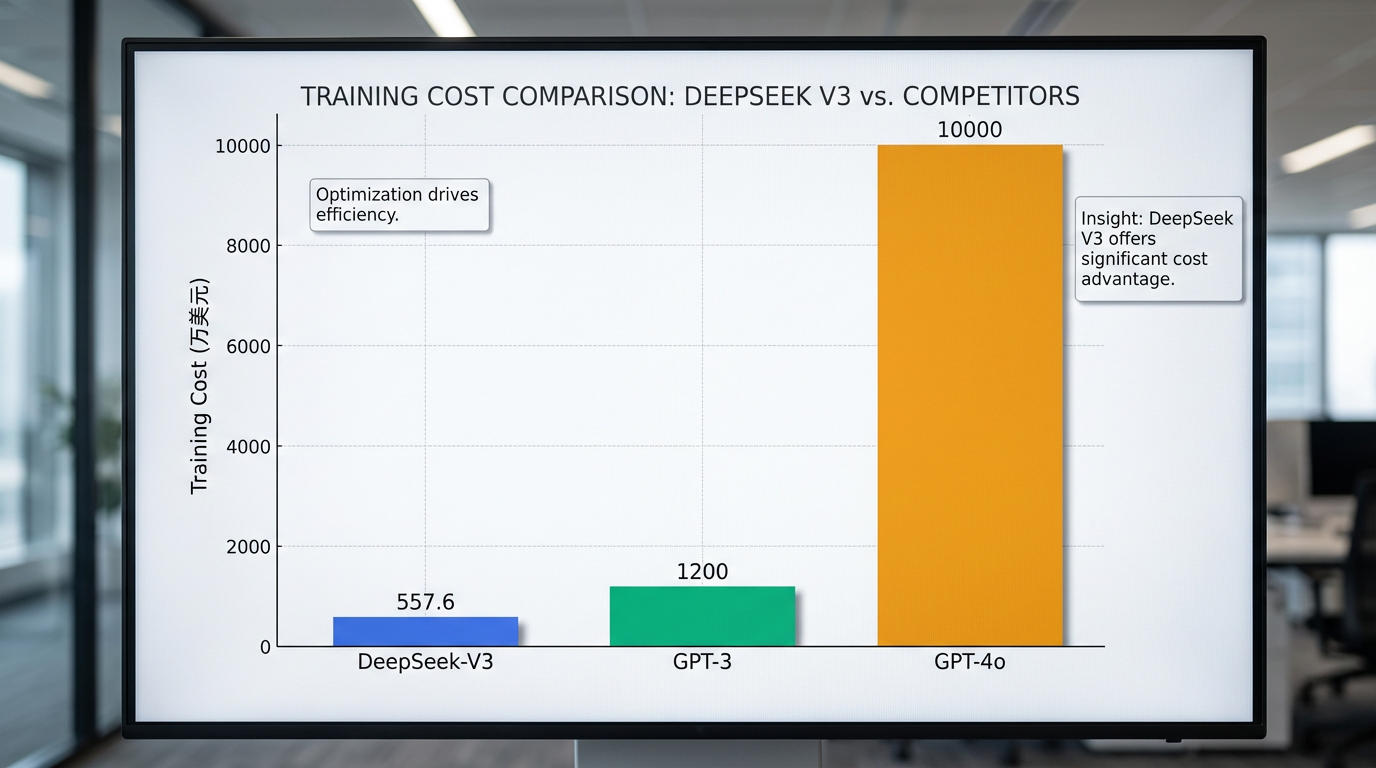
- 低训练成本: DeepSeek-V3的训练成本约为557.6万美元,远低于同期GPT-3的1200万美元 5,甚至不到GPT-4o约1亿美元训练成本的二十分之一 。此外,DeepSeek-R1模型的后训练阶段成本更是低至约29.4万美元 6。
- 创新性架构提升效率:
- 混合专家架构(MoE): DeepSeekMoE是DeepSeek V2和V3的关键创新,通过动态稀疏路由算法,仅激活少量专家网络,显著降低了显存占用达60% ,并实现了4倍的推理速度提升 ,从而扩大了模型容量。
- 多头潜在注意力(MLA): DeepSeek V2引入的MLA技术利用低秩压缩,有效减少了KV缓存占用空间 ,降低了每个Token的计算量和内存消耗,在处理长上下文时优势显著 。
- mHC(流形约束超连接): DeepSeek团队提出的mHC架构解决了大模型在扩容时面临的稳定性难题,为构建更庞大、更深层推理能力的模型提供了可能 7。
- 先进的训练方法:
- FP8混合精度训练: DeepSeek V3采用FP8混合精度训练,在不显著牺牲精度的前提下,大幅减少了内存占用和计算需求,从而降低了硬件成本和能耗 。
- DualPipe跨节点通信与MTP: DeepSeek V3通过优化基础设施,减少流水线气泡,实现高效节点间通信,并采用MTP(Multi-Token Prediction)技术,一次预测多个Token,进一步提升了训练效率 。
- 部署效率优化:
- 自适应推理引擎: 通过动态批处理和模型量化(如8位整数量化INT8),DeepSeek模型在边缘设备部署时,可将模型体积压缩至原大小的四分之一,同时保持98%的推理精度 ,响应延迟从120毫秒降至35毫秒 。
- 动态剪枝: 在算力受限场景中,DeepSeek的动态剪枝技术显著降低了资源需求,在NVIDIA A100 GPU上运行百亿参数模型时,峰值内存占用仅为同规模模型的65%,能耗降低了22% 8。
二、强大的推理能力
DeepSeek-R1作为DeepSeek在推理能力上的集中体现,通过创新性的强化学习方法,展现出超越传统模型的推理水平。
- 纯强化学习驱动: DeepSeek-R1完全依赖GRPO(Group Relative Policy Optimization)强化学习算法进行训练 ,摆脱了对人工标注数据的依赖,使模型通过自我博弈持续进化,在数学推理能力上表现尤为出色 。GRPO通过蒙特卡洛采样取代价值模型,有效降低了计算和存储开销 9。
- 思维链与R1-Zero的自我进化: DeepSeek-R1在生成答案前会进行大量的思维链过程,分解问题并进行多步推理 。R1-Zero模型在训练过程中展现出“涌现”现象,学会了搜索、反思、顿悟和纠错等行为,尤其在困难推理问题上的能力随训练显著提升 。
- 推理能力蒸馏: DeepSeek证实其推理能力可以有效蒸馏到更小的模型中,通过监督微调(SFT)将教师模型(DeepSeek-R1)的知识迁移到学生模型,使其在推理基准测试中表现卓越 。
三、多模态融合进展
尽管灰度测试的新模型目前仍为纯文本模型,仅支持文本和语音处理 ,但DeepSeek在多模态领域已取得显著进展,拥有专门的多模态模型产品。
- DeepSeek-VL2和Janus-Pro: DeepSeek已发布用于高级多模态理解的DeepSeek-VL2以及进军文生图领域的Janus-Pro多模态大模型 。
- 跨模态注意力机制: DeepSeek通过改进的Transformer架构,采用跨模态注意力机制实现了文本、图像、语音的联合建模 。在医疗影像诊断等场景中,模型能够同时解析CT影像和患者病历文本,生成综合诊断建议 8。
- 动态模态权重分配: 模型可根据任务需求自动调整各模态的贡献度,例如在医疗影像诊断中优先依赖CT图像进行分析 10。
四、卓越的代码能力
DeepSeek模型在编程和代码处理方面也表现出领先水平。
- DeepSeek-V3在编程任务(HumanEval-MUL)中准确率达到82.6% 11。
- 有传闻指出,即将发布的DeepSeek-V4有望在编程任务上超越Anthropic的Claude和OpenAI的GPT系列 7。
五、严格的安全性考量
DeepSeek高度重视模型的安全性,并建立了多层防护机制。
- 风险控制体系: DeepSeek-R1通过风险控制体系,包括过滤潜在风险对话和基于模型审查风险,来管理内容安全 6。
- 防御越狱攻击: 虽然R1模型在防御越狱攻击方面已有所表现,但DeepSeek仍在持续改进 。同时,DeepSeek还致力于数据脱敏和部署模型监控以增强安全性 12。
六、开放的开源策略
DeepSeek采用开放的开源策略,推动了人工智能技术的普及和发展。
- MIT许可证开源: DeepSeek-R1采用MIT许可证开源,允许无限制的商业应用,被认为是目前最开放的前沿模型之一 。
- 公开技术文档: DeepSeek公开模型权重和详尽的技术文档(如R1论文从22页扩充至86页),促进了全球AI社区的协作和技术普及 。
七、与竞品的差异化优势
DeepSeek新模型在性能、价格和技术路线上与当前主流大模型形成了显著的差异化竞争 13。
- 性能对标:
- 成本效益优势:
- 独特的技术路线:
- 算法突破替代硬件依赖: DeepSeek通过其创新性架构和算法(如MoE、MLA、FP8、GRPO)实现了低成本高效训练,证明了算法创新能够有效应对高端芯片受限的挑战,打破了美国在AI领域的算力护城河 。
- 推理训练: DeepSeek-R1独立探索出基于大规模强化学习的大语言模型推理技术路线,避开了业界广泛思索的Search+PRM(过程奖励模型)“误区” 9。
- 开源策略: DeepSeek的开源策略直接挑战了OpenAI等闭源巨头的市场地位,推动了AI领域竞争格局的重塑,并成为全球开源大模型领域的标杆 。
- 市场地位与挑战: DeepSeek-R1发布后七天内用户增长至1亿,曾登顶中国和美国苹果应用商店免费APP下载榜,超越ChatGPT 。然而,随着OpenAI O3系列、GPT-4.5、Claude Opus 4、Google Gemini 2.5 Pro等竞争模型的相继发布,DeepSeek也面临激烈的市场竞争,其消息份额从高峰期有所下降 15。此外,国际地缘政治也对其出海发展带来结构性障碍 。
市场影响与未来展望
DeepSeek新模型的发布,不仅是技术层面的突破,更是对全球AI产业格局的一次深刻重塑。本节将深入分析DeepSeek新模型发布后对AI行业格局、应用开发可能带来的深远影响,并探讨其在实际生产和生活中的潜在应用价值。
1. 初期反响:行业震动与全球关注
DeepSeek-V3和R1模型的发布,以其独特的“成本技术”路线、开源策略和卓越效能,在中国乃至全球AI领域引发了前所未有的关注和积极反响。业界普遍将其视为中国AI的“斯普特尼克时刻”,标志着中国在全球AI竞争中异军突起 。模型发布后,被形象地誉为“来自东方的神秘力量” 16。
国际科技巨头也纷纷对其技术实力表示认可。英伟达CEO黄仁勋称其为“送给全球AI行业的礼物”,Meta首席科学家杨立昆肯定了DeepSeek在开源和技术优化上的重大突破 16。微软、OpenAI、亚马逊等企业均对其技术实力表示认可,其中亚马逊的AWS Bedrock率先接入了DeepSeek模型 16。微软CTO科特甚至承认,DeepSeek以传统模型1/5的成本实现了微软90%的性能 17。美国前总统特朗普也对DeepSeek“低价但不低质”的AI产品及其带来的积极影响予以评价,并认为这给美国科技行业敲响了警钟,敦促美国企业需全力以赴与中国企业竞争 16。
DeepSeek的崛起也迫使竞争对手加速行动。其开源策略促使国际巨头如OpenAI加快商业化进程,密集推出Agent等前沿产品,并快速发布o3-mini和GPT4.5,甚至宣布GPT-5将尽快发布并给予免费用户一定使用额度 。谷歌紧急重启了已搁置的“太极计划”,要求AI团队“像DeepSeek一样思考”,甚至允许工程师使用竞争对手的框架 17。Meta也加速了其开源策略的迭代 18。此外,DeepSeek的出现导致英伟达股价曾单日暴跌17%,市值蒸发4.3万亿人民币,有分析师直言“DeepSeek证明,不用H100也能玩转AI”,硬件厂商甚至连夜修改PPT主推支持FP8精度的特供版 19。这标志着中国AI正从“技术追随者”向“自主创新者”转型,打破了中国在AI核心技术领域难以原创的固有认知 16。有学者指出,“AI能力没有护城河”,且“资源受限反而激发了中国团队的创造力” 16。
2. 市场表现:从爆发式增长到激烈竞争
DeepSeek新模型在发布初期展现出惊人的市场接受度。DeepSeek-R1在发布后仅7天内用户量突破1亿,刷新了互联网应用程序用户增长速度的纪录 20。上线一周即登顶中国、美国等140多个国家的应用商店下载榜首,日活用户突破4000万 21。发布前18天内实现1600万次下载,约为ChatGPT同期下载量的2倍,曾登顶苹果App Store下载排行并稳居美国Google Play榜首 17。2025年2月1日,DeepSeek日活突破3000万,成为史上最快突破此日活的APP 17。
然而,在后续的市场表现中,DeepSeek也面临激烈的市场竞争和地缘政治挑战。根据Poe发布的《2025年春季人工智能模型使用趋势》报告,DeepSeek R1的消息份额从2月中旬的7%高峰下降至4月底的3%,下降超过50%,表明其影响力有所减弱 。在权威大模型评测平台Chatbot Arena LLM Leaderboard上,DeepSeek R1已下滑至第9位 。Sensor Tower旗下的Data.ai数据显示,DeepSeek在全球下载排名中稳定在第11位,但在用户活跃度、使用时长和用户渗透率等排名中,前100名均未见其身影 。苹果App Store美国排名也跌出前100,与发布初期的表现形成鲜明对比 。
用户反馈指出DeepSeek R1的主要问题是“推理速度慢”,尤其在高频交互场景中,这削弱了其竞争力 。同时,随着竞争对手如Gemini 2.5 Pro、OpenAI o3和o4系列的推出,用户注意力被更优质的模型吸引,形成了新旗舰模型“快速蚕食”旧模型的局面 。此外,DeepSeek缺乏与大厂生态的深度绑定,不如OpenAI、Gemini与Azure/Google,以及国内Qwen与阿里、豆包与字节跳动的整合 。
针对这些挑战,DeepSeek于5月28日发布了R1的升级版本DeepSeek-R1-0528。虽然并非R2,但据网友测评,其性能和体验有明显提升,消除了40%-45%的幻觉 。新版本强化了深度思考能力(平均思考token数从12K增至23K),显著提升了复杂推理任务的表现 。在Live CodeBench权威大模型测评中,R1-0528排名第四,在Artificial Analysis报告中排名第二 。
3. 深远影响:技术范式重塑与应用生态革新
DeepSeek新模型的发布及其开源策略,正在推动AI行业从传统的“技术竞赛”转向“效率革命”,重塑产业格局并加速应用开发。
技术范式变革:从“暴力堆料”到“效率革命”与“降本优先”
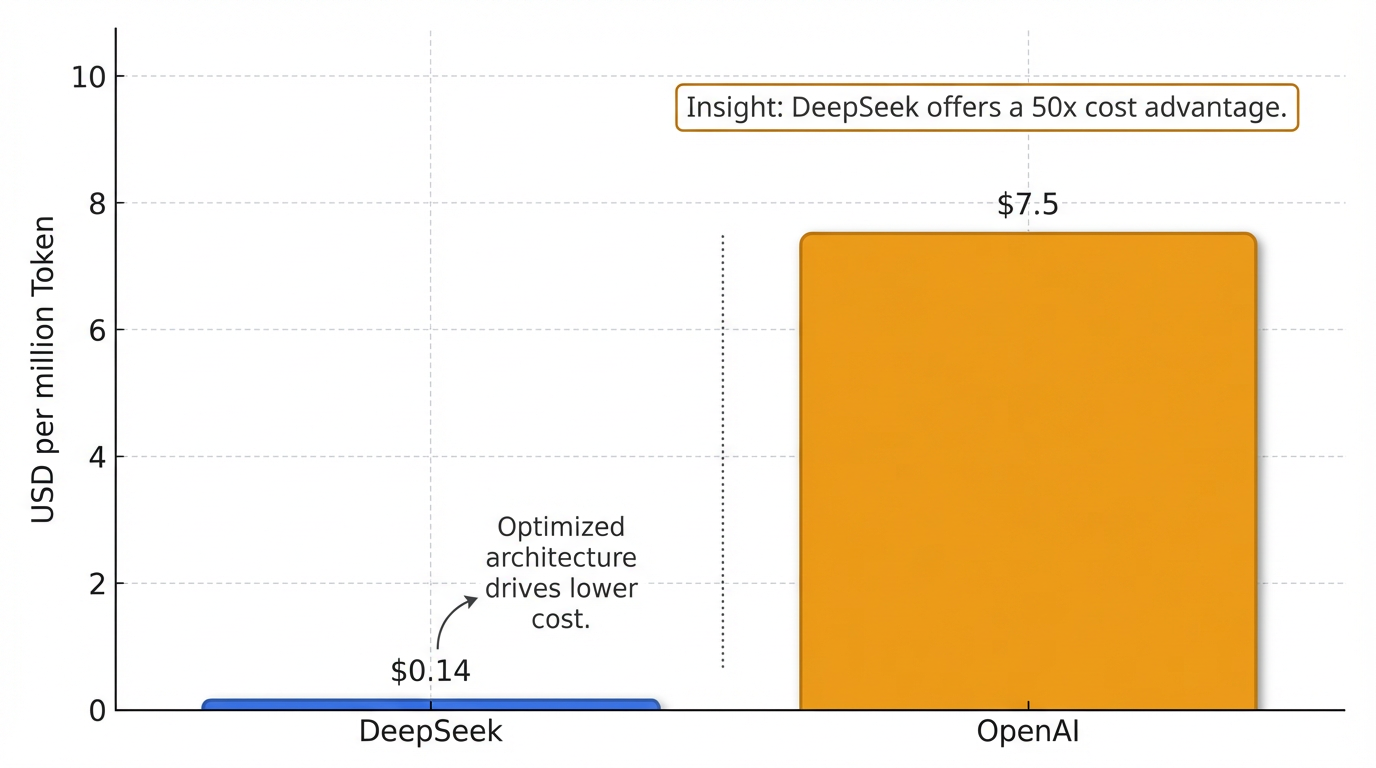
DeepSeek的成功实践证明了“降本优先”的中国式创新逻辑,与欧美国家推崇的“参数规模扩张”路线形成差异 22。它通过算法优化和架构设计,在保持性能的同时大幅降低资源消耗。DeepSeek-V3的训练成本仅为OpenAI同类模型的约十分之一 ,推理成本低至每百万Token 0.14美元,远低于OpenAI的7.5美元 21。
其核心技术包括:跨维度知识蒸馏技术,能够将大模型的深层推理能力迁移到小模型中,使70亿参数量的小模型在数学解题准确率提升23个百分点 22;GRPO算法的应用,使得算力消耗降低30%,提升了边缘设备的AI推理效率,例如智能制造企业质检设备的年耗电量从1.2万度降至3600度,推理延迟缩短至0.3秒 22。
AI行业格局的重塑与“技术民主化”
DeepSeek的开源核心代码和API定制权限打破了传统AI生态的“金字塔结构”,形成“大厂炼模型、中小厂做应用”的分布式生态,有望终结巨头垄断 22。其极致性价比甚至带来了“开源印钞机”效应,其推理系统理论日利润可高达346万元人民币,成本利润率可达545% 。
在硬件生态方面,DeepSeek对底层硬件的优化加速了国产模型使用国产芯片,直接利好包括华为昇腾在内的国产半导体产业链,CUDA的竞争壁垒有所松动 18。甚至AMD也已将DeepSeek-V3集成到其GPU产品 17。DeepSeek凭借其开放力度,吸引了国内外主流软硬件厂商适配,有望成为全球AI创新的技术底座,开启AI 2.0时代的“模型—芯片—系统”一体化生态,迎来AI领域的“安卓时刻” 17。
对应用开发的深远影响
DeepSeek降低了AI应用开发的门槛。开源API的推出使全链路模型定制能力赋予普通个人开发者,GitHub上DeepSeek开源项目发布仅一周就引发1.2万个衍生项目 。其低成本特性催生了金融、医疗、制造等领域的“轻量级AI应用”,带来显著的效率提升和成本优化 22。
| 行业名称 | 改进指标 | DeepSeek前数值 | DeepSeek后数值 | 提升/降低幅度 |
|---|---|---|---|---|
| 金融 | 年均算力成本 | 500万元 | 80万元 | 降低84% |
| 金融 | 高频交易效率 | 100% | 130% | 提升30% |
| 金融 | 交易误判率 | 100% | 75% | 降低25% |
| 医疗 | 硬件投入成本 | 100% | 10% | 降低90% |
| 工业质检 | 质检设备年耗电量 | 1.2万度 | 3600度 | 降低70% |
| 工业质检 | 人工干预需求 | 100% | 30% | 降低70% |
| 工业质检 | 运维成本 | 100% | 35% | 降低65% |
| 工业质检 | 质检效率 | 100% | 140% | 提升40% |
| 工业质检 | 富士康iPhone主板贴片环节节拍时间 | 100% | 88% | 缩短12% |
| 农业 | 智能灌溉节水率 | 0% | 40% | 节水40% |
| 农业 | 番茄产量 | 100% | 118% | 提高18% |
例如,某券商引入DeepSeek小模型实现毫秒级市场预测,高频交易效率提升30%,交易误判率降低25%,年均算力成本从500万元锐减至80万元 22。医疗领域7B参数病理分析模型识别准确率达98.5%,硬件投入成本降低90% 22。工业质检中,模型体积压缩至原来的1/10,缺陷检出率99.2%,人工干预需求降低70%,运维成本降幅65%,质检效率提升40% 22,富士康iPhone主板贴片环节节拍时间缩短12%,产能提升至120万台/日 。农业领域实现了病虫害精准预测与防治,智能灌溉节水40%,番茄产量提高18% 23。教育领域,个性化学习模型边际成本趋近于零,农村学校可享一线城市AI教学资源 22。
DeepSeek通过蒸馏技术和算法优化,显著降低模型存储需求与计算量,加速了端侧AI渗透,有望加速AI手机、AI耳机等智能终端的普及与渗透 21。国内多家手机厂商已接入DeepSeek模型,例如华为、荣耀、OPPO等 17。DeepSeek的爆火也迫使友商从“卖模型”转向“卖解决方案”,例如豆包推出“AI中台”,Kimi发布“长文本工作流”平台,文心强化“模型+行业知识库”组合 24。
4. 未来挑战与中国AI新路径
尽管DeepSeek为中国AI发展带来了巨大机遇,但其面临的挑战不容忽视。DeepSeek不依赖“暴力美学”的Scaling Law,通过纯强化学习训练方法,开辟了大模型能力提升的“第二路径”,为在有限算力条件下实现大模型“小而美”发展提供了案例支撑 17。这种“降本优先”的中国式创新逻辑有望成为全球AI发展的第三极,引领智能时代走向可持续未来 。
DeepSeek需要持续技术创新,以应对OpenAI(o3系列、GPT-4.5、GPT-5)、Anthropic(Claude 3.7 Sonnet、Opus 4、Sonnet 4)、Google(Gemini 2.5 Pro和Flash版本)、阿里巴巴(Qwen3)、马斯克(Grok-3)以及Meta(Llama 4)等竞争对手的快速迭代 。目前,DeepSeek已掌握“微调”技术,优化后的R1版本消除了40%-45%的幻觉,提升了推理能力,可能为R2的进一步架构升级争取时间 。
此外,DeepSeek的崛起引起全球高度警惕,地缘政治争议和信任危机为其出海发展设置了障碍 16。微软曾尝试在Azure云服务上提供DeepSeek模型接入,但随后采取了强硬的禁用措施;OpenAI曾指控DeepSeek使用“蒸馏技术”,并呼吁美国政府实施AI出口管制,禁止在政府设备上使用DeepSeek 16。意大利、澳大利亚、韩国等国家已在政府部门禁用DeepSeek,理由是潜在的隐私风险和国家安全考量 16。为应对这些质疑,DeepSeek通过公开模型代码、技术论文、强调隐私保护(MIT媒体实验室审计报告)、法律团队合规说明以及与开发者互动等方式积极回应 16。
最后,DeepSeek的开源特性带来了模型滥用风险(生成虚假信息)、生态利益冲突(大厂与中小企业技术红利分配不均)以及可持续性疑虑(未来遭遇性能瓶颈时,低成本优势能否持续)等伦理挑战 22。因此,需要建立新型人机信任机制与技术问责框架,解决模型决策逻辑的不可解释性,并通过构建“AI防火墙”系统,平衡技术普惠与风险防控 25。
总结
DeepSeek新模型以其突破性的百万Token上下文能力,重新定义了AI处理超长文本的潜力,使其能够一次性处理海量信息。通过MoE、MLA、FP8等核心技术创新,DeepSeek实现了“降本增效”的中国式AI发展路径,有效降低了训练和推理成本,颠覆了传统AI对算力的过度依赖5。
DeepSeek的开源策略和高性价比特性推动了AI技术民主化进程,显著降低了应用开发门槛,加速了AI技术在金融、医疗、工业等各行业的深度渗透与普及。该模型被誉为中国AI的“斯普特尼克时刻”,标志着中国AI正从技术追随者向自主创新者转变,在全球AI竞争格局中占据了重要地位16。
尽管面临激烈的国际竞争和地缘政治挑战,DeepSeek通过持续的技术迭代(如R1升级版)和对生态建设的关注,正引领AI行业从单纯的技术竞赛走向效率革命22,并展现出全球AI可持续发展的“中国路径”。