Gemini 3.1 Pro: 重磅发布、核心亮点与未来展望
引言:Gemini 3.1 Pro重磅发布
2026年2月19日(UTC时间),Google正式发布了其最新一代AI模型Gemini 3.1 Pro的预览版 。作为Google的最新旗舰模型,Gemini 3.1 Pro被定位为“最先进的推理型Gemini模型”,旨在解决那些“一个简单答案远远不够”的复杂问题。
此次发布不仅是Google在人工智能领域迈出的新里程碑,更深刻体现了其推动AI从传统的“对话”模式转向更具实用性的“执行”模式的战略目标。Google强调,Gemini 3.1 Pro将强大的推理能力真正落地到日常和专业应用场景中,市场竞争焦点也因此从单纯的模型规模转向实际任务的完成率和可用性。Gemini 3.1 Pro的问世,无疑预示着AI领域将迎来一场以实用性和深度推理为核心的新变革。
核心亮点:技术突破与主要新功能
Gemini 3.1 Pro的发布标志着Google在AI领域取得了显著的技术飞跃,其设计目标直指复杂任务处理和高级推理能力的提升 1。作为Gemini 3 Pro的升级版本 4,它在核心架构、推理能力、多模态理解以及代理工作流方面均实现了质的飞跃,使其成为“更聪明、更具能力的基础模型” 5, [1-6]。
一、核心技术架构与基础能力
Gemini 3.1 Pro的核心优势之一在于其采用了混合专家(MoE)架构的Transformer模型 5。这意味着在处理每个请求时,模型只会激活部分参数,从而在保持高性能的同时,显著降低了计算成本和响应延迟 6。
其次,模型继承了100万Token的超大上下文窗口,与Gemini 3 Pro保持一致 6。这一能力使其能够一次性处理约75万英文单词,或一本300页的书籍,甚至整个代码库、长视频历史记录或多达900张图片/PDF页面 6。这种前所未有的上下文处理能力有效减少了传统检索增强生成(RAG)系统中常见的上下文碎片化问题 9。
二、关键技术突破与新功能详解
Gemini 3.1 Pro的突破集中在“复杂问题求解”和“高级推理”上 2。
-
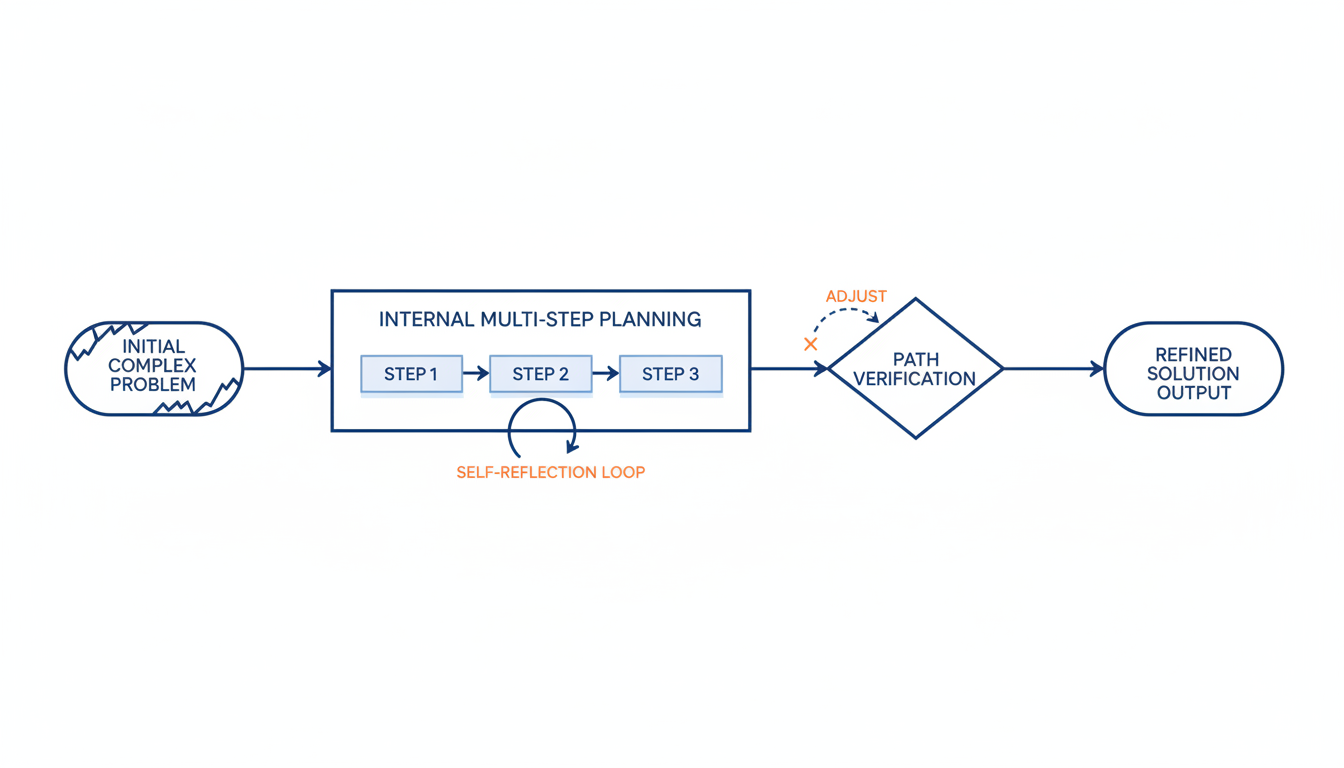
推理能力显著增强 Google将Gemini 3.1 Pro描述为在复杂问题求解、跨领域分析及抽象逻辑任务方面具有“更聪明、更具能力”的表现 5, [1-6]。尤其值得关注的是,模型融合了Deep Think模式 2。这一模式通过内部的思维链(Chain of Thought)过程,模拟人类专家的“慢思考”系统,进行多步骤规划、自我反思和路径验证,从而换取更高的智能水平 7。 为了赋能开发者更好地利用其高级推理能力,Gemini 3.1 Pro还引入了
thinking_level参数。该参数允许开发者控制模型在生成响应前执行的内部推理深度(分为低、中、高三档),以便在回答质量、推理复杂性、延迟和费用之间取得最佳平衡 8。在多项基准测试中,Gemini 3.1 Pro的推理能力表现卓越:
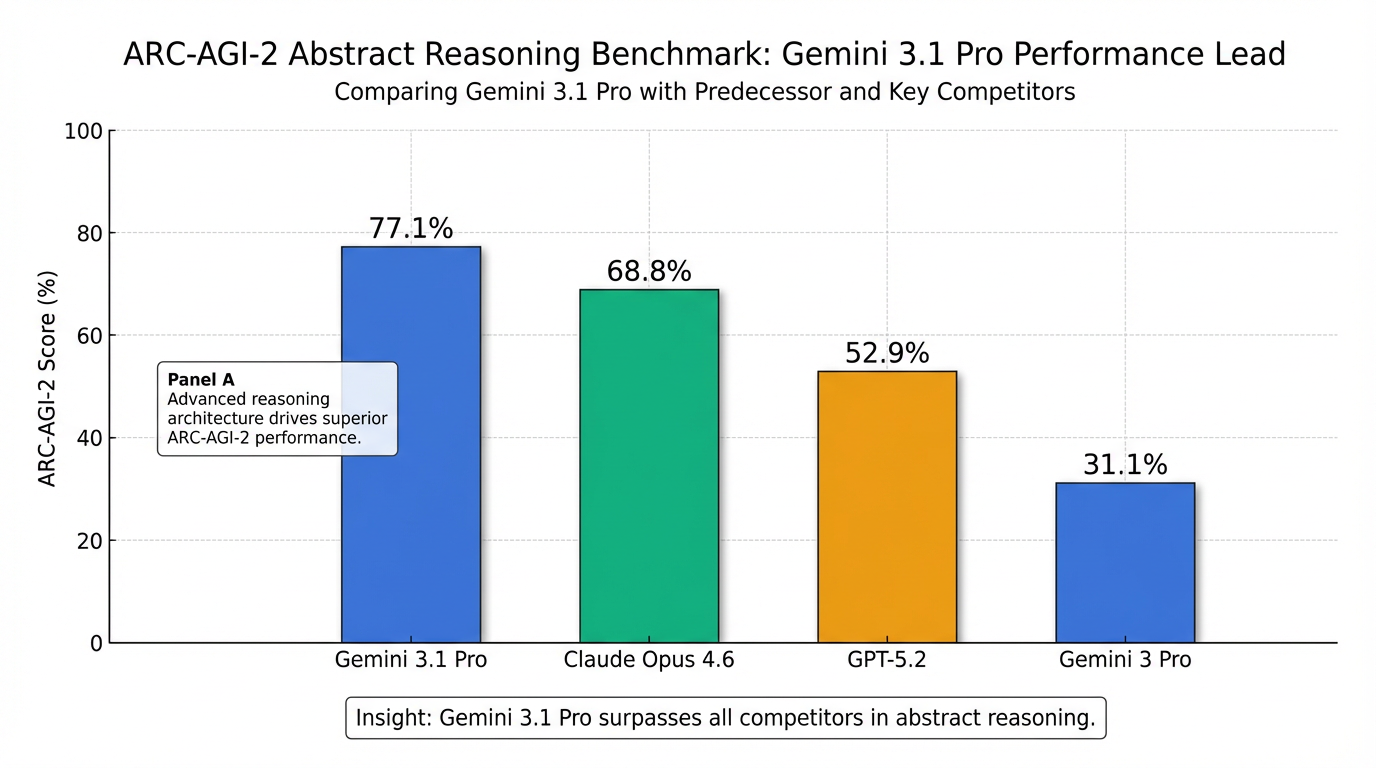
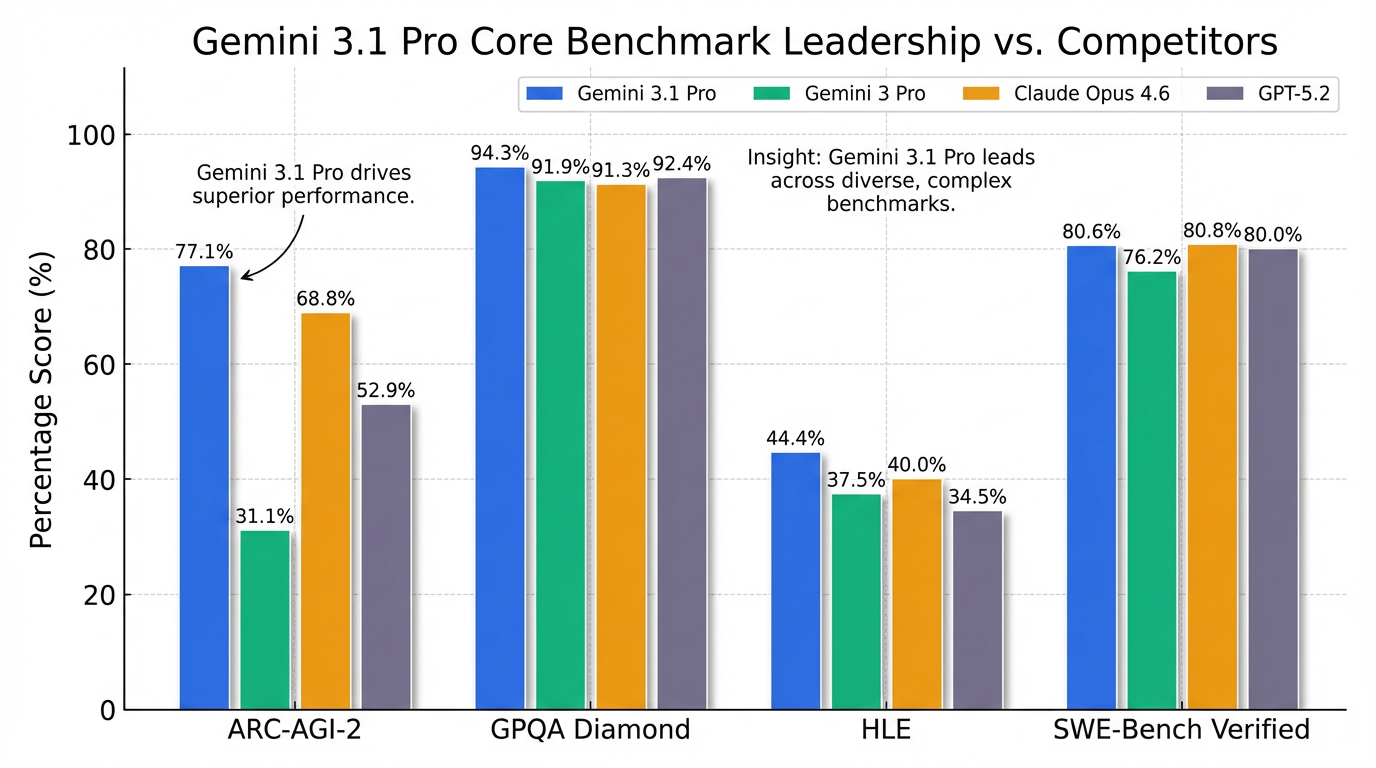
- ARC-AGI-2(抽象推理)得分高达77.1%,是Gemini 3 Pro (31.1%) 的两倍多,并显著超越Claude Opus 4.6 (68.8%) 和GPT-5.2 (52.9%) 4。
- GPQA Diamond(研究生级科学知识推理)得分94.3% 4,超越Claude Opus 4.6 (91.3%)和GPT-5.2 (92.4%) 3。在Deep Think模式下,该测试得分达到93.8% 7。
- Humanity's Last Exam (HLE)(极高难度AI测试),在无工具条件下得分44.4%,高于Claude Opus 4.6 (40.0%) 和GPT-5.2 (34.5%) 15。
-
原生多模态理解与处理能力升级 Gemini 3.1 Pro被设计为原生多模态模型,能够从训练初期就理解和生成文本、代码、图片、音频、视频和PDF等多种模态内容,并支持混合输入 6。其跨模态推理能力能够理解图片中的文字并结合上下文推理,分析视频内容并生成详细描述,识别音频中的语音并转换为文本,并将多种模态信息综合起来给出答案 6。例如,它能捕捉“视频中说话者的语调与其面部微表情是否矛盾”这类深层细微差别 7。 在多模态处理方面,模型引入了**
media_resolution参数**,允许更精细地控制视觉处理,以提高读取细小文字或识别细节的能力(同时需权衡Token用量和延迟) 8。此外,多模态函数响应现在可以包含图片和PDF等模态对象 8。模型支持长达1小时的视频理解(无音频)或45分钟(含音频) 8,并支持最大100MB文件直接上传分析 14以及YouTube视频链接分析 14。 在MMMU-Pro(多模态通用考试)中,Gemini 3.1 Pro取得了81% 16或80.5% 14的得分,显示出其在处理图表、工程图纸及视频内容方面的强大能力,领先于GPT-5.1 (76%)和Claude 4.5 (68%) 16。 -
创新代码生成与工程能力 Gemini 3.1 Pro在代码生成和工程应用方面表现突出。它能够高效进行前端开发,一次性生成超过2000行的前端代码,包括完整功能模块和响应式布局 6。模型还支持SVG动画代码生成,直接根据文本提示生成动态、可缩放且文件体积小的SVG动画代码 1。 此外,它能可视化复杂系统,理解复杂的API,并基于遥测数据实时构建可视化仪表盘 1。在交互式设计方面,可以编写复杂的3D椋鸟群舞模拟代码,并构建支持手部追踪和动态配乐的沉浸式体验 1。甚至在创意编程上,Gemini 3.1 Pro能够将文学主题(如《呼啸山庄》)转化为功能性代码,设计出捕捉作品精髓的网站界面 1。 其卓越的代码能力也体现在基准测试中:
-
代理行为与工具协同的深化 Gemini 3.1 Pro在实现智能代理(Agent)方面迈出了重要一步。模型引入了严格的**
thoughtSignature验证机制**,确保在API调用之间保持推理上下文,极大地提高了多轮函数调用的可靠性 8。此外,它支持流式函数调用,以改善工具使用过程中的用户体验 8。模型能够进行复杂的工具协同编排,例如执行浏览器交互、在沙箱环境中运行代码、调用第三方API,并组合多个工具来完成复杂的任务 6。 在评估代理能力方面: -
生成式用户界面 (Generative UI) Gemini 3.1 Pro具备生成式用户界面的能力,这在Gemini App和Google Search的AI模式中得到了体现。模型能够根据用户的意图,实时生成并渲染交互式组件,提供动态视图 7。通过个性化定制,模型可以根据用户需求生成完全不同的界面,实现“千人千面”的界面生成能力 7。
下方图表展示了Gemini 3.1 Pro在各项基准测试中与前代及竞品的性能对比:
卓越能力展现:为什么说它“非常强”?
Gemini 3.1 Pro被Google定位为“更聪明、更具能力的基础模型”5,其卓越性能体现在复杂问题求解、跨领域分析及抽象逻辑任务上5, [1-6]。本节将深入探讨其各项关键能力,并通过基准测试数据和具体应用案例,全面阐释其“非常强”的表现。
一、核心推理能力:深度思考与参数调控
Gemini 3.1 Pro的核心推理能力实现了显著提升。Google将上周在Gemini 3 Deep Think中首次推出的“升级核心智能”引入了3.1 Pro模型中2。这种Deep Think模式通过内部的思维链(Chain of Thought)过程,模拟人类专家的“慢思考”系统,能够进行多步骤规划、自我反思和路径验证,以换取更高的智能水平7。
为了进一步优化模型的推理效率和资源消耗,Gemini 3.1 Pro引入了thinking_level参数8。开发者可以利用该参数控制模型在生成响应前执行的内部推理深度(分为低、中、高三个级别),从而在回答质量、推理复杂性、延迟和费用之间取得平衡8。
在多项权威基准测试中,Gemini 3.1 Pro展现了领先的推理性能:
- ARC-AGI-2:这项抽象推理测试中,Gemini 3.1 Pro得分高达77.1%,是Gemini 3 Pro(31.1%)的两倍以上,并显著超越了Claude Opus 4.6(68.8%)和GPT-5.2(52.9%)4。
- GPQA Diamond:在研究生级科学知识推理测试中,模型得分达到94.3%4,甚至超越了Claude Opus 4.6(91.3%)和GPT-5.2(92.4%)3。值得注意的是,在Deep Think模式下,该测试的得分也达到了93.8%7。
- Humanity's Last Exam (HLE):这是一项极高难度的AI测试,在无工具条件下,Gemini 3.1 Pro得分44.4%,表现优于Claude Opus 4.6(40.0%)和GPT-5.2(34.5%)15。
二、代码生成与工程能力:从创意到实现
Gemini 3.1 Pro在代码生成和工程应用方面表现出惊人的实力,尤其擅长处理前端开发、动画生成、系统可视化及复杂交互设计等任务:
- 前端开发:能够一次性生成超过2000行的前端代码,包括完整的功能模块和响应式布局,极大地提升了开发效率6。
- SVG动画代码生成:可以直接根据文本提示生成可用于网站的动态SVG动画代码。这些动画完全由纯代码构建,可在任何缩放比例下保持清晰锐利,且文件体积小巧1。
- 复杂系统可视化:模型能够理解复杂的API,并基于实时遥测数据(例如国际空间站的轨道数据)构建交互式的可视化仪表盘1。
- 交互式设计与创意编程:例如,它可以编写复杂的3D椋鸟群舞模拟代码,并构建沉浸式体验,支持手部追踪和动态配乐1。此外,模型还能将文学主题(如《呼啸山庄》)转化为功能性代码,设计出捕捉作品精髓的网站界面1。
在衡量代码能力的基准测试中,Gemini 3.1 Pro也取得了优异成绩:
- SWE-Bench Verified:在解决真实软件工程问题方面,得分达到80.6%,与Claude Opus 4.6(80.8%)基本持平,并高于Gemini 3 Pro(76.2%)和GPT-5.2(80.0%),这表明其编程能力已跻身行业第一梯队4。
- Terminal-Bench 2.0:在终端命令行操作测试中,得分53.8%17,高于Gemini 3 Pro(32.6%)、GPT-5.1(47.6%)和Claude 4.5(42.8%),体现了其作为“系统管理员”的强大能力16。
- LiveCodeBench Pro:Elo分数从2439提升至288714。
三、多模态理解与处理:深度融合与精细控制
Gemini 3.1 Pro被设计为原生多模态模型,这意味着它从训练初期就能理解和生成多种模态的内容,支持文本、代码、图片、音频、视频和PDF等混合输入6。
- 跨模态推理:模型不仅能理解图片中的文字并结合上下文推理,还能分析视频内容并生成详细描述,识别音频中的语音并转换为文本,并将多种模态信息综合起来给出答案6。例如,它能够捕捉“视频中说话者的语调与其面部微表情是否矛盾”这类深层细微差别,展现了其强大的跨模态理解能力7。
- 媒体分辨率(
media_resolution)参数:为开发者提供了更精细地控制多模态视觉处理的能力。更高的分辨率可以增强模型读取细小文字或识别细节的能力,但相应会增加Token用量和延迟8。 - 多模态函数响应:除了文本,函数响应现在可以包含图片和PDF等模态对象,进一步拓展了模型的应用场景8。
- 视频理解能力:支持处理时长高达1小时(无音频)或45分钟(含音频)的视频,每帧默认分辨率的Token数为708。
- 文件上传与YouTube链接分析:模型支持最大100MB的文件直接上传进行分析14,并且能够直接输入YouTube视频链接进行内容分析,大大提升了便捷性14。
在多模态理解基准测试MMMU-Pro(多模态通用考试)中,Gemini 3.1 Pro取得了81%16或80.5%14的得分,显示出在处理图表、工程图纸及视频内容方面的强大能力14,领先于GPT-5.1(76%)和Claude 4.5(68%)16。
四、代理行为与工具协同:智能工作流编排
Gemini 3.1 Pro在构建智能Agent和编排复杂工作流方面具备显著优势:
thoughtSignature:模型引入了严格的“思维签名”验证机制,以确保在API调用之间保持推理上下文,从而显著提高了多轮函数调用的可靠性8。- 流式函数调用:支持流式传输部分函数调用参数,这有助于改善工具使用过程中的用户体验,尤其是在需要快速反馈的场景下8。
- 工具协同编排:Gemini 3.1 Pro能够执行复杂操作,例如浏览器交互、在沙箱环境中运行代码、调用第三方API,并能智能地组合多个工具来完成复杂的任务6。
在衡量代理行为的基准测试中:
- Vending-Bench 2:这项长期规划代理工作测试显示,Gemini 3.1 Pro获得了5478美元的净值,远超GPT-5.1的1473美元和早期模型的573美元,突显了其卓越的规划和执行能力16。
- τ2-bench:在工具使用测试中,模型平均得分85.4%,这表明其在API调用准确性和减少错误方面的显著进步16。
五、生成式用户界面 (Generative UI):个性化交互体验
Gemini 3.1 Pro在生成式用户界面方面展现出创新能力:
- 动态视图:在Gemini App和Google Search的AI模式中,Gemini 3.1 Pro(或其核心技术,Gemini 3)能够根据用户的意图,实时生成并渲染交互式组件7。
- 个性化定制:模型可以根据用户需求,生成完全不同的界面,实现真正意义上的“千人千面”的界面生成能力,为用户提供高度定制化的交互体验7。
六、综合性能基准对比概览
为了更直观地展示Gemini 3.1 Pro的卓越能力,以下图表总结了其在多个关键基准测试中与前代模型及主要竞品的对比表现:
市场影响与应用前景展望
Gemini 3.1 Pro的发布,作为Google在AI领域的最新一代模型预览版,无疑将对全球AI生态系统产生深远影响,为开发者、企业级用户和普通用户开辟新的机遇 1。其强大的高级推理、代码生成和多模态理解能力,将赋能现有Google产品,并推动AI解决方案在法律、金融、教育、内容创作、系统架构设计和全栈应用开发等多个领域的广泛应用,特别是针对“那些一个简单答案远远不够”的复杂任务求解场景 6。
在当前激烈的AI模型竞争中,Gemini 3.1 Pro凭借在多项关键基准测试中的优异表现,进一步巩固了Google在顶尖AI模型领域的领先地位。例如,在抽象推理任务ARC-AGI-2中,其得分达到77.1%,是Gemini 3 Pro的两倍以上,并显著超越Claude Opus 4.6和GPT-5.2等主要竞争对手 4。同时,在软件工程问题解决(SWE-Bench Verified)、终端命令行操作(Terminal-Bench 2.0)和多模态通用考试(MMMU-Pro)等领域,Gemini 3.1 Pro也展现出领先或极具竞争力的水平 4。这无疑将对整个AI竞争格局产生深远影响。
模型对“复杂问题求解”和“智能体型工作流”的聚焦,尤其体现在其集成的Deep Think模式(模拟人类“慢思考”进行多步骤规划和自我反思)和强大的工具协同编排能力上,预示着未来AI发展将更加侧重于多步骤规划、自我反思和复杂的工具协同 7。这使得AI能够执行浏览器交互、代码运行(在沙箱环境内)及第三方API调用等复杂操作,从而实现更高级的自动化和智能化。其代理行为在Vending-Bench 2等长期规划代理工作测试中取得的净值远超竞品,也印证了这一趋势 16。
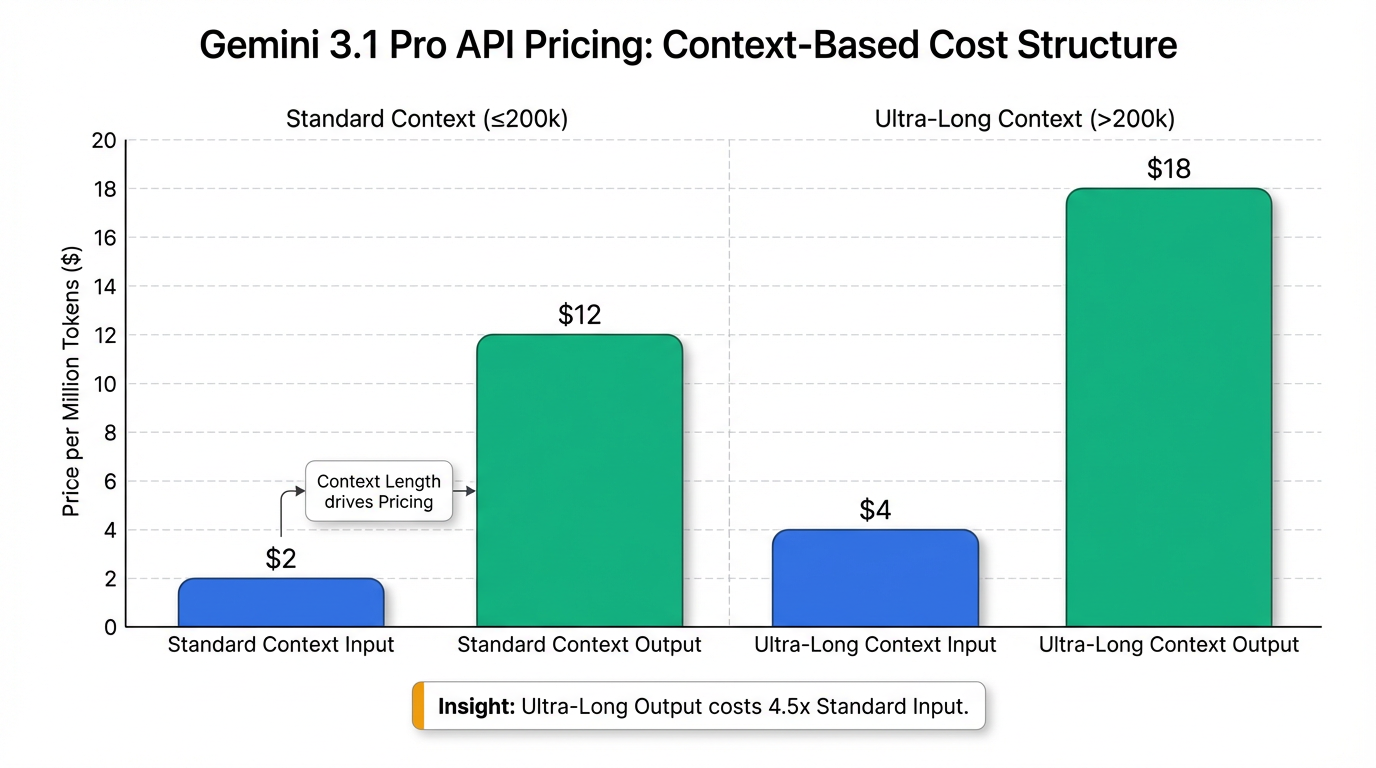
在市场策略方面,Gemini 3.1 Pro采用了“加量不加价”的定价策略,并在API层面提供了标准上下文(≤200k tokens)和超长上下文(>200k tokens)的差异化收费,以及通过Google AI Pro订阅方案提供更高的使用额度 14。这种多层级可用性(预览版通过AI Studio、Vertex AI等向开发者和企业开放,通过Gemini App向普通用户提供)旨在降低使用门槛,扩大用户群体和市场渗透率,加速其在预览阶段向全面正式版开放的进程 1。
然而,尽管Gemini 3.1 Pro表现出色,其商业化落地仍面临一些挑战和限制。模型仍然存在幻觉问题,GPQA测试结果显示其有8%的错误率 9。在处理100万Token的超长上下文时,还可能面临较高的成本波动、高达20-30秒的首次Token生成延迟,以及信息可能变得模糊等问题 16。此外,考虑到其生成bash脚本的能力,安全性(需要在容器内运行并要求人类批准sudo命令)和非开源属性(目前不支持微调,仅支持2k Token的系统指令调优)也需要持续关注 16。解决这些挑战将是实现更广泛商业化应用的关键,以便更好地发挥其巨大的技术和商业价值。
总结与展望
Gemini 3.1 Pro 作为 Google 于 2026 年 2 月 19 日发布的最新一代 AI 模型预览版 1,无疑在人工智能前沿领域树立了新的里程碑。它被定位为 Gemini 3 Pro 的升级版本 4,其核心价值在于能够高效处理复杂任务并提供卓越的高级推理能力 1。该模型通过集成“Deep Think”模式及全面提升的代码与多模态能力,进一步巩固了其在 AI 领域的领先地位,尤其擅长应对那些“一个简单答案远远不够”的复杂挑战 2。
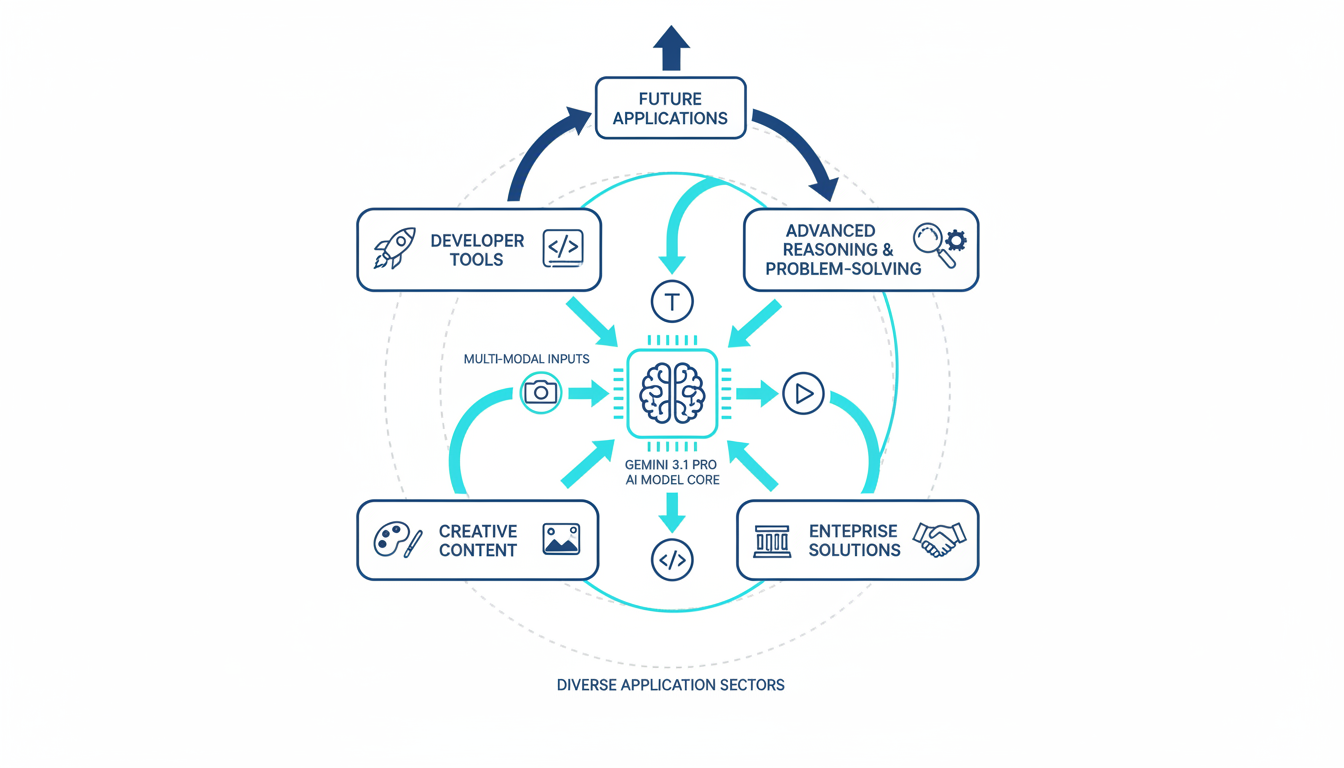
Gemini 3.1 Pro 的关键能力体现在多个创新方面:
- 100 万 Token 超大上下文窗口:这一特性使其能够一次性处理约 75 万英文单词、整个代码库,甚至多达 900 张图片/PDF 页面 6,显著提升了信息处理的广度和深度。
- 原生多模态支持:模型能够从训练初期就理解和生成文本、代码、图片、音频、视频和 PDF 等多种模态内容,并实现深度的跨模态推理,捕捉细微的语义和情感差别 6。
- 显著增强的推理能力:引入的 Deep Think 模式通过模拟人类“慢思考”进行多步骤规划、自我反思和路径验证,配合
thinking_level参数允许开发者控制推理深度,极大地提升了复杂问题求解能力 8。在 ARC-AGI-2 基准测试中,其推理性能是 Gemini 3 Pro 的两倍以上 4。 - 强大的代码生成与工程能力:模型能够一次性生成超过 2000 行前端代码,包括动态 SVG 动画,理解复杂 API 并实时构建可视化仪表盘 6。在 SWE-Bench Verified 和 Terminal-Bench 2.0 等编程基准测试中,表现达到行业领先水平 4。
- 升级的多模态处理:通过
media_resolution参数实现更精细的视觉处理,支持长达 1 小时的视频分析,并在 MMMU-Pro 多模态通用考试中取得 80.5% 至 81% 的领先分数 14。 - 代理行为与工具协同:借助
thoughtSignature机制和流式函数调用,模型能够有效地编排和调用多个外部工具和 API,完成复杂的代理工作流,并在 Vending-Bench 2 和 τ2-bench 等测试中展现出卓越的规划和执行能力 8。 - 生成式用户界面 (Generative UI):在 Gemini App 和 Google Search 的 AI 模式中,模型能够根据用户意图实时生成并渲染交互式组件,实现高度个性化的用户界面 7。
Gemini 3.1 Pro 的发布,不仅代表了人工智能技术的又一次质的飞跃,更预示着未来 AI 赋能的广阔前景。它将深刻推动智能 Agent 的发展,加速复杂数据分析的效率,激发创意编程的潜力,支持个性化教育的进步,并在代码库分析、法律合规、财务分析、系统架构设计等众多领域带来革命性的创新 2。通过向开发者、企业用户和普通用户开放其强大的能力,Gemini 3.1 Pro 有望成为构建下一代智能应用和解决方案的基石,驱动整个人工智能生态系统向前发展,最终实现更加智能、高效和个性化的数字体验 2。