GPT 5.3 Codex Spark: Confirmación y Análisis de sus Capacidades Mejoradas
Introducción: El supuesto lanzamiento de GPT 5.3 Codex Spark
En respuesta a la consulta sobre el lanzamiento oficial de "GPT 5.3 Codex Spark", se confirma que el modelo de inteligencia artificial "GPT-5.3-Codex-Spark" ha sido lanzado oficialmente por OpenAI como una vista previa de investigación (research preview) 1. Este anuncio tuvo lugar el 12 de febrero de 2026 . Este lanzamiento marca un hito significativo, ya que representa el primer resultado de la colaboración entre OpenAI y Cerebras Systems .
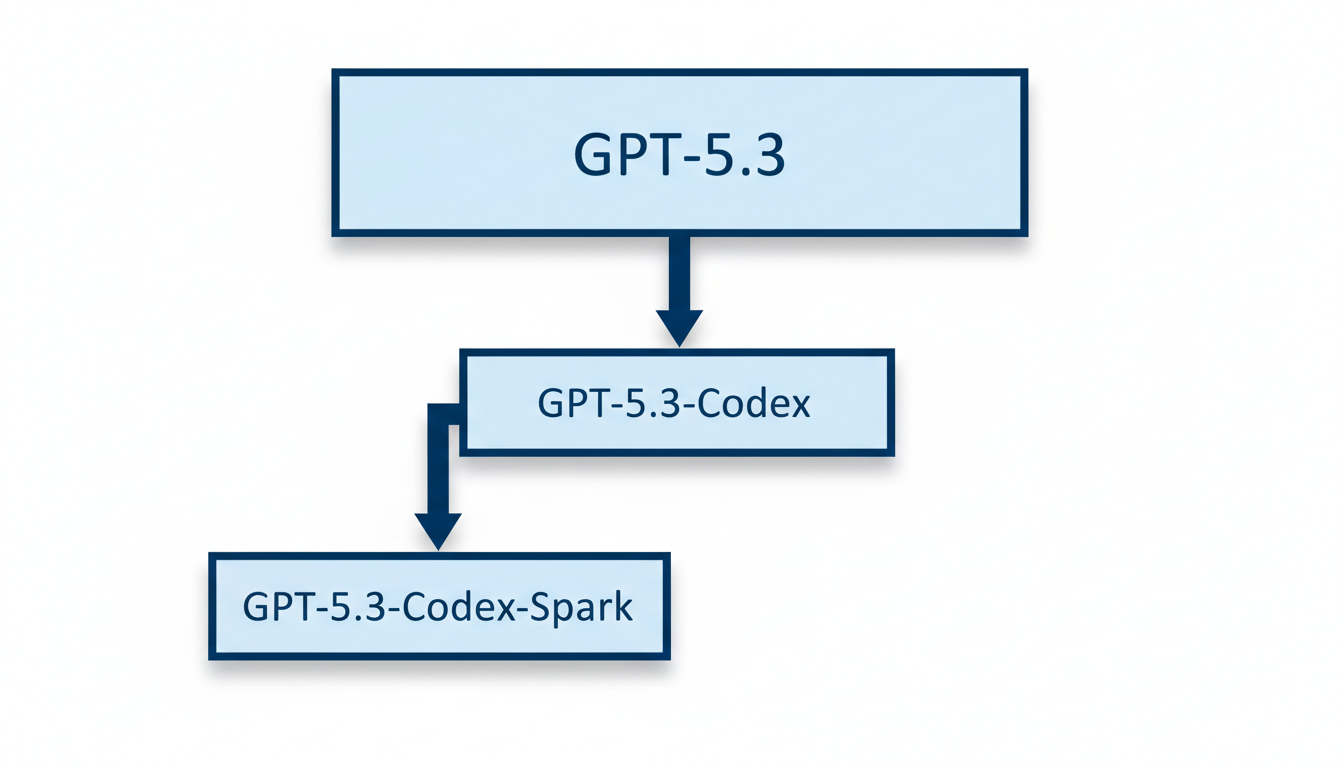
Es fundamental diferenciar "GPT-5.3-Codex-Spark" de otros modelos similares dentro del ecosistema de OpenAI. A diferencia del modelo más general "GPT-5.3-Codex", que es la versión agéntica de codificación más avanzada de OpenAI y fue lanzado el 5 de febrero de 2026 , la versión "Spark" es una iteración más pequeña y optimizada . Su diseño está específicamente adaptado para tareas que requieren una codificación ultra-rápida y en tiempo real . Además, se ha detectado una referencia a un modelo general "GPT-5.3" en la base de código de OpenAI, aunque sus detalles aún no se han hecho públicos 2.
La introducción de "GPT-5.3-Codex-Spark" subraya la estrategia de OpenAI de desarrollar modelos especializados que aborden necesidades específicas del desarrollo de software, priorizando la velocidad y la baja latencia . Comprender estas distinciones y el contexto de cada lanzamiento es crucial para apreciar la evolución de las capacidades de inteligencia artificial de OpenAI.
¿Qué es GPT 5.3 Codex Spark? Una visión general
"GPT-5.3-Codex-Spark" es un modelo de inteligencia artificial lanzado oficialmente por OpenAI como una vista previa de investigación (research preview) el 12 de febrero de 2026 . Este modelo representa el primer hito en la colaboración entre OpenAI y Cerebras Systems .
El propósito principal de GPT-5.3-Codex-Spark es ofrecer un modelo agéntico de codificación altamente optimizado para la codificación en tiempo real y la interacción conversacional, priorizando de manera significativa la baja latencia . Se posiciona como una versión más pequeña y especializada dentro de la familia GPT-5.3-Codex, diseñada para tareas específicas donde la velocidad y la eficiencia son cruciales .
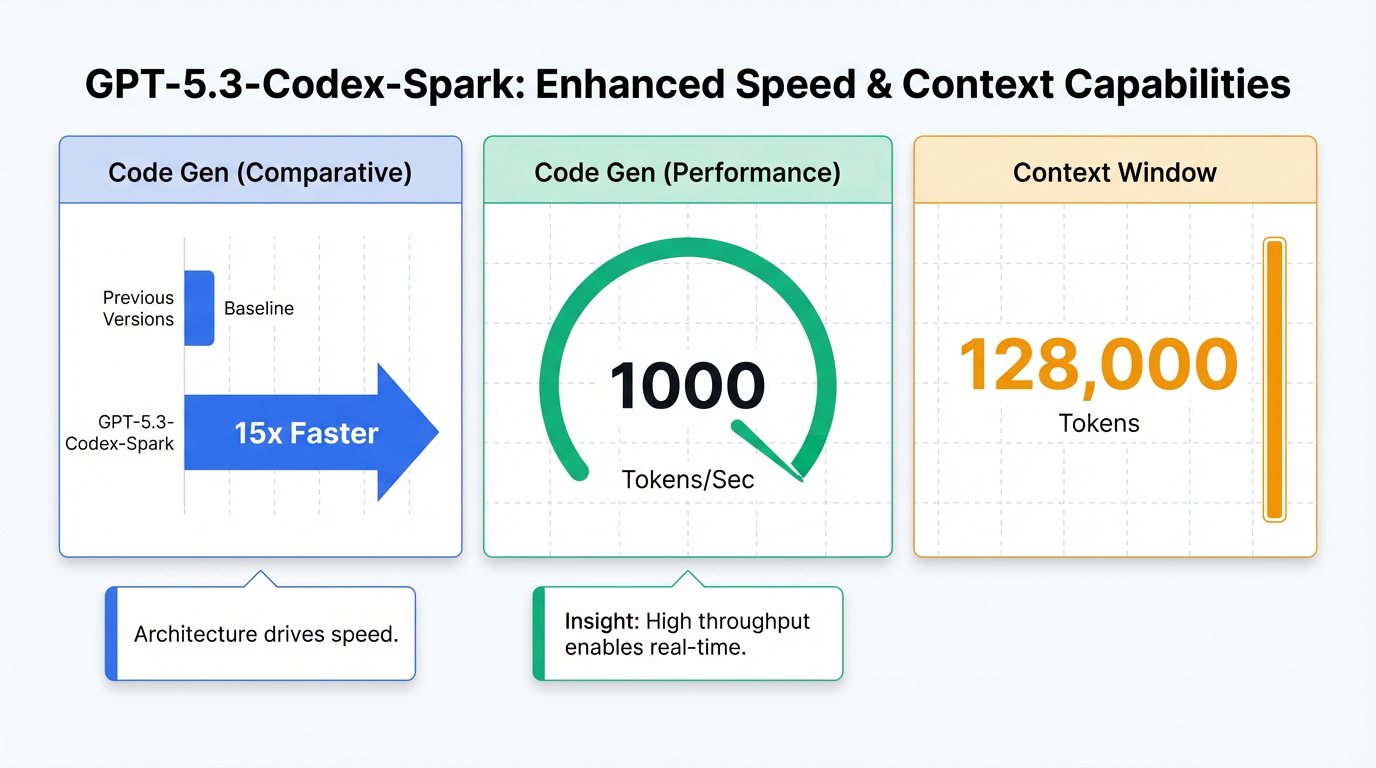
Entre sus características fundamentales distintivas, "GPT-5.3-Codex-Spark" destaca por su impresionante velocidad y baja latencia. Es capaz de generar código hasta 15 veces más rápido que versiones anteriores y puede entregar más de 1000 tokens por segundo , lo que se traduce en un tiempo de respuesta casi instantáneo . Además, opera con una amplia ventana de contexto de 128.000 tokens . Una de sus capacidades clave es la colaboración en tiempo real, permitiendo a los desarrolladores interactuar y guiar al modelo mientras trabaja sin perder el contexto, lo que facilita una edición precisa y la revisión de planes .
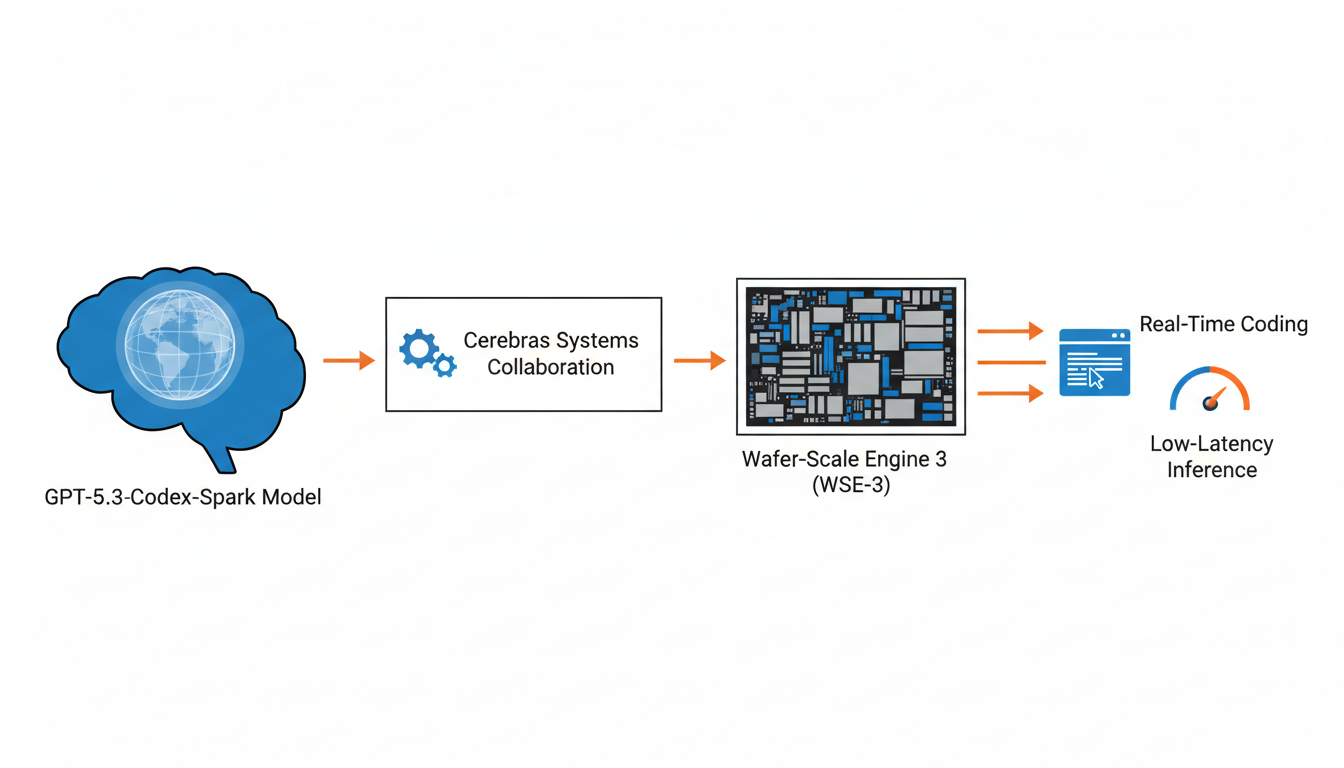
El rendimiento excepcional de este modelo se logra gracias a su ejecución en el Wafer-Scale Engine 3 (WSE-3) de Cerebras . Este hardware especializado es un acelerador de IA diseñado específicamente para la inferencia de alta velocidad y baja latencia, crucial para las capacidades de Spark .
GPT-5.3-Codex-Spark se diferencia de otros modelos de la familia. Mientras que "GPT-5.3-Codex", lanzado el 5 de febrero de 2026, es el modelo agéntico de codificación más avanzado y general de OpenAI, combinando habilidades de codificación con razonamiento avanzado y conocimiento profesional , Spark es una variante más pequeña y focalizada en la optimización de velocidad y latencia . GPT-5.3-Codex es un 25% más rápido que su predecesor, GPT-5.2-Codex, y es capaz de realizar tareas de larga duración que involucran investigación, uso de herramientas y ejecución compleja . Finalmente, existe una referencia a "GPT-5.3" (sin los sufijos Codex ni Spark) en la base de código de OpenAI, lo que sugiere un modelo general distinto, aunque sus detalles aún no se han hecho públicos 2.
Capacidades y Mejoras Destacadas
El modelo "GPT-5.3-Codex-Spark" de OpenAI se distingue por una serie de capacidades significativamente mejoradas que lo hacen particularmente impresionante, especialmente en el ámbito de la codificación y la interacción en tiempo real. Fue lanzado como una vista previa de investigación el 12 de febrero de 2026, marcando un hito en la colaboración entre OpenAI y Cerebras Systems .
Una de las características más destacadas es su optimización para velocidad y baja latencia en la codificación en tiempo real y la interacción conversacional, priorizando la respuesta instantánea . Esto se traduce en un rendimiento superior, generando código hasta 15 veces más rápido que versiones anteriores y entregando más de 1000 tokens por segundo . Este nivel de eficiencia permite un tiempo de respuesta casi instantáneo, facilitando una experiencia de usuario fluida y dinámica .
Este rendimiento se logra gracias a su integración con hardware especializado: el modelo se ejecuta en el Wafer-Scale Engine 3 (WSE-3) de Cerebras Systems . El WSE-3 es un acelerador de IA diseñado específicamente para inferencia de alta velocidad y baja latencia, lo que es fundamental para las capacidades de Spark .
"GPT-5.3-Codex-Spark" también opera con una amplia ventana de contexto de 128.000 tokens . Esta capacidad asegura que el modelo pueda mantener el hilo de la conversación y el código a lo largo de interacciones complejas y prolongadas, sin perder la información relevante.
Además, el modelo ofrece capacidades de colaboración en tiempo real, permitiendo a los desarrolladores interactuar y guiar al modelo mientras trabaja sin perder el contexto . Esta funcionalidad es crucial para la edición precisa y la revisión de planes, mejorando la eficiencia del flujo de trabajo de desarrollo .
Como vista previa de investigación, "GPT-5.3-Codex-Spark" está disponible para usuarios de ChatGPT Pro a través de la aplicación de Codex, la interfaz de línea de comandos (CLI) y la extensión de VS Code . El acceso a la API se está implementando progresivamente para socios de diseño seleccionados .
A continuación, se presenta una tabla comparativa que resume las características principales de "GPT-5.3-Codex-Spark" frente a su contraparte más general, "GPT-5.3-Codex":
| Modelo | Fecha de Lanzamiento | Tipo/Enfoque Principal | Capacidades Clave | Ventana de Contexto | Disponibilidad |
|---|---|---|---|---|---|
| GPT-5.3-Codex-Spark | 12 de febrero de 2026 (vista previa) | Optimizado para codificación en tiempo real y baja latencia; versión más pequeña y especializada. | Hasta 15x más rápido que versiones anteriores; >1000 tokens/segundo; ejecuta en WSE-3 de Cerebras; colaboración en tiempo real. | 128.000 tokens | ChatGPT Pro (aplicación Codex, CLI, extensión VS Code); API para socios seleccionados. |
| GPT-5.3-Codex | 5 de febrero de 2026 | Modelo agéntico de codificación más avanzado; combina habilidades de codificación con razonamiento y conocimiento profesional. | 25% más rápido que GPT-5.2-Codex; realiza tareas de larga duración (investigación, uso de herramientas); depuración automática; refactorización de código; detección de vulnerabilidades de ciberseguridad. | No especificado | Suscriptores de pago de ChatGPT; aplicación Codex para Mac. |
Impacto Potencial y Direcciones Futuras
El lanzamiento de "GPT-5.3-Codex-Spark" como vista previa de investigación por OpenAI representa un hito significativo que promete transformar el panorama del desarrollo de software y la inteligencia artificial en general. Este modelo, optimizado para velocidad y baja latencia, sienta las bases para una nueva era de interacción con asistentes de codificación .
La capacidad de "GPT-5.3-Codex-Spark" para generar código hasta 15 veces más rápido que las versiones anteriores y entregar más de 1000 tokens por segundo, con un tiempo de respuesta casi instantáneo, transformará radicalmente el desarrollo de software . Esto facilitará la codificación en tiempo real y la interacción conversacional fluida, permitiendo a los desarrolladores guiar al modelo y editar con precisión sin perder el contexto, lo que agilizará los ciclos de desarrollo y mejorará la productividad .
La estrecha colaboración entre OpenAI y Cerebras Systems, donde el rendimiento de "GPT-5.3-Codex-Spark" se logra al ejecutarse en el Wafer-Scale Engine 3 (WSE-3) de Cerebras, subraya una tendencia creciente hacia la co-diseño de hardware y software en la inteligencia artificial . Esta estrategia permite optimizar los modelos de IA para tareas específicas, prometiendo avances significativos en eficiencia y rendimiento más allá de lo que los enfoques generales pueden ofrecer. A largo plazo, esta sinergia entre hardware y software específico para IA podría convertirse en un estándar para el despliegue de modelos complejos.
Las perspectivas para los modelos de generación de código y asistentes de programación avanzados son inmensas. Mientras que "GPT-5.3-Codex-Spark" se enfoca en la velocidad de codificación, el modelo más amplio "GPT-5.3-Codex" es un modelo "agéntico" que combina habilidades de codificación con razonamiento avanzado y conocimiento profesional . Esto sugiere un futuro en el que los asistentes de IA no solo generarán código de manera eficiente, sino que también podrán realizar tareas de larga duración que implican investigación, uso de herramientas y ejecución compleja, como la depuración automática inteligente y la refactorización de código heredado .
Además, el potencial para la automatización mejorada y la eficiencia en la detección de vulnerabilidades se ve reforzado. El modelo "GPT-5.3-Codex" ya puede detectar vulnerabilidades de ciberseguridad, una capacidad que, combinada con la velocidad y la baja latencia de "GPT-5.3-Codex-Spark", podría llevar a sistemas de seguridad más proactivos y robustos en el proceso de desarrollo . Esta integración promete acelerar la identificación y mitigación de riesgos de seguridad, haciendo que el software sea más seguro desde sus etapas iniciales.
Conclusión: Verificando las expectativas y próximos pasos
Las expectativas iniciales del usuario sobre el lanzamiento de GPT-5.3-Codex-Spark han sido confirmadas. Efectivamente, OpenAI ha lanzado oficialmente este modelo como una vista previa de investigación el 12 de febrero de 2026 . Este evento marca un hito crucial en la colaboración estratégica entre OpenAI y Cerebras Systems, destacando un enfoque claro en la optimización del rendimiento para la codificación .
GPT-5.3-Codex-Spark se distingue por sus capacidades significativamente mejoradas, enfocadas en la velocidad ultrarrápida y la baja latencia. Está optimizado para la codificación en tiempo real y la interacción conversacional, priorizando la capacidad de respuesta casi instantánea . El modelo puede generar código hasta 15 veces más rápido que versiones anteriores y es capaz de entregar más de 1000 tokens por segundo . Además, opera con una impresionante ventana de contexto de 128.000 tokens, lo que facilita el manejo de proyectos de código complejos y extensos .
Este rendimiento excepcional es posible gracias a su ejecución en el Wafer-Scale Engine 3 (WSE-3) de Cerebras, un acelerador de IA diseñado específicamente para inferencia de alta velocidad y baja latencia . Esta integración tecnológica representa un diferenciador clave que potencia las avanzadas capacidades del modelo.
Es importante posicionar a GPT-5.3-Codex-Spark como una versión especializada y optimizada dentro de la familia más amplia de modelos GPT-5.3 de OpenAI 1. Mientras que "GPT-5.3-Codex", lanzado el 5 de febrero de 2026, es el modelo agéntico de codificación más avanzado de OpenAI, con capacidades de razonamiento y conocimiento profesional para tareas de larga duración , Spark está diseñado para ser una herramienta ágil y rápida para tareas específicas de codificación en tiempo real .
Las implicaciones de GPT-5.3-Codex-Spark para el futuro del desarrollo de IA en la generación de código son profundas. Su enfoque en la colaboración en tiempo real, permitiendo a los desarrolladores interactuar y guiar al modelo sin perder el contexto , sienta las bases para entornos de programación inmersivos y altamente eficientes. La prioridad en velocidad y baja latencia transformará la experiencia del desarrollador, haciendo que la asistencia de IA sea más fluida e integrada, lo que conducirá a ciclos de desarrollo más rápidos y a una mayor innovación en el software.