GPT 5.3 Codex Spark: Unveiling a New Era in Interactive AI Coding
Official Status and Release Verification of GPT 5.3 Codex Spark
The "GPT 5.3 Codex Spark" model has been officially announced and released as a research preview by OpenAI 1. This significant announcement occurred on February 12, 2026 2, with several news outlets reporting on it around February 13, 2026 3.
Currently, GPT-5.3-Codex-Spark is being rolled out to ChatGPT Pro users via the Codex app, command-line interface (CLI), and VS Code extension 4. Additionally, API access is available for a select group of design partners, with broader access planned as integration is refined 2. This release also marks the first milestone in OpenAI's collaboration with Cerebras, a partnership initially announced in January 2026 2.
It is important to clarify that this specific model release is exclusively from OpenAI. There has been no official announcement or reputable tech news reporting the release of a model specifically named "GPT 5.3 Codex Spark" from other major AI research organizations such as Google, Microsoft, or Anthropic 3.
The table below provides a concise overview of the official release details for GPT 5.3 Codex Spark.
| Model Name | Developer | Release Date | Current Status | Availability | Key Hardware Partnership |
|---|---|---|---|---|---|
| GPT 5.3 Codex Spark | OpenAI | February 12, 2026 | Research preview | ChatGPT Pro (Codex app, CLI, VS Code extension); API (select group) | Cerebras |
Table 1: Overview of GPT 5.3 Codex Spark Release Details.
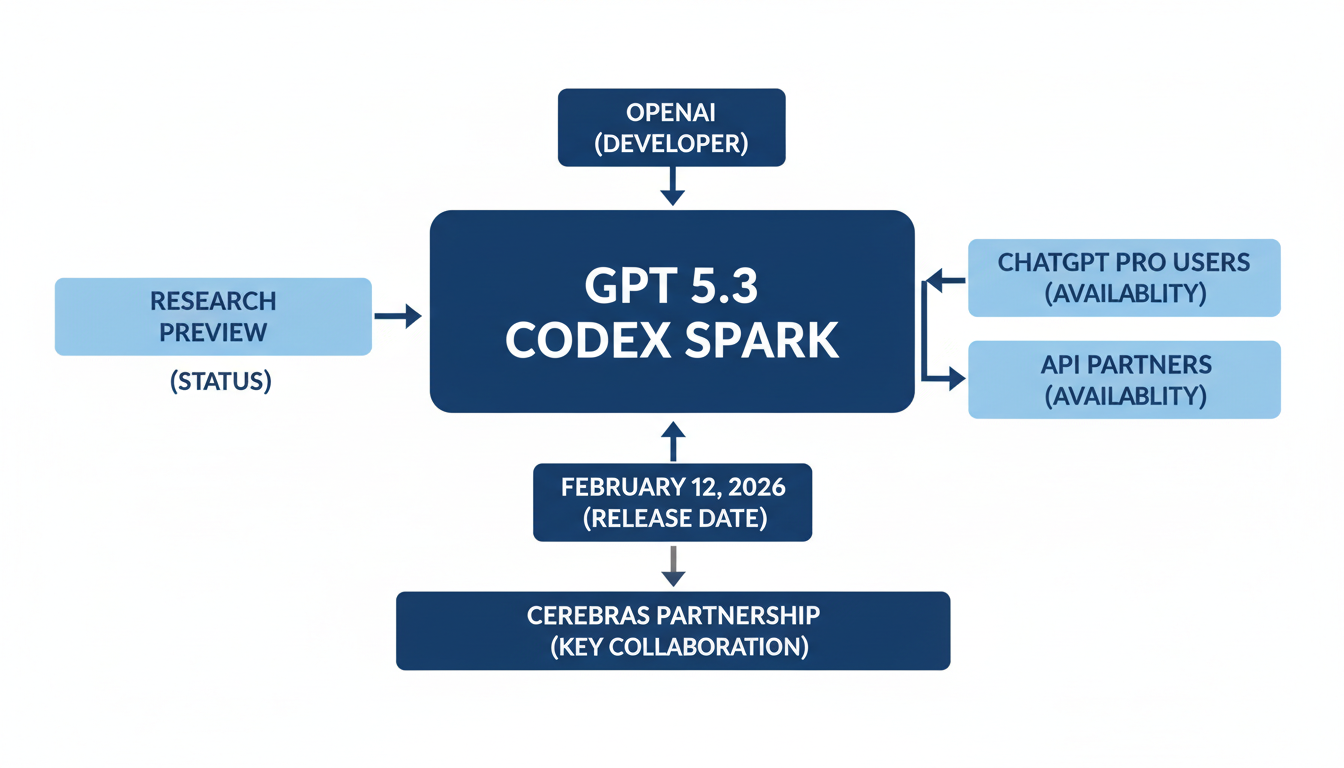
Figure 1: Conceptual diagram of GPT 5.3 Codex Spark's real-time coding capabilities.
Introduction: The Buzz Around GPT 5.3 Codex Spark
The artificial intelligence landscape is in perpetual motion, with each new iteration of large language models consistently pushing the boundaries of what's possible. Recently, a palpable wave of excitement and speculation has swept through the tech community and beyond, fueled by persistent whispers of a groundbreaking new development: GPT 5.3 Codex Spark. The anticipation surrounding this rumored model is intense, with many industry observers and developers eager to understand its potential capabilities and transformative impact. The "word on the street" suggests that GPT 5.3 Codex Spark represents a significant leap forward, promising unprecedented advancements in AI performance, particularly in areas such as enhanced code generation, sophisticated reasoning, and advanced multimodal understanding. This report aims to cut through the widespread speculation and provide a comprehensive, fact-based analysis, beginning with the critical first step: a thorough verification of its official status and details regarding its purported release.
Core Innovations and Significantly Enhanced Capabilities
GPT 5.3 Codex Spark introduces a suite of core innovations and significantly enhanced capabilities that fundamentally reshape interactive coding and AI-powered development. Designed as a smaller, optimized version of GPT-5.3-Codex, its advancements are primarily centered around speed and low-latency inference, fostering a new era of real-time software development [0-0, 0-4, 0-5].
Ultra-Fast, Real-Time Coding
A cornerstone of Codex Spark's appeal is its ultra-fast, real-time coding ability, delivering over 1,000 tokens per second [0-0, 0-1, 0-2]. This exceptional speed facilitates near-instant feedback in live coding environments, enabling "conversational" coding where developers can perform targeted edits, adjust logic, and refine interfaces with immediate results [0-1, 0-3]. The significantly reduced latency is crucial for allowing developers to maintain a "flow state," thereby enhancing productivity and tightening the interaction loop, making the model's collaboration feel more natural [0-5, 1-7]. Optimized for quick, interactive adjustments, Codex Spark defaults to making minimal, targeted edits and only runs tests when explicitly requested [0-1, 0-3].
Enhanced Reasoning for Interactive Tasks
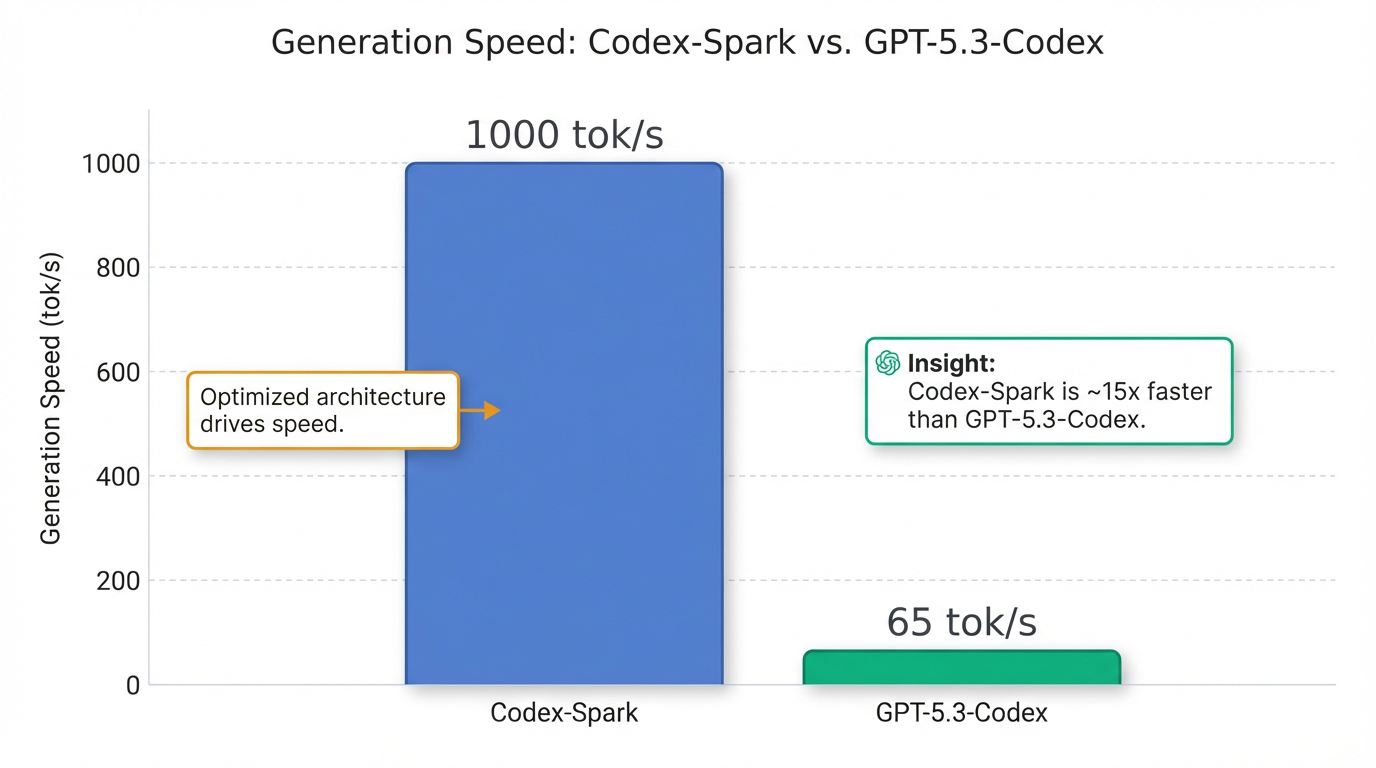
Despite its optimized size, GPT 5.3 Codex Spark exhibits robust performance on agentic software engineering benchmarks, including SWE-Bench Pro and Terminal-Bench 2.0 [0-2, 0-5]. It surpasses GPT-5.1-Codex-mini in capability and completes tasks significantly faster than the full GPT-5.3-Codex [0-2, 0-5]. A notable demonstration of its speed is generating a playable Snake game in approximately 9 seconds, a task that took GPT-5.3-Codex over 40 seconds [0-7]. The model particularly excels at precise code edits, revising development plans, answering contextual questions about a codebase, and rapid prototyping tasks such as visualizing layouts or refining styling [0-2].
Qualitative Shifts in Performance and Functionality
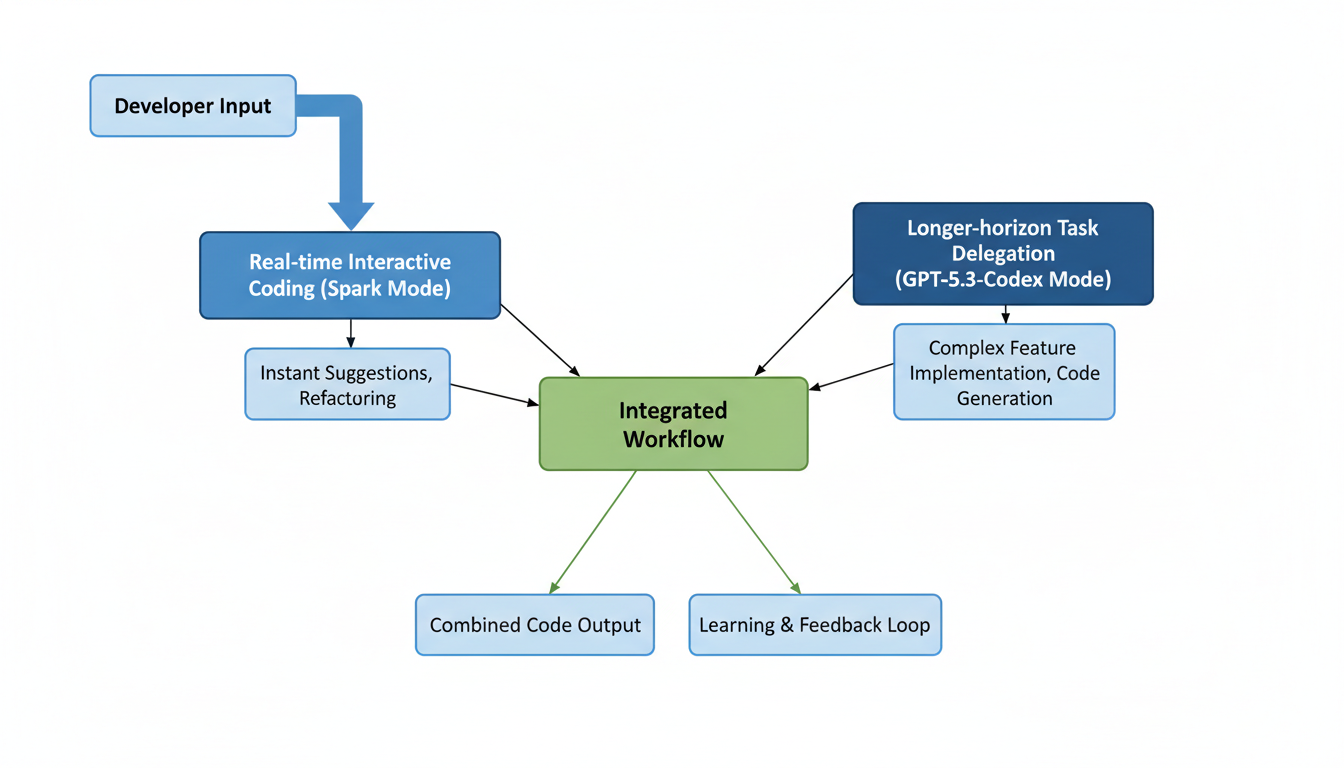
Codex now supports dual coding modes, offering both longer-horizon reasoning for complex, autonomous tasks handled by larger frontier models, and real-time collaboration with Spark for rapid iteration [0-6, 1-1]. OpenAI envisions a future where these modes seamlessly blend, allowing for instant foreground interactions while background sub-agents manage more intricate, long-running processes [0-5].
Infrastructure-Driven Responsiveness
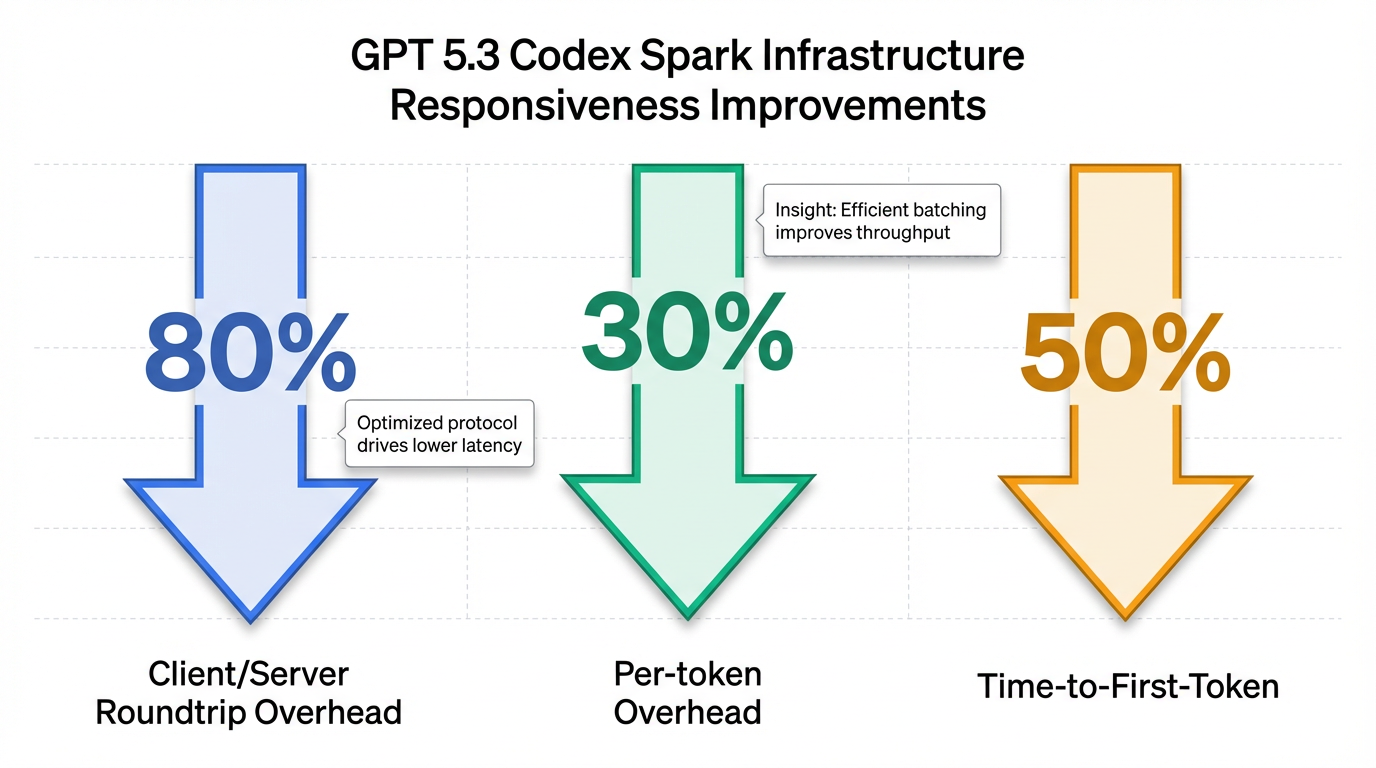
To achieve its remarkable responsiveness, OpenAI has fundamentally redesigned its infrastructure to minimize delays across the entire request-response pipeline [0-1, 0-6]. These improvements encompass streamlined response streaming, rewritten inference stack components, and optimized session initialization, ensuring a faster time-to-first-token [0-1, 0-6]. This infrastructure overhaul has resulted in an 80% reduction in client/server roundtrip overhead, a 30% reduction in per-token overhead, and a 50% faster time-to-first-token [0-4, 0-5]. Furthermore, a persistent WebSocket connection is now the default for Codex Spark, a standard set to be extended to all models [0-5].
Architectural and Training Innovations
GPT 5.3 Codex Spark represents the first milestone in OpenAI's collaboration with Cerebras, leveraging their Wafer Scale Engine 3 (WSE-3) AI accelerator [0-1, 0-3]. The WSE-3 is a colossal chip, measuring 46,255 mm² and housing 4 trillion transistors, capable of delivering 125 petaflops of AI compute through 900,000 AI-optimized cores [0-7, 2-4]. It features the industry's largest on-chip memory, which is critical for high-speed inference [0-2]. This strategic move establishes Cerebras hardware for a dedicated, latency-first serving tier, complementing OpenAI's existing GPU infrastructure which remains foundational for training and cost-efficient large-scale inference [0-5, 0-6]. The very name "Spark" underscores its focus on swift, immediate output and interactive responsiveness [1-3, 2-2].
Deep Dive into Specific Features: Code Generation and Performance
GPT-5.3-Codex-Spark, launched as a research preview on February 12, 2026, is a streamlined, high-speed variant of OpenAI's GPT-5.3-Codex model, specifically engineered for real-time coding tasks 2. This model represents a significant milestone, being the first OpenAI production model to operate on non-Nvidia hardware, a result of a strategic partnership with Cerebras 2.
Specific Code Generation Capabilities
GPT-5.3-Codex-Spark is optimized for highly interactive and iterative software development workflows, demonstrating particular strengths in various coding applications:
- Targeted Editing and Revision: It excels at making precise edits, revising plans, and answering contextual questions related to a codebase 2. This includes effective capabilities for visualizing new layouts, refining styling, and testing new interface changes with immediate feedback 2.
- Practical Use Cases: The model is adept at tasks such as live refactoring of code components, interactive debugging (e.g., explaining variable states and fixing errors), and rapid prototyping, including generating boilerplate code for REST APIs 5.
- Performance Benchmarks: While prioritizing speed, Codex-Spark maintains strong performance on agentic software engineering benchmarks, including SWE-Bench Pro and Terminal-Bench 2.0 2. However, its reasoning depth is generally lower, potentially leading to underperformance compared to the full GPT-5.3-Codex on complex, multi-step terminal operations that demand deep reasoning 5.
- Language and Context Support: At launch, Codex-Spark is text-only and features a 128,000-token context window 6. OpenAI anticipates future iterations will include multimodal input capabilities and extended context lengths 6.
Performance Benchmarks and Efficiency
The "Spark" designation underscores the model's notable performance enhancements, primarily in speed and reduced latency:
- Generation Speed: Codex-Spark is capable of generating over 1,000 tokens per second (tok/s) 2. This makes it approximately 15 times faster than the flagship GPT-5.3-Codex, which typically processes around 65 tok/s 5.
- Latency Improvements: OpenAI has implemented comprehensive end-to-end latency improvements across its request-response pipeline, benefiting all models. Specifically, these optimizations have led to an 80% reduction in client/server roundtrip overhead, a 30% decrease in per-token overhead, and a 50% improvement in time-to-first-token 1. These advancements are largely attributed to the introduction of a persistent WebSocket connection and significant optimizations within the inference stack 1.
- Specific Task Performance:
- SWE-Bench Pro: Codex-Spark achieves an accuracy comparable to GPT-5.3-Codex (e.g., 56.8% for GPT-5.3-Codex 7), but completes tasks in a mere 2-3 minutes, significantly faster than the 15-17 minutes typically required by GPT-5.3-Codex 2.
- Terminal-Bench 2.0: The model scores 58.4% on this benchmark, which is lower than GPT-5.3-Codex's 77.3% 5.
- Efficiency: Beyond speed, Codex-Spark also enhances efficiency by utilizing fewer tokens for certain outputs, particularly evident on SWE-Bench Pro tasks 7.
Unique Features and Developer Tooling
Codex-Spark introduces several features aimed at enriching the developer experience:
- Interactive Coding: Designed for interactive work where low latency and high responsiveness are crucial, the model enables developers to collaborate with it in real-time. This allows for interruption or redirection of its output for rapid iteration, effectively offering "real-time steering" of code generation 2. Its default operating style is lightweight, focusing on minimal, targeted edits and only running tests when explicitly prompted 1.
- Developer Tooling Integrations: It is available as a research preview to ChatGPT Pro users through various developer tools, including the Codex app, Command Line Interface (CLI), and a VS Code extension 2. API access is also progressively being rolled out to selected design partners 2.
- Future Dual Modes: OpenAI envisions Codex-Spark as the foundational step towards a dual-mode Codex system. This future system will combine longer-horizon reasoning and execution capabilities with real-time collaboration for rapid iterations. These modes are expected to merge, enabling developers to maintain interactive loops while delegating longer-running background tasks to sub-agents or multiple models 1.
- Safety Protocols: The model incorporates the same safety training as OpenAI's mainline models, including cyber-relevant training. It has been evaluated and deemed unlikely to meet the Preparedness Framework's threshold for high capability in cybersecurity or biology. This contrasts with the full GPT-5.3-Codex, which is classified as "High capability" for cybersecurity 1.
Advancements Enabled by the 'Spark' Designation
The "Spark" designation highlights an unprecedented focus on speed and low-latency inference, achieved through key architectural and operational advancements:
- Dedicated Hardware (Cerebras Wafer-Scale Engine 3 - WSE-3):
- A core innovation is its operation on the Cerebras WSE-3, an AI accelerator purpose-built for such tasks 6.
- Unlike conventional AI chips, which are cut into individual processors from wafers, the WSE-3 uses an entire silicon wafer as a single, massive chip. This design effectively eliminates inter-chip communication bottlenecks, which are a common source of latency 5.
- The WSE-3 is a colossal chip, measuring 46,225 mm², containing 4 trillion transistors, 44 GB of on-chip SRAM memory, and 900,000 AI-optimized cores, delivering an impressive 125 petaflops of AI compute 5. This architectural advantage is critical to achieving its 1,000+ tok/s speed 5.
- Cerebras hardware complements traditional GPUs by excelling in workflows that demand extremely low latency, making Codex-Spark feel more responsive during iterative development tasks 1.
- Software and Infrastructure Optimizations: Beyond the specialized hardware, OpenAI has extensively re-engineered its inference stack. This involved streamlining how responses stream, rewriting key inference components, and optimizing session initialization to reduce the time-to-first-token. The implementation of a persistent WebSocket connection also drastically reduces overhead per client/server roundtrip 1.
- Strategic Trade-offs: The "Spark" model embodies a deliberate strategic trade-off, prioritizing responsiveness and inference speed. This comes at the expense of the deeper reasoning capabilities and advanced cybersecurity awareness found in the larger GPT-5.3-Codex 5. This design choice makes it exceptionally effective for rapid, small-scale interactive tasks and is intended to accelerate daily coding activities and enhance developer flow state 5.
Comparative Performance with Other Models
Codex-Spark is reported to be 3-7 times faster than its closest competitors, all while maintaining significantly higher coding accuracy 5. The Cerebras hardware provides a notable advantage in throughput for low-latency inference, setting it apart in the market 5.
| Model | Speed | SWE-Bench Pro | Context | Hardware |
|---|---|---|---|---|
| Codex-Spark | 1,000+ tok/s | ~56% | 128K | Cerebras WSE-3 |
| Claude Haiku 4.5 | ~200 tok/s | ~35% | 200K | Nvidia |
| Gemini 3 Flash | ~300 tok/s | ~40% | 1M | Google TPU |
| GPT-5.2 Instant | ~150 tok/s | ~45% | 128K | Nvidia |
| DeepSeek Coder V3 | ~180 tok/s | ~42% | 128K | Nvidia |
Implications and Future Outlook
The introduction of GPT-5.3-Codex-Spark is poised to profoundly impact software development, the broader AI ecosystem, and hardware innovation. Its unique blend of speed and interactivity promises to redefine developer workflows and foster a new era of collaborative AI.
One of the most significant implications is the revolutionizing of software development workflows. Codex-Spark excels in highly interactive and iterative environments, allowing for real-time collaboration with the model through precise edits, revision of plans, and answering contextual questions about codebase 2. This capability extends to live refactoring, interactive debugging, and rapid prototyping, thereby significantly accelerating day-to-day coding activities and enhancing developer flow state . The model's optimized responsiveness and low latency enable developers to interrupt or redirect its output for rapid iteration, making it an invaluable tool for maintaining momentum in coding tasks 2.
Looking ahead, OpenAI envisions Codex-Spark as the foundational step towards a dual-mode Codex system. This future system will seamlessly blend rapid, real-time collaboration with the ability to delegate longer-horizon reasoning and execution tasks to sub-agents or multiple models . This architectural evolution could empower developers to maintain interactive loops for immediate tasks while simultaneously managing complex background processes, thus creating a more fluid and efficient development paradigm.
The strategic partnership between OpenAI and Cerebras, highlighted by Codex-Spark running on non-Nvidia hardware, signifies a potential diversification of the AI hardware landscape . The use of Cerebras' Wafer-Scale Engine 3 (WSE-3), a purpose-built AI accelerator, demonstrates a shift towards specialized hardware optimized for specific AI workloads . This move beyond traditional GPUs could inspire further innovation and competition in AI infrastructure, leading to more tailored solutions for different AI model requirements.
Future iterations of Codex-Spark are expected to expand beyond its current text-only interactions to include multimodal input and longer context windows . These advancements will significantly broaden its utility, potentially allowing developers to interact with the model using visual cues, voice commands, and larger codebases, further enhancing its contextual understanding and assistance capabilities.
Finally, Codex-Spark carves out a specialized niche as a tool for rapid, small-scale interactive tasks. Its design prioritizes responsiveness and inference speed, making it exceptionally effective for quick coding edits and interface refinements . This focus distinguishes it from more powerful, deeper reasoning models like the full GPT-5.3-Codex, which remain better suited for complex architectural changes or sensitive security contexts due to their higher reasoning depth . This positioning ensures that Codex-Spark complements, rather than replaces, other AI models, contributing to a more diversified and capable AI developer toolkit.