GPT 5.3 Codex Spark 最新发布:能力突破与核心亮点深度解析
引言
根据最新的搜索结果,备受瞩目的GPT-5.3-Codex-Spark模型确实存在,其正式名称为GPT-5.3-Codex-Spark,也被简称为Codex-Spark。该模型是由OpenAI与Cerebras合作推出的,标志着人工智能在编程领域又迈出了重要一步。本文旨在围绕GPT-5.3-Codex-Spark的最新发布情况、核心功能、突出能力及其对AI编程领域的潜在影响进行深入探讨。
作为OpenAI与Cerebras合作的首个公开发布成果,GPT-5.3-Codex-Spark是为实时编程设计的超高速模型,旨在解决AI编程中普遍存在的“等待焦虑”问题1。它被定位为针对快速推理场景优化的“具备高度能力的小模型”2,其推出对于提升开发效率和优化编码体验具有重要意义,预示着未来AI编程工具将更加智能、高效和即时。
GPT 5.3 Codex Spark 是什么?
GPT-5.3-Codex-Spark,简称为Codex-Spark,是OpenAI与Cerebras合作推出的一款面向实时编程的超高速模型2。这款模型由OpenAI与Cerebras共同发布2,其中Cerebras主要负责提供算力支持,该模型运行在其晶圆级引擎3 (Wafer-Scale Engine 3, WSE-3) 上2。值得注意的是,这是OpenAI与Cerebras首次公开发布合作成果,也标志着OpenAI首次将模型部署在非NVIDIA的硬件上3。
Codex-Spark的核心定位是一款“具备高度能力的小模型”,专注于解决AI编程中普遍存在的“等待焦虑”问题,专门针对快速推理场景进行优化,以实现超高速的实时编程体验2。它被视为OpenAI推出的GPT-5.3-Codex模型的“较小版本”或“精简版”4,与作为“父模型”的GPT-5.3-Codex形成互补,共同构建一个灵活且高效的编程助手生态系统5。该模型致力于为开发者提供超高速的即时编码反馈和协作体验2,以显著提升开发效率。
最新发布详情
GPT-5.3-Codex-Spark是OpenAI与Cerebras合作推出的一款专注于实时编程的超高速模型,旨在解决AI编程中的“等待焦虑”问题1。该模型被定位为“具备高度能力的小模型”2,是GPT-5.3-Codex模型的“较小版本”或“精简版”,专门针对快速推理场景进行了优化2。Cerebras在此次合作中提供了关键的算力支持,该模型运行在其晶圆级引擎3 (Wafer-Scale Engine 3) 上,这也是OpenAI与Cerebras合作的首个公开发布成果,同时也是OpenAI首个部署在非NVIDIA硬件上的模型。
该模型于当地时间2026年2月12日以“研究预览”(research preview) 形式开放,而其更宏大的父模型GPT-5.3-Codex(非Spark版本)已于2026年2月5日正式登场。OpenAI和Cerebras选择在2026年2月12日发布了关于该模型的官方公告。据报道,GPT-5.3-Codex-Spark预计将在2026年第二季度全面上线1。
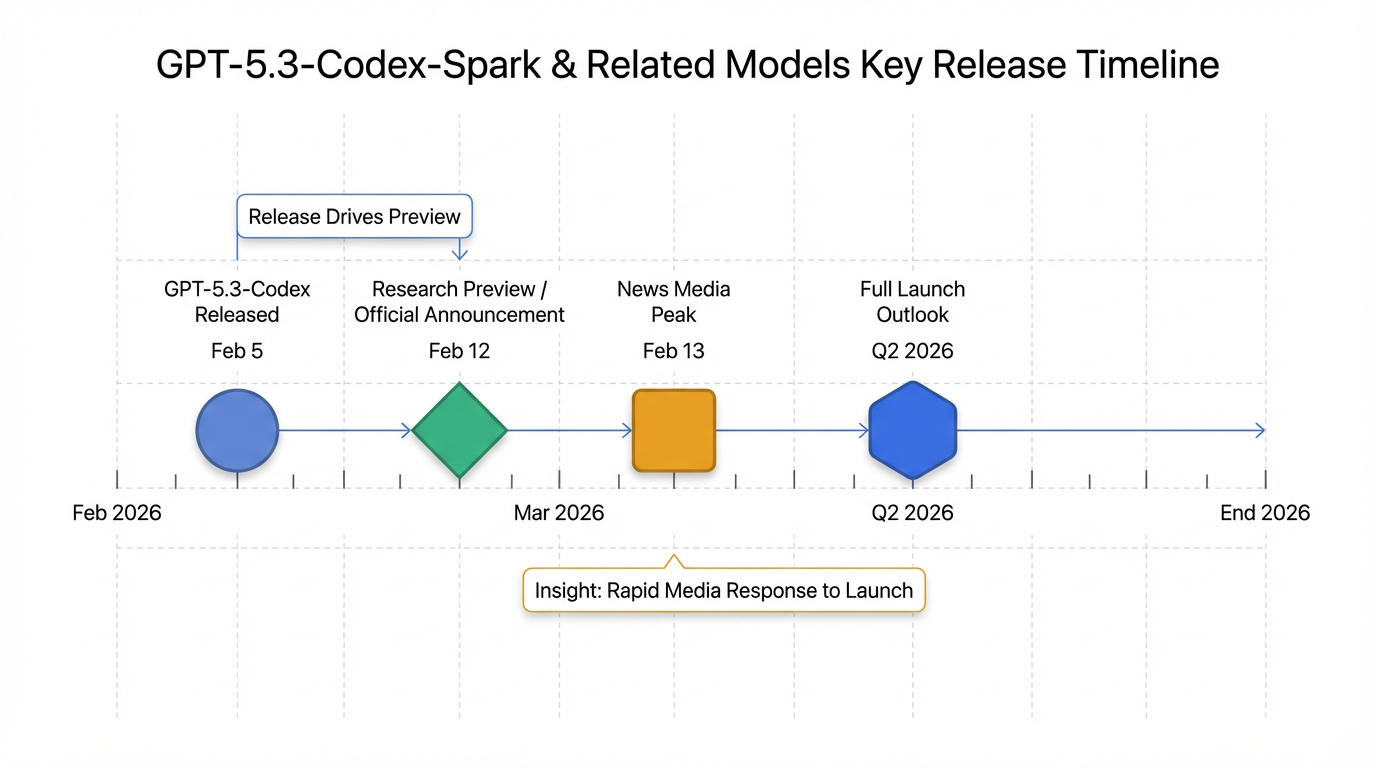
此次发布获得了广泛关注,OpenAI发布了题为《Introducing GPT-5.3-Codex-Spark》的官方博客文章5,Cerebras公司也发布了题为《Introducing OpenAI GPT-5.3-Codex-Spark Powered by Cerebras》的官方新闻稿6。2026年2月13日左右,IT之家、新浪科技、凤凰网、Yahoo Tech、财联社、钛媒体、ITBear 比尔科技、搜狐网、AASTOCKS 等多家权威科技媒体均对该模型的发布进行了详细报道。
目前,Codex-Spark以研究预览形式向ChatGPT Pro用户推送,覆盖Codex应用、命令行界面 (CLI) 以及VS Code扩展。API访问将逐步向部分设计合作伙伴开放。在研究预览期间,Codex-Spark将有独立的速率限制,其使用量不计入标准Codex限制。OpenAI预计在2026年将这种“超高速推理”能力带到更大规模的前沿模型上,并在未来版本中引入更多功能,包括更大模型、更长上下文长度以及多模态输入。
模型亮点与能力突破
GPT-5.3-Codex-Spark 作为 OpenAI 与 Cerebras 合作的“首个里程碑”,同时也是 OpenAI 首个部署在非 NVIDIA 硬件上的模型,凭借其一系列突破性亮点和能力,在实时编程领域树立了新的标杆。它被正式定位为 GPT-5.3-Codex 的“更小版本”或“精简版”,专门为需要极高交互速度的实时软件开发场景而优化,强调“快速、响应及时、可引导”,确保开发者在工作中保持主导地位。该模型是“具备高度能力的小模型”,专注于快速推理和原型设计场景。
实时编程的超高速引擎
GPT-5.3-Codex-Spark 的核心优势在于其超高速实时编程能力。它能够实现每秒超过 1000 token 的推理速度,提供近乎即时的编码反馈。据报告显示,其生成代码的速度比 GPT-5.3-Codex 快 15 倍,这使得开发者可以获得前所未有的流畅交互体验。在功能上,该模型擅长进行精确的代码修改、计划调整,并能围绕代码库进行上下文问答,同时也能高效地完成 UI/UX 优化,例如快速可视化新布局、优化样式以及测试新的界面变更等工作。其默认工作方式轻量级,进行最小化、有针对性的编辑,极大地提升了开发效率。
强大的技术规格与深度优化
在技术规格方面,GPT-5.3-Codex-Spark 展现了其强大实力。它拥有一个高达 128k token 的上下文窗口,能够处理更为复杂和庞大的代码库。更值得关注的是,该模型运行在 Cerebras 的晶圆级引擎 3 (Wafer-Scale Engine 3, WSE-3) 上,WSE-3 是 Cerebras 的第三代晶圆级巨型芯片,集成了 4 万亿个晶体管,这为其极致的性能提供了硬件基础。
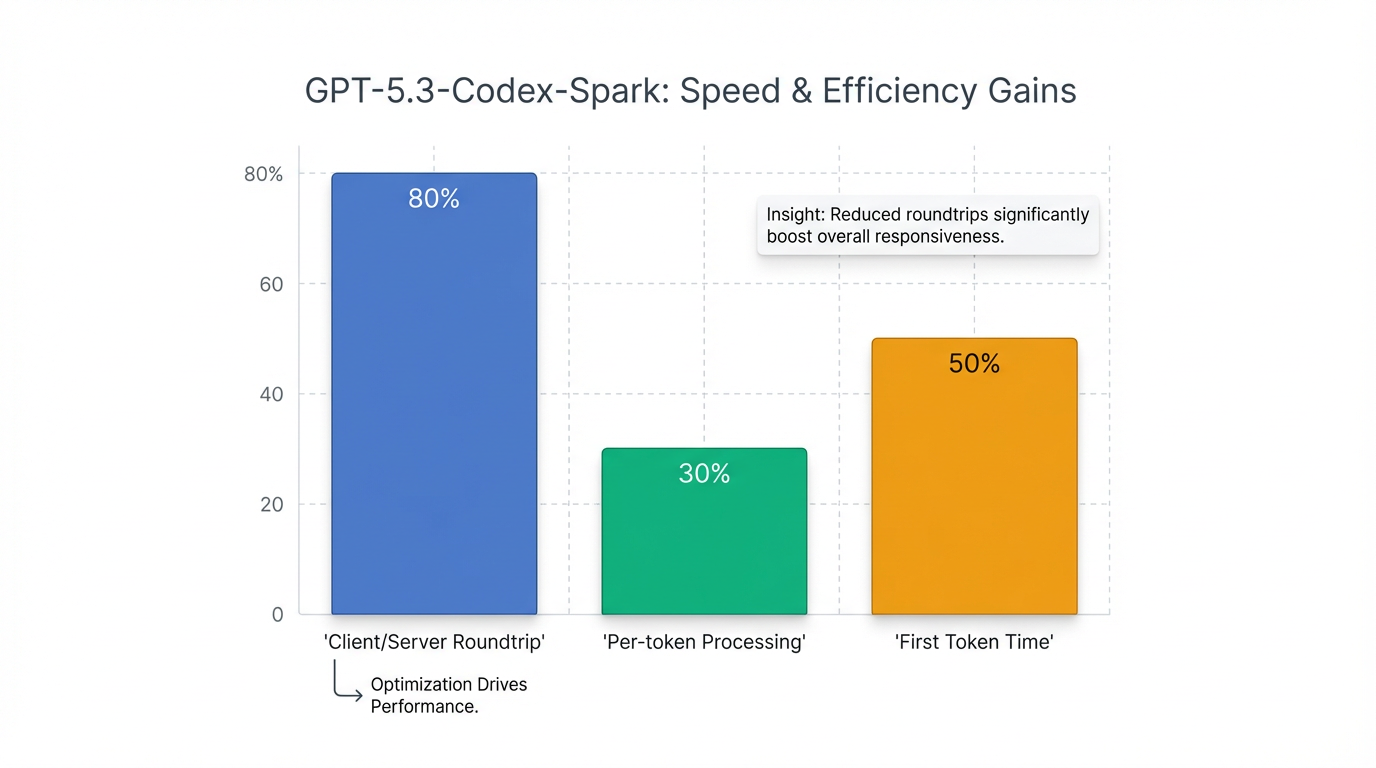
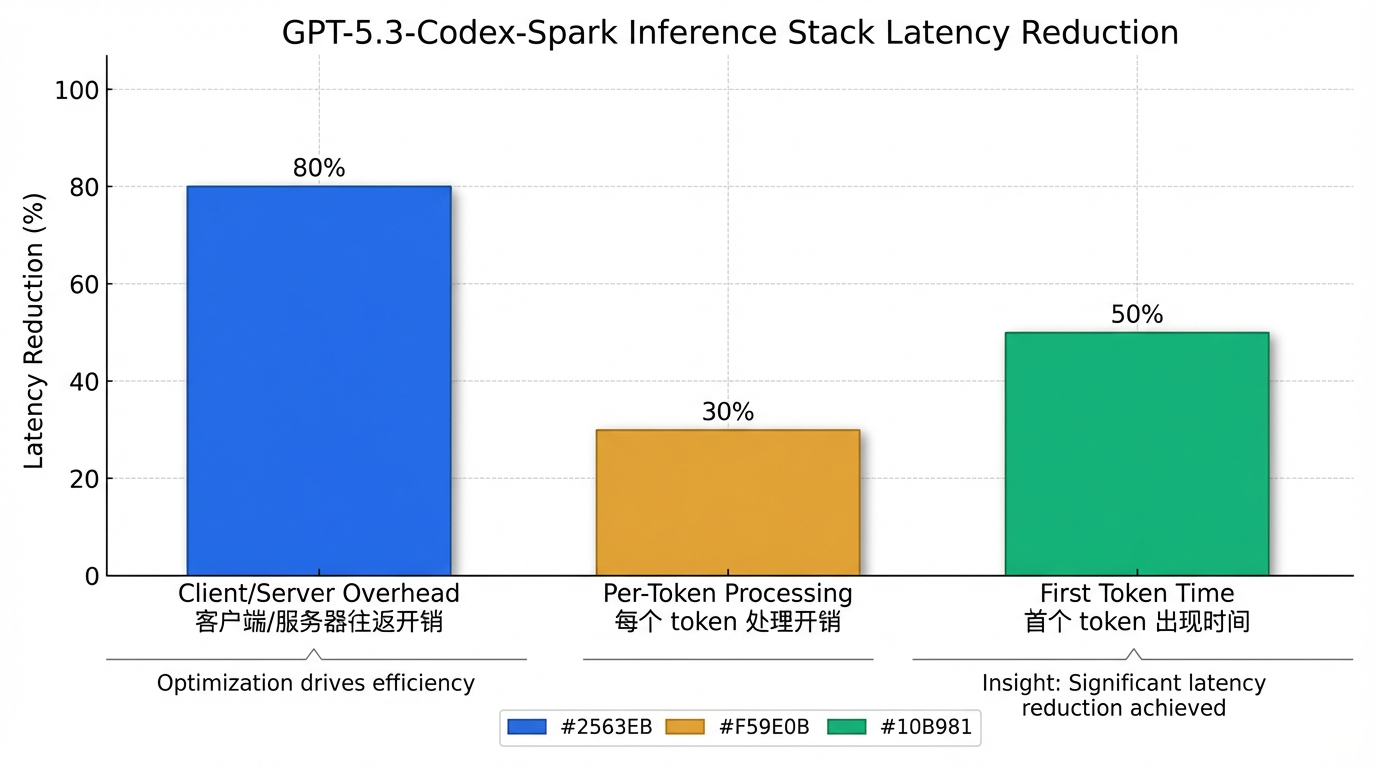
OpenAI 对整个推理堆栈进行了深度延迟优化,具体表现在:
- 客户端/服务器往返开销减少 80%。
- 每个 token 的处理开销减少 30%。
- 首个 token 的出现时间缩短 50%。 这些优化通过引入持久性 WebSocket 连接和对 Responses API 的针对性优化实现,显著提升了模型响应速度。
基准性能的卓越表现
GPT-5.3-Codex-Spark 在基准测试中展现出令人印象深刻的性能。在 SWE-Bench Pro 和 Terminal-Bench 2.0 等代理式软件工程基准测试中,它表现出色,在完成任务耗时显著缩短的同时,能够给出比 GPT-5.1-Codex-mini 更好的回答。相较于父模型 GPT-5.3-Codex,Spark 能够以更少的时间完成任务。虽然为了实现极致的速度,其在某些复杂任务的“能力”或“质量”上可能有所权衡(例如在生成 SVG 图像时,质量不如 GPT-5.3-Codex7),但 OpenAI 认为这种速度带来的交互体验价值,高于能力上的轻微妥协8。
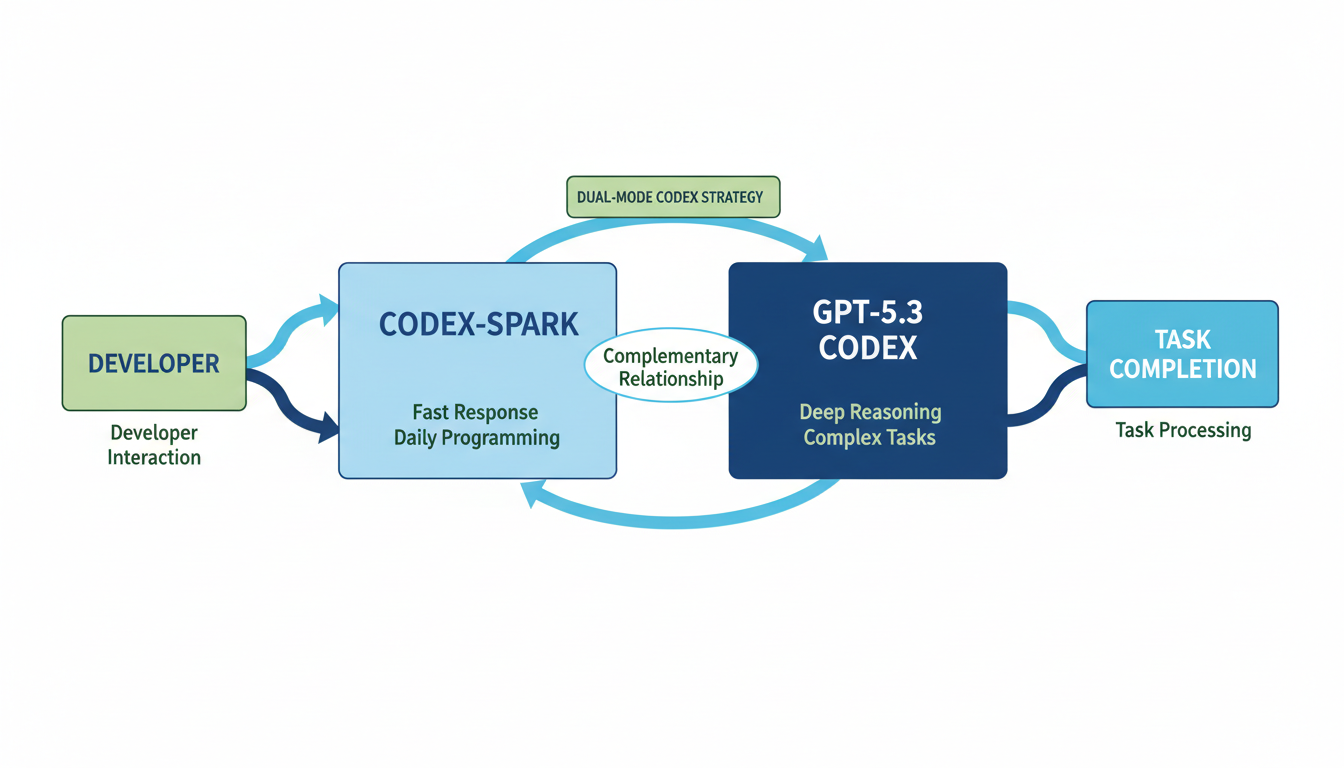
GPT-5.3-Codex-Spark 的推出标志着 Codex 系统走向“双重模式”的关键一步。它结合了自身卓越的实时协作能力,与未来可能由其他模型承担的长时间推理与执行能力形成高效互补。这种战略布局不仅展示了 OpenAI 在提升开发者生产力方面的决心,也预示着大模型与“小而强”模型协同工作的新范式。
市场反响与潜在影响
市场反馈与用户反响
GPT-5.3 Codex Spark 被定位为 GPT-5.3 Codex 的轻量化版本 9,专为对交互速度要求极高的实时软件开发场景设计 10。该模型面向 ChatGPT Pro 用户开放研究预览 10,并通过 Codex 应用、命令行界面 (CLI) 以及 VS Code 扩展提供服务 10。API 访问权限则逐步向部分设计合作伙伴开放 10。OpenAI 首席执行官萨姆·奥特曼(Sam Altman)曾暗示此次发布“让我感到‘怦然心动’” 11。
在活跃度方面,Codex 应用的活跃用户已超过 100 万 12,发布后十天内下载量超过 100 万次 13。目前,在免费和付费层级积极使用 Codex 的开发者已超过 32.5 万 13。该模型的发布旨在解决 AI 编程中的“等待焦虑”,回应开发者对实时交互的迫切需求 14。许多开发者表示,此前传统模型生成代码时存在等待延迟,这严重拖慢开发节奏并打断编程思路,而 Spark 的实时反馈能力有望重塑编程体验 14。有用户指出,许多开发者正从 Claude Code 转向 Codex,认为 Codex Plus 会员即可使用且不易封号 12。此外,GPT-5.3 Codex Spark 革新了交互模式,用户可以在模型生成代码的过程中随时打断、重新指挥方向,模型几乎能瞬间响应,代码感觉“就像是从指尖流出来的” 9。
GPT-5.3 Codex Spark 的发布加剧了 AI 编码助手市场的竞争 13。它旨在与 Alphabet 旗下谷歌及 Anthropic 等公司在 AI 编程助手市场展开竞争 15。以下是同期主要竞争产品的对比:
| 产品名称 | 速度 (tokens/s) | 主要特点 | Terminal-Bench 2.0成绩 |
|---|---|---|---|
| GPT-5.3 Codex Spark | 超 1000 | 实时编程,轻量化版本,解决“等待焦虑”,支持过程中打断/重指挥,Cerebras WSE-3硬件支持 | 性能逊于完整的 GPT-5.3 Codex |
| GitLab | 目标 800 | 计划2026年Q3推出基于自有模型的实时编程助手 | 无 |
| Google DeepMind AlphaCode 2.5 | 750 | 2026年1月更新,新增Python和Java实时调试功能 | 无 |
| Anthropic Claude 3.1-Code | 约 600 | 代码漏洞识别准确率比行业平均水平高出15%,更注重代码安全性 | 无 |
| Claude Opus 4.6 | 无 | 与GPT-5.3 Codex Spark同期发布,在某些方面(如上下文长度)具有优势 | 65.4% |
业界评价与专家评论
GPT-5.3 Codex Spark 在技术上取得了显著突破,其最亮眼的性能体现在超高速推理能力上,可实现超 1000 tokens/s 的推理速度 10,比旗舰 GPT-5.3 Codex 快约 15 倍 9。这一性能的核心驱动力来自 Cerebras 研发的第三代晶圆级引擎(WSE-3),该芯片集成了多达 4 万亿个晶体管 11,消除了传统多芯片集群间的通信延迟 14,能以极高的并行计算能力处理大规模模型推理任务 14。OpenAI 表示,预计在 2026 年将这种“超高速推理”能力带到更大规模的前沿模型上 10。
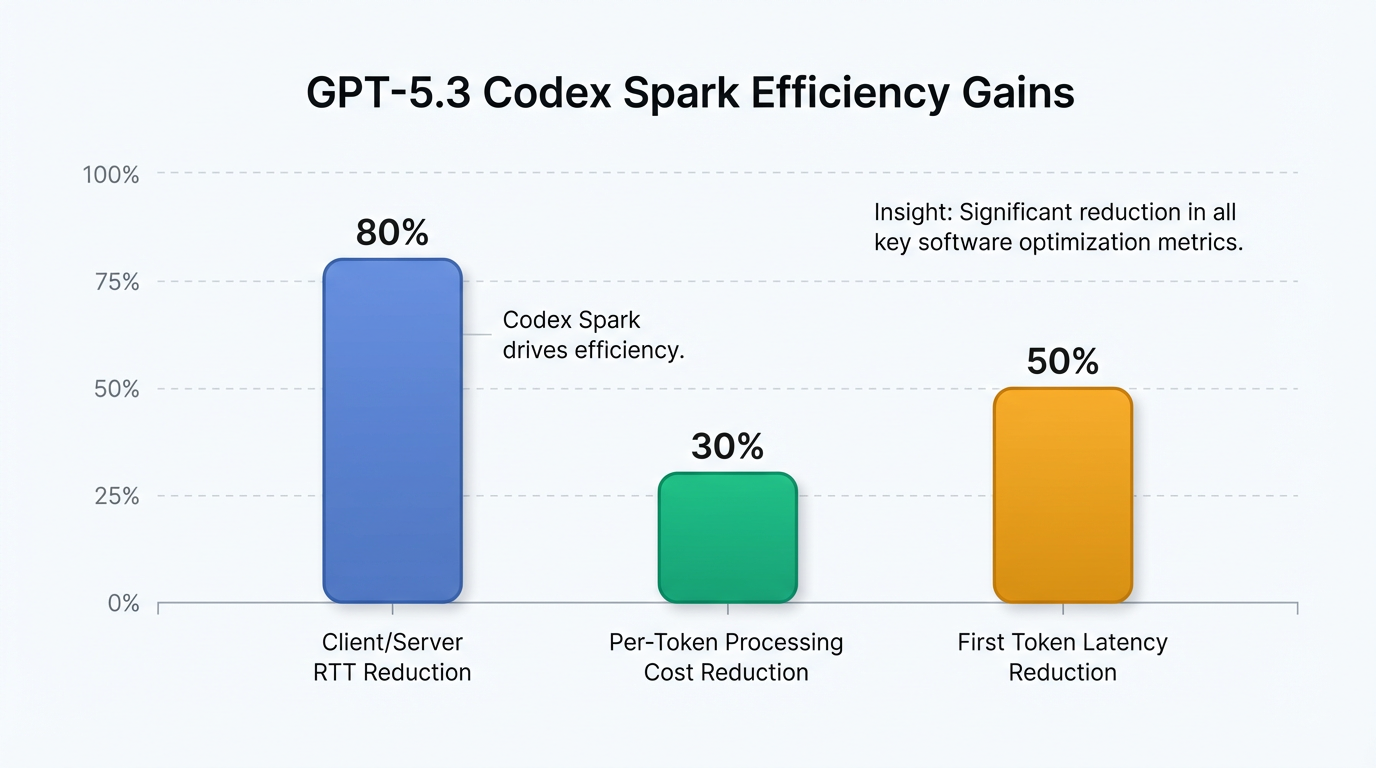
同时,OpenAI 也通过软件优化提升了性能。他们针对编程场景调整了 tokenization 策略,优先高效处理代码语法结构和关键词;并简化了部分非必要的推理步骤,在保证代码准确性的前提下进一步压缩响应时间 14。此外,在框架中实现了端到端延迟优化,客户端/服务器单次往返开销降低 80%,每 token 处理开销降低 30%,第一个 token 出现时间缩短 50% 16。
在基准测试表现上,Codex-Spark 在 SWE-Bench Pro、Terminal-Bench 2.0 等软件工程基准测试上,完成任务耗时显著缩短的同时,能够给出比 GPT-5.1-Codex-mini 更好的回答 10。具体来看,GPT-5.3 Codex 在 Terminal-Bench 2.0 上的表现远超之前的纪录(77.3%),而 Claude Opus 4.6 为 65.4% 12。
OpenAI 提出了“双重模式”战略,设想让 Codex-Spark 与 GPT-5.3 Codex 互补配合,Spark 负责快速响应和日常编程,而更大、更强的 GPT-5.3 Codex 则负责处理需要深度推理和长时间执行的复杂任务 9。OpenAI 强调 Codex-Spark 的设计核心在于将 Codex 的延迟压低至极限,构建“双重模式 Codex”:能兼顾快速迭代时的实时协作,以及深度推理与执行时的长周期任务 11。
OpenAI 还指出,“agentic coding”(代理编程)正逐渐改变软件开发方式,机器能够在较少人工监督下持续工作数小时甚至数天 10。Codex-Spark 被设计为与 Codex 进行实时协作的模型,强调“快速、响应及时、可引导”,让开发者保持工作中的主导位置 10。
此次发布还揭示了 OpenAI 在战略合作与“去英伟达化”方面的布局。OpenAI 与 AI 芯片巨头 Cerebras 达成了价值逾 100 亿美元的多年期合作协议 9,采购高达 750MW 的低延迟运算能力 17。Cerebras 的估值约 230 亿美元,刚完成 10 亿美元融资 9。此举被视为 OpenAI 拓宽芯片供应体系、降低对英伟达过度依赖的重大战略布局 11。这是 OpenAI 在推理层面首次大规模跳出英伟达生态 9,表明对于特定场景,专用芯片可以把体验提升到一个完全不同的量级 9。OpenAI 发言人表示,GPU 仍是训练与推理的核心主力,负责大规模与成本效益运算,Cerebras 则补足极低延迟场景 17。OpenAI 的合作关系是“基础性的”,同时通过与 Cerebras、AMD 和博通的合作有意扩展其周围的生态系统 13。Cerebras CTO 肖恩·莱(Sean Lie)对与 OpenAI 和开发者社区一起探索快速推理能带来的可能性感到兴奋,认为它将开启新的交互模式、新的使用场景和“根本不同的模型体验” 9。
对软件开发领域的潜在影响
GPT-5.3 Codex Spark 的出现将深刻改变开发实践与工作流程。它能够提供近乎即时的编码反馈,让开发者在编写复杂算法或调试代码时,输入问题后迅速获得代码片段或修复建议 14。这种即时性将大幅提升开发效率,并帮助开发者维持连贯的思维状态,减轻认知负担 14。
该模型被定位为日常编程的生产力工具,适用于快速原型、实时协作、即时迭代 9。开发者可以在代码生成过程中随时打断、调整方向,模型能快速响应 9。它将支持更深度的“代理编程”,机器能在较少人工监督下持续工作,从而改变软件开发方式 10。Codex-Spark 擅长精确代码修改、计划调整、围绕代码库进行上下文问答,适用于快速可视化新布局、优化样式以及测试新的界面变更等 10。在实测中,GPT-5.3-Codex 展现出处理本地文件、格式转换、调用 Skills、制作 Word/PPT/Excel、下载视频、开发 App 等能力 12。
在工具集成与生态发展方面,该模型将整合到主流 IDE 插件和在线编程平台中 14。目前已覆盖 Codex 应用、CLI 以及 VS Code 扩展 10。值得一提的是,GPT-5.3 Codex(旗舰版)是 OpenAI 首个深度参与自身开发的模型,使用早期版本来调试训练过程、管理模型部署、诊断测试结果,这种“AI 训练 AI”的模式大幅提升了开发效率 18。GPT-5.3 Codex 已从单纯的代码编写工具,演变为一个能将代码作为工具来操作计算机并完成端到端工作的智能体 19。它能支持软件生命周期的全流程,包括调试、部署、监控、撰写 PRD、编辑文案、用户研究、测试、指标分析等 19。
对AI研究领域的潜在影响
OpenAI 与 Cerebras 的合作表明,对于特定 AI 任务,专用芯片(如晶圆级芯片)可能提供比通用 GPU 更优的性能和更低的延迟 9。这将推动 AI 硬件领域的发展和多元化,减少对单一供应商(如英伟达)的过度依赖 11。Cerebras 的 Wafer Scale Engine 3 提供了极低延迟的推理平台,解决了 AI 模型扩展时对超低延迟算力资源的迫切需求 17。OpenAI 将这种“超高速推理”能力引入到更大规模的前沿模型上 10,有望加速未来更大规模 AI 模型的部署和应用。
在 AI 模型研究方向上,业界对 AI 模型“Agentic 能力”的关注持续增加,即模型具备长程规划、多步执行以及处理复杂系统工程的能力 20。GPT-5.3 Codex Spark 的发布是这一方向的体现,推动 AI 模型向更复杂的任务和更强的自主性发展。OpenAI 提出“双重模式 Codex”的概念,预示着 AI 模型未来可能在兼顾快速交互与深度推理之间寻找最佳平衡,从而适应更多元的应用场景 17。此外,GPT-5.3 Codex 是首个在网络安全相关任务中被评为“高能力”的模型,直接训练用于识别软件漏洞 19。这表明 AI 在网络安全研究和防御领域的应用将成为重要的研究方向。
局限性、争议与挑战
尽管 GPT-5.3 Codex Spark 带来了显著的性能提升,但也存在能力与速度的权衡。其速度提升是以功能上的妥协为代价的 21。在 SWE-Bench Pro 和 Terminal-Bench 2.0 等基准测试中,Codex-Spark 的性能逊于完整的 GPT-5.3 Codex 模型 21。OpenAI 认为这是可接受的权衡,因为多数开发者会接受这样的取舍以换取更即时的创作节奏 21。然而,社区中也有用户对“速度更快”的同时能否维持足够的推理深度和代码质量表示担忧 16。他们认为速度快但有缺陷的代码毫无用处,而代码速度慢但正确才有用 16。
在访问限制与资源瓶颈方面,Codex-Spark 目前以研究预览形式发布,可能会因需求量高而出现排队或暂时限制访问的情况,以维持服务稳定性 17。API 访问权限初期仅向部分设计合作伙伴逐步开放,OpenAI 尚未向公众开放 API,原因是“模型太强了,会存在很大的风险” 12。
OpenAI 内部也面临挑战与外部压力。该公司正应对一系列内部动荡,包括安全团队解散、研究人员离职以及在 ChatGPT 中引入广告等争议 13。这些问题引发了外界对公司方向和价值观的审视 13。同时,AI 编码助手市场竞争激烈,来自谷歌、Anthropic 等对手的压力促使 OpenAI 不断创新 13。此外,OpenAI 与英伟达之间微妙的关系,此前达成的千亿美元合作据称陷入停滞 13,凸显了 OpenAI 在供应商多元化策略上的挑战 13。