MiniMax-M2.5, AI 에이전트 및 코딩 워크플로우의 새로운 지평을 열다
MiniMax-M2.5 출시 발표
MiniMax-M2.5가 2026년 2월 11일에 공식적으로 발표 및 출시되었습니다 1. 이 모델은 웹 및 데스크톱용 MiniMax Agent 플랫폼을 통해 배포되기 시작했으며 2, 로이터 통신에 의해 당일 보도되었습니다 1. 이번 출시는 "중국 AI에게 중요한 날"로 평가받으며 2, "앞으로 몇 달 동안 오픈소스 AI 담론의 분위기를 조성할 것"으로 전망되고 있습니다 3.
MiniMax는 "모두를 위한 AI" 및 "모두와 함께하는 지능"이라는 비전 아래 고성능이면서 저비용 모델 기능을 지속적으로 제공하여 AI 기술 접근성의 장벽을 허무는 것을 목표로 합니다 4. 특히, 선행 모델인 M2는 기존 해외 모델의 높은 비용과 느린 속도, 그리고 국내 모델의 성능 격차라는 문제점을 해결하고자 개발되었습니다 5. MiniMax는 성능, 가격, 속도 사이의 최적 균형을 달성하여 더 많은 사용자가 AI 시대의 지능 향상 혜택을 누리도록 하는 것을 핵심 비전으로 삼고 있습니다 4.
선행 모델인 M2.1은 AI 에이전트 워크플로우 및 복잡한 코드 생성에 최적화되어 출시되었으며 6, 다국어 소프트웨어 개발, 다단계 계획 및 도구 사용에 강점을 가집니다 6. M2.1은 M2 대비 실제 복합 작업 환경에서의 성능 향상과 더 많은 프로그래밍 언어 및 오피스 시나리오에서의 유용성 증대에 중점을 두었습니다 4. 이러한 배경을 바탕으로 MiniMax-M2.5 또한 이전 모델들의 강점을 계승하며 AI 기술의 보편화와 에이전트 및 코딩 시나리오에서의 효율성을 더욱 발전시키는 데 목적이 있는 것으로 예상됩니다. MiniMax는 고성능, 저비용 모델의 지속적인 공개를 통한 오픈소스 전략을 강조하며, 중소기업이나 개인 개발자도 고급 AI 기술에 접근할 수 있도록 지원합니다 4.
주요 특징 및 혁신
MiniMax는 "모두를 위한 AI (AI for All)"와 "모두와 함께하는 지능 (Intelligence with Everyone)"이라는 비전 아래 MiniMax-M2.5를 선보였습니다4. 이 최신 대규모 언어 모델(LLM)은 이전 MiniMax M2 및 M2.1 모델의 강력한 기반을 토대로 AI 에이전트 및 코딩 워크플로우에 최적화된 성능과 효율성을 제공하며, 고성능 AI 기술의 접근성을 높이고 AI 민주화를 가속화하는 데 중점을 둡니다4.
1. 핵심적인 새로운 기능 및 개선된 사양
1.1 MiniMax-M2.5의 핵심 새로운 기능 MiniMax-M2.5는 이전 버전의 장점을 계승하며, 사용자 경험 및 기능적 통합 측면에서 크게 진일보했습니다.
- 새로운 에이전트 데스크톱: MiniMax Agent Desktop이라는 새로운 AI 네이티브 워크스페이스가 MiniMax-M2.5와 함께 출시되어, AI 에이전트 기능을 데스크톱 환경으로 확장했습니다7. 이는 사용자가 작업을 보다 쉽게 제출하고 관리할 수 있도록 설계되었습니다7.
- '자동(Auto)' 및 '전문가(Experts)' 모드: MiniMax-M2.5는 에이전트 데스크톱 내에서 '자동' 및 '전문가' 모드를 제공하여, 다양한 수준의 사용자와 복잡한 작업에 맞춰 유연한 에이전트 실행 환경을 지원합니다7.
1.2 주요 기술 사양 (MiniMax M2/M2.1 기반) MiniMax-M2.5의 구체적인 세부 사양은 명시되지 않았으나, 이전 모델인 M2와 M2.1의 사양을 바탕으로 발전했을 것으로 예상됩니다. MiniMax M2/M2.1 모델의 주요 기술 사양은 다음과 같습니다.
| 사양 항목 | 내용/값 | 적용 모델 | 비고 |
|---|---|---|---|
| 모델 아키텍처 | Mixture-of-Experts (MoE) 시스템 | M2, M2.1 | 트랜스포머 기반 |
| 총 파라미터 수 | 2,300억 개 | M2 | 거대 모델급 성능 |
| 활성 파라미터 수 | 약 100억 개 | M2 | 연산 효율성 극대화 |
| 희소성 (활성 비율) | 4.37% (전체 파라미터 대비) | M2 | Qwen3보다 2배 더 희소 |
| 희소성 비율 | 23:1 | M2.1 | 높은 희소성 |
| 추론 비용 | Claude 3.5 Sonnet의 8% | M2 | 오픈 모델 중 가장 저렴한 API 가격 |
| 추론 속도 | Claude 3.5 Sonnet의 2배 | M2 | 초당 약 100 토큰 |
| 컨텍스트 윈도우 | 약 200,000 토큰 범위 | M2, M2.1 | 장기 컨텍스트 지원 (예: 204,800 / 196,608 토큰) |
| 정밀도 | FP8 기반 | M2 | 경량 추론 구조 |
| 모달리티 | 텍스트 전용 | M2 | 도구 호출 및 함수 호출 지원 |
| 모달리티 확장 | 시각 정보 처리 능력 입증 | M2.1 | 도형 둘레, H빔 제원 인식 테스트 |
MiniMax-M2.5는 MiniMax M2 및 M2.1의 핵심 기술 사양을 기반으로 설계되었습니다. 모델 아키텍처는 Mixture-of-Experts (MoE) 시스템을 채택한 트랜스포머 기반으로, 거대 모델의 성능을 발휘하면서도 소형 모델에 가까운 추론 비용을 유지합니다4. 기반 모델인 MiniMax M2는 총 2,300억 개의 파라미터를 가지지만, 이 중 한 번에 약 100억 개의 파라미터만 활성화됩니다4. M2.1은 23:1의 높은 희소성 비율을 가지며8, MiniMax M2는 각 추론 단계에서 전체 파라미터의 4.37%만 사용하여 Qwen3보다 2배 더 희소합니다4. 컨텍스트 윈도우는 약 200,000 토큰8, 204,800 토큰9, 또는 196,608 토큰10의 장기 컨텍스트를 지원합니다. 또한, M2는 FP8 정밀도 기반의 경량 추론 구조를 갖추고 있습니다11. MiniMax M2의 훈련 데이터에 대한 구체적인 정보는 공개되지 않았습니다4.
2. 이전 버전 대비 혁신적인 특징 및 개선점
MiniMax-M2.5는 M2 및 M2.1의 혁신적인 특징들을 계승하고 더욱 발전시켜, 특히 AI 에이전트 및 코딩 워크플로우에 특화된 개선을 이루었을 것으로 기대됩니다.
2.1 M2.1의 M2 대비 주요 개선점 MiniMax M2.1은 기존 M2 모델의 강점을 계승하면서 특히 실제 복합 작업 환경에서의 성능 향상과 더 많은 프로그래밍 언어 및 오피스 시나리오에서의 유용성에 중점을 두었습니다4.
- 탁월한 다국어 프로그래밍 능력: Rust, Java, Golang, C++, Kotlin, Objective-C, TypeScript, JavaScript 등 다양한 프로그래밍 언어에서 업계 최고 수준의 성능을 달성했습니다4.
- 웹 개발 및 앱 개발 능력 향상: 네이티브 Android 및 iOS 개발 기능이 크게 강화되었고, 복잡한 인터랙션, 3D 과학 장면 시뮬레이션, 고품질 시각화에서 뛰어난 성능을 보입니다4.
- 복합 명령어 제약 조건 처리 강화: 코드 실행 정확성뿐만 아니라 "복합 명령어 제약 조건"의 통합 실행을 강조하여 실제 오피스 시나리오에서의 유용성을 증대했습니다4.
- 더 간결하고 효율적인 응답: M2 대비 모델 응답 및 사고 체인이 더 간결해졌으며, 응답 속도 향상과 토큰 소모량 감소를 이루었습니다4.
- 뛰어난 에이전트/도구 스캐폴딩 일반화 능력: Claude Code, Droid 등 다양한 프로그래밍 도구 및 에이전트 프레임워크에서 일관되고 안정적인 성능을 발휘했습니다4.
- 고품질 대화 및 글쓰기: 일상 대화, 기술 문서, 글쓰기 시나리오에서도 더 상세하고 구조화된 응답을 제공합니다4.
- Interleaved Thinking 업그레이드: M2에서 도입된 체계적인 문제 해결 기능인 '인터리브드 씽킹'이 M2.1에서 더욱 업그레이드되었습니다4.
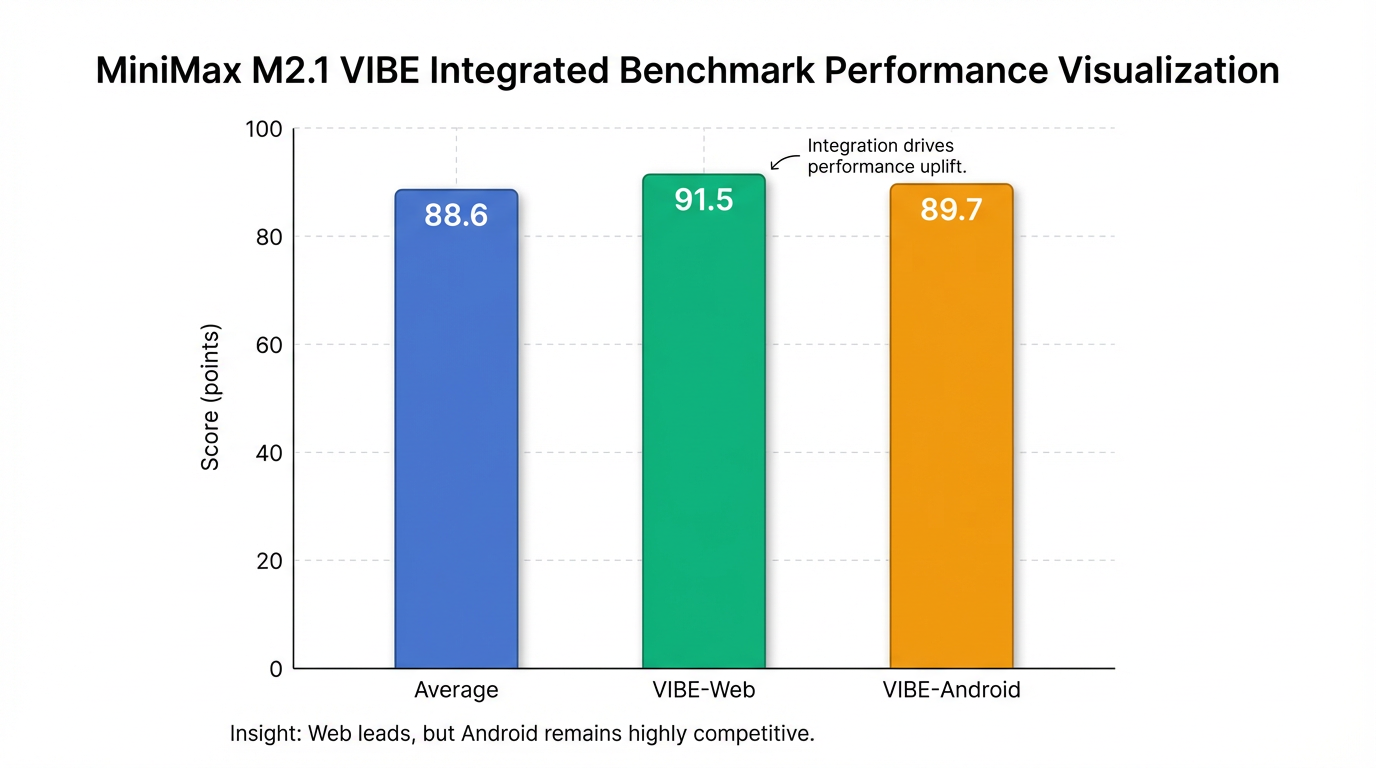
- 성능 벤치마크: MiniMax M2.1은 VIBE(Visual & Interactive Benchmark for Execution) 통합 벤치마크에서 평균 88.6점을 달성했으며, 특히 VIBE-Web (91.5점) 및 VIBE-Android (89.7점)에서 탁월한 성능을 보였습니다4.
2.2 혁신적인 측면 및 '모두를 위한 AI' 비전 MiniMax-M2.5는 MiniMax의 "모두를 위한 AI"라는 철학을 실현하며 다음과 같은 혁신적인 특징들을 통해 AI 기술의 적용 장벽을 낮춥니다.
- 최적화된 효율성: MiniMax M2는 MoE 아키텍처와 낮은 활성 파라미터(약 100억 개)를 통해 거대 모델급 성능을 저비용으로 제공합니다4. 이는 Claude 3.5 Sonnet 비용의 8%에 불과하며, 추론 속도는 약 두 배(초당 약 100 토큰) 빠릅니다4. API 가격은 오픈 모델 중 가장 저렴한 수준으로 평가받습니다11.
- 에이전트 기능 특화: M2는 AI 에이전트 및 코딩 워크플로우에 심층 최적화되어, 복잡한 에이전트 애플리케이션 구축을 위한 이상적인 기반을 제공합니다4. "생각하도록 설계되었다"는 철학은 에이전트가 복잡한 요청을 자율적으로 이해하고 계획을 세워 수행하는 능력을 강화하며, Interleaved Thinking은 일관된 추론 사슬 유지를 돕습니다12.
- 오픈소스 리더십 및 경제성: MiniMax M2는 Artificial Analysis 종합 지능 지수에서 오픈소스 모델 중 1위, 전체 톱5에 진입하며 구글 제미나이 2.5 프로를 능가하는 성능을 입증했습니다12. 또한, Hugging Face를 통해 모델 가중치가 오픈소스화되어, 소규모 팀이나 개인 개발자도 고급 AI 기술에 접근할 수 있게 하여 AI 민주화를 선도합니다4.
MiniMax는 이러한 기술적 성과와 글로벌 인지도를 바탕으로 2025년 Q1 홍콩 증시 IPO를 추진할 계획입니다12.
성능 및 활용 분야
MiniMax-M2.5는 에이전트 및 코딩 워크플로우에 최적화된 대규모 언어 모델(LLM)로, 효율성과 강력한 성능의 균형을 통해 AI 모델 경쟁에서 주목받고 있습니다 . 이 모델은 MiniMax-M2/M2.1의 후속 버전으로, 특히 코딩 성능과 에이전트 작업 처리 능력에 초점을 맞춰 개발되었습니다 14.
1. 기술 사양 및 아키텍처
MiniMax-M2.5는 정확한 사양이 명시되지 않았으나, MiniMax-M2/M2.1을 기반으로 볼 때, MoE(Mixture-of-Experts) 아키텍처를 채택하여 총 2,300억 개의 파라미터 중 한 번에 약 100억 개의 활성 파라미터만 사용합니다 . 이러한 설계는 모델이 거대 모델 수준의 성능을 발휘하면서도 작은 모델과 유사한 추론 비용과 낮은 지연 시간을 유지하도록 돕습니다 . 특히 M2.1의 경우, 각 추론 단계에서 전체 파라미터의 4.37%만을 사용하여 Qwen3보다 두 배 더 희소한 특성을 보입니다 4.

MiniMax 모델의 핵심 기술적 특징은 다음과 같습니다:
- 활성 파라미터 최적화: 2,300억 개 파라미터 중 100억 개만 선택적으로 활성화하여 비용 효율성과 속도를 극대화합니다 .
- 초장문 컨텍스트 윈도우: MiniMax-M2는 최대 204,000 토큰(약 15만 단어)의 컨텍스트를 처리할 수 있어, 전체 코드베이스나 문서를 이해하는 데 충분한 수준을 제공합니다 15. 다만, MiniMax-M2.5는 OpenCode 벤치마크에서 64K 토큰의 컨텍스트를 사용했습니다 14.
- 인터리브드 사고(Interleaved Thinking) 형식: 모델이 추론 과정에서
...태그 안에 내부 사고 과정을 캡슐화하여 출력합니다. 이는 모델의 투명성과 추적성을 높이고, 다단계 추론에서 컨텍스트를 유지하는 데 기여합니다 . 이 '사고' 토큰을 대화 기록에서 유지하는 것이 성능 보존에 필수적입니다 .
2. 벤치마크 결과 및 경쟁 모델과의 비교
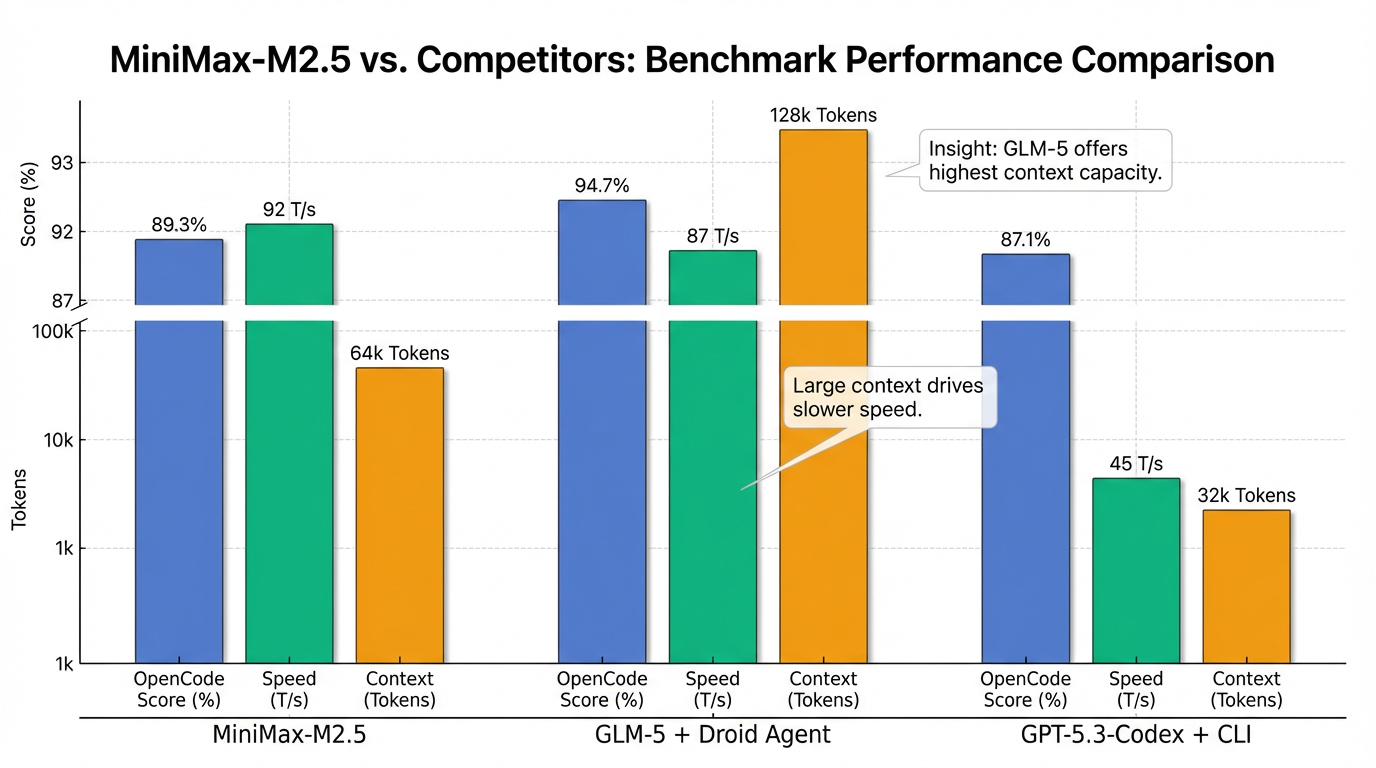
MiniMax-M2.5는 OpenCode 벤치마크에서 89.3%의 점수를 기록했으며, 초당 92 토큰의 속도를 보였습니다 14. 이는 GPT-5.3-Codex (87.1%, 45 토큰/초)나 GLM-4.7 + Droid (82.4%, 78 토큰/초)보다 높은 성능을 의미합니다 14. 그러나 GLM-5 + Droid Agent (94.7%, 87 토큰/초)에는 5.4% 뒤처지는 결과를 보였습니다 14. MiniMax-M2.5의 OpenCode 점수는 CLI 에이전트와 함께 측정되었습니다 14.
이전 버전인 MiniMax-M2는 Artificial Analysis의 Intelligence Index에서 61점을 기록하며 오픈소스 모델 중 1위를 차지했으며, 이는 Claude Opus 4.1(59점)과 Qwen 3 72B(58점)를 능가하는 결과입니다 . 비용 측면에서는 MiniMax-M2가 Claude Sonnet 대비 약 8% 수준의 비용으로 2배 빠른 추론 속도를 제공하여 높은 효율성을 자랑합니다 .
3. 주요 활용 분야 및 강점
MiniMax-M2.5는 특히 다음과 같은 분야에서 뛰어난 성능을 보입니다:
- 코딩 및 소프트웨어 엔지니어링: 다중 파일 편집, 코드-실행-수정 루프, 테스트 검증된 코드 수정 등 엔드투엔드 개발자 워크플로우에 최적화되어 있습니다 . Rust, Java, Golang, C++, Kotlin, Objective-C, TypeScript, JavaScript 등 다양한 언어를 지원하는 뛰어난 다국어 프로그래밍 능력을 갖추고 있습니다 4. LiveCodeBench에서 GPT-5에 버금가는 성능을 보여 복잡한 문제에 대한 정확한 코드 생성이 가능하며 15, 웹 및 앱 개발 능력(네이티브 Android/iOS 개발, 3D 인터랙티브 애니메이션, 웹 UI 디자인)에서도 강점을 가집니다 4.
- 에이전트 워크플로우: 복잡하고 장기적인 도구 체인(셸, 브라우저, 검색, 코드 실행)을 계획하고 실행하는 데 탁월하며, 오류 복구 및 증거 추적성 유지가 가능합니다 . '인터리브드 사고'를 통해 모델의 투명한 추론 과정을 제공하고, 이를 통해 다단계 문제 해결 능력을 향상시킵니다 . 또한, 전략적 계획, 자기 교정, 간격 감지, 적응적 행동과 같은 고급 에이전트 기능을 지원합니다 16.
- 효율성 및 비용 효과: MoE 아키텍처와 희소 활성화를 통해 낮은 지연 시간, 적은 컴퓨팅 비용, 높은 처리량을 제공합니다 . M2 모델은 4개의 H100 GPU에서도 FP8 정밀도로 효율적인 배포가 가능하여 많은 조직에 기술 접근성을 높입니다 .
- 다국어 능력: M2.1은 다국어 시나리오에서 상당한 성능 향상을 보였으며, 이는 번역 시 문화적 맥락과 관용적 표현을 더 잘 유지하는 데 기여합니다 .
4. 초기 사용자 및 전문가의 평가
MiniMax-M2는 "효율성을 위한 혁신", "작지만 최대 효과"라는 평가를 받으며, 'AI계의 샤오미'로 불리기도 합니다 17. 전문가들은 M2가 단순히 벤치마크 점수를 위한 모델이 아니라 실제 업무 현장의 문제를 해결하기 위해 만들어진 실용적인 모델이라고 평가합니다 5. 개발자 커뮤니티에서는 M2가 수학 문제 해결 시 스스로 오류를 발견하고 수정하는 사고 과정을 보여주었으며, 전체 프로젝트를 이해하고 다루는 능력이 뛰어나다고 언급됩니다 5. MiniMax 팀 또한 M2를 활용하여 온라인 데이터 분석, 기술 이슈 조사, 프로그래밍, 사용자 피드백 처리, 채용 이력서 스크리닝 등 다양한 내부 에이전트를 구축했다고 밝혔습니다 5.
MiniMax-M2.5에 대해서는 "빠르고 배포하기 쉬운 MoE 모델"로, 다단계 에이전트, 코드 생성 및 복구, 터미널/IDE 워크플로우, 도구 호출을 위해 설계되었으며, 낮은 대기 시간과 비용 효율적인 추론 능력을 우선시한다고 평가됩니다 9. M2.5는 특정 코딩 작업에 특화되어 빠르고 효율적이라는 평가를 받았지만, 비표준적이거나 레거시 코드와 같은 복잡한 작업에서는 "너무 예측 가능"하여 약점을 보이기도 합니다 14. 특히 Python의 복잡한 데코레이터나 메타클래스 처리에서는 GLM-5보다 유연성이 떨어진다는 지적이 있습니다 14.
5. 한계점
MiniMax 모델의 주요 한계점으로는 높은 상세도(verbosity)로 인한 높은 토큰 사용량이 지적됩니다 . 이는 낮은 토큰당 가격에도 불구하고 실제 운영 비용을 증가시킬 수 있습니다 18. 또한, 현재로서는 텍스트 전용 모델로 멀티모달(이미지 생성, 오디오 처리 등) 기능은 지원하지 않습니다 . 특정 유형의 심층 추론, 복잡한 수학 증명, 미묘한 철학적 논증, 창의적 글쓰기 등에서는 최상위 모델에 비해 약점을 보일 수 있습니다 18. MiniMax-M2.5의 경우, 12GB 메모리 GPU에서 실행 가능하지만 14, M2의 완전한 로컬 배포는 4x H100 GPU와 같은 상당한 하드웨어 요구 사항을 가질 수 있습니다 18.
종합적으로 MiniMax-M2.5는 탁월한 효율성과 에이전트 및 코딩 작업에 특화된 강력한 성능을 제공하여, 비용 효율적인 AI 솔루션을 찾는 개발자와 기업에게 매력적인 선택지가 될 것으로 보입니다 .
시장 영향 및 향후 전망
MiniMax는 2021년 중국 상하이에 설립된 이래, 2024년 3월 6억 달러 투자 유치와 2026년 1월 홍콩 증시 상장을 통해 빠르게 성장하며 AI 시장의 주요 플레이어로 부상했습니다 19. "모두를 위한 AI" 비전 아래 고성능이면서도 비용 효율적인 AI 모델을 제공하며 AI 기술 접근성의 장벽을 낮추는 것을 목표로 합니다 4. 특히, MiniMax-M2는 Artificial Analysis Intelligence Index에서 61점을 기록하며 모든 오픈소스 AI 모델 중 1위, 전체 LLM 중 글로벌 5위에 오르는 인상적인 성과를 보여주었습니다 21. 이는 Google DeepMind의 Gemini 2.5 Pro(60점)를 앞선 결과이며 20, OpenAI의 GPT-5와 같은 선두 모델들과 어깨를 나란히 하여 비용 효율적인 중국 오픈소스 AI 진영의 기술적 진보를 입증했습니다 20. MiniMax-M2.5는 이러한 발전의 최신 단계로, 글로벌 AI 산업의 경쟁 구도에 새로운 동력을 제공하고 있습니다.
MiniMax-M2.5 모델군은 경쟁이 치열한 AI 시장에서 코딩 및 에이전트 작업에 특화된 강력한 가치 제안을 통해 차별점을 부각합니다 18. MiniMax-M2는 SWE-bench Verified에서 69.4점, Terminal-Bench에서 46.3점, BrowseComp에서 44점을 기록하며 코딩 및 에이전트 작업에서 Claude Sonnet 4.5 및 GPT-5와 경쟁하거나 특정 영역에서는 능가하는 성능을 보였습니다 4. 특히 BrowseComp 벤치마크에서는 Claude 모델보다 훨씬 우수했습니다 18. GPT-5가 기능의 폭과 일관성에서 선두를 유지하지만 18, MiniMax는 저렴한 비용으로 유사한 성능을 제공하는 대안이 됩니다 18. 또한, Gemini 2.5 Pro는 멀티모달 기능에서 강점을 가지는 반면 18, MiniMax는 텍스트 전용 워크플로에서 더 나은 효율성과 지능 벤치마크에서의 우위를 제공합니다 18.
모델군의 핵심 차별점은 다음과 같습니다. MiniMax-M2.5는 총 2,300억 개의 파라미터 중 추론 시 약 100억 개의 파라미터만 활성화되는 효율적인 MoE(Mixture of Experts) 아키텍처를 채택했습니다 9. 이는 경쟁 모델 대비 적은 활성 파라미터 수입니다 18. 이 아키텍처 덕분에 낮은 지연 시간을 유지하면서도 뛰어난 성능을 제공하며 6, 4대의 NVIDIA H100 GPU에서도 구동 가능하여 효율적인 배포가 가능합니다 4. 추론 속도는 초당 약 100 토큰으로 Claude Sonnet 4.5 대비 약 두 배 빠릅니다 4. 특히, 코딩, 다단계 에이전트 워크플로, 도구 호출에 명시적으로 설계되어 있으며 9, '코드-실행-테스트-수정'의 완전한 사이클을 지원합니다 6. "Interleaved Thinking" 기능으로 내부 추론 과정을 투명하게 보여주며 9, 다국어 번역 시 문화적 맥락을 유지하는 강점도 있습니다 18.
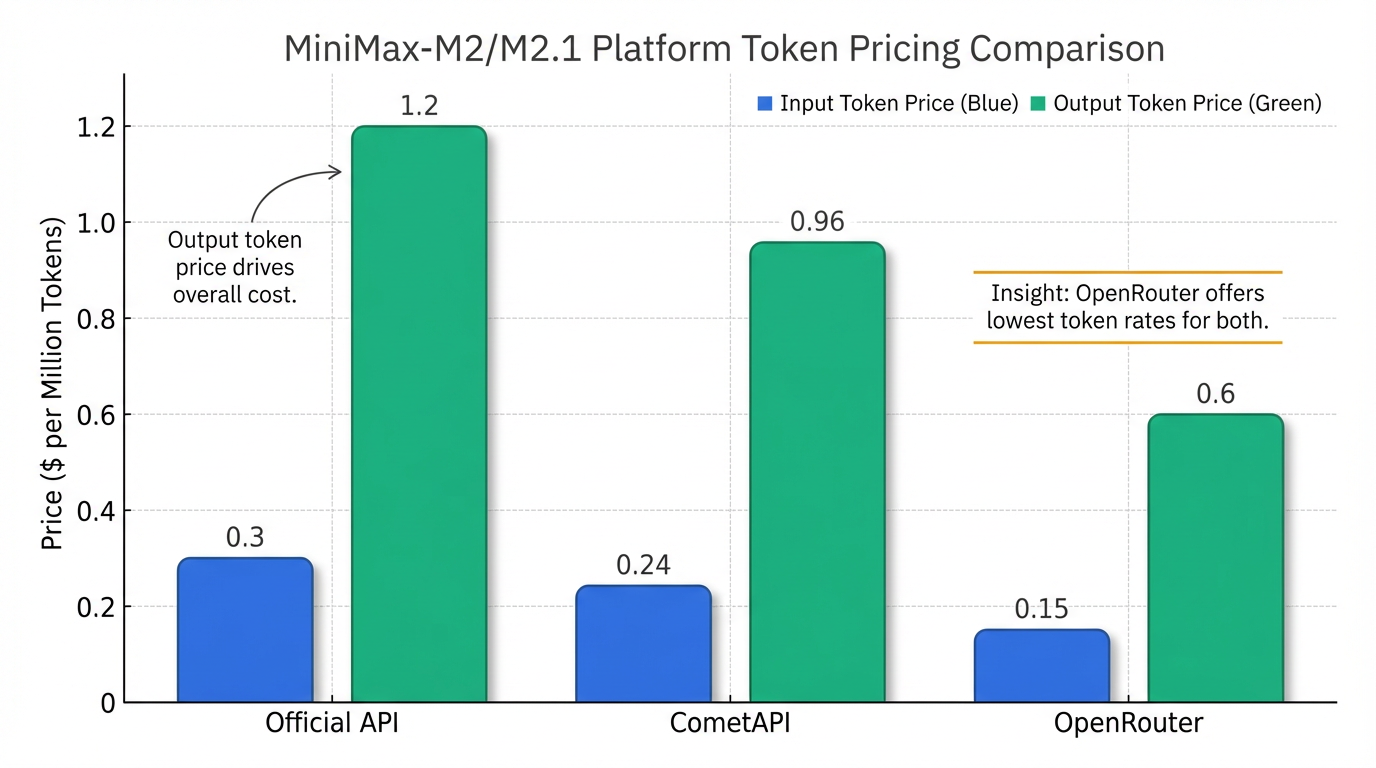
가격 정책 또한 MiniMax-M2.5의 중요한 강점입니다. MiniMax-M2/M2.1의 공식 API 가격은 백만 입력 토큰당 $0.30–$0.315, 백만 출력 토큰당 $1.20–$1.26으로 책정되었으며 6, CometAPI를 통하면 공식 가격 대비 20% 할인된 가격으로 이용 가능합니다 9. 이는 Anthropic Claude Sonnet 4.5 비용의 약 8% 수준이며 9, GPT-4 Turbo보다 훨씬 저렴하여 24 특히 아시아 사용자에게 비용 효율적인 선택지가 됩니다 24. 2026년 2월 11일 "해외 에이전트 웹사이트"를 통해 MiniMax-M2.5가 출시되었다고 보고되었으며 1, OpenRouter와 같은 플랫폼을 통해 전 세계 개발자들에게 접근성을 제공합니다 24.
향후 전망에 대해 전문가들은 2025년 AI 시장이 단일 최고 모델보다는 기능별 특화 모델 스택을 구축하는 경향을 보였으며 25, MiniMax-M2.5는 코딩 및 에이전트 워크플로에 집중하여 이러한 시장 트렌드에 부합한다고 평가합니다 9. MiniMax를 포함한 중국 AI 모델들은 뛰어난 가성비와 기술적 진보로 글로벌 AI 경쟁 구도에 중요한 동력을 제공하며 21, 2026년 2분기까지 선두 모델들과의 성능 격차가 더욱 줄어들거나 동등해질 것으로 예상됩니다 21. AI 활용이 가속화되는 기업 환경에서 MiniMax-M2.5와 같이 코딩 및 에이전트 작업에 특화된 모델의 실용성은 계속해서 주목받을 것이며 20, OpenRouter와 같은 플랫폼을 통한 쉬운 접근성은 개발자들이 최첨단 AI 기술을 비용 효율적으로 실험하고 통합하는 데 기여할 것입니다 24.
그러나 MiniMax-M2.5가 직면할 도전 과제도 존재합니다. MiniMax M2는 텍스트 전용 모델로, 멀티모달 기능(이미지/오디오 처리)이 없다는 한계가 있습니다 9. 또한, Intelligence Index 평가에 1.2억 토큰을 사용하는 등 '장황함(verbose)'이라는 단점이 있어 18, 낮은 per-token 가격에도 불구하고 실제 운영 비용이 예상보다 높아질 수 있습니다 18. 이는 지연 시간, 메모리 사용량, 사용자 경험에도 영향을 미칠 수 있으므로 18, 효과적인 프롬프트 엔지니어링이나 후처리 과정을 통해 관리해야 할 중요한 과제입니다 9. 그럼에도 불구하고, MiniMax-M2.1은 "광범위한 소프트웨어 개발 작업에서 최전선 성능을 제공하는 강력한 오픈소스 모델"이자 "현재 가장 균형 잡힌 오픈 모델"로 평가되며 4, MiniMax-M2.5 역시 이러한 가능성을 기반으로 지속적인 발전을 이룰 것으로 전망됩니다.