MiniMax-M2.5 重磅发布:探索其核心技术与应用前景
引言:MiniMax-M2.5 模型横空出世,引发业界广泛关注
2026年2月,人工智能领域迎来了一项重磅发布——MiniMax-M2.5模型正式亮相,迅速引爆了业界内外的高度关注。MiniMax-M2.5模型于2026年2月11日正式上线其Agent平台,并在次日,即2月12日,受到了IT之家、TechWeb和每日经济新闻等众多科技媒体的广泛报道,将其誉为MiniMax的最新旗舰编程模型。
此次发布距离其上一代M2.2版本仅一个多月,充分展现了MiniMax惊人的迭代速度。它与智谱AI的GLM-5等同期发布的模型共同构成了2026年春节期间AI模型发布的热潮,预示着人工智能技术竞赛的白热化。
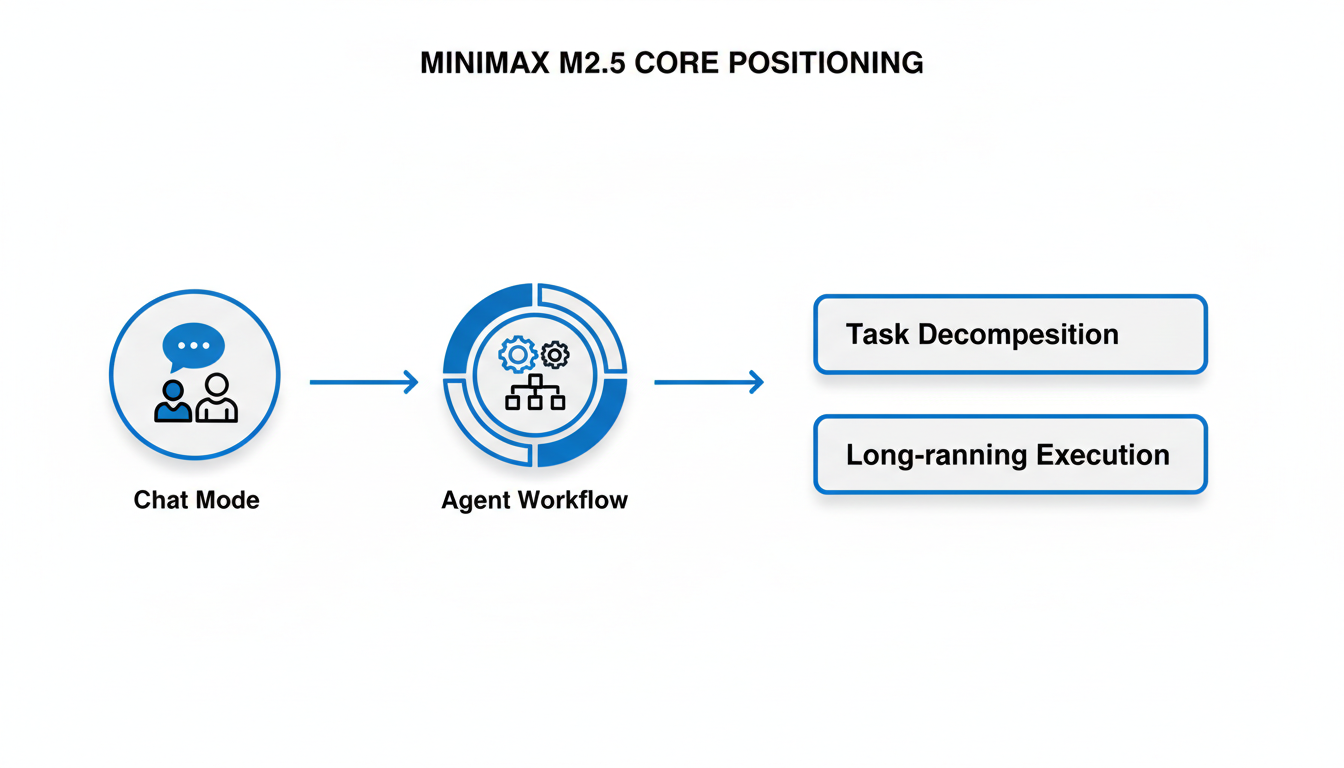
MiniMax官方对M2.5模型有着清晰且宏大的定位,将其定义为“全球首个为Agent场景原生设计的生产级模型”。这一前瞻性设计旨在推动AI应用从传统的简单聊天模式,向更高级的Agent式工作流程演进1,专注于复杂的任务分解和长时间运行的执行,以满足未来AI在自动化和智能化领域的深层需求1。这一开创性的定位,无疑为M2.5模型在竞争激烈的AI市场中树立了独特的里程碑。
核心特性与技术突破:MiniMax-M2.5 在哪些方面实现创新?
MiniMax-M2.5 模型作为 MiniMax 公司最新的旗舰编程模型,在架构设计、核心技术、数据策略以及功能表现上均实现了显著创新与突破,尤其强调其原生Agent设计理念和独特的“交错思维”机制。
模型架构与设计理念
MiniMax-M2.5 在模型架构上展现出领先的设计理念,旨在平衡强大性能与计算效率:
- 高效能激活参数量:M2.5 的激活参数量仅为 100亿 (10B) 。这一设计使其在实现卓越性能的同时,显著优化了显存占用和推理能效比 。
- 原生Agent设计:模型采用先进的设计理念,原生为智能体(Agent)交互场景进行优化,能够更好地理解并处理复杂的任务流程 2。
- 稀疏混合专家 (MoE) 架构:MiniMax 家族(如 M2、M2.1)广泛采用稀疏混合专家(MoE)架构 。M2 的总参数量高达 2300亿 (230B),但在推理时仅激活 100亿 (10B) 参数 。这种“大储备+小激活”的设计策略使得模型在保证高性能的同时,实现了出色的计算效率 3。M2.5 预期将继承并优化这一高效架构。
核心技术模块
MiniMax-M2.5 集成了多项核心技术模块,以确保其在复杂任务处理中的稳定性和可靠性:
- 交错思维 (Interleaved Thinking):这是 MiniMax M2 的核心创新技术,并预计在 M2.5 中得到沿用 4。该技术将推理过程无缝融入工具调用的每个环节,形成一个“思考 → 行动 → 反思”的动态循环 4。它从根本上解决了长链路任务中常见的“状态漂移”问题,显著提升了 Agent 的规划、自我纠正能力以及长期工作流的可靠性,确保计划、意图和中间结论在多轮次交互中持续保持连贯性 4。
- 稳健的 Attention 机制选择:在注意力机制的选择上,MiniMax M2 团队优先考量稳定性与可靠性,最终回归并使用了更传统的 Full Attention (全注意力) 机制 。尽管一些高效注意力机制在小任务上表现尚可,但在上下文长度增加时性能衰减显著,且实际表现不如 Full Attention 。M2.5 很可能延续这一经过验证的工程实践。
训练数据策略
MiniMax-M2.5 在训练数据方面,沿袭并发展了 M2 模型成熟的策略,旨在提升模型的泛化能力和鲁棒性:
- 数据质量精细衡量:MiniMax 团队将数据质量的衡量标准细化为思维链(CoT)和响应(Response)两个关键维度,要求数据逻辑完整、表述简洁明确 。
- 数据多样性注入:在数据合成过程中,MiniMax 刻意引入格式多样性,以避免模型过度拟合特定基准测试格式,确保其在各种复杂环境中都能具备强大的泛化能力 。
- 广泛的任务覆盖:模型训练数据尽可能广泛地涵盖不同领域的任务,以增强模型对多样化场景的适应性 。
- 高效数据清洗流程:通过基于规则判断与大模型辅助判断相结合的数据清洗流程,MiniMax 有效整理并剔除了导致模型产生幻觉或指令未遵循等问题的“坏数据” 。
- 全轨迹泛化数据链路:M2 团队设计了一整套覆盖全轨迹扰动的数据链路,用于全面提升 Agent 的泛化能力 5。该链路模拟了真实使用场景中可能出现的各种情况,包括工具变化、系统提示语调整、环境参数变化、用户反复提问以及工具返回异常等,从而大幅提升了模型在各种复杂和不确定情境下的稳定表现 5。
显著功能提升与技术突破
MiniMax-M2.5 在功能性方面实现了显著提升,并在多项技术指标上达到业界领先水平:
- 编程与智能体性能对标国际顶尖模型:MiniMax-M2.5 在编程与智能体性能方面直接对标国际顶尖模型 Claude Opus 4.6 。有内测用户反馈其能力与 Opus 4.6 “打的有来有回” 6。
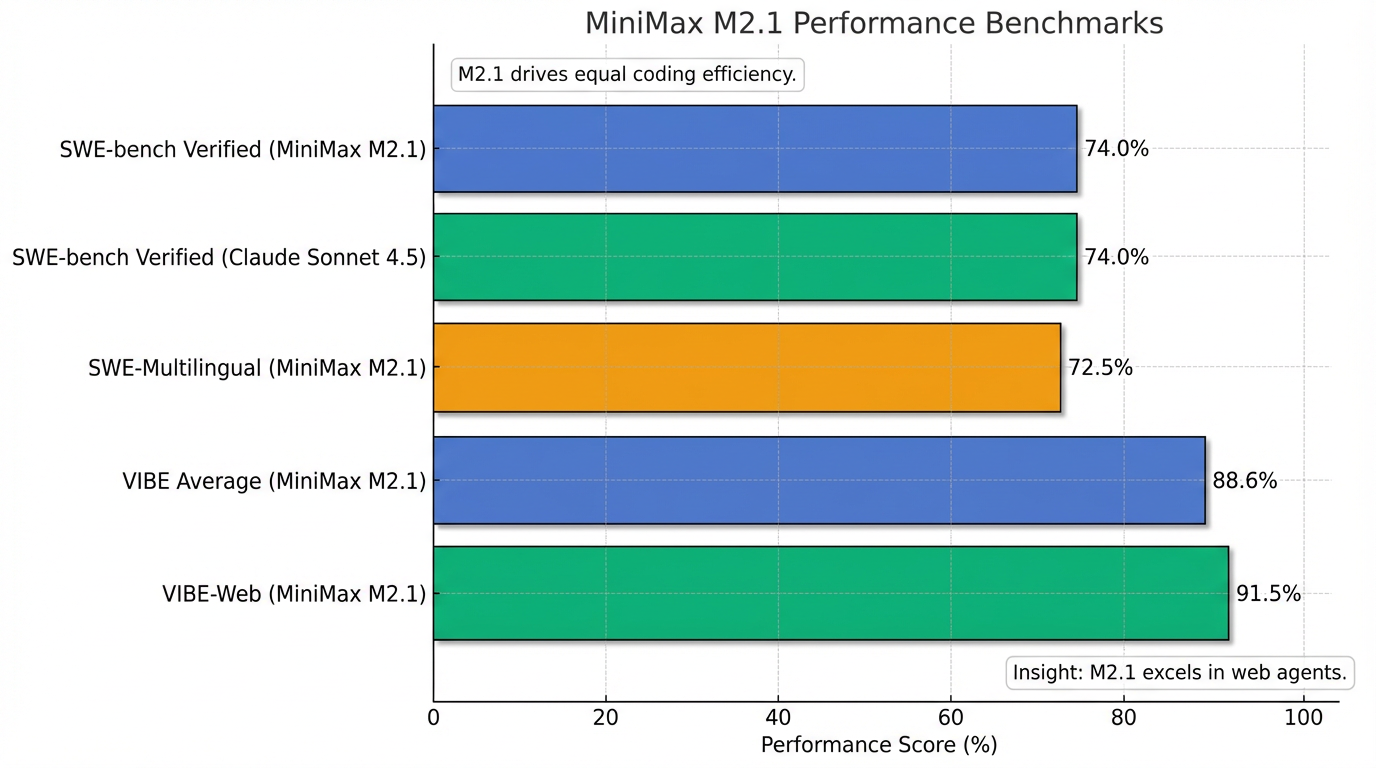
- 超越前代及竞品:M2.1 在 SWE-bench Verified 测试中取得了 74.0% 的准确率,与 Claude Sonnet 4.5 性能持平 。在 SWE-Multilingual 任务上,M2.1 达到 72.5% 的成绩,在 Rust、Go、Java 等非 Python 语言编程能力上超越了诸多竞品 7。此外,M2.1 在 VIBE 全端开发基准测试中平均得分 88.6%,其中 VIBE-Web 得分高达 91.5% 。
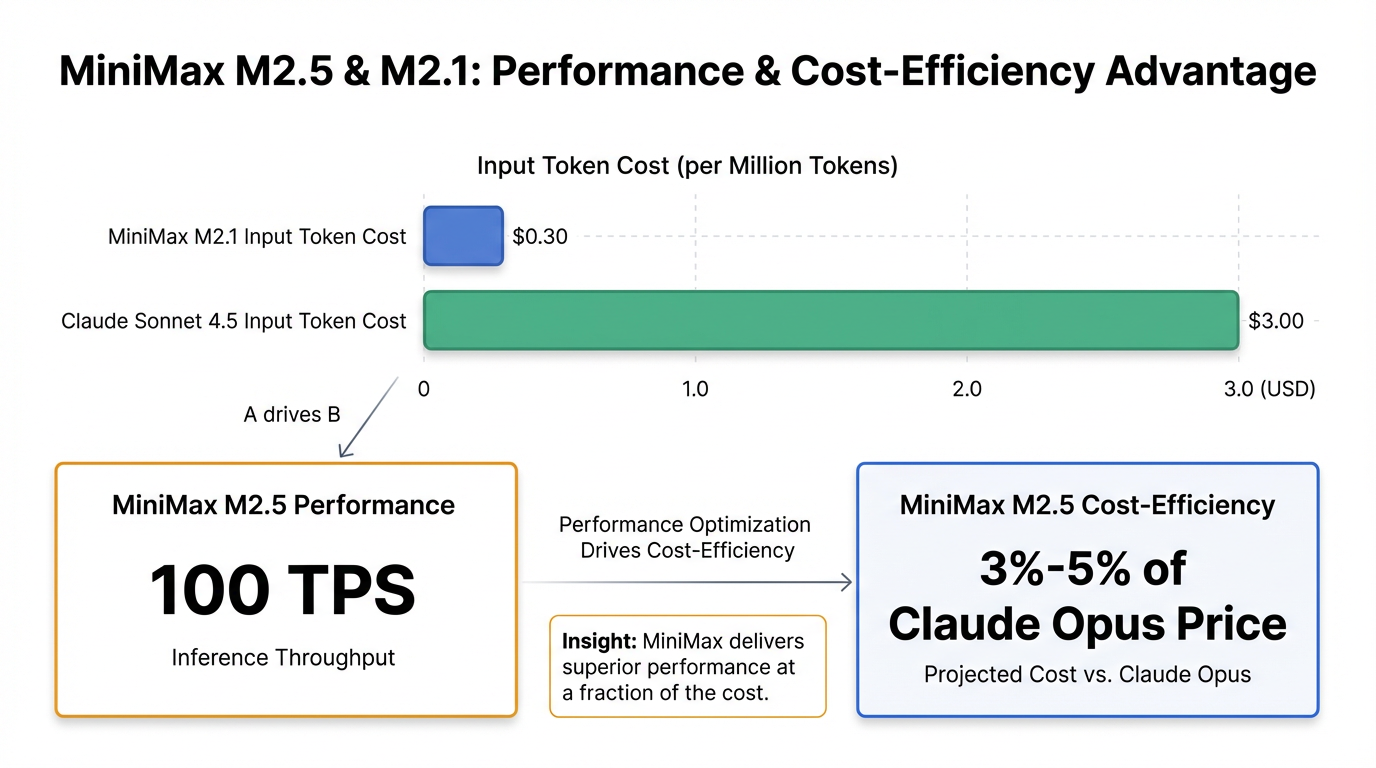
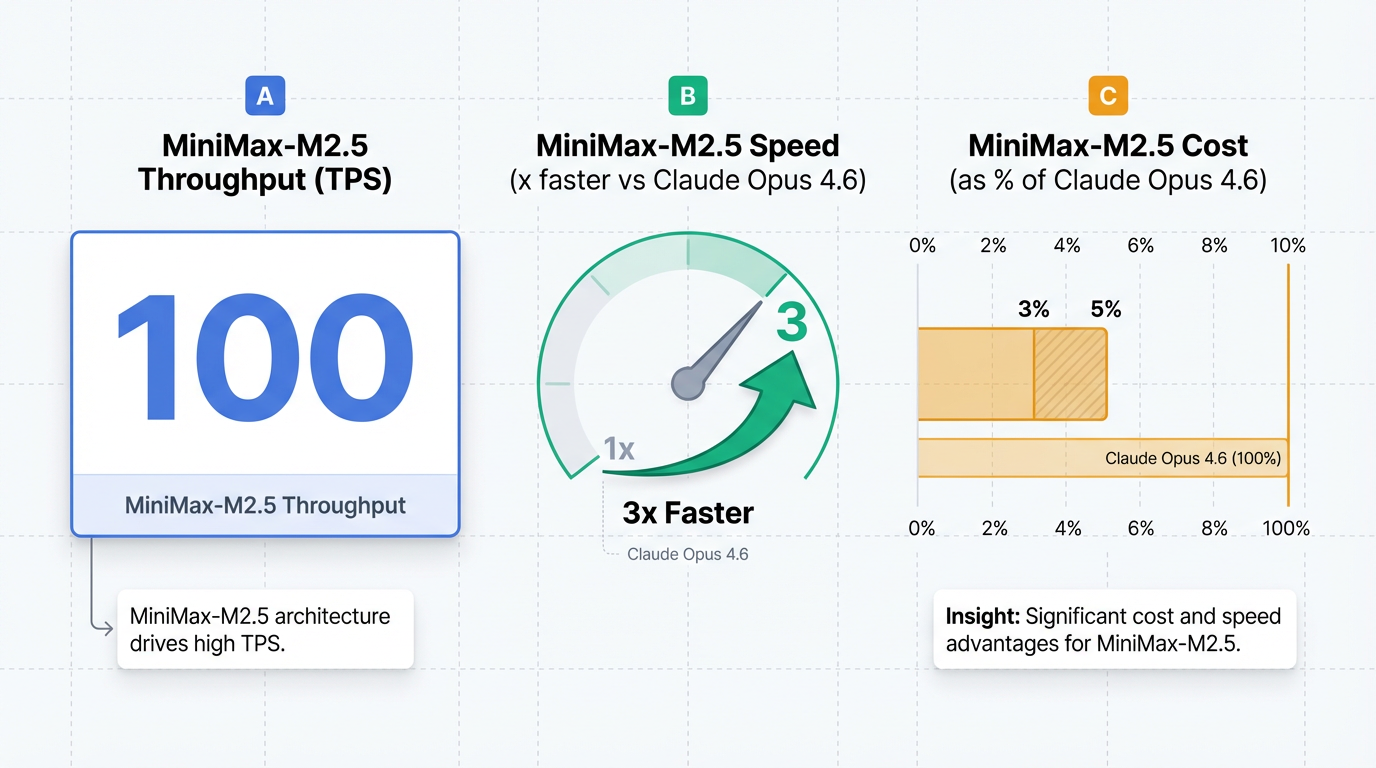
- 效率与成本优势:MiniMax-M2.5 支持 100 TPS (每秒事务处理量) 的超高吞吐量,其推理速度优于现有国际顶尖模型 ,实测响应速度实现了翻倍提升 8。在成本方面,M2.1 每百万输入 Token 成本仅为 0.30 美元,比 Claude Sonnet 4.5 的 3.00 美元/百万 Token 节省了 90% 。据称,M2.5 的价格预计仅为 Claude Opus 系列的 3%-5%(待官方确认) 6。
- 模型体积优化:M2.5 仅 100亿 (10B) 的激活参数量,使其在显存占用和推理能效比方面表现出色 ,实现了高性能与资源消耗的优异平衡。
- 更接近原生思维直觉:通过将“交错思维”深度融入模型的推理流程,M2.5 的思考-行动模式比早期依赖 Prompt 工程的 ReAct 框架更为稳健,更能体现自然的思维直觉 4。
性能表现与应用前景:M2.5 的实际能力如何?将在哪些领域发挥作用?
MiniMax-M2.5 作为 MiniMax 公司的最新旗舰模型,其性能表现和应用前景备受瞩目。在编程与智能体(Agent)性能方面,M2.5 直接对标国际顶尖模型 Claude Opus 4.6 2,被评为“真正的SOTA模型”,能力可与 Opus 4.6 匹敌 6,甚至被誉为“国产编程王者” 9。
性能数据显示,其前身 M2.1 在 SWE-bench Verified 上取得了 74.0% 的准确率,与 Claude Sonnet 4.5 性能持平 7。在 SWE-Multilingual 任务中,M2.1 的准确率达到 72.5%,尤其在 Rust、Go、Java 等非 Python 语言方面超越了竞品 7。此外,M2.1 在 VIBE 全端开发基准测试中平均得分高达 88.6%,其中 VIBE-Web 更是达到 91.5% 7。
MiniMax-M2.5 作为全球首个为 Agent 场景原生设计的生产级模型 2,强调其能够更好地理解和处理复杂任务 2。其核心的“交错思维 (Interleaved Thinking)”技术,使得 M2.5 在 Agent 执行过程中能够形成“思考 → 行动 → 反思”的动态循环 4。这显著提升了 Agent 的规划、自我纠正和处理长链路任务的可靠性 4,有效避免了逻辑中断和“状态漂移”问题,确保计划、意图和中间结论能够跨轮次延续 4。MiniMax-M2.5 的定位体现了向“Agentic Engineering”发展的趋势,表明其具备处理复杂、多步骤系统工程任务的能力 9。它能够出色规划并稳定执行复杂的工具链任务,协同调用 Shell、浏览器、Python 代码执行器和各种 MCP 工具 10,在处理复杂逻辑指令、长代码生成以及执行准确性上取得了显著突破 8。
在实际应用中,MiniMax-M2.5 在 Excel 高阶处理、深度调研、PPT 制作等 Office 核心生产力场景中均达到了行业领先 (SOTA) 水平 2。同时,它还支持 PC、App 及跨端应用的全栈编程开发 2。
在效率与成本方面,MiniMax-M2.5 展现出显著优势。它支持 100 TPS 的超高推理吞吐量,推理速度优于现有国际顶尖模型,实测响应速度实现了翻倍提升 。M2.1 的每百万输入 Token 成本仅为 0.30 美元,相较于 Claude Sonnet 4.5 (3.00 美元/百万 Token) 降低了 90% 7。据内部消息,M2.5 的价格预计仅为 Opus 系列的 3%-5% 6。
市场反响与专家评价:业界对 MiniMax-M2.5 的看法如何?
MiniMax-M2.5自2026年2月11日/12日发布以来,立即受到了媒体、技术专家和用户的广泛关注。业界普遍认为其在编程和智能体(Agent)能力方面具有显著优势,但同时也伴随着对实测数据和成本效益的深入讨论 。
媒体广泛关注与市场热烈反响
媒体普遍报道MiniMax-M2.5是MiniMax最新旗舰编程模型,并被定位为全球首个为Agent场景原生设计的生产级模型 11。报道强调其编程与智能体性能可与国际顶尖模型比肩,直接对标Anthropic的Claude Opus 4.6 11。在技术参数方面,M2.5模型激活参数量仅为10B,却在显存占用和推理能效比上具有明显优势,支持100 TPS(每秒事务处理量)的超高吞吐量,推理速度甚至达到Claude Opus 4.6的3倍 12。M2.5于2026年2月11日正式上线其Agent平台,距离上一代M2.2发布仅一个多月,展现了MiniMax快速的迭代周期和技术创新能力 1。
在应用场景上,M2.5支持PC、App及跨端应用的全栈编程开发,尤其在Excel高阶处理、深度调研、PPT等Office核心生产力场景中处于行业领先(SOTA)地位 12。市场对M2.5的认可度极高,发布当天MiniMax股价在港股盘中涨幅一度超过20%,总市值突破1800亿港元,充分反映了市场对其新模型的高度期待 12。媒体还指出,MiniMax M2.5与同期发布的DeepSeek新模型、智谱GLM-5等共同构成了中国大模型领域的“春节发布季”,标志着国产模型正从“价格战”转向以编程与智能体为核心的技术竞速 11。
技术专家与社区的高度评价
技术专家和社区对MiniMax-M2.5的评价普遍积极。许多评论将其誉为“国产最强编程模型” 9,有用户内测反馈M2.5是真正的SOTA模型,能力提升巨大,在编程与智能体性能上与Claude Opus 4.6“打得有来有回” 6。实测结果显示,M2.5在处理复杂逻辑指令、长代码生成及执行准确性上取得显著突破,其工程化落地能力令人意外 8。此外,M2.5还专注于任务分解和长时间运行执行,进一步提升了其在复杂任务中的表现 1。
在效率与成本方面,M2.5被认为是同性能级别AI编程模型中的“价格标杆” 13,据说其使用成本仅为Claude Opus的3%-5% 6。为了保障模型训练的稳定性和效率,M2.5采用了Agent RL算法和CISPO算法 13。
在架构选择上,MiniMax团队解释了M2系列(包括M2.5)采用Full Attention而非更高效的Linear Attention的原因:尽管Full Attention计算开销较大,但在复杂任务(如长链推理、跨工具操作)中能提供更可靠、更稳定的表现,这是出于工程稳定性和可用性的优先考量 14。值得关注的是,M2.5还采用了“交错式思维链”(Interleaved Thinking)策略,通过在思考与行动间交替循环,显著提升了模型在长链任务中的容错率和泛化能力 14。
用户使用反馈与潜在改进空间
用户使用反馈进一步验证了M2.5在编程和Agent场景的卓越能力。有内测用户在获得无限token的情况下,成功将Go语言编写的微服务转换为Rust语言,生成了3万行代码,并获得Rust专家“像模像样”的积极评价 9。早期测试还表明,M2.5能够完美生成包含动态规划表、自动播放动画及交互控制的完整HTML代码,响应速度实现翻倍提升 8。内测用户Austin也表示,M2.5在实际项目和OpenClaw测试中,用于编程和智能体开发“完全无问题” 6。
然而,用户反馈中也存在一些争议点和改进空间。有开发者在对比测试MiniMax M2(可能指M2.5的前代或系列模型)与Claude 4.5时发现,在处理核心或疑难代码问题上,MiniMax M2的能力仍与Claude 4.5存在一定差距 15。在特定集成环境下,MiniMax M2可能无法临时中断任务,必须等待单一任务完成后才能接受新输入,有时会导致代码“祸祸”的风险 15。该开发者甚至戏称模型在某些情境下的行为如同“实习生且性格是犟种”,建议M2.5在核心业务代码上的使用仍需谨慎 15。此外,目前官方渠道对M2.5的具体技术特性、性能基准测试结果和API定价信息披露相对有限,DataLearnerAI等平台指出当前尚无可展示的评测数据 16。对于M2.1的评测也显示,虽然准确率有所提升,但响应时间几乎翻倍,成本增加了约21.6%,且在“语言与指令遵从”方面有所下降 17。在与其他开源模型对比中,M2.1在准确率上仍有差距 17。
MiniMax-M2.5的发布标志着国产大模型在编程和Agent领域的进一步突破,其技术创新和成本优势受到肯定,但在实际生产环境中的全面表现和官方信息透明度仍需进一步观察和验证。
结论与展望:总结 MiniMax-M2.5 的意义及对未来的影响
MiniMax-M2.5的发布,标志着中国大模型技术在编程和智能体(Agent)领域取得了里程碑式的突破 1。作为MiniMax于2026年2月11日或12日正式发布的最新旗舰编程模型 ,M2.5凭借其卓越的技术创新、领先的性能表现以及积极的市场反响,重新定义了AI Agent的生产力标准。
技术创新与性能突破
MiniMax-M2.5被官方定义为“全球首个为Agent场景原生设计的生产级模型” ,致力于从简单的聊天模式向Agent式工作流程演进,专注于任务分解和长时间运行的执行 1。其核心优势在于编程与智能体能力(Coding & Agentic)的显著提升,支持PC、App及跨端应用的全栈编程开发 。在性能方面,M2.5直接对标国际顶尖模型Claude Opus 4.6 ,并在Excel高阶处理、深度调研、PPT制作等Office核心生产力场景中处于行业领先地位 。
MiniMax-M2.5通过仅100亿(10B)的激活参数量 ,显著降低了显存占用,实现了100 TPS(Tokens Per Second)的超高吞吐量,推理速度甚至超越了部分国际顶尖模型 。其所采用的“交错思维”(Interleaved Thinking)技术 4,使得模型能在执行长链路任务时高效自我修正、动态规划与样本复用,有效避免了逻辑中断和“状态漂移”问题 4。同时,MiniMax团队对Full Attention机制的坚持 18,也反映出其对工程稳定性和可靠性的优先考量 18。
对AI Agent领域的深远影响
MiniMax-M2.5作为专为Agent场景原生设计的模型,对AI Agent领域具有划时代的意义。它不仅在技术层面实现了复杂逻辑指令、长代码生成及执行准确性的显著突破 8,更推动了国产大模型从单一的任务执行向更复杂的系统工程(Agentic Engineering)方向发展 9。其强大的工具调用与协同能力 10,以及多文件处理能力 7,预示着未来AI将能更自主、更可靠地完成复杂工作流。这无疑将加速AI Agent在企业级应用中的落地,有效提升各行各业的生产力,解决传统工作效率痛点 2。
市场反响与未来展望
MiniMax-M2.5的发布在市场引起了强烈反响。发布当天,MiniMax的股价在盘中一度上涨超过20%,总市值突破1800亿港元 ,显示了市场对其新模型的高度认可和期待。媒体普遍将其誉为“国产编程王者” 9,并且其极具竞争力的成本优势(据称仅为Claude Opus的3%-5%) 6使其成为同性能级别AI编程模型中的“价格标杆” 13。M2.5与同期发布的智谱GLM-5等模型共同构成了2026年春节期间的AI模型发布热潮,标志着国产大模型已从“价格战”转向以编程与智能体为核心的技术竞速 19。
展望未来,MiniMax-M2.5无疑将引领编程技术新潮流,加速AI Agent技术从实验室走向大规模生产应用。尽管仍有部分观点指出在特定场景下模型表现和官方信息透明度仍有提升空间 16,但其在性能、效率和成本方面的综合优势,以及对Agent原生设计的坚持,使其有望成为推动人工智能行业发展的关键力量。MiniMax-M2.5的出现,不仅展现了中国在大模型领域的技术实力和创新活力,也为全球AI Agent技术的发展提供了新的方向和可能性。