Seedance 2.0: A Deep Dive into Multimodal AI Video Generation Capabilities
Introduction: Unveiling Seedance 2.0's Multimodal Prowess
Seedance 2.0, developed by ByteDance's Seed team, officially launched around February 8-12, 2026, marking a significant evolution in the field of AI video generation . This latest iteration is heralded as a "next-generation video creation model," signifying a pivotal shift from randomized generation towards unparalleled precision control, effectively providing "director-level control" for creators .
At the heart of Seedance 2.0's breakthrough capabilities is its advanced multimodal "All-Round Reference" System. This system is engineered to simultaneously accept and process diverse inputs, including text, images, audio, and video, offering creators an unprecedented level of control over the generated content . This report will provide a deep dive into Seedance 2.0's core multimodal capabilities, groundbreaking features, and its potential impact on various industries, setting the stage for a new era of AI-driven video production.
Understanding Multimodal AI in Seedance 2.0
Seedance 2.0, developed by ByteDance's Seed team, officially launched around February 8-12, 2026, representing a significant advancement in AI video generation . It marks a pivotal shift from randomized generation to precision control, offering "director-level control" for creators 1. This "next-generation video creation model" moves beyond basic text-to-video capabilities towards a more sophisticated, multimodal approach .
Defining Multimodal AI in Seedance 2.0: Director-Level Control and All-Round Reference System
At its core, Seedance 2.0's multimodal AI is defined by its "All-Round Reference" system, designed to provide unparalleled creative control 1. Unlike previous models that often relied on single input types, Seedance 2.0 accepts and intelligently processes diverse inputs simultaneously, including text, images, audio, and video 1. This integrated approach allows for a level of precision and nuanced instruction-following that grants creators "director-level control" over the generative process 1.
Supported Multimodal Inputs: Text, Images, Audio, and Video
Seedance 2.0 offers extensive multimodal input capabilities, allowing users to combine various data types to guide video generation 1. A single generation request can incorporate natural language instructions alongside multiple visual and auditory assets 1.
The specific input limits are detailed below:
| Input Type | Maximum Quantity | Maximum Duration |
|---|---|---|
| Text | 1 (main prompt) | N/A |
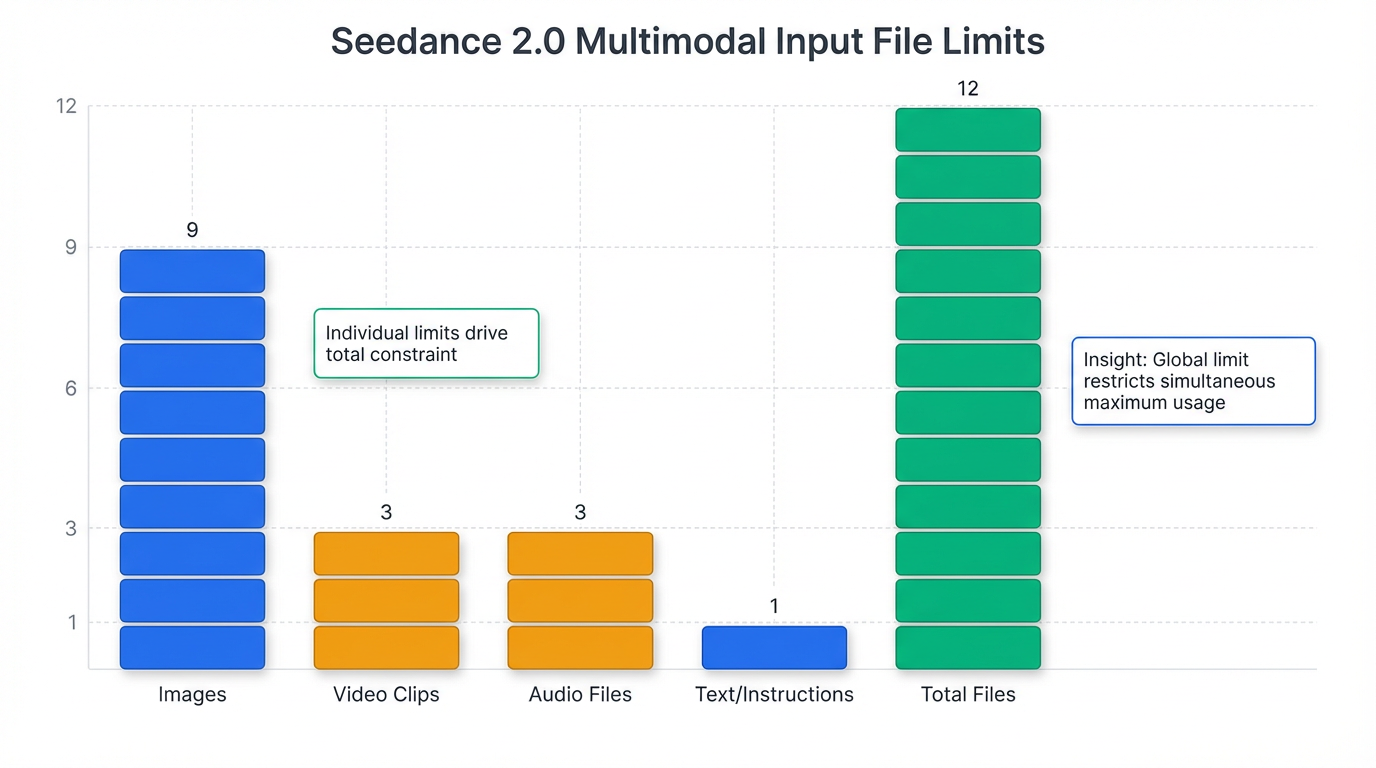
| Images | 9 images | N/A |
| Video | 3 clips | 15 seconds total |
| Audio | 3 files | 15 seconds total |
| Total Files | 12 files | N/A |
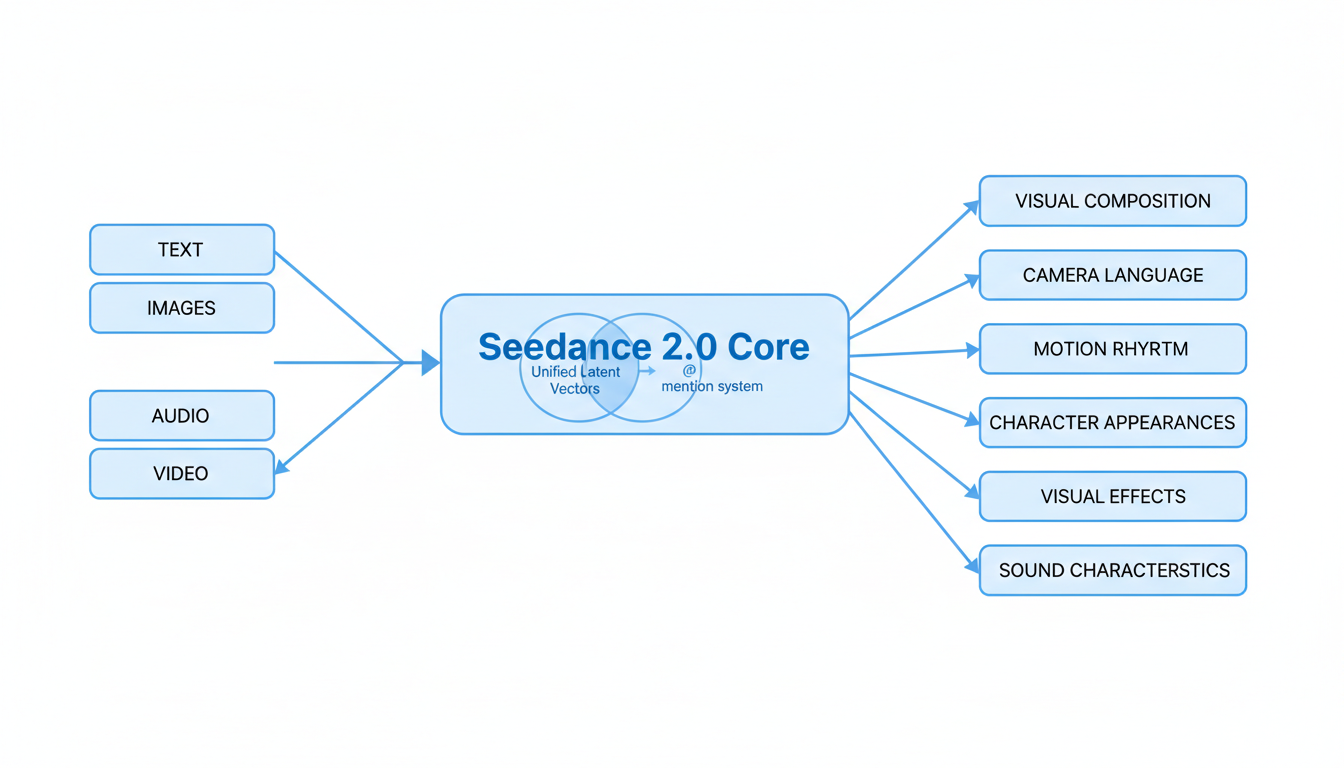
These inputs can be strategically utilized to influence elements like visual composition, camera language, motion rhythm, character appearances, visual effects, and sound characteristics 1.
Core Architectural Principles: Dual-Branch Diffusion Transformer and World Model Concept
The foundation of Seedance 2.0's advanced capabilities lies in its sophisticated AI architecture. It is built on ByteDance's "Dual-Branch Diffusion Transformer architecture" and operates as a diffusion model 1. This Diffusion Transformer (DiT) architecture replaces the traditional U-Net backbone of diffusion models with a transformer, enhancing scalability and attention mechanisms to capture long-range relationships in both spatial and temporal dimensions 2.
Seedance 2.0 is also regarded as a "World Model" contender, demonstrating a deep understanding of physical laws such as gravity, wind direction, and fluid dynamics . This enables it to construct scenes that adhere to real-world logic, implicitly understanding the consistency of three-dimensional space, replicating background parallax, correct shadow lengths, and smooth camera pans 3. This deep understanding allows the model to act as a "multimodal director," orchestrating complex interactions and realistic movements 4.
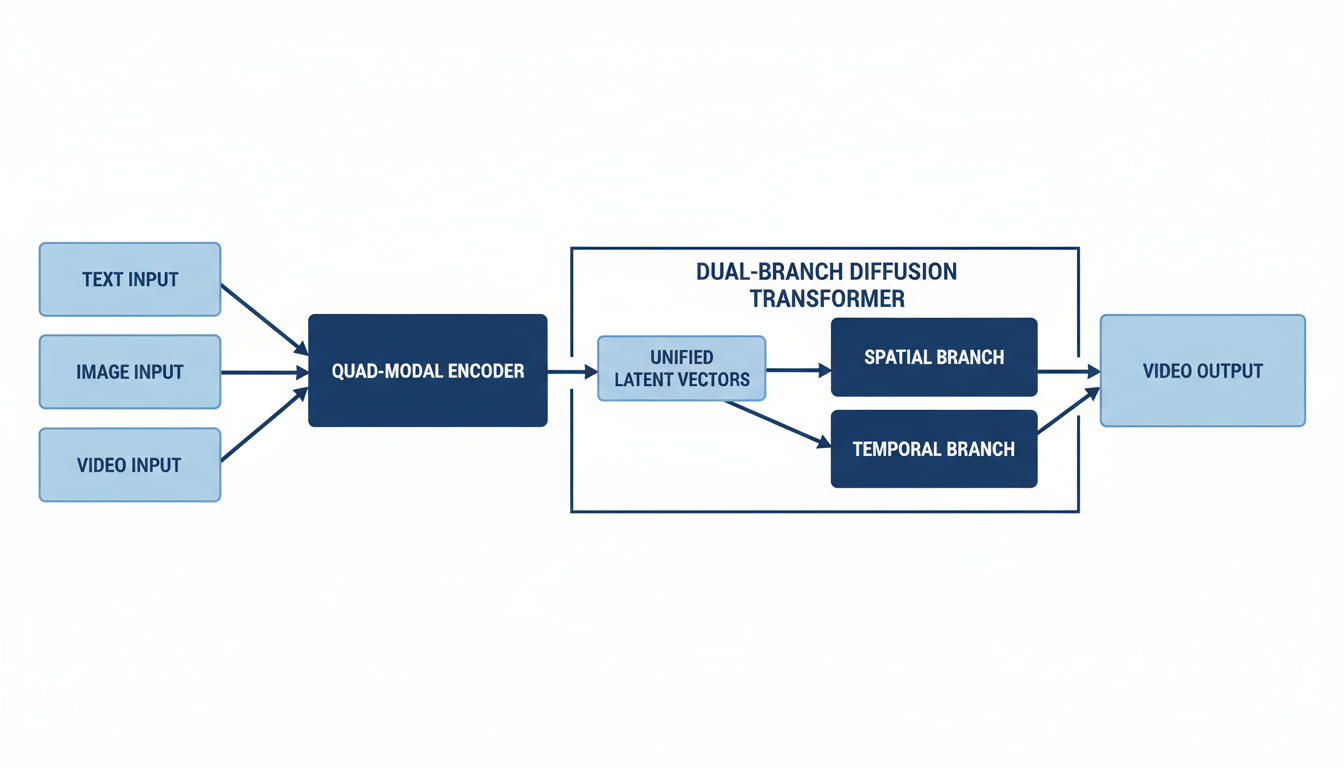
The Quad-Modal Encoder: Processing and Conversion to Unified Latent Vectors
The integration process begins with a "quad-modal encoder" that efficiently processes each type of input data 5. Instead of a single funnel, Seedance 2.0 utilizes pre-trained encoders for each modality 5:
- Text: Processed by a Large Language Model (LLM)-based encoder to extract semantic meaning 5.
- Images: Encoded into visual feature tokens 5.
- Video: Reference clips are encoded into spatiotemporal tokens 5.
- Audio: Encoded into waveform or spectrogram tokens 5.
All these raw inputs are then converted into a "unified language of latent vectors" 5. This mathematical representation allows for comprehensive multimodal content reference and editing 6.
Data Integration Mechanisms: The '@ Mention' System and Inter-Branch Communication
Information from these diverse modalities is seamlessly integrated through the unified language of latent vectors, enabling a coherent understanding across different input types 5. A crucial mechanism for user control over this integration is the @ mention system . This system allows users to explicitly reference uploaded assets within their prompts and assign specific roles to them . For example, users can instruct the model to reference @Video1 for camera movement or @Audio1 for background music 7. This capability enables the model to extract and apply specific elements such as motion patterns, visual effects, character appearances, camera techniques, and audio rhythms from the referenced files .
Furthermore, within the architectural design, the dual-branch diffusion transformer ensures continuous communication between its video and audio generation components 5. This inter-branch communication is vital for maintaining perfect synchronization throughout the creation process 5.
Role of Spatial and Temporal Branches in Multimodal Processing
The "dual-branch diffusion transformer" is a key architectural innovation that separates content generation from temporal coherence . This design addresses the inherent trade-off in single-pipeline models between maintaining high frame quality and ensuring temporal consistency 8.
- The Spatial Branch is dedicated to frame-level content generation, focusing on object appearance, scene composition, high-resolution output (up to 2K), and robust character identity encoding for consistency 8.
- The Temporal Branch is responsible for managing cross-frame motion coherence, controlling camera movements and transitions, synchronizing audio-visual timing, and ensuring multi-shot narrative continuity 8.
These two specialized branches process information independently, yet constantly communicate, before merging at the final rendering stage to produce a cohesive and high-quality video 8.
Physical Accuracy and Instruction Following in Multimodal Generation
Seedance 2.0 significantly enhances instruction-following and adherence to physical laws, resulting in highly natural and plausible motion and interaction scenes 1. The model incorporates physics-aware training objectives that penalize physically implausible motion during the generation process 2. This rigorous training leads to videos where physical phenomena like gravity, fabric draping, and fluid behavior appear substantially more believable and consistent with real-world physics 2. This deep understanding is a hallmark of its "World Model" capabilities, allowing for the generation of complex scenes that respect fundamental physical principles .
Core Video Generation Features and Workflows
Seedance 2.0, ByteDance's advanced AI video generation model, offers a sophisticated suite of features that provide "director-level control" for creators, fundamentally evolving the video creation workflow from randomized generation to precision control .
Multimodal "All-Round Reference" System
Central to Seedance 2.0's capabilities is its multimodal "All-Round Reference" system, which accepts and processes diverse inputs simultaneously, including text, images, audio, and video . Users can input up to 9 images, 3 video clips (maximum 15 seconds total), and 3 MP3 audio files (maximum 15 seconds total), alongside natural language instructions, totaling up to 12 files per generation . An "@ mention system" in prompts allows users to explicitly reference and assign roles to these assets, enabling the model to extract and apply specific elements such as visual composition, camera language, motion rhythm, character appearances, visual effects, and sound characteristics from the referenced files . This comprehensive input system is facilitated by a "quad-modal encoder" that processes each input type—text via an LLM-based encoder, images into visual feature tokens, video clips into spatiotemporal tokens, and audio into waveform or spectrogram tokens—converting them into unified latent vectors for coherent integration 5.
Extreme Character and Object Consistency
Addressing a persistent challenge in AI video generation, Seedance 2.0 ensures extreme character and object consistency across multiple shots . The model maintains flawless character retention, locking in facial features, clothing details, body proportions, and product details, thereby eliminating the "character drift" common in earlier models . This commitment to consistency extends to high visual quality, reduced frame flicker, and stable lighting throughout the generated output .
Native Audio-Video Generation and Lip-Sync
A significant breakthrough is Seedance 2.0's ability to generate audio and video simultaneously in a single pass, ensuring perfect millisecond-level synchronization . This capability produces perfectly synchronized sound effects, natural ambient audio, and phoneme-level lip-sync in over 8 languages, including English, Mandarin Chinese, Korean, Japanese, Spanish, French, German, and Portuguese . Furthermore, it supports multi-speaker voice cloning, allowing users to upload real voices to guide accent and tone 5. The underlying "dual-branch transformer" architecture ensures continuous communication between video and audio generation processes, maintaining this seamless synchronization 5.
Multi-Shot Storytelling and Cinematic Camera Control
Seedance 2.0 facilitates coherent multi-scene narratives from a single prompt, incorporating automatic camera transitions, persistent character identity, and cinematic continuity . It supports advanced camera techniques like Dolly Zoom, tracking shots, close-ups, and wide shots, and can even replicate camera movements from reference videos . For enhanced workflow, an "Agent" mode can automatically plan storyboards and camera movements based on a creative brief 9. A dedicated narrative planner functions like a storyboard artist, breaking down prompts into distinct camera shots and orchestrating their generation while maintaining shared consistency data across cuts 5. This enables the application of "cinematic grammar" such as establishing shots and shot-reverse-shot techniques 8.
Enhanced Control and Physical Accuracy
The model demonstrates significant improvements in instruction-following and adherence to physical laws, such as gravity, momentum, and collision behavior, resulting in highly natural and plausible motion and interaction scenes . Seedance 2.0 is regarded as a "World Model" contender due to its deep understanding of physical laws, allowing it to construct scenes that implicitly understand three-dimensional space, accurately replicating background parallax, correct shadow lengths, and smooth camera pans .
Video Editing and Extension
Seedance 2.0 provides robust AI-native editing capabilities. Users can perform character replacement, add or delete content within existing videos, and seamlessly extend videos while maintaining narrative coherence and visual style .
Output Specifications and Workflow Overview
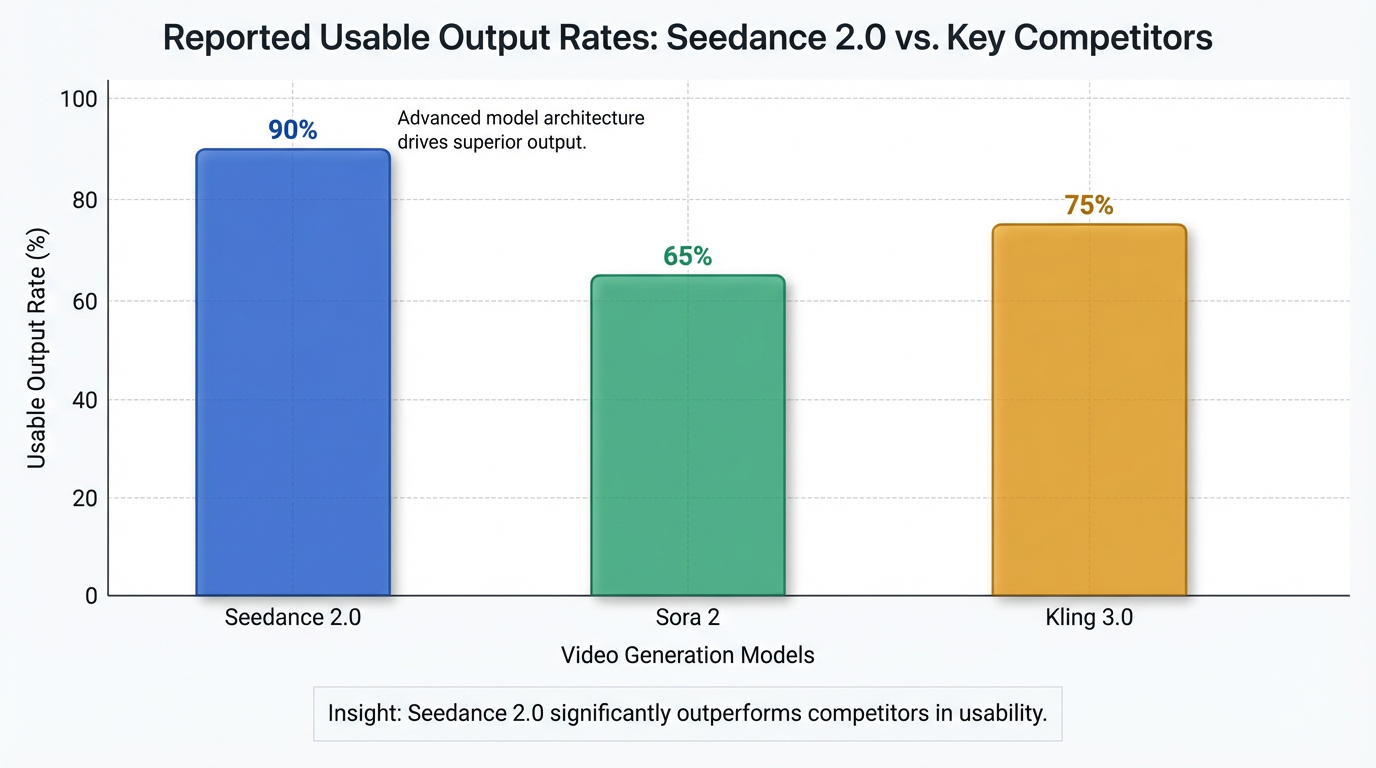
Seedance 2.0 delivers output resolutions up to 2K (2048x1080), with future plans for 4K . Video durations typically range from 4 to 15 seconds, though some sources indicate capabilities for up to 60 seconds or more . It supports 6 aspect ratios, including 16:9, 9:16, 4:3, 3:4, 21:9, and 1:1 . The output is watermark-free and suitable for commercial use 10. The generation process is up to 30% faster than its predecessor, with a 15-second clip taking approximately 5-6 minutes in tests . ByteDance reports a high usability rate, with over 90% of generated videos being suitable for commercial deployment without requiring re-generation .
Performance, Use Cases, and Market Impact
Seedance 2.0 represents a significant leap in AI video generation, distinguishing itself through enhanced efficiency, quality, and an unparalleled level of user control. It has been described as a "next-generation video creation model" that shifts from randomized generation to precision control, offering "director-level control" for creators . This addresses the critical "uncontrollability" pain point prevalent in earlier AI video tools 11.
The model achieves a substantial improvement in generation quality, boasting a reported 90%+ usable output rate for complex interaction and motion scenes . This rate is significantly higher than competitors like Sora 2 (60-70%) or Kling 3.0 (75%) . Furthermore, Seedance 2.0 generates video up to 30% faster than its predecessor, with a 15-second clip typically taking around 5-6 minutes in tests . This efficiency translates into considerable economic impact, enabling tasks that traditionally take a full day to be completed in five minutes and reducing production costs to as low as ~$0.42 (3 RMB) per shot , representing a potential 10,000x efficiency gain over traditional visual effects (VFX) workflows 12.
Achieving 'Director-Level Control' through Multimodal Input
A cornerstone of Seedance 2.0's precision control is its multimodal "All-Round Reference" system, which simultaneously accepts diverse inputs including text, images, audio, and video . Users can input up to 9 images, 3 video clips (max 15 seconds total), and 3 MP3 audio files (max 15 seconds total), alongside natural language instructions, accumulating up to 12 files per generation task . An "@ mention system" in prompts explicitly references and assigns roles to these assets, allowing creators to dictate elements such as visual composition, camera language, motion rhythm, character appearances, visual effects, and sound characteristics . This granular control transforms the creative process from "prompt guessing" to "precise replication" 11.
Core Features and Effectiveness
Seedance 2.0 integrates several breakthrough features that contribute to its high quality and effectiveness:
- Extreme Character and Object Consistency: It ensures flawless character retention across multiple shots, maintaining facial features, clothing details, body proportions, product details, and even small text, effectively addressing the "character drift" issue common in earlier models . This is supported by Global Identity Persistence (GIP) 13.
- Native Audio-Video Generation and Lip-Sync: The model generates audio and video simultaneously in a single pass, ensuring perfectly synchronized sound effects, natural ambient audio, and phoneme-level lip-sync in over 8 languages, including English, Mandarin Chinese, Korean, Japanese, Spanish, French, German, and Portuguese . It also supports multi-speaker voice cloning 5.
- Multi-Shot Storytelling and Cinematic Camera Control: Seedance 2.0 can generate coherent multi-scene narratives from a single prompt, incorporating automatic camera transitions, persistent character identity, and cinematic continuity . It supports advanced camera techniques like Dolly Zoom, tracking shots, close-ups, and wide shots, and can replicate camera movements from reference videos . A "narrative planner" acts like a storyboard artist, breaking down prompts into distinct camera shots and orchestrating their generation with shared consistency data .
- Enhanced Control and Physical Accuracy: The model demonstrates improved instruction-following and adherence to physical laws, such as gravity, momentum, and collision behavior, resulting in highly natural and plausible motion and interaction scenes . Regarded as a "World Model" contender, it implicitly understands three-dimensional space, replicating background parallax and smooth camera pans .
- Video Editing and Extension: Users can perform character replacement, add or delete content within existing videos, and seamlessly extend videos while maintaining narrative coherence and visual style .
Output Specifications and Performance Metrics
Seedance 2.0 delivers output resolutions up to 2K (2048x1080) for cinematic quality . While some sources mention 1080p 14, future plans include 4K output, expected with Seedance 2.5 in mid-2026 . Video durations typically range from 4 to 15 seconds , though some capabilities for 60+ seconds are noted and approximately 20 seconds 2. It supports 6 aspect ratios, including 16:9, 9:16, 4:3, 3:4, 21:9, and 1:1 . The output is watermark-free, suitable for commercial use 10.
Key Industry Applications and Use Cases
Seedance 2.0 targets a broad audience, including filmmakers, marketers, content creators, advertising agencies, and corporate clients , and is poised to revolutionize content production across various industries .
Examples of Multimodal Generation:
- A text-to-video (T2V) prompt can generate a detailed figure skating performance with specific camera angles and a narrative 1.
- An image-to-video (I2V) prompt animates a girl hanging and shaking laundry 1.
- A reference-to-video (R2V) prompt utilizes multiple images and text to depict a girl traveling through famous paintings, with specific actions and styles 1.
- A complex prompt might combine character images with a reference video's camera movements (e.g., Hitchcock zoom, orbit shots) and facial expressions within an elevator setting 7.
- For a fight scene, a multimodal prompt could use images for character appearance, a video for combat movements, and another image for the background setting 15.
Key applications include:
- Commercial and Industrial Content: Used for film, advertising, e-commerce, gaming, short drama, and serialized content .
- Marketing & E-Commerce: Generating product promos, A/B test creatives, localized campaign visuals, and dynamic product videos that accurately reproduce textures and brand details . It can even dress virtual models in real clothes from a single prompt, accelerating e-commerce video production .
- Film & Content Creation: Ideal for pre-visualizing scenes, storyboarding, creating pitch decks, social media content, and rapid prototyping for concepts like game cutscenes or architectural walkthroughs .
- Education & Enterprise: Facilitating the creation of animated explainers, training videos, and corporate communications with multilingual narration .
- Animation (2D & 3D/Game CG): Revolutionizing animation by generating styles similar to popular franchises with lower costs, addressing potential labor shortages, and allowing game studios to produce complex scenes in minutes instead of months .
- Mass Content Creation for Multi-Channel Networks (MCNs): Its low content creation threshold is transformative for MCNs, allowing them to generate consistent, voice-dubbed stories and translate content into multiple languages .
- Film and Television Visual Effects (VFX): Offers practical workflows for low- to medium-end visual effects, significantly reducing the cost and time for complex scenes .
- Real Estate & Architecture: Transforming property photos into immersive virtual tours and showcasing architectural designs with dynamic walkthroughs 16.
Market Positioning and Differentiating Factors
Seedance 2.0 is positioned as a "virtual director" tool, fundamentally shifting the workflow from random generation to directed creation . Its primary differentiator is its unparalleled multimodal "all-round reference" system, which enables precise control over character, motion, camera, and style – a feature not matched by competitors like Sora 2, Runway, or Pika .
It stands out for:
- Superior Controllability and Consistency: Solving the persistent AI video problems of inconsistency and lack of control that other models often struggle with .
- Native Audio-Visual Synchronization: Producing synchronized video and audio at a millisecond level, including accurate lip-syncing across multiple languages, saving significant post-production effort .
- Multi-Shot Narrative Coherence: Designed to generate complete, edited scenes with consistent characters and environments across multiple shots, understanding cinematic grammar for viable narrative storytelling .
- High Usability Rate: Boasting a reported 90%+ usable output rate on the first try, significantly outperforming competitors .
- Efficiency and Cost-Effectiveness: It can deliver in five minutes what traditionally takes a creative team a full day , drastically reducing production costs .
- ByteDance Ecosystem Integration: As a product of ByteDance, it benefits from the company's vast data and understanding of short-form video dynamics, integrating into platforms like Dreamina AI, Doubao, Volcano Engine Model Ark Experience Center, and CapCut .
While OpenAI's Sora 2 might have an edge in raw physics simulation and hyper-realism in certain instances , Seedance 2.0 is generally considered superior in workflow efficiency, storytelling capability, consistency, and audio synchronization . Runway excels in its editing pipeline but lacks Seedance's multimodal input and native audio sync 14. Kling struggles with complex multi-element scenes but can generate longer videos (up to 2 minutes) than Seedance's typical 15-20 second cap 14.
User Feedback and Industry Reception
Seedance 2.0's launch generated immense excitement, with users and industry experts calling it a "singularity moment" for video creation . Reactions included exclamations like "Amazing" and "Is this really AI?" , and Feng Ji, CEO of Game Science, declared it the "strongest video generation model on Earth" 17.
Positive feedback highlights:
- Accurate Motion Replication: Content creators appreciate the "incredibly accurate" motion replication when referencing dance videos 16.
- Cinematic Camera Control: Filmmakers find the reference capability "mind-blowing," praising its ability to perfectly replicate camera movement and pacing from film clips 16.
- Character Consistency: Creative directors laud the model for solving the "biggest problem" of character consistency, noting stable faces, clothing, and small text throughout videos 16.
- Seamless Editing and Extension: Video producers describe the extension feature as seamless, allowing natural merging and extension of clips, akin to an "AI editor that understands continuity" 16.
- 10x Content Output: Social media managers report a tenfold increase in content output by referencing trending video templates 16.
- Fantastic Audio Generation: Music video directors praise the built-in audio generation for matching sound effects and music beat sync 16.
- Efficiency: The tool enables a full day's work in five minutes and allows short films to be produced in under 30 minutes 17.
Limitations and Challenges in Practical Application
Despite its advancements, ByteDance acknowledges that Seedance 2.0 is "still far from perfect," with areas needing optimization 18.
- Output Duration: Primarily generates short clips (4-15 seconds), requiring stitching for longer content, which can sometimes reveal seams .
- Complexity Handling: Complex scenes with intricate multi-character interactions or precise action timing may still require multiple iterations 19.
- Text Rendering: Text rendering (e.g., signs, subtitles, logos) often results in garbled outputs, indicating an industry-wide limitation 19.
- Generation Time: While faster, generation is not real-time, taking 60–180+ seconds per clip 19.
- Consistency Drift: In very long or complex multi-shot sequences, character identity and facial consistency can occasionally drift 19.
- Prompt Sensitivity and Learning Curve: Requires precise cinematic language, as vague prompts yield generic results. The multimodal reference system has a real learning curve .
- Physics Glitches: Despite improvements, complex object interactions (e.g., hands holding cups, objects interacting with water) can still result in visual errors 17.
- Reference Conflicts: If reference materials conflict (e.g., lighting, proportions), the model may blend them unpredictably, highlighting the need for careful "reference hygiene" 20.
- No Built-in Editor: Seedance 2.0 is primarily a generation tool, not a full editing suite, meaning external software is still required for post-production 14.
- Smaller English Community: Being newer in the English-speaking market, it has fewer tutorials, community templates, and third-party integrations compared to established Western models 14.
- Limited Public Reviews (Trustpilot): Some negative Trustpilot reviews for a general "Seedance AI" service indicate user dissatisfaction with promised capabilities, resolution, and refund policies for paid tiers 21.
Ethical and Industry Concerns
The rapid advancements of Seedance 2.0 also raise several ethical and industry concerns:
- Job Displacement: Professionals express fear that Seedance 2.0 could eliminate entry-level jobs in editing, VFX, and sound design 17.
- Deepfake Potential: The ability to generate hyper-realistic video from simple inputs raises concerns about deepfakes and the need for cross-verification of unverified content . ByteDance proactively suspended an early "voice-from-photo" feature due to deepfake concerns and implemented consent verification safeguards .
- Copyright Issues: Concerns exist regarding data transparency in training and potential copyright infringement, as AI-generated content can closely resemble known intellectual property 22. The model currently restricts the use of real-person images or videos as main references without verification 18.
Economic Impact and Future Outlook
Seedance 2.0 is expected to revolutionize content production by significantly lowering costs and increasing efficiency across various sectors . ByteDance plans for continuous development, with Seedance 2.5 anticipated in mid-2026, which is expected to feature 4K output and potentially real-time generation capabilities 23. Seedance 2.0 is currently available on platforms like Dreamina AI, Doubao, and Volcano Engine Model Ark Experience Center, with API services expected to launch for enterprise users . It is also integrated into CapCut, ByteDance's video editing app 23.
Conclusion: The Future of AI Video Generation with Seedance 2.0
Seedance 2.0, launched in early February 2026, represents a transformative leap in AI video generation, moving beyond randomized outputs to offer unprecedented "director-level control" for creators . Its core contributions lie in its sophisticated multimodal "all-round reference" system, exceptional consistency, and precise control capabilities . The model accepts up to 12 diverse inputs simultaneously—including text, images, audio, and video—using an "@ mention system" to guide the generation with specific instructions on visual composition, camera language, motion rhythm, and audio characteristics . This innovative approach effectively addresses the long-standing "character drift" issue, ensuring flawless character and object retention across multiple shots and maintaining uniformity throughout the video . Furthermore, its native audio-video generation with millisecond-level synchronization, phoneme-level lip-sync in over 8 languages, and the ability to handle multi-shot storytelling with cinematic camera control distinguish it from competitors .
These advancements have profound implications for content creation across various industries, signaling a disruptive potential previously unimaginable. Seedance 2.0 is poised to revolutionize commercial and industrial content, marketing, e-commerce, film, content creation, education, and enterprise applications by significantly lowering costs and increasing efficiency . It enables the rapid creation of product promos, localized campaign visuals, animated explainers, storyboards, and even game cutscenes . User feedback has hailed Seedance 2.0 as a "singularity moment," with some industry experts declaring it the "strongest video generation model on Earth" . It promises to democratize "Hollywood-quality" content creation, allowing small businesses to produce personalized video ads and game studios to rethink expensive CG outsourcing . The reported 90%+ usable output rate further solidifies its position as a highly efficient tool, capable of delivering a full day's creative work in just five minutes .
Looking ahead, ByteDance plans to continue evolving Seedance, with Seedance 2.5 anticipated in mid-2026, bringing with it projected 4K output capabilities and potentially real-time generation 23. Continued efforts are focused on achieving deeper alignment between large models and human feedback 18. This trajectory suggests a future where AI-driven video creation becomes even more integrated and intuitive, further streamlining creative workflows.
However, the transformative power of Seedance 2.0 also brings broader societal and ethical considerations to the forefront. Concerns surrounding job displacement, particularly for entry-level roles in editing, VFX, and sound design, have been raised 17. The model's hyper-realistic generation capabilities necessitate ongoing discussions about the potential for deepfakes and the need for robust verification mechanisms . ByteDance has already responded to these concerns by suspending a "voice-from-photo" feature and implementing consent verification safeguards, alongside restricting the use of real-person images or videos without authorization . Additionally, questions regarding data transparency and potential copyright infringement remain pertinent as AI-generated content becomes indistinguishable from human-made creations 22. As Seedance 2.0 continues to integrate into ByteDance's ecosystem, including platforms like Dreamina AI, Doubao, and CapCut, its influence on the AI video generation landscape will undeniably reshape creative industries, demanding continuous adaptation and ethical vigilance.