딥시크 V4: 100만 토큰 컨텍스트 시대를 여는 AI 혁신
서론: 딥시크 신규 모델 출시 개요
딥시크는 2026년 2월 출시를 목표로 차세대 인공지능 모델인 DeepSeek V4를 선보일 예정입니다 1. 이 혁신적인 모델은 "수십만 개에서 거의 백만 개의 토큰"에 달하는 전례 없는 대규모 컨텍스트 창을 지원하며 1, 이는 현재 AI 코딩 도구의 주요 한계점으로 지적되던 부분을 해결하는 데 중요한 역할을 할 것으로 기대됩니다 1.
DeepSeek V4는 특히 코딩 중심의 장문 컨텍스트 대규모 언어 모델로 설계되었습니다 1. 실제 엔지니어링 및 기업 워크플로우를 위한 코드 지능, 리포지토리 수준의 추론, 그리고 프로덕션 안정성에 중점을 두고 있으며 1, 단순한 대화형 모델을 넘어 개발자가 소프트웨어를 작성, 유지 관리 및 확장하는 방식에 최적화된 AI 시스템으로 포지셔닝됩니다 1. 본 보고서에서는 DeepSeek V4의 이러한 핵심 특징과 기술적 배경, 그리고 시장에 미칠 영향에 대해 심층적으로 분석하고자 합니다.
주목할 만한 핵심 기능: 100만 토큰 컨텍스트 심층 분석
DeepSeek V4는 '수십만 개에서 거의 백만 개의 토큰'에 달하는 대규모 컨텍스트 창을 지원하며, 이는 AI 모델의 성능과 활용 가능성에 있어 중요한 진보를 의미합니다 2. 이 섹션에서는 DeepSeek V4의 100만 토큰 컨텍스트가 가지는 기술적 의미, 구현 방식, 사용자 경험 및 이점, 기존 모델과의 차별점, 그리고 AI 코딩 도구 분야에서 한계를 극복하는 기여도를 심층 분석합니다.
100만 토큰 컨텍스트의 의미 및 기존 LLM 한계 극복
DeepSeek V4의 100만 토큰 컨텍스트는 AI 모델이 매우 방대한 양의 정보를 한 번에 '이해'하고 '처리'할 수 있음을 의미합니다 1. 이는 전체 코드베이스를 청킹(chunking) 없이 수용하고, 파일 전반에 걸친 아키텍처 컨텍스트를 보존하며, 누락된 의존성으로 인한 환각(hallucination)을 줄여 대규모 리팩토링의 일관성을 높이는 데 필수적입니다 1.
기존 대규모 언어 모델(LLM)은 컨텍스트 길이가 길어질수록 계산 복잡도가 제곱적으로 증가(O(N²))하여 메모리 사용량 폭증과 속도 저하를 야기하는 한계가 있었습니다 . 또한, 관련 정보가 컨텍스트의 중간에 있을 때 모델 성능이 급격히 저하되는 'Lost in the Middle' 현상도 일반적인 문제였습니다 . DeepSeek V4는 이러한 문제들을 극복하며 혁신적인 발전을 이루었습니다.
핵심 기술적 구현
DeepSeek V4는 다음과 같은 핵심 기술적 혁신을 통해 100만 토큰 컨텍스트를 효율적으로 구현합니다:
-
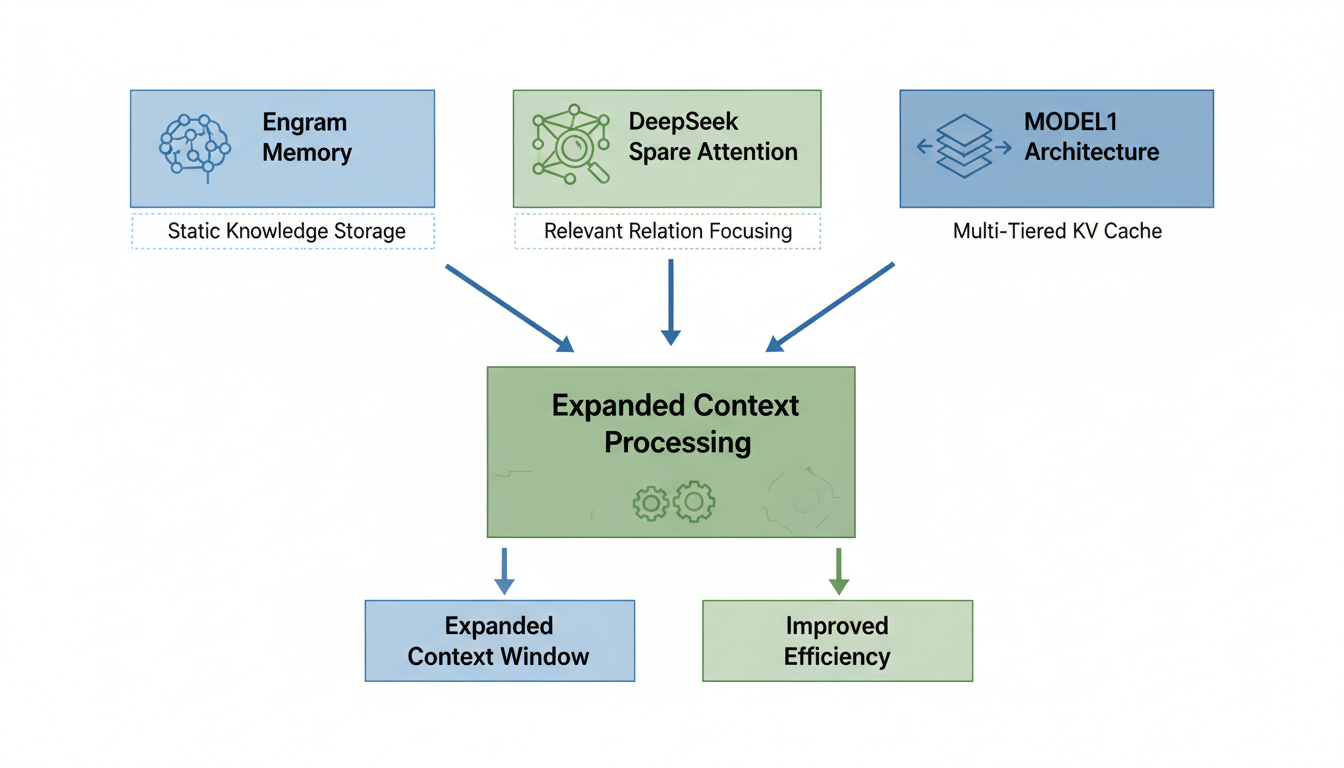
Engram 조건부 메모리 아키텍처: Engram은 정적 지식 조회(CPU RAM)와 동적 추론(GPU HBM)을 분리하여, 모델이 필요할 때만 대규모 지식 저장소에서 정보를 효율적으로 검색하도록 합니다 . 이는 기존 모델이 반복적으로 정적 조회 테이블을 재구성하는 컴퓨팅 자원 낭비를 줄입니다 . Engram은 토크나이저 압축(어휘 크기 23% 감소), 멀티헤드 해싱(O(1) 조회 가능), 컨텍스트 인식 게이팅(관련 없는 정보 억제)을 통해 작동하여 3, GPU 메모리 사용량을 절감하고 100만 토큰 이상의 컨텍스트를 확장하며, 운영 비용을 20배 낮출 수 있습니다 . 100B 매개변수의 Engram 테이블은 호스트 DRAM에 상주하면서도 처리량 페널티가 3% 미만입니다 3.
-
DeepSeek Sparse Attention (DSA): DSA는 모든 토큰 쌍에 대해 주의(attention)를 계산하는 기존 방식 대신, 계산 자원을 가장 관련성 높은 관계에만 집중시키는 '지능형 희소성(intelligent sparsity)'을 구현합니다 . 주의 메커니즘을 두 단계로 분할하는데, 첫째, 빠른 관련성 필터링을 수행하는 'Lightning Indexer'가 소규모 벡터 투영, 단순한 내적, ReLU, FP8 정밀도를 사용하여 빠르게 관련성을 평가합니다. 둘째, 선택된 상위 k개의 토큰에 대해서만 정밀한 주의를 계산하여, 계산 복잡도를 O(N²)에서 O(N·k)로 줄입니다 4. 이를 통해 100만 토큰 이상의 컨텍스트 창을 지원하면서도 계산 비용을 기존 대비 약 50% 절감합니다 .
-
MODEL1 아키텍처 (계층형 KV 캐시 저장): 이 아키텍처는 KV(Key-Value) 캐시를 고빈도(GPU VRAM), 중빈도(CPU RAM), 저빈도(디스크 저장소)로 계층화하여 저장합니다 . 그 결과, GPU에서 KV 데이터의 80%를 오프로드하여 메모리 40% 절감, 컨텍스트 10배 확장, 비용 60% 절감이라는 성능 향상을 가져옵니다 .
-
mHC (Manifold-Constrained Hyper-Connections): mHC는 잔여 연결(residual connection)을 최적화하여 정보 흐름을 유연하게 만들고, 깊은 네트워크 훈련 중 기울기 소실 또는 폭발 문제를 해결합니다 . 이는 다중 병렬 스트림을 통해 정보 교환을 가능하게 하여 더 풍부한 처리 능력을 제공하며, 신호 폭발을 방지하기 위해 스트림 상호 작용을 제한합니다 3.
-
희소 FP8 디코딩: FP8(8비트 부동 소수점)과 BF16(16비트 부동 소수점)을 혼합하여 사용하여 정확도를 유지하면서 메모리 사용량을 크게 줄입니다 . 이 기술은 추론 속도를 1.8배 향상시키면서도 정확도 손실을 0.5% 미만으로 유지합니다 .
AI 모델 성능 향상
DeepSeek V4의 긴 컨텍스트는 AI 모델의 전반적인 성능을 크게 향상시킵니다:
- 추론 능력: 장문 컨텍스트에서 정보에 안정적으로 접근하고 사용하는 능력을 개선하며 4, Engram 기술은 'Needle in a Haystack' 벤치마크에서 정확도를 84.2%에서 97%로 향상시켰습니다 5.
- 일관성 및 신뢰성: 'Lost in the Middle' 문제를 완화하여 모델이 컨텍스트의 모든 부분에서 정보를 효과적으로 활용할 수 있도록 합니다 .
- 비용 효율성: DSA, MODEL1, Engram, FP8 디코딩 등 혁신적인 기술을 통해 기존 모델 대비 현저히 낮은 추론 비용(백만 토큰당 $0.10, 경쟁 모델의 40% 수준)으로 최첨단 성능을 제공합니다 .
사용자(개발자, 기업) 이점 및 활용 가능성
DeepSeek V4의 100만 토큰 컨텍스트는 특히 개발자와 기업 사용자에게 다음과 같은 혁신적인 이점과 활용 가능성을 제공합니다:
- 대규모 코드베이스 처리: 전체 코드베이스를 한 번에 처리하고 깊이 있게 이해할 수 있어, 수십만, 나아가 100만 토큰 이상의 컨텍스트를 활용합니다 .
- 생산성 혁명:
- 코드 생성 및 이해: 더 정확하고 효율적이며 유지 보수 가능한 코드를 생성하고 개발자의 의도를 더 잘 이해합니다 6.
- 리포지토리 수준 리팩토링: 대규모 코드베이스 전체에서 다중 파일 추론, 종속성 추적, 일관성 유지가 가능하며 , 복잡한 프로젝트에 대한 새로운 개발자의 온보딩을 빠르고 효과적으로 만듭니다 6.
- 지능형 버그 탐지 및 수정: 복잡한 상호 의존성을 추적하고, 여러 파일에 걸쳐 버그를 진단하며, 시스템 전체 컨텍스트를 고려한 수정 제안을 할 수 있습니다 .
- AI 코딩 에이전트: 장기간의 개발 세션 동안 일관성을 유지하며, 단순한 자동 완성 도구를 넘어 시스템 수준의 이해를 제공하는 AI 시스템으로의 전환을 가능하게 합니다 7.
- 하드웨어 접근성: 듀얼 NVIDIA RTX 4090 또는 싱글 RTX 5090과 같은 소비자용 하드웨어에서도 구동 가능하도록 설계되어 , 에어갭(air-gapped) 환경이나 엄격한 데이터 거버넌스 요구 사항을 가진 기업에서도 로컬 배포가 가능합니다 8.
기존 LLM 컨텍스트 길이와의 차별점 및 기술적 우위
DeepSeek V4의 100만 토큰 컨텍스트는 현재 시장에 나와 있는 주요 LLM과 비교할 때 여러 면에서 차별화됩니다.
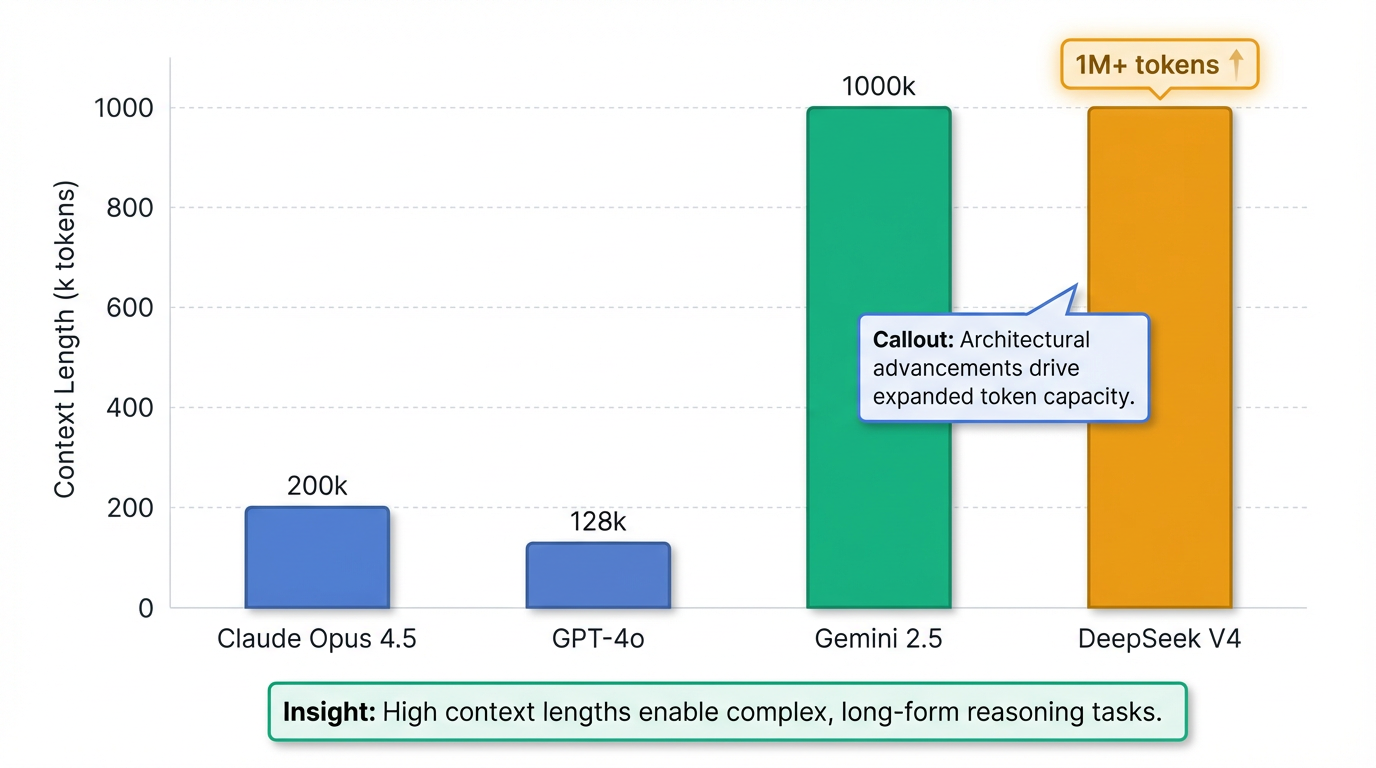
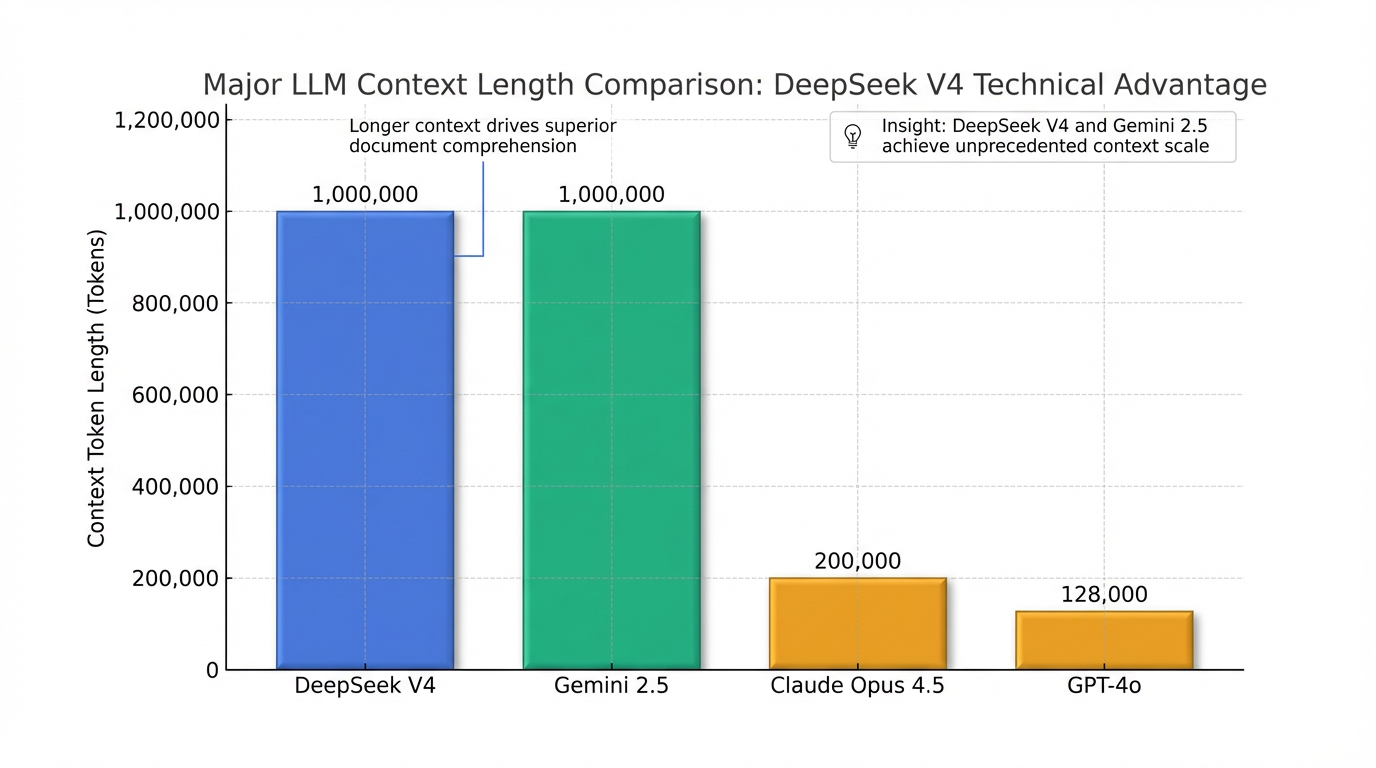
- 컨텍스트 길이 비교: Claude Opus 4.5는 200k 토큰 , GPT-4o는 128k 토큰 3, Gemini 2.5는 1M 토큰을 지원하는 반면 3, DeepSeek V4는 100만 개 이상의 토큰을 지원합니다 .
- 성능 우위 (특히 코딩 분야): 내부 테스트 결과, DeepSeek V4는 Claude 및 OpenAI의 GPT 시리즈를 능가하는 코딩 성능을 보인다고 보고되었습니다 . HumanEval 벤치마크에서 98% 9 (또는 90% 10), GSM8K에서 96% 9를 기록하여, Claude Opus 4.5의 SWE-bench Verified 80.9% 5를 넘어설 것으로 예상됩니다 8.
| 모델 | 벤치마크 | 점수 |
|---|---|---|
| DeepSeek V4 | HumanEval | 98% |
| DeepSeek V4 | GSM8K | 96% |
| Claude Opus 4.5 | SWE-bench Verified | 80.9% |
- 비용 효율성 및 접근성: DeepSeek V4는 경쟁 모델보다 현저히 낮은 추론 비용(백만 토큰당 $0.10)으로 최첨단 성능을 제공하여 9, AI의 민주화를 추구합니다. 이는 오픈 소스 가중치(예상)와 소비자용 하드웨어 지원을 통해 가능하며 , 폐쇄형 모델 제공업체에 대한 상당한 압력으로 작용할 수 있습니다 5.
AI 코딩 도구 분야에서의 한계 극복 기여
DeepSeek V4의 긴 컨텍스트 창은 AI 코딩 도구 분야에서 기존 모델의 주요 한계를 극복하는 데 결정적인 기여를 합니다.
- 전체 리포지토리 이해: 기존 AI 코딩 도구는 대규모 리포지토리를 처리할 수 있어도 일관성 유지, 컨텍스트 드리프트, 누락된 종속성 처리 등에서 어려움을 겪었습니다. DeepSeek V4는 이러한 문제들을 '장문 컨텍스트 훈련(long-context discipline)'을 통해 극복하고자 합니다 7.
- 멀티 파일 추론: V4는 여러 파일 간의 논리를 관리하고, 프로젝트 전반의 아키텍처 패턴 및 코딩 규칙을 인식하여 복잡한 시스템 수준의 개발 작업을 처리할 수 있습니다 .
- 버그 진단 및 수정: 스택 추적을 분석하고, 실행 경로를 추적하며, 시스템 전체 컨텍스트를 고려한 수정 사항을 제안하여 기존 모델의 한계 (단일 파일만 보고 버그 수정 시 다른 부분 손상)를 해결합니다 .
- 지속적인 개발 세션: '컨텍스트 벽(Context Wall)' 문제를 해결하여, AI가 장시간 동안 프로젝트를 '기억'하고 일관성을 유지할 수 있게 함으로써 7, 단순한 코드 조각 완성을 넘어 시스템 수준의 이해를 갖춘 코딩 에이전트 역할을 수행합니다 .
- 오프라인 환경 지원: 오픈 소스 및 소비자 하드웨어 호환성을 통해, 데이터 거버넌스 요구 사항이 엄격하거나 에어갭 환경이 필요한 개발 팀도 DeepSeek V4를 자체 인프라 내에서 활용할 수 있습니다 . 이는 보안 및 규제 준수가 중요한 산업 분야에서 AI 코딩 도구의 활용을 확장시킵니다 8.
DeepSeek V4의 100만 토큰 컨텍스트는 단순한 기술적 진보를 넘어, AI가 소프트웨어 개발 및 복잡한 정보 처리 방식에 근본적인 변화를 가져올 수 있는 잠재력을 보여줍니다. 이는 AI 모델이 실제 엔지니어링 문제를 해결하고, 대규모 시스템의 복잡성을 관리하며, 개발 워크플로우를 혁신하는 데 핵심적인 역할을 할 것입니다.
기타 주요 특징 및 성능
DeepSeek V4는 100만 토큰 컨텍스트라는 혁신적인 기술 외에도, 다양한 측면에서 AI 모델의 전반적인 성능을 크게 향상시켰습니다. 모델은 장문 컨텍스트에서 정보에 안정적으로 접근하고 사용하는 능력이 개선되었으며 4, 특히 Engram 기술을 통해 'Needle in a Haystack' 벤치마크에서 정확도를 84.2%에서 97%로 크게 향상시켰습니다 5. 또한, 관련 정보가 컨텍스트 중간에 있을 때 성능이 저하되는 'Lost in the Middle' 문제를 완화하여 모델의 일관성과 신뢰성을 높였습니다 .
DeepSeek V4는 DSA(DeepSeek Sparse Attention), MODEL1 아키텍처, Engram 조건부 메모리 아키텍처, 그리고 희소 FP8 디코딩 등 혁신적인 기술적 구현을 통해 최첨단 성능을 제공하면서도 기존 모델 대비 현저히 낮은 추론 비용을 자랑합니다 . 백만 토큰당 $0.10의 추론 비용은 경쟁 모델 대비 약 40% 수준으로, 매우 높은 비용 효율성을 달성합니다 .
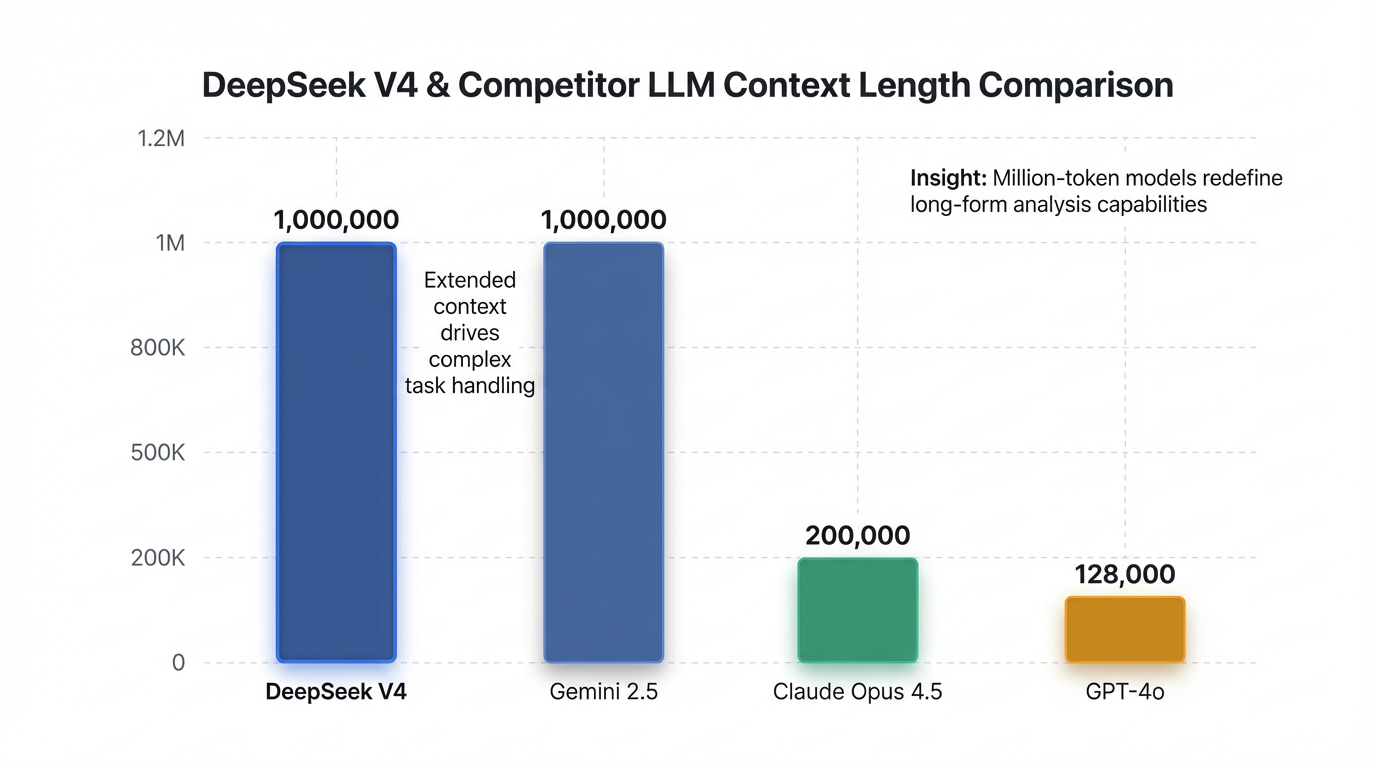
경쟁 LLM과 비교했을 때, DeepSeek V4의 컨텍스트 길이는 압도적인 우위를 보입니다. Claude Opus 4.5는 200k 토큰 , GPT-4o는 128k 토큰 3, Gemini 2.5는 1M 토큰을 지원하는 반면 3, DeepSeek V4는 100만 개 이상의 토큰 컨텍스트를 제공합니다 . 특히 코딩 분야에서는 내부 테스트 결과 Claude 및 OpenAI의 GPT 시리즈를 능가하는 성능을 보였다고 보고되었습니다 . HumanEval 벤치마크에서 98% 9 (또는 90% 10), GSM8K에서 96% 9를 기록하며, Claude Opus 4.5의 SWE-bench Verified 80.9% 5를 넘어설 것으로 예상됩니다 8.
이러한 성능과 함께 DeepSeek V4는 AI의 민주화에도 기여합니다. 낮은 추론 비용뿐만 아니라, 오픈 소스 가중치(예상)와 듀얼 NVIDIA RTX 4090 또는 싱글 RTX 5090과 같은 소비자용 하드웨어에서도 구동 가능하도록 설계되어 접근성을 크게 높였습니다. 이는 에어갭(air-gapped) 환경이나 엄격한 데이터 거버넌스 요구 사항을 가진 기업에서도 로컬 배포를 가능하게 하여 8 폐쇄형 모델 제공업체에 상당한 압력으로 작용할 수 있습니다 5.
산업적 의의 및 기대 효과
DeepSeek V4의 100만 토큰 컨텍스트는 단순한 기술적 진보를 넘어, AI가 소프트웨어 개발 및 복잡한 정보 처리 방식에 근본적인 변화를 가져올 수 있는 잠재력을 보여줍니다. 이는 AI 모델이 실제 엔지니어링 문제를 해결하고, 대규모 시스템의 복잡성을 관리하며, 개발 워크플로우를 혁신하는 데 핵심적인 역할을 할 것입니다 2. 특히 AI 산업 전반, 개발자, 그리고 기업 사용자에게 다음과 같은 혁신적인 영향을 미칠 것으로 예상됩니다.
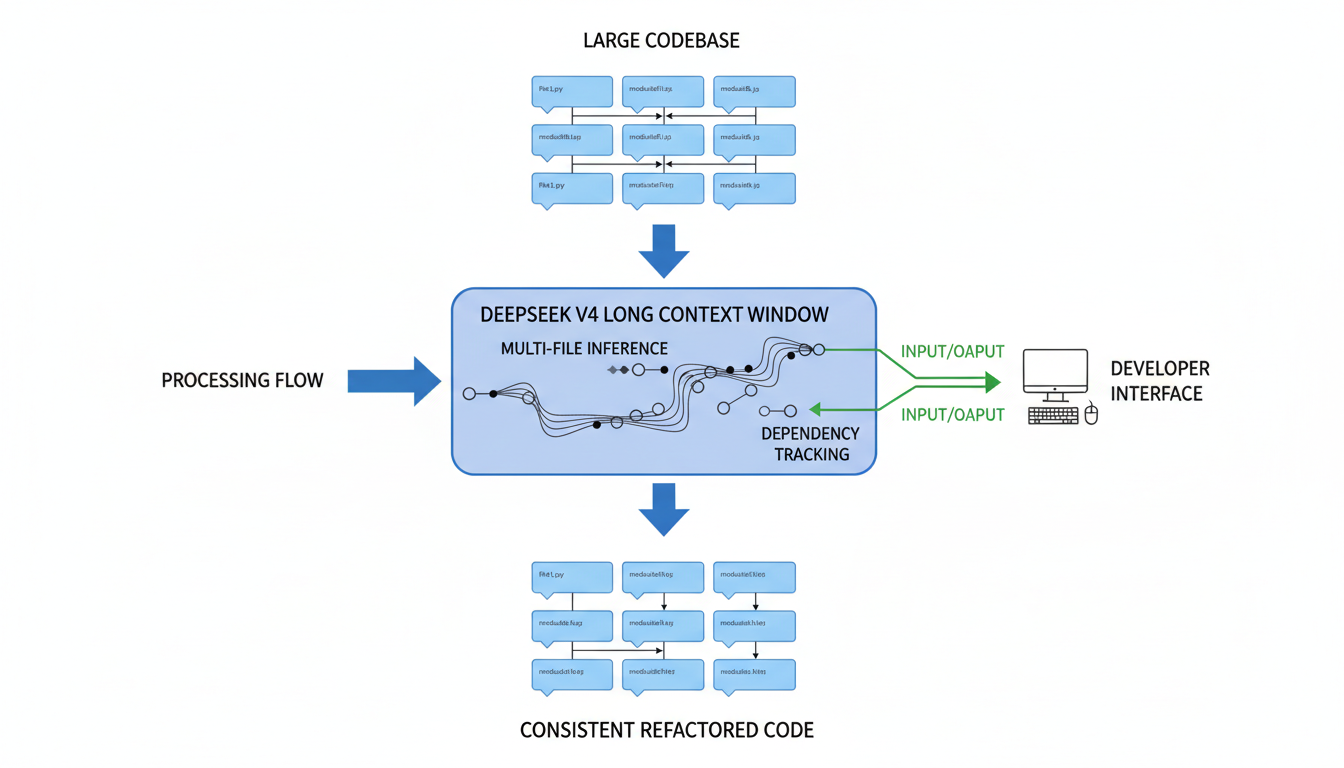
AI 산업 및 개발자/기업에 미칠 영향
DeepSeek V4는 대규모 컨텍스트 기반의 혁신적인 개발 환경을 조성합니다. 이는 전체 코드베이스를 청킹(chunking) 없이 수용하고, 파일 전반에 걸친 아키텍처 컨텍스트를 보존하며, 누락된 의존성으로 인한 환각(hallucination)을 줄여 대규모 리팩토링의 일관성을 높이는 데 필수적입니다 1.
기존 AI 코딩 도구는 대규모 리포지토리를 처리할 수 있었음에도 불구하고, 일관성 유지, 컨텍스트 드리프트, 누락된 종속성 처리 등에서 어려움을 겪었습니다. DeepSeek V4는 이러한 문제들을 '장문 컨텍스트 훈련(long-context discipline)'을 통해 극복하고자 합니다 7. 이는 AI 코딩 도구 패러다임의 변화를 예고하며, 단순한 자동 완성 도구를 넘어 시스템 수준의 이해를 제공하는 AI 시스템으로의 전환을 가능하게 합니다 7.
주요 활용 사례 및 잠재적 가치
DeepSeek V4의 100만 토큰 컨텍스트는 개발자와 기업 사용자에게 다음과 같은 구체적인 활용 사례와 잠재적 가치를 제공하며 생산성 혁명을 이끌 것입니다.
- 대규모 코드베이스 이해: 전체 코드베이스를 한 번에 처리하고 깊이 있게 이해할 수 있게 함으로써, 수십만, 나아가 100만 토큰 이상의 컨텍스트를 활용합니다 . 이는 개발자가 코드를 더 정확하고 효율적이며 유지 보수 가능하게 생성하도록 돕고, 개발자의 의도를 더 잘 이해하게 합니다 6.
- 리포지토리 수준 리팩토링 및 멀티 파일 추론: V4는 여러 파일 간의 논리를 관리하고, 프로젝트 전반의 아키텍처 패턴 및 코딩 규칙을 인식하여 복잡한 시스템 수준의 개발 작업을 처리할 수 있습니다 . 대규모 코드베이스 전체에서 다중 파일 추론, 종속성 추적, 일관성 유지가 가능하며 , 복잡한 프로젝트에 대한 새로운 개발자의 온보딩을 빠르고 효과적으로 만듭니다 6.
- 지능형 버그 탐지 및 수정: 복잡한 상호 의존성을 추적하고, 여러 파일에 걸쳐 버그를 진단하며, 시스템 전체 컨텍스트를 고려한 수정 제안을 할 수 있습니다 . 이는 스택 추적을 분석하고, 실행 경로를 추적하여 기존 모델의 한계(단일 파일만 보고 버그 수정 시 다른 부분 손상)를 해결합니다 .
- AI 코딩 에이전트화 및 지속적인 개발 세션: '컨텍스트 벽(Context Wall)' 문제를 해결하여, AI가 장시간 동안 프로젝트를 '기억'하고 일관성을 유지할 수 있게 함으로써 7, 단순한 코드 조각 완성을 넘어 시스템 수준의 이해를 갖춘 코딩 에이전트 역할을 수행합니다 .
접근성 확대 및 보안/규제 준수
DeepSeek V4는 소비자 하드웨어 및 로컬 배포를 통한 접근성 확대의 중요성을 강조합니다. 듀얼 NVIDIA RTX 4090 또는 싱글 RTX 5090과 같은 소비자용 하드웨어에서도 구동 가능하도록 설계되어 , 에어갭(air-gapped) 환경이나 엄격한 데이터 거버넌스 요구 사항을 가진 기업에서도 로컬 배포가 가능합니다 8. 이는 AI의 민주화를 추구하며 9, 오픈 소스 가중치(예상)와 소비자용 하드웨어 지원을 통해 폐쇄형 모델 제공업체에 대한 상당한 압력으로 작용할 수 있습니다 . 또한, 오픈 소스 및 소비자 하드웨어 호환성을 통해, 데이터 거버넌스 요구 사항이 엄격하거나 에어갭 환경이 필요한 개발 팀도 DeepSeek V4를 자체 인프라 내에서 활용할 수 있습니다 . 이는 보안 및 규제 준수가 중요한 산업 분야에서 AI 코딩 도구의 활용을 확장시킵니다 8.
결론: 딥시크 신규 모델에 대한 총평 및 전망
2026년 2월 출시될 예정인 딥시크의 차세대 AI 모델 DeepSeek V4는 코딩 중심의 장문 컨텍스트 대규모 언어 모델로서, 소프트웨어 개발 방식을 혁신할 잠재력을 지니고 있습니다 1. 특히 "수십만 개에서 거의 백만 개의 토큰"에 달하는 방대한 컨텍스트 창 지원은 AI 모델이 처리할 수 있는 정보량의 한계를 극복하며 새로운 지평을 열었다는 평가를 받습니다 .
DeepSeek V4의 100만 토큰 컨텍스트는 단순한 규모 확장을 넘어, 기존 대규모 언어 모델의 고질적인 기술적 한계를 혁신적으로 해결했다는 점에서 큰 의미를 가집니다. 기존 모델들이 컨텍스트 길이가 길어질수록 계산 복잡도가 O(N²)으로 급증하고 메모리 사용량이 폭증하는 문제 와, 관련 정보가 컨텍스트 중간에 있을 때 성능이 저하되는 'Lost in the Middle' 현상 에 시달렸던 것과 달리, DeepSeek V4는 Engram 조건부 메모리 아키텍처 , DeepSeek Sparse Attention (DSA) , MODEL1 아키텍처 , mHC (Manifold-Constrained Hyper-Connections) 등의 핵심 기술 혁신을 통해 이를 극복했습니다. 이 기술들은 효율적인 지식 조회, 계산 비용 절감, 메모리 최적화 등을 가능하게 하여, 100만 토큰 이상의 컨텍스트를 안정적이고 비용 효율적으로 처리할 수 있게 합니다 .
이러한 기술적 우위는 산업 전반에 걸쳐 상당한 파급 효과를 가져올 것입니다. 특히 개발자들에게는 대규모 코드베이스 전체를 한 번에 이해하고 처리하여, 리포지토리 수준의 리팩토링, 지능형 버그 탐지 및 수정, 그리고 장기간 일관성을 유지하는 AI 코딩 에이전트의 등장을 가능하게 함으로써 생산성의 혁명을 가져올 것입니다 . 또한, 백만 토큰당 $0.10에 불과한 경쟁력 있는 추론 비용 과 듀얼 NVIDIA RTX 4090과 같은 소비자용 하드웨어에서도 구동 가능한 접근성은 AI의 민주화를 가속화할 주요 요인으로 작용할 전망입니다.
DeepSeek V4는 Claude Opus 4.5의 200k 토큰, GPT-4o의 128k 토큰 등 현존하는 주요 LLM보다 월등히 긴 100만 개 이상의 컨텍스트를 제공하며 , 내부 테스트 결과 코딩 분야에서 Claude 및 OpenAI의 GPT 시리즈를 능가하는 성능을 보인다고 보고되었습니다 .
결론적으로, DeepSeek V4는 단순한 성능 향상을 넘어 AI가 소프트웨어 개발 및 복잡한 정보 처리 방식에 근본적인 변화를 가져올 수 있는 잠재력을 보여줍니다. 코딩 우선 모델 설계와 혁신적인 컨텍스트 기술을 통해, DeepSeek은 폐쇄형 모델 제공업체들에게 강력한 경쟁 우위를 점하며 5, AI 산업 내에서 소프트웨어 개발의 미래를 재정의하고 AI 모델의 접근성과 효율성을 크게 높이는 핵심적인 역할을 할 것으로 기대됩니다.