 Claude Sonnet 4.6 is now available in Atoms.
Claude Sonnet 4.6 is now available in Atoms.
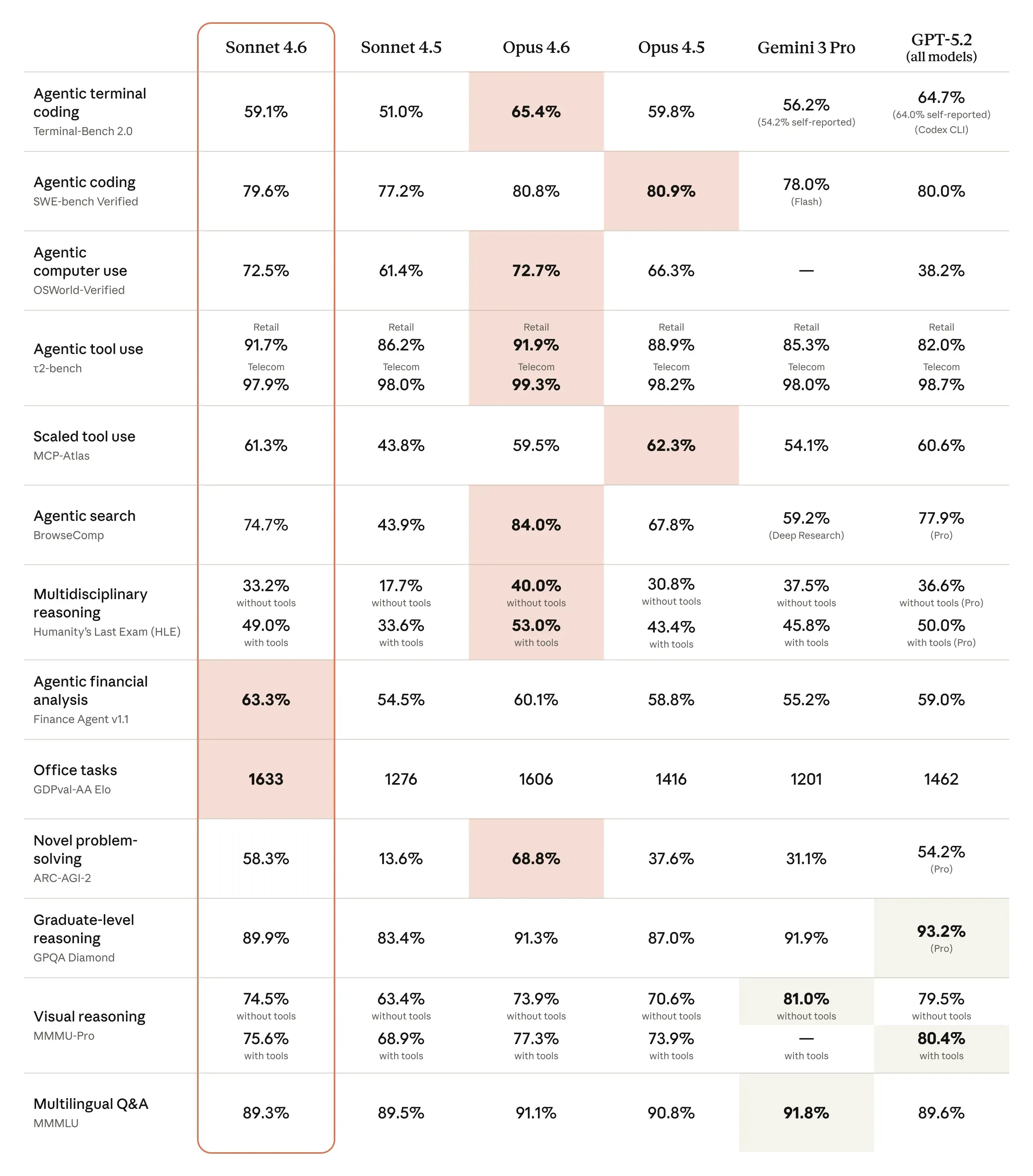
Anthropic positions Sonnet 4.6 as a full upgrade across coding, long-context reasoning, agent planning, office work, and “computer use,” with a 1M token context window in beta and Sonnet pricing that stays in the Sonnet tier (starting at $3 / $15 per million input / output tokens, per Anthropic’s announcement). See Introducing Claude Sonnet 4.6 for the official overview, and Claude Sonnet 4.6 now available in Amazon Bedrock for cloud availability context.
We ran our own evals before shipping. Here’s what we saw, where Sonnet 4.6 wins, and how to think about using it in production.
What “Sonnet 4.6” actually changes
There are three changes that matter if you build with LLMs every day.
First: instruction following becomes less fragile. You can spot this in code review, refactoring, and “do exactly X but don’t touch Y” edits. A model doesn’t need new tricks; it needs fewer unforced errors.
Second: the model is more economical with reasoning. Not “shorter answers.” Cleaner thinking paths: fewer steps, less looping, less verbal flailing before it commits to a plan. That shows up as latency and token cost.
Third: long-context isn’t just capacity, it’s usable context. A big window is pointless if retrieval degrades into mush halfway through a large repo. Anthropic explicitly calls out Sonnet 4.6’s improvements across long-context reasoning and planning in its release note (Anthropic’s Sonnet 4.6 announcement), and we care because Atoms users routinely paste “too much”: logs, specs, diffs, failing tests, and fragments of architecture decisions that matter.
If you want the short version: Sonnet 4.6 behaves more like a careful coworker and less like a chatbot that needs supervision.
Our internal results: c46s vs c46o
Internally we refer to Claude Sonnet 4.6 as c46s and Claude Opus 4.6 as c46o. We tested both, because “best” is always conditional: quality targets, runtime budget, and tolerance for retries.
Summary table (offline)
| Metric | c46s (Sonnet 4.6) | c46o (Opus 4.6) | Why it matters |
|---|---|---|---|
| Average score | 4.14 | 4.08 | Higher average with fewer disappointments |
| 4–5 score share | 85.71% | 82.54% | More “good or great,” fewer “almost” |
| Avg reasoning steps | 7.29 | 10.63 | Less wandering, faster convergence |
| Input tokens (avg) | 91,370.57 | 140,527.58 | Lower prompt + context processing cost |
| Output tokens (avg) | 20,861.95 | 18,375.23 | Slightly more verbose, but acceptable |
| Success rate | 100% | Not 100% (1 failure) | Reliability beats hero runs |
A few details worth calling out:
Quality: The average moved to 4.14, and the share of high scores (4–5) rose to 85.71%. That combination matters more than any single number: it signals fewer weak outputs you have to rewrite.
Aesthetics: Sonnet 4.6 ranked #1 in our aesthetics scoring. Translate that however you like—UI copy, layout sense, naming choices, formatting discipline—but the pattern is consistent: it produces outputs that require less “make it look professional” cleanup.
Efficiency: The average reasoning steps dropped from 10.63 → 7.29. That’s not just speed. It’s a proxy for focus: fewer detours, fewer self-contradictions, fewer mid-answer pivots.
Cost: We saw a large drop in input token consumption (140,527.58 → 91,370.57) and a modest increase in output tokens (18,375.23 → 20,861.95). Net effect: better total cost for the work we measured. In real usage, this also tends to reduce “context tax”—the penalty you pay when a model keeps rereading a long prompt to compensate for weak internal state tracking.
Stability: Sonnet 4.6 hit 100% success in our offline run: no failures, no “no score” cases. Opus had one failure. That gap is small, but it matters if you’re running eval harnesses or automations where a single failure breaks a job.
Product run: 32 datasets, 100% executability
Offline numbers are only half the story. We also ran a product-facing test set: 32 datasets, and Sonnet 4.6 achieved 100% executability.
“Executability” here is not a vibe score. It means the output is operationally usable in the workflow: steps are coherent, artifacts are produced in the right format, and the result can actually be run or applied without a second prompt that says “please fix the thing you just broke.”
We also did human spot checks on the same conversation slices we use for Opus. The result was consistent with the numbers: the best outputs weren’t louder, they were cleaner. Fewer incorrect assumptions. Better formatting discipline. Less rework.
Why Sonnet 4.6 is a strong default for Atoms users
In practice, most teams need a default model that behaves predictably at scale.
Sonnet 4.6 is a good default when your work looks like any of the following:
You’re doing iterative building: spec → draft → revise → implement → test → patch. Models fail here when they lose their own constraints or mutate requirements midstream.
You’re doing code review and debugging: the job is not to generate code. It’s to identify what’s wrong, propose minimal fixes, and explain risk. A model that invents details is worse than a model that refuses.
You’re doing multi-file refactors: the hard part is keeping changes consistent. Models that over-edit create merge conflicts you didn’t need.
You’re doing workflow automation: tool use, web tasks, “computer use” style actions. Anthropic explicitly highlights major improvements in computer use for Sonnet 4.6 (Sonnet 4.6 release note), and AWS echoes this positioning in its Bedrock availability update (AWS Bedrock announcement). Whether you use those capabilities directly or not, the underlying trait is what matters: stepwise reliability across longer sequences.
If you only care about the most difficult edge-case reasoning, Opus still has a place. But for the majority of “ship work,” Sonnet 4.6’s balance is hard to ignore.
How to evaluate Sonnet 4.6 without fooling yourself
If you want an honest model eval, don’t obsess over one benchmark. Build a harness that matches your work.
Here are the checks that tend to expose real differences quickly:
- Constraint retention: Does the model remember the key “do/don’t” rules after 20 turns?
- Minimal diffs: When asked to change one behavior, does it touch unrelated parts?
- Failure behavior: When it doesn’t know, does it ask a precise question—or guess?
- Consistency: Run the same task multiple times. Do you get the same class of answer, or random swings?
- Time-to-usable: Count how many turns it takes to get something you can ship.
The goal is not to crown a winner. The goal is to reduce rework. A model that scores slightly lower on a reasoning puzzle but saves you two review cycles is the better model.
Practical notes: prompt style that works better with Sonnet 4.6
You don’t need exotic prompts. You need fewer contradictions.
What tends to work well:
Write requirements as hard constraints, not suggestions. “Must” and “must not” are clearer than “try to.”
Ask for a plan plus an explicit diff strategy when editing code: what files change, what doesn’t change, and why.
When reviewing code, ask for evidence-based claims: “point to the line, the function, the failing test, the invariant.” It forces grounded reasoning.
If the task is long, structure the conversation so that the model can maintain state: recap decisions, list invariants, and keep a short “current goal” block. Even with longer context windows, good hygiene beats raw capacity.
Anthropic also describes updated controls and long-run features such as context compaction in its broader 4.6 line (Introducing Claude Opus 4.6). Even if you’re focused on Sonnet, the shared direction is clear: longer sessions, fewer collapses, better control over how much the model “thinks.”
What we shipped in Atoms, and what’s next
Sonnet 4.6 is now live in Atoms, and it passed both our offline evals and product run tests (32 datasets, 100% executability). The decision was simple: higher average quality, fewer reasoning steps, lower input token burn, and cleaner outputs in human spot checks.
If you’re already using Atoms, the best next step is not to “try it.” It’s to swap it into your real workflow and compare:
- How many turns until you can merge the change?
- How often do you need to restate constraints?
- How often do you have to roll back unintended edits?
If you want to share your own results, we’re especially interested in the failure cases: the tasks where Sonnet 4.6 still misses, and what signal would have helped it succeed. That’s how models become useful tools instead of expensive autocomplete.
