Análisis del Nuevo Modelo DeepSeek: Innovaciones Clave y el Salto al Contexto Extendido
Introducción al Nuevo Modelo DeepSeek
DeepSeek ha realizado anuncios oficiales detallando el lanzamiento de sus nuevos modelos, enfatizando la eficiencia, el rendimiento y la transparencia. El hito más reciente es el lanzamiento del DeepSeek V3.1-Terminus en marzo de 2025, destacándose como el primer modelo de código abierto de DeepSeek que soporta una impresionante ventana de contexto de un millón de tokens 1. Una actualización de este modelo fue anunciada el 22 de septiembre de 2025 2.
Este lanzamiento sienta las bases para el esperado DeepSeek V4, cuya llegada se anticipa para principios de 2026, con referencias comunes que lo sitúan en febrero de 2026 o alrededor del Año Nuevo Chino 3. Aunque el V4 se enfocará en el manejo de contexto largo, la capacidad de un millón de tokens se ha confirmado explícitamente para el V3.1-Terminus 3.
El DeepSeek V3.1-Terminus ha sido diseñado para procesar grandes volúmenes de información de manera eficiente y presenta las siguientes características clave:
- Capacidad de Contexto: Un millón de tokens, lo que equivale a la capacidad de procesar documentos extensos o secuencias de conversación de hasta 400 páginas, siendo ideal para resumir libros completos o analizar bases de conocimiento 1.
- Eficiencia: Muestra mejoras significativas en la eficiencia de inferencia y una reducción del 38% en las alucinaciones 1.
- Soporte Multilingüe: Compatibilidad con más de 100 idiomas 1.
- Código Abierto: Distribuido bajo licencia MIT, lo que proporciona la libertad para inspeccionar, modificar e integrar el modelo en proyectos comerciales, democratizando el acceso a tecnologías avanzadas de IA 4.
El Salto Cuántico en la Gestión de Contexto: DeepSeek V3.1-Terminus y el Futuro de los Un Millón de Tokens
El modelo DeepSeek V3.1-Terminus, lanzado entre el 22 y 29 de septiembre de 2025 5, representa una actualización significativa en las capacidades de los modelos de lenguaje grandes de DeepSeek. Esta versión busca refinar las capacidades existentes, centrándose en la consistencia del lenguaje y las habilidades de los agentes de IA 5. En particular, la capacidad de su ventana de contexto ha sido un punto clave de discusión.
Ventana de Contexto de DeepSeek V3.1-Terminus: 128.000 Tokens
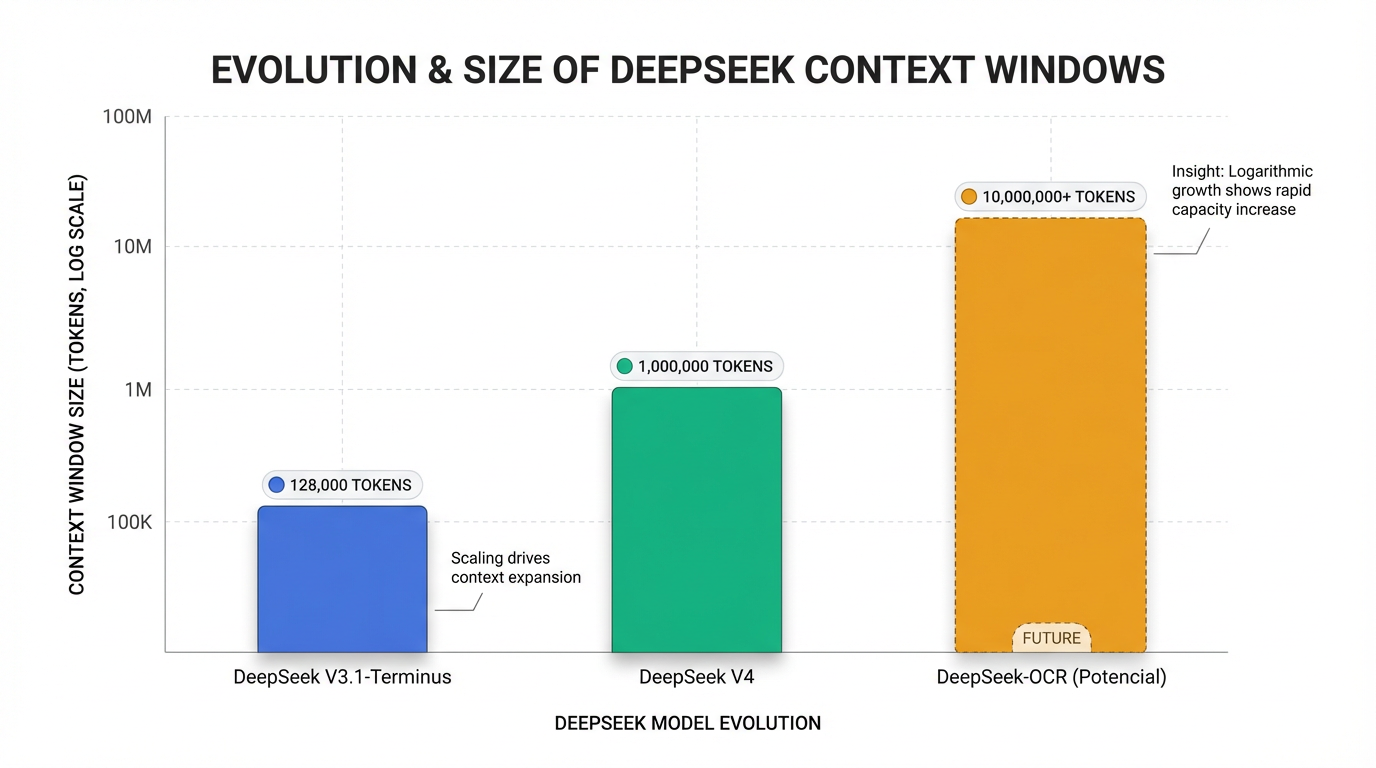
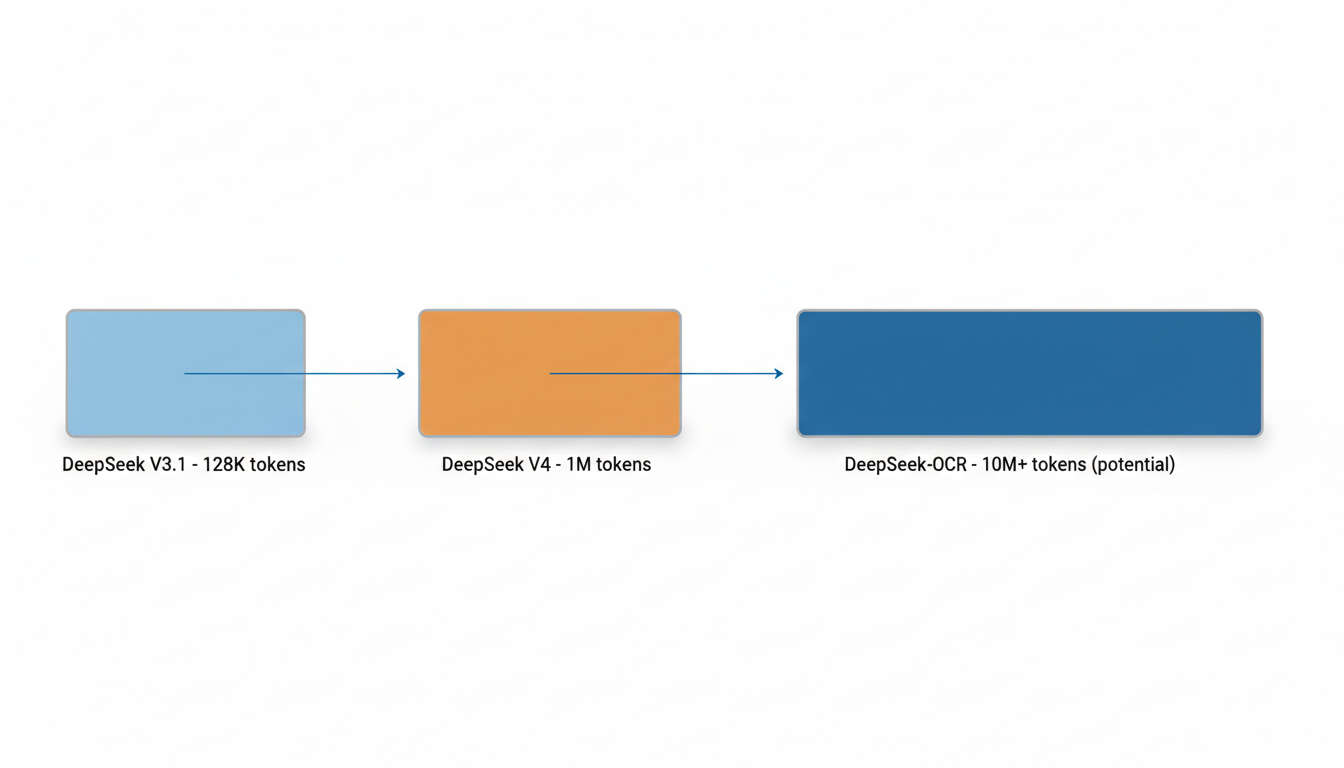
DeepSeek V3.1-Terminus, en sus modos "pensante" (deepseek-reasoner) y "no pensante" (deepseek-chat), posee una ventana de contexto de 128.000 tokens . Esta capacidad es considerable, equivalente a entre 300 y 400 páginas de texto en una única interacción 6 o aproximadamente 192 páginas A4 con fuente Arial tamaño 12 . Esto duplica la capacidad de su predecesor V3.0, que era de 64.000 tokens 7. Cabe destacar que algunas plataformas de terceros, como Kilo Code y Fireworks AI, han reportado una ventana de contexto de 163.840 tokens para DeepSeek V3.1 Terminus en sus integraciones , aunque los anuncios oficiales de DeepSeek para V3.1 y V3.1-Terminus mencionan explícitamente 128.000 tokens .
Los beneficios de una ventana de contexto de 128.000 tokens son amplios:
- Procesamiento de Documentos Largos: Permite al modelo procesar textos extensos y conversaciones coherentes, como novelas completas o documentos técnicos detallados, facilitando el análisis y la síntesis de información compleja .
- Capacidades de Agente Mejoradas: Es crucial para agentes de programación que necesitan "leer" repositorios de código completos para tareas como refactorización, identificación de errores o implementación de nuevas funcionalidades 8.
- Razonamiento y Comprensión Profunda: Permite al modelo comprender, resumir o analizar textos más largos, manteniendo el contexto general a lo largo de interacciones complejas sin perder el hilo de la conversación o los datos presentados .
El Salto al Millón de Tokens: DeepSeek V4
La expectativa de una ventana de contexto de un millón de tokens no se aplica a DeepSeek V3.1-Terminus, sino que es una característica distintiva del futuro modelo DeepSeek V4. Se ha mencionado ampliamente que DeepSeek V4 contará con esta capacidad excepcional . Su lanzamiento se esperaba para principios de 2026, específicamente entre el primer trimestre y febrero, con informes de su uso ya a finales de enero de 2026 .
DeepSeek V4 se posiciona como un modelo fundamental de próxima generación, diseñado para el razonamiento de grado de producción, ingeniería de software avanzada y sistemas multimodales 9. Se espera que este modelo cuente con un billón de parámetros y tres innovaciones arquitectónicas clave: Manifold-Constrained Hyper-Connections, Engram conditional memory y Sparse Attention. Estas innovaciones podrían redefinir la economía de la IA, apuntando a puntajes superiores al 80% en SWE-bench con un costo de inferencia entre 10 y 40 veces menor que el de sus competidores occidentales 10.
El impacto potencial de un contexto de un millón de tokens es transformador. Permite una integración sin precedentes de información, desde bases de conocimiento enteras hasta extensos códigos fuente, sin la necesidad de resumir agresivamente o enfocarse solo en la información "caliente". A diferencia de los modelos con 128K tokens, que llevan a los usuarios a ser más selectivos con la información, una ventana de 1M tokens permite incluir archivos "fríos" o de contexto secundario, mejorando la coherencia y la exhaustividad de las respuestas .
Más Allá del Millón: El Potencial de DeepSeek-OCR
Mirando hacia el futuro, DeepSeek también está explorando formas de expandir aún más las ventanas de contexto. Una técnica innovadora desarrollada por DeepSeek, llamada DeepSeek-OCR, convierte texto en imágenes para una compresión de datos visuales hasta 10 veces más eficiente que los tokens de texto estándar 11. Esta aproximación está allanando el camino para modelos con ventanas de contexto de 10 millones, 20 millones o incluso más tokens, lo que sugiere una dirección futura para una capacidad de contexto verdaderamente masiva 11.
La siguiente tabla resume las ventanas de contexto de los modelos DeepSeek actuales y futuros:
| Modelo | Ventana de Contexto | Estado | Fecha de Lanzamiento/Anuncio |
|---|---|---|---|
| DeepSeek V3.1-Terminus | 128.000 tokens | Lanzado | Septiembre de 2025 |
| DeepSeek V3.1-Terminus (Fireworks AI/Kilo Code) | 163.840 tokens | Integración de terceros | Septiembre de 2025 |
| DeepSeek V4 | 1.000.000 tokens | Lanzado/Anunciado | Principios/Mediados de Febrero de 2026 |
| DeepSeek-OCR (Técnica) | Potencial de 10-20 millones+ tokens | En desarrollo/Investigación | Febrero de 2026 (publicación) |
En resumen, la discrepancia inicial entre la expectativa de un millón de tokens y la capacidad actual se debe a que DeepSeek V3.1-Terminus, aunque potente con 128.000 tokens, no es el modelo que ofrece esta capacidad. El verdadero "salto cuántico" al millón de tokens es una característica del anticipado y ya lanzado DeepSeek V4 , con desarrollos como DeepSeek-OCR prometiendo magnitudes aún mayores en el futuro.
Otras Características Innovadoras y Mejoras Clave
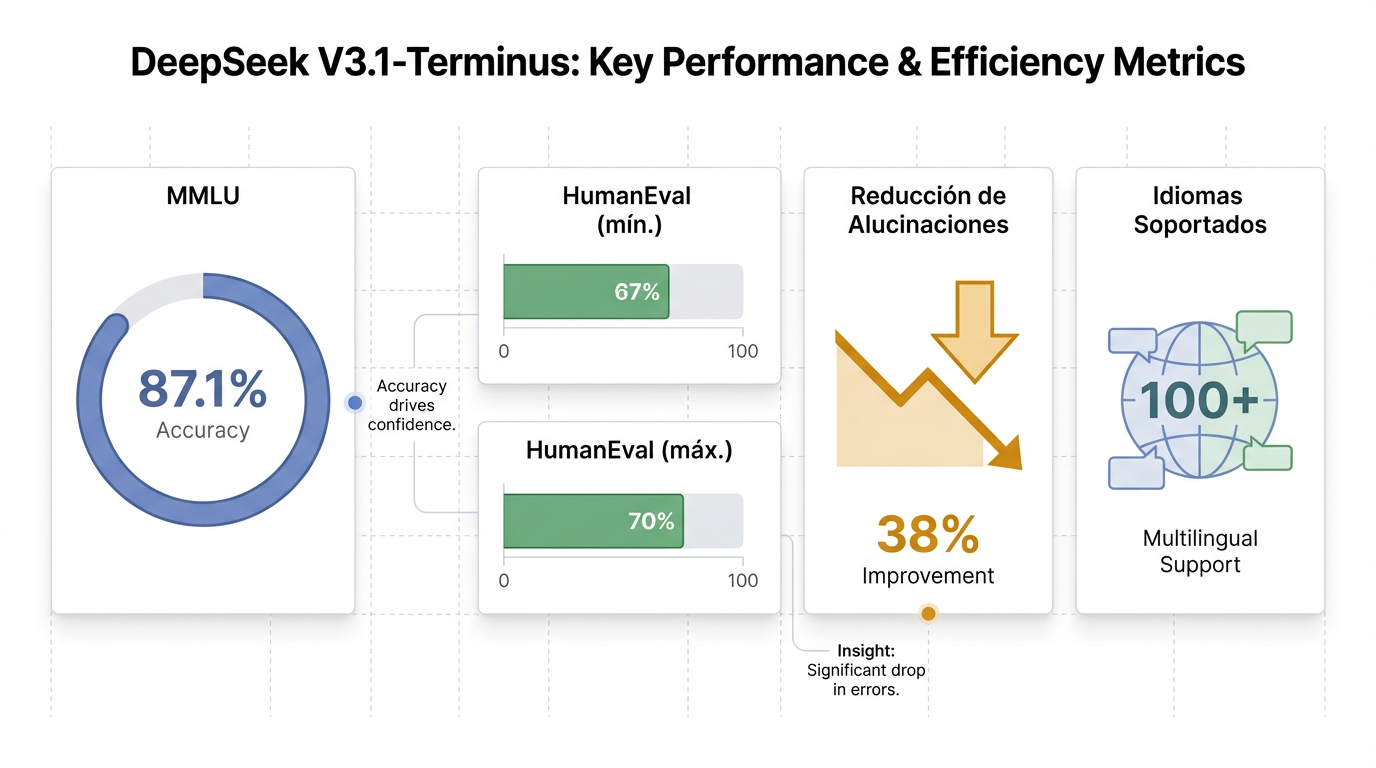
Más allá de su impresionante capacidad de manejo de contexto extendido, el modelo DeepSeek V3.1-Terminus introduce una serie de mejoras y características clave que lo posicionan como una herramienta de IA altamente competitiva y versátil. Se ha logrado una significativa mejora en la eficiencia de inferencia, acompañada de una notable reducción del 38% en las alucinaciones, lo que contribuye a una mayor fiabilidad de sus resultados 1.
El soporte multilingüe es otra de sus fortalezas, ya que el modelo es compatible con más de 100 idiomas, ampliando su aplicabilidad a una audiencia global 1. En cuanto al rendimiento, V3.1-Terminus ha demostrado resultados destacados en benchmarks críticos, obteniendo un formidable 87.1% en MMLU y entre un 67% y 70% en HumanEval, lo que subraya su capacidad en diversas tareas 1.
Un pilar fundamental de la estrategia de DeepSeek es su compromiso con el código abierto. El modelo V3.1-Terminus se distribuye bajo una licencia MIT, lo que no solo permite la inspección y modificación por parte de la comunidad, sino que también facilita su integración en proyectos comerciales y democratiza el acceso a estas avanzadas tecnologías de IA 4.
Finalmente, el diseño de este modelo está optimizado para la era de los agentes, mejorando la eficacia en el uso de herramientas y en agentes de código y búsqueda 4. Para ello, opera en modos duales: deepseek-chat para proporcionar respuestas rápidas y deepseek-reasoner para ejecutar razonamientos más profundos 2.
Impacto y Posicionamiento en el Ecosistema de la IA
DeepSeek V3.1-Terminus, lanzado entre el 22 y 29 de septiembre de 2025 5, se ha posicionado rápidamente como un desafiante clave frente a la dominación de los gigantes de la IA propietarios. Su estrategia de código abierto, combinada con un rendimiento de frontera a una fracción del costo, busca establecer un nuevo estándar de accesibilidad en la inteligencia artificial, alterando la dinámica de la competencia global 12.
Rendimiento y Costo-Eficiencia: Comparativa con Líderes del Mercado
DeepSeek V3.1-Terminus exhibe un rendimiento competitivo, desafiando directamente a los sistemas propietarios estadounidenses 12. En comparación con su versión base, el modelo Terminus muestra mejoras en áreas clave como el razonamiento y el conocimiento (MMLU-Pro y GPQA-Diamond) y una mejora notable en el razonamiento de casos límite ("Humanity's Last Exam"). También destaca por un avance significativo en el uso de herramientas de agente, particularmente en tareas de navegación (BrowseComp), respuesta a preguntas sencillas (SimpleQA), ingeniería de software (SWE Verified) y manejo de la línea de comandos (Terminal-bench). Sin embargo, se observa una ligera regresión en desafíos de codificación competitiva (Codeforces) y en el benchmark de navegación en chino (BrowseComp-zh) .
| Benchmark | DeepSeek V3.1 | DeepSeek V3.1-Terminus | Notas |
|---|---|---|---|
| MMLU-Pro | 84.8 | 85.0 | Mejora ligera en razonamiento y conocimiento |
| GPQA-Diamond | 80.1 | 80.7 | Mejora ligera en conocimiento avanzado |
| Humanity's Last Exam | 15.9 | 21.7 | Mejora notable en razonamiento de casos límite |
| LiveCodeBench | 74.8 | 74.9 | Sin diferencia significativa en codificación por razonamiento puro |
| Codeforces | 2091 | 2046 | Leve regresión en desafíos de codificación competitiva |
| Aider-Polyglot | 76.3 | 76.1 | Caída insignificante |
| Uso de Herramientas de Agente | |||
| BrowseComp | 30.0 | 38.5 | Gran mejora en tareas de navegación y razonamiento |
| BrowseComp-zh | 49.2 | 45.0 | Regresión en el benchmark de navegación en chino |
| SimpleQA | 93.4 | 96.8 | Mejora en respuesta a preguntas sencillas con herramientas |
| SWE Verified | 66.0 | 68.4 | Mejora sólida en tareas de ingeniería de software |
| SWE-bench Multilingual | 54.5 | 57.8 | Mejora en resolución de errores de código multilingüe |
| Terminal-bench | 31.3 | 36.7 | Gran avance en tareas de interfaz de línea de comandos |
Frente a otros modelos líderes, DeepSeek V3.1 ha logrado una tasa de éxito del 71,6% en desafíos de programación (benchmark Aider), superando ligeramente a Claude Opus 4, a la vez que era aproximadamente 68 veces más económico 7. En comparación con GPT-4, DeepSeek-V3 es aproximadamente 214,3 veces más barato en costos de tokens de entrada/salida. Además, DeepSeek-V3 supera a GPT-4 en HumanEval (82.6% vs 67%) y MMLU (88.5% vs 86.4%) 13. Sin embargo, GPT-4 mantiene la ventaja en HellaSwag (95.3% vs 88.9%) y ofrece procesamiento de imágenes, capacidad de la que carece DeepSeek-V3 13. Es importante señalar que la ventana de contexto de DeepSeek V3.1-Terminus (128.000 tokens) es significativamente menor que la de otros competidores como GPT-5 (256.000 tokens), Gemini 2.5 Pro (1 millón de tokens) y Grok 4 Fast (2 millones de tokens) .
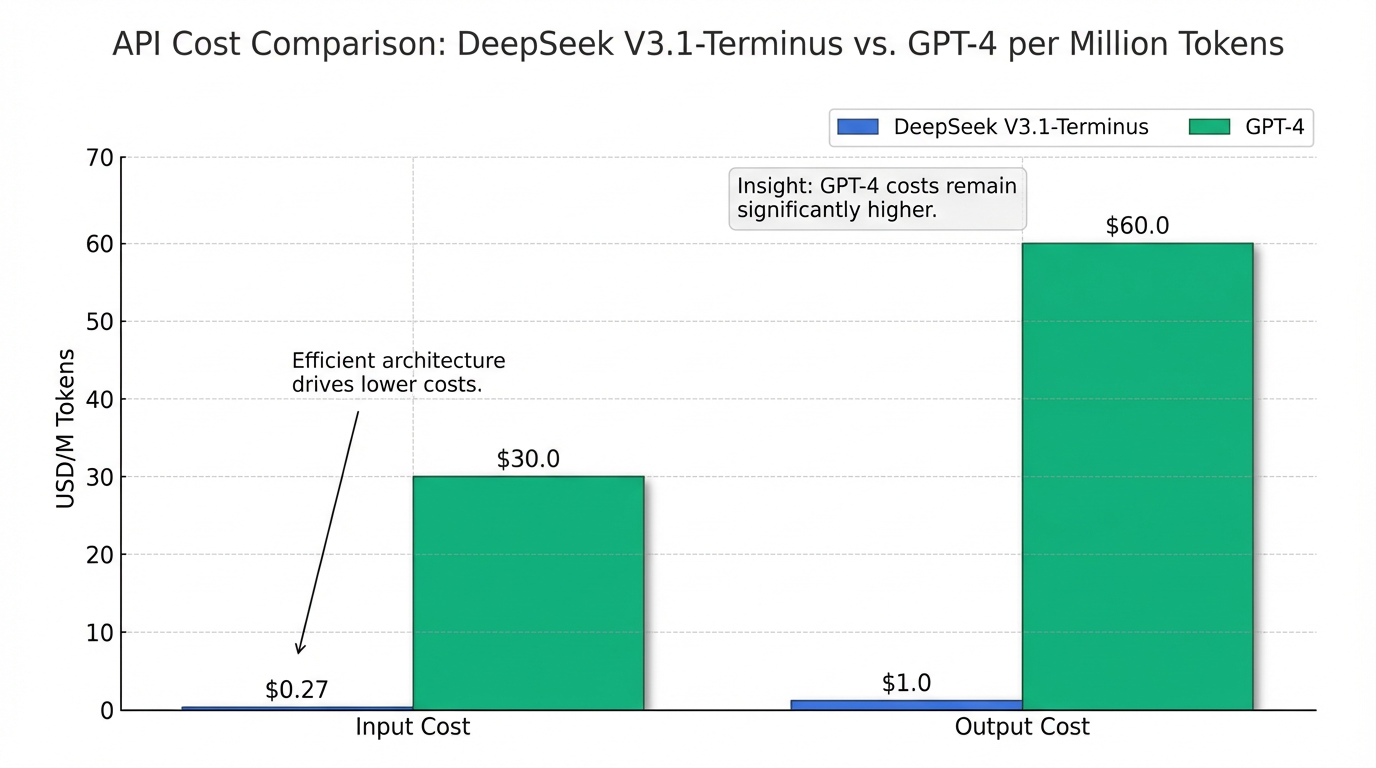
Los costos de la API de DeepSeek V3.1-Terminus son notablemente bajos, con aproximadamente $0,27 por millón de tokens de entrada y $1,0 por millón de tokens de salida para su versión serverless . Esto contrasta fuertemente con los costos de GPT-4, que alcanzan los $30,00 de entrada y $60,00 de salida por millón de tokens 13.
La Estrategia de Código Abierto: Ventajas y Desafíos
La distribución de DeepSeek V3.1-Terminus bajo la permisiva Licencia MIT 5 permite su uso comercial y modificación 12, lo que ha sido elogiado como un "cambio de juego" en la comunidad de IA 7.
Ventajas:
- Accesibilidad y Costo Reducido: La licencia MIT y la disponibilidad de los pesos del modelo permiten a empresas y desarrolladores implementar y adaptar el modelo localmente, reduciendo costos y la dependencia de proveedores externos .
- Transparencia y Control: Ofrece control total sobre la implementación y permite la inspección del modelo, evitando la naturaleza de "caja negra" de las soluciones propietarias .
- Fomento de la Innovación: Su enfoque de código abierto desafía los modelos de negocio cerrados y fomenta la colaboración y la innovación en el ecosistema de la IA, especialmente para aquellos con recursos limitados .
Desafíos y Preocupaciones:
- Requisitos de Hardware: El tamaño considerable del modelo (700 GB) implica barreras prácticas para el autoalojamiento, requiriendo recursos computacionales y experiencia significativos .
- Seguridad y Alineación: El Centro para Estándares e Innovación en IA (CAISI) del NIST estadounidense ha expresado preocupaciones sobre la susceptibilidad de los modelos DeepSeek a ataques de "agent hijacking" (12 veces más) y su respuesta al 94% de las peticiones maliciosas en pruebas de jailbreaking, frente al 8% de los modelos estadounidenses 2. También se ha señalado que estos modelos reproducen narrativas favorables al Partido Comunista Chino con mayor frecuencia 2. Esto genera inquietudes sobre seguridad y alineación para empresas occidentales, que requieren una debida diligencia geopolítica .
- Soporte Empresarial: Las empresas occidentales pueden preferir proveedores nacionales que ofrezcan plataformas integradas y soporte y seguridad de nivel empresarial 12.
Posicionamiento Estratégico y Reacciones de la Comunidad
DeepSeek V3.1-Terminus ha sido diseñado específicamente para la "era de los agentes", incorporando mejoras significativas en el uso de herramientas y las capacidades de los agentes de código y búsqueda . Su compatibilidad con el formato de precisión FP8, optimizado para los chips de IA chinos de próxima generación, posiciona estratégicamente a DeepSeek para un uso generalizado en la infraestructura de IA emergente de China, reduciendo la dependencia de la tecnología de GPU estadounidense 7.
La comunidad de IA ha reaccionado con entusiasmo ante DeepSeek V3.1 y Terminus. Los probadores iniciales de Reddit y Hacker News se mostraron impresionados, especialmente con sus capacidades de codificación y la relación "costo/rendimiento es una locura" 7. Sam Altman, CEO de OpenAI, incluso ha reconocido que la competencia de modelos de código abierto chinos como DeepSeek ha influido en la decisión de OpenAI de liberar sus propios modelos de código abierto 12. Sin embargo, se reportaron críticas iniciales sobre la ignorancia de partes de la entrada o respuestas sin sentido de DeepSeek V3.1 en ciertos escenarios . La actualización Terminus abordó estas críticas mejorando la consistencia del lenguaje, reduciendo la mezcla de texto en chino e inglés y eliminando caracteres anormales .
El Futuro del Contexto: Hacia un Millón de Tokens y Más Allá
A pesar de que DeepSeek V3.1-Terminus cuenta con una robusta ventana de contexto de 128.000 tokens , el interés de la comunidad se ha centrado en la promesa de modelos con una capacidad aún mayor. Es importante aclarar que DeepSeek V3.1-Terminus, incluyendo sus versiones "Reasoning" y "Non-reasoning", tiene oficialmente una ventana de contexto de 128.000 tokens . Sin embargo, la expectativa de un millón de tokens se asocia principalmente con la próxima generación de modelos de la compañía.
DeepSeek ha anunciado y, según los informes, ha lanzado una versión con una ventana de contexto de un millón de tokens: DeepSeek V4. Se esperaba su lanzamiento a principios de 2026, específicamente entre el primer trimestre y febrero , con informes de su uso datando de finales de enero de 2026 . DeepSeek V4 se posiciona como un modelo fundamental para el razonamiento de grado de producción y la ingeniería de software, buscando redefinir la economía de la IA con un costo de inferencia significativamente menor . Además, la técnica innovadora DeepSeek-OCR, que convierte texto en imágenes para una compresión de datos visuales más eficiente, está allanando el camino para modelos con ventanas de contexto de 10 millones, 20 millones o incluso más, señalando una dirección futura hacia capacidades de contexto aún mayores 11. La comunidad de la IA espera futuras actualizaciones, incluyendo posibles versiones DeepSeek V4 y R2 (el sucesor de DeepSeek R1) 6.
| Modelo | Ventana de Contexto (Oficial/Estimado) | Estado | Fecha de Lanzamiento/Anuncio |
|---|---|---|---|
| DeepSeek V3.1-Terminus | 128.000 tokens | Lanzado | Septiembre de 2025 |
| DeepSeek V3.1-Terminus (Fireworks AI/Kilo Code) | 163.840 tokens | Integración de terceros | Septiembre de 2025 |
| DeepSeek V4 | 1.000.000 tokens | Lanzado/Anunciado | Principios/Mediados de Febrero de 2026 |
| DeepSeek-OCR (Técnica) | Potencial de 10-20 millones+ tokens | En desarrollo/Investigación | Febrero de 2026 (publicación) |