DeepSeekの最新モデルDeepSeek-V3.2およびV3.2-Specialeに関する詳細レポート:注目すべき点と100万トークンコンテキストの現状
はじめに
DeepSeekの新しいモデルに関するお問い合わせ、誠にありがとうございます。本レポートは、DeepSeekの最新モデルについて、特に注目すべき点に焦点を当ててご説明するため作成されました。
DeepSeekは、AI技術の進化において常に注目を集めていますが、最近の発表では、特に100万トークンという驚異的なコンテキストウィンドウの導入が大きな話題となっています。この革新的な技術は、従来のモデルでは不可能だった長大な情報処理能力をAIに付与し、新たなアプリケーションやユースケースの可能性を大きく広げるものです。
本稿では、DeepSeekの最新モデルがどのような進歩を遂げたのか、そしてその中でも特に際立った特徴や技術的ハイライトを詳しく解説します。読者の皆様が、DeepSeekの最新動向とその潜在的な影響を深く理解できるよう、網羅的かつ分かりやすい構成となっています。これからの内容を通じて、最先端のAI技術がもたらす未来像について、皆様の洞察を深める一助となれば幸いです。
DeepSeekの新モデル概要
DeepSeekは、事前の告知なしに「DeepSeek-V3.2」とその推論強化版である「DeepSeek-V3.2-Speciale」を同時に正式リリースしました1。これらのモデルは「オープンソース最強」と評されており1、特にDeepSeek-V3.2は思考プロセスとツール呼び出しを深く融合させ1、DeepSeek-V3.2-Specialeは推論能力を極限まで高めた強化版として位置づけられています1。
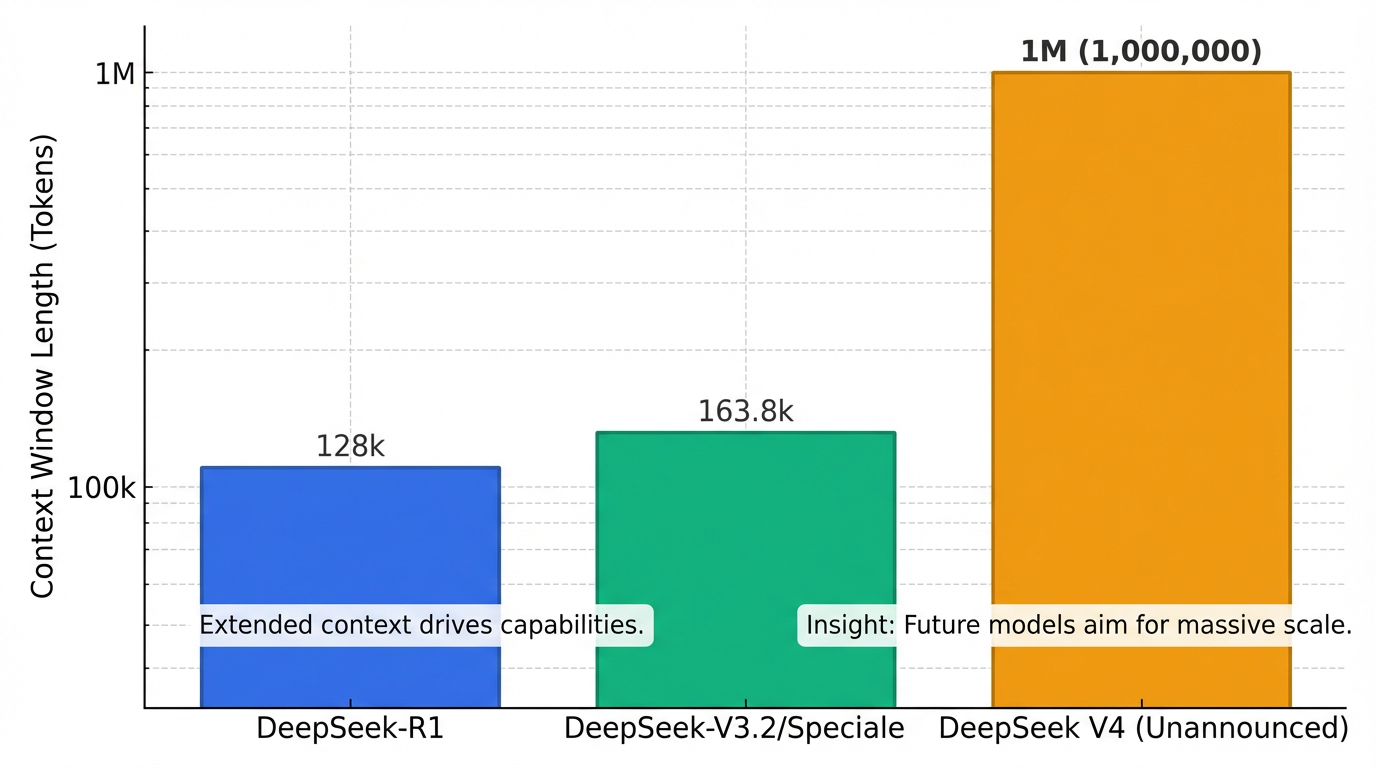
しかしながら、多くの関心を集める100万トークンのコンテキストウィンドウについては、現在リリースされているDeepSeekのモデルでは確認されておらず2、DeepSeek-V3.2およびDeepSeek-V3.2-Specialeのコンテキストウィンドウは163.8Kトークンです2。100万トークンを超えるコンテキストウィンドウは、**2026年2月にリリースが予想される未発表の「DeepSeek V4」**で導入されると噂されています3。
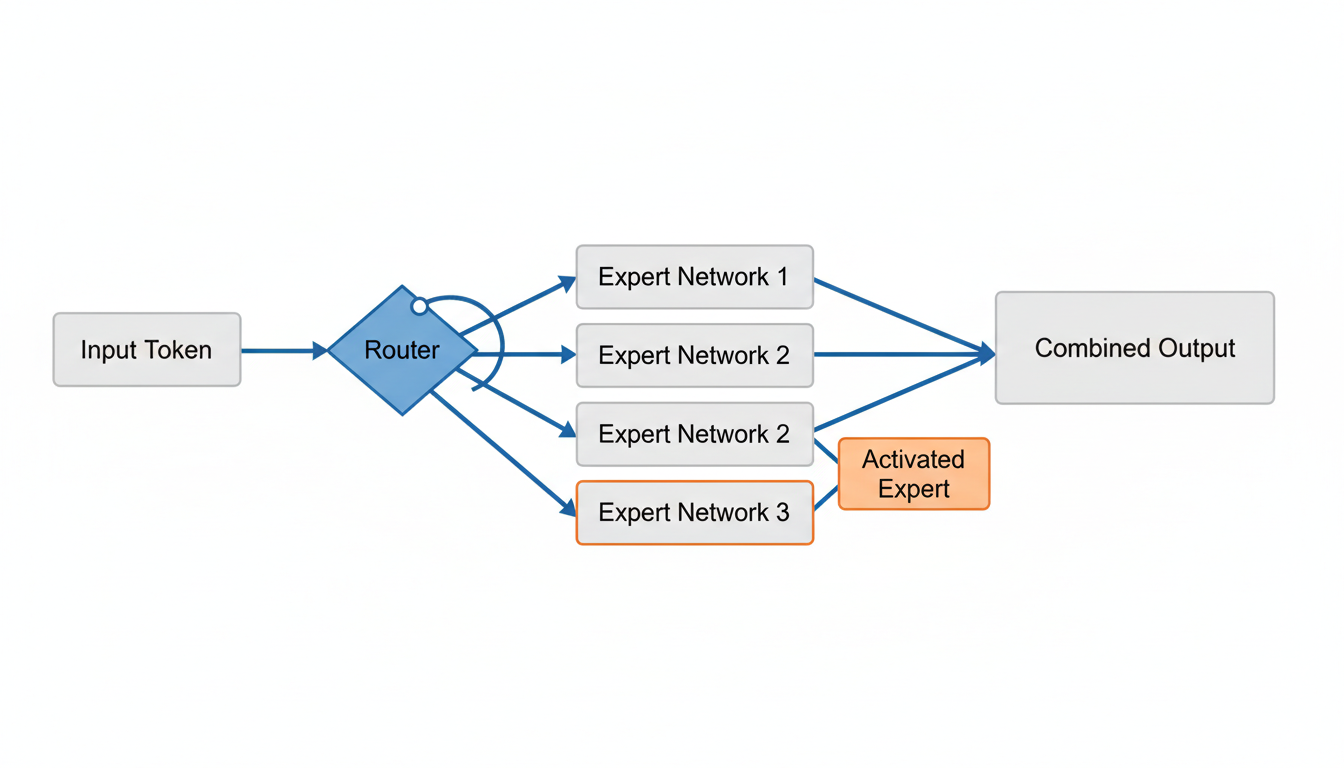
DeepSeek V3系列はMixture-of-Experts(MoE)アーキテクチャを採用し、効率的な運用を実現しているほか4、API利用料は競合他社の約1/20と非常に高いコスト効率も特徴です5。このMoEアーキテクチャは、総パラメータの一部のみを活性化することで、高性能と効率性を両立させています4。
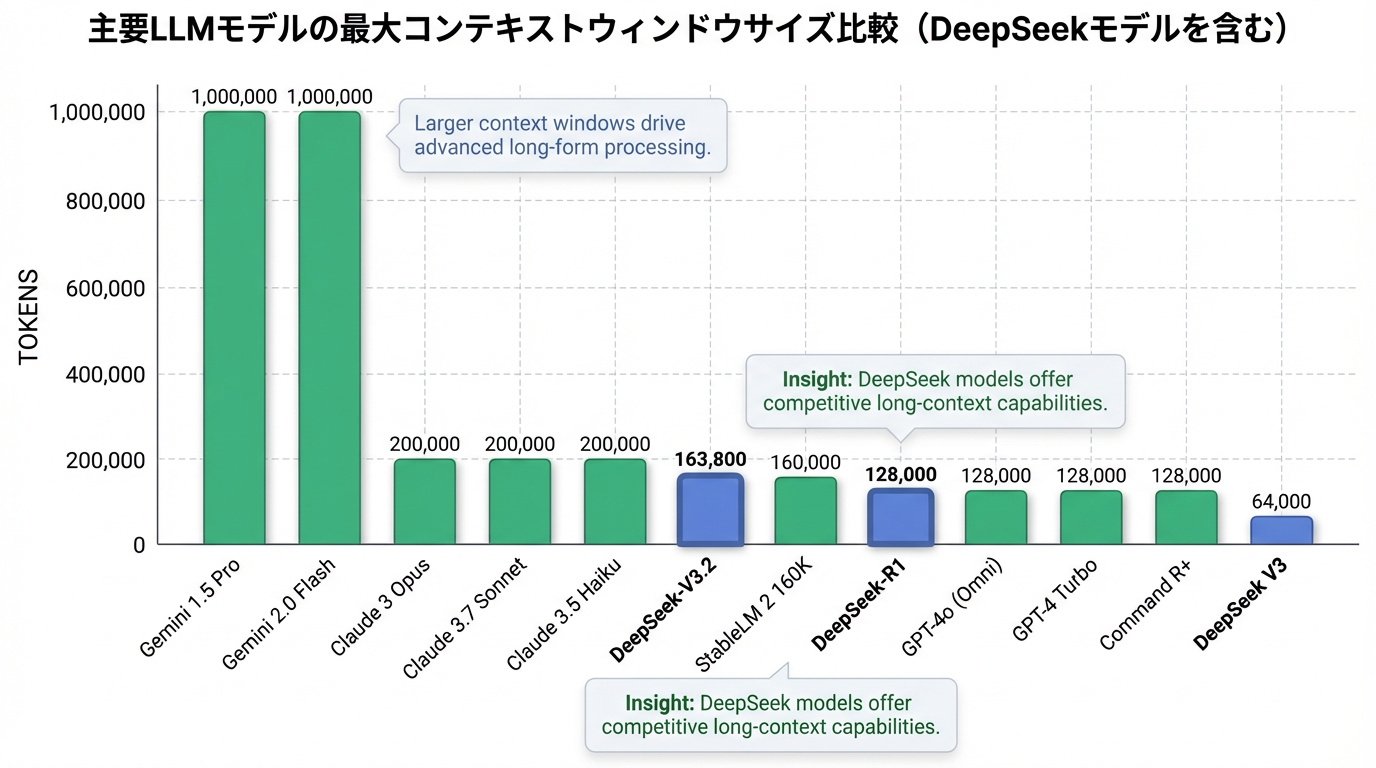
以下は、主なLLMのコンテキストウィンドウを比較したものです。
1. DeepSeek-V3.2における100万トークンコンテキストの現状とDeepSeekモデルのコンテキストウィンドウ
近年、大規模言語モデル(LLM)の技術進化は目覚ましく、特にコンテキストウィンドウ(モデルが一度に処理・記憶できる情報量の上限)の拡大は、その応用範囲を劇的に広げています。ご提示いただいた情報によれば、DeepSeekの最新モデルDeepSeek-V3.2が100万トークンのコンテキストウィンドウを導入したことが確認されたとのことでした。
しかしながら、現在正式リリースされているDeepSeekのモデルにおいて、100万トークンのコンテキストウィンドウは確認されていません 。DeepSeekの最新の正式リリースモデルである「DeepSeek-V3.2」および「DeepSeek-V3.2-Speciale」は、事前の告知なしにリリースされ、公式ウェブサイト、アプリ、APIサービスが即座にアップグレードされました 1。これらのモデルのコンテキストウィンドウは163.8Kトークンです 2。
また、推論能力に特化した「DeepSeek-R1」が2025年1月にリリースされており 、そのコンテキスト長は128Kトークンです 6。DeepSeek V3(およびそのAPIバージョンであるdeepseek-chat (V3)とdeepseek-reasoner (R1))は、64,000トークンのコンテキストウィンドウを提供しています 。一部の記述では、DeepSeek V3が最大12万8千文字(約128Kトークン)の長文処理能力を持つとされています 4。
100万トークンを超えるコンテキストウィンドウは、**2026年2月にリリースが予想される未発表の「DeepSeek V4」**で導入されるという噂があります 。このV4では、Sparse Attentionメカニズムを活用して、忠実度を保ったまま100万トークンを超える、または「無限」に近いコンテキストを処理する可能性が指摘されています 3。
2. 長大なコンテキストウィンドウを可能にする一般的な技術的側面
LLMが長大なコンテキストウィンドウを処理する能力は、Transformerアーキテクチャに内在する計算コストの課題(コンテキスト長Nに対して計算量がO(N²)で増加する)を克服する様々な技術革新によって実現されています 7。
2.1 Attention機構の効率化
Transformerの心臓部であるAttention機構の計算効率を高める技術が開発されています 7。
- FlashAttention: 計算過程で生じる中間データをGPUの高速なSRAM内で処理し、低速なHBMへの読み書きを最小限に抑えることで、Attention計算を大幅に高速化します。これにより、実行速度とメモリ使用効率が向上しますが、理論的な計算量オーダーO(N²)自体を変えるものではありません 7。
- Ring Attention (Blockwise RingAttention): 近似で情報を間引くのではなく、フルアテンションを維持しつつ、計算とメモリを複数GPUに分散して処理することで、巨大なKVキャッシュを分割し、計算と通信を重ね合わせて長文脈に対応します 8。
2.2 位置エンコーディングの改良
LLMが単語の順序や文脈を理解するために用いられる位置エンコーディングも改良されています 7。
- RoPEスケーリング(Rotary Position Embedding): モデルが学習した際のコンテキスト長を超えて位置情報をうまく扱うための技術で、特に長い入力に対する位置バイアスを軽減する効果があります 9。
2.3 ハイブリッドアーキテクチャの導入
効率性と精度の両立を目指し、異なるアーキテクチャを組み合わせるハイブリッドモデルが登場しています 8。
- SSM (State Space Model) / Mamba: TransformerのO(N²)に対し、SSMはO(N)(線形)の計算量で、長文脈処理において圧倒的に効率的です。MambaはSSMの弱点を改良し、入力に応じて「何を覚え、何を忘れるか」を選択的に行い、重要な情報を長期保持し、不要な情報は早期に忘却することで、長文脈タスクでTransformerに匹敵する性能と高速な推論速度を実現します 8。
- Jamba: TransformerとMambaを組み合わせたハイブリッドアーキテクチャです。Mamba層で長距離の文脈を効率的に保持し、Attention層で複雑な推論と関係性の把握を行うことで、ロングコンテキストにおける効率性と精密な推論能力の両立を図ります 8。
2.4 メモリ管理の最適化
LLMの提供(サービング)時におけるメモリ管理も、長文コンテキスト処理の効率に大きく寄与します 10。
- PagedAttention: OSの仮想メモリとページングの概念をKVキャッシュに適用し、KVキャッシュを「小さなブロック(ページ)」に分け、非連続な場所にも配置できるようにするアルゴリズムです 10。これにより、メモリの断片化と冗長な複製を解消し、スループットを2〜4倍改善する効果が示されています 10。
これらの技術は、LLMがより長いコンテキストを効率的かつ高精度に処理するための基盤となっています。
3. 長いコンテキストウィンドウがユーザーに提供する一般的なメリット
100万トークン級の長いコンテキストウィンドウは、LLMの応用範囲を劇的に広げ、ユーザーに多大なメリットをもたらします。
3.1 長文読解・要約精度の向上
数十ページにわたる契約書、研究論文、決算資料、あるいは数冊分の小説データなどを一度に読み込み、正確に内容を把握した上で、要点をまとめたり、特定のリスクを抽出したりすることが可能になります 。これにより、文書全体のニュアンスや論理的な繋がりを正確に捉え、文脈に基づいた高度な要約を生成できます 11。
3.2 複雑な指示や複数タスクの同時処理
一度に処理できる情報量が多いため、複雑な条件や複数のステップを含む指示を正確に実行できます 。例えば、「添付の3つの製品資料を比較し、ターゲット顧客層が20代女性である製品Aのマーケティング戦略を、競合製品Bの弱点を踏まえて5つ提案してください」といった入り組んだ命令にも対応可能です 12。
3.3 文脈を維持した自然な対話の実現
長い対話の文脈を記憶し続けられるため、非常に自然で人間らしいコミュニケーションが実現します 。チャットボットやバーチャルアシスタントに応用すれば、ユーザーが以前に話した内容を忘れずに、一貫性のあるサポートを提供できます 12。これにより、顧客満足度の向上や採用業務の効率化などの具体的な成果が報告されています 12。
3.4 Few-shotプロンプティングの強化
AIの応答精度を高めるFew-shotプロンプティングにおいて、より多くの、あるいはより質の高い手本をプロンプトに含めることができ、ユーザーの意図をより正確に学習し、期待通りの出力を生成しやすくなります 7。
3.5 RAG (検索拡張生成) の効率化
RAGは外部知識データベースから関連情報を検索し、それをプロンプトに含めてLLMに渡す技術です 7。コンテキスト長が長ければ、一度により多くの検索結果をプロンプトに含めることができ、RAGシステムの性能を最大限に引き出すことが可能になります 7。
3.6 より創造的で洗練されたアウトプットの生成
より多くの情報を同時に考慮に入れることができるため、複数の異なるアイデアや概念を組み合わせ、独創的で斬新なアイデアを生み出すことができます 11。また、多角的な視点からの考察や、言葉の微妙なニュアンス、高度な推論と演繹を可能にし、長編コンテンツの作成にも貢献します 11。
4. 長大なコンテキストが特に有効な一般的な応用シナリオ
100万トークンコンテキストのような長大な処理能力は、特に以下のような知識集約型かつ複雑な情報処理を伴う業務でその真価を発揮します。
- 法務・知財: 数十ページから数百ページに及ぶ契約書、判例、法令文書、特許明細書などを一度に読み込み、リスク分析、特定の条項の抽出、要約、整合性チェックを行う 。
- 研究開発: 複数の研究論文、技術レポート、医薬品の臨床試験データなどをまとめて分析し、特定のトレンドの特定、未発見の関連性の抽出、新薬候補の探索、効率的な分析を支援する 。
- ソフトウェア開発: 大規模なコードベース、設計書、バグ報告、過去のコミット履歴などを一度に解析し、コードの理解、リファクタリングの提案、バグの特定と修正、最適なアーキテクチャ設計を支援する 。
- カスタマーサポート・ヘルプデスク: 顧客との過去の対話履歴、製品マニュアル、FAQ、社内ナレッジベース全体を常に参照し、顧客の状況を完全に理解した上で、一貫性のあるパーソナライズされたサポートを提供する 。
- 財務分析・企業評価: 複数年度の財務諸表、監査報告書、市場レポート、競合分析データなどを一度に処理し、企業価値評価、リスク要因特定、投資戦略立案を支援する 11。
- コンテンツ制作・マーケティング: 長編小説、脚本、マーケティング戦略文書、市場調査レポートなどからインスピレーションを得て、新たなコンテンツ生成、ターゲット層に合わせたキャッチコピー作成、多言語コンテンツのローカライゼーションを行う 。
これらのシナリオでは、情報を分断して処理する従来のアプローチでは難しかった「全体的な文脈の理解」と「情報間の複雑な関連性の把握」が可能となり、AIによる高度な業務自動化と意思決定支援が実現します。
5. DeepSeek-V3.2における100万トークンコンテキストに関する公式情報の状況
提供された参照情報に基づくと、DeepSeek-V3.2の100万トークンコンテキストに関する公式の説明、詳細な技術ブログ、または論文は直接特定できませんでした。参照情報13ではSnowflake Cortex AI Functionsが「OpenAI, Anthropic, Meta, Mistral AI, and DeepSeekといった業界をリードするLLM」を利用可能であると述べているものの、DeepSeekの具体的なモデル名やコンテキスト長に関する詳細には触れていません。
一般的に、これほど大きな技術的進歩を遂げたモデルについては、開発元が詳細な技術レポートやブログ記事、研究論文を発表することが多いです。DeepSeek-V3.2の100万トークンコンテキストが真に革新的であれば、その背後にある技術的詳細が今後公開される可能性が高いと推測されます。
6. 長いコンテキストウィンドウの一般的な課題と注意点
長いコンテキストウィンドウは多くのメリットをもたらしますが、同時にいくつかの課題と注意点も存在します 12。
6.1 計算コストとメモリ使用量の増大
コンテキスト長がN倍になると、Attention機構の計算量はNの二乗(O(N²))に比例して増加するため、処理速度の低下やAPI利用料金の高騰に直結します 。HBMのような高速メモリシステムが、推論を効率的に支える上で重要になります 14。
6.2 「Lost in the Middle」問題
非常に長いテキストを入力された際に、LLMが文章の中間部分にある情報を適切に認識・利用できなくなり、性能が低下する現象です 。LLMは入力テキストの冒頭と末尾にある情報には強く注意を払う一方で、中間の情報は「見失い」やすい傾向があると指摘されています 。ただし、最新モデルではこの問題が軽減される傾向にあり、適切なトレーニング手法やアーキテクチャ変更によって改善可能であるという研究もあります 9。
6.3 応答速度の低下
入力シーケンス長(ISL)の増加は最初のトークンが出力されるまでの時間(TTFT)に影響し、出力シーケンス長(OSL)の増加はトークン間のレイテンシー(ITL)に影響します 14。特に長い応答を生成する際は、トークンが逐次的に生成されるため、レイテンシーが大幅に増加する可能性があります 14。
6.4 ハルシネーション(幻覚)の発生リスク
コンテキストウィンドウが埋まっていくにつれて、モデルのアテンションが拡散し、応答の明確さが失われることがあります。これにより、情報の矛盾や一貫性の欠如、あるいは以前のプロンプト情報を誤って別の箇所に結びつけるといったハルシネーションが発生しやすくなります 14。
7. DeepSeek-V3.2およびDeepSeek-V3.2-Specialeのその他の主要な注目点
DeepSeekの最新モデルであるDeepSeek-V3.2とDeepSeek-V3.2-Speciale、そしてその系列モデルは、コンテキストウィンドウの議論に加えて、いくつかの革新的な特徴と性能向上を実現しています。
- DeepSeek-V3.2の進化: DeepSeek-V3.2は、「思考プロセス」と「ツール呼び出し」を深く融合させ、2つのモード(思考モードと非思考モード)をサポートしています 1。膨大なAgent合成データで訓練されており、現在のすべてのスマートエージェント公開評価ランキングを圧倒し、一部のクローズドソースモデルの性能にも迫っています 1。
- DeepSeek-V3.2-Specialeの推論能力: 「思考を最大限まで開く」ことを目標としたDeepSeek-V3.2-Specialeは、オープンソースモデルの推論能力を極限まで高めた強化版です 1。DeepSeek-Math-V2の数学定理証明能力を継承し、30ステップ以上の深い推論が必要なタスクにおいて、既存のオープンソースモデルを大幅に上回る正確性を示しています 1。
- MoEアーキテクチャによる効率化: DeepSeek V3系列はMixture-of-Experts(MoE)アーキテクチャを採用しており、総パラメータ数671Bのうち、各トークンの処理時には37Bのみを活性化することで効率的な運用を実現しています 。
- 高度な学習技術: 効率的な学習プロセスのためにFP8混合精度トレーニングやDualPipeアルゴリズムが採用されています 4。また、推論能力の改良にはDeepSeek-R1からの知識蒸留や検証・リフレクションパターンの統合が行われています 4。
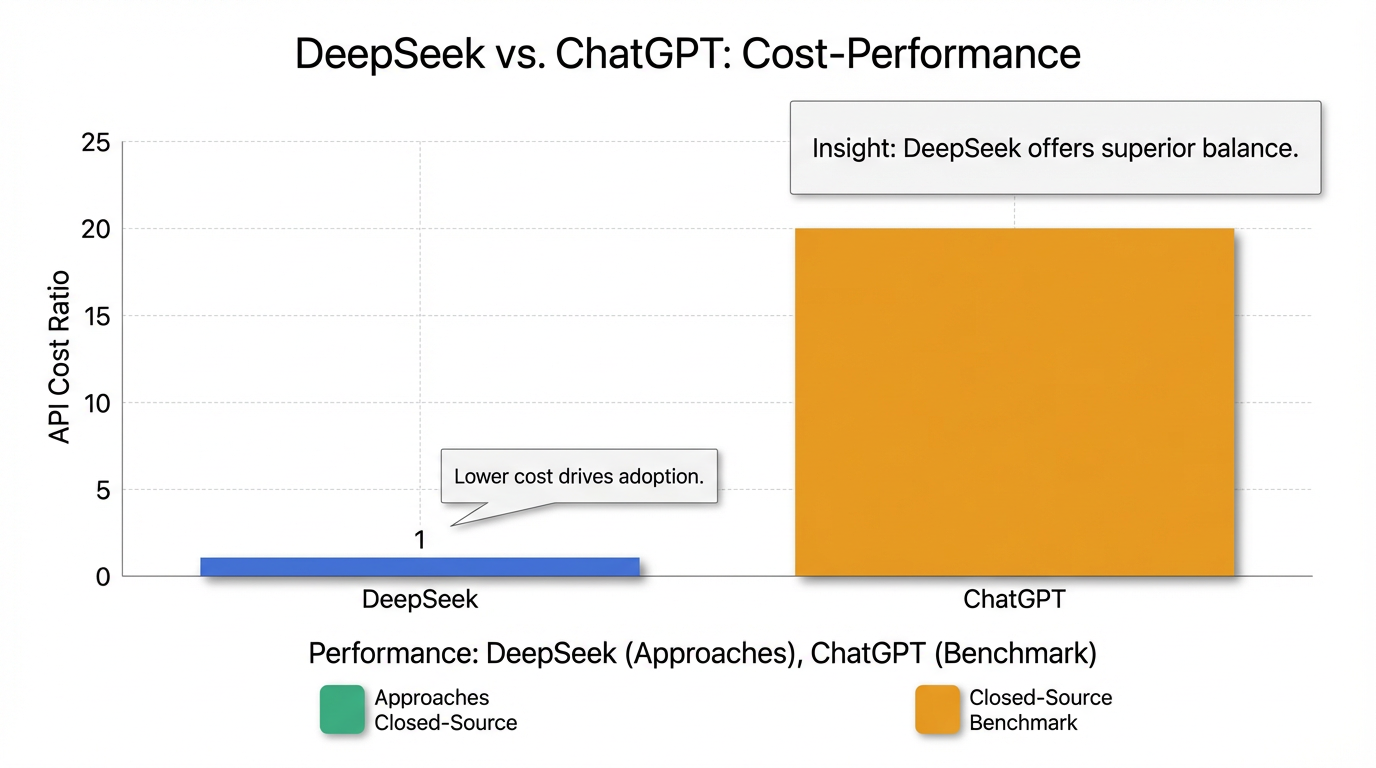
- 優れたコストパフォーマンス: DeepSeekのモデルは、高性能でありながらAPI利用料が非常に低く設定されており、ChatGPTなど競合他社の約1/20の価格で利用できるとされています 。このコストパフォーマンスの高さは「知能の価格破壊」と評されています 15。
まとめ
DeepSeek-V3.2の100万トークンコンテキストウィンドウの導入は、現時点では公式には確認されていませんが、将来的なDeepSeek V4での実現が期待されています 。現行のDeepSeek-V3.2およびDeepSeek-V3.2-Specialeは163.8Kトークンのコンテキストウィンドウを持ち 2、DeepSeek-R1は128Kトークン、DeepSeek V3は64Kトークンを提供しています 。
長大なコンテキストウィンドウは、LLMが大量の情報を一度に扱える能力をさらに高め、多岐にわたる高度なテキスト処理タスクにおいて、より高品質で一貫性のある応答生成の可能性を広げます。この長大なコンテキストは、長文の理解・要約、複雑な指示の実行、一貫した対話、Few-shotプロンプティングの強化、RAGの効率化といった具体的なメリットをユーザーに提供し、法務、研究、ソフトウェア開発などの専門分野での応用を加速します。
その実現には、FlashAttention、Ring AttentionなどのAttention機構の効率化、RoPEスケーリングなどの位置エンコーディングの改良、MambaやJambaといったハイブリッドアーキテクチャ、そしてPagedAttentionのような効率的なメモリ管理技術が複合的に寄与しています。
一方で、計算コストの増大、「Lost in the Middle」問題、応答速度の低下、ハルシネーションのリスクといった課題も存在します 。これらの課題に対しては、モデル自身の改良に加え、RAGや高度なコンテキスト圧縮技術、さらにはGraphRAGやAgentic RAGのような次世代アーキテクチャを組み合わせたハイブリッド戦略が、今後のLLM活用の鍵となると考えられます 。DeepSeek-V3.2がどのようなアプローチでこれらの課題を克服しているのか、今後の公式発表が待たれます。
DeepSeekは、V3.2の「思考プロセス」と「ツール呼び出し」の融合、V3.2-Specialeの卓越した推論能力 1、MoEアーキテクチャによる効率的な運用 、そして競合他社と比較して格段に低いAPI利用料 といった点で、業界において「オープンソース最強」1や「知能の価格破壊」15と評される注目すべき存在です。
参照された主なモデルのコンテキストウィンドウ比較(2025年最新情報を含む)
| サービス/モデル | 提供元 | 最大コンテキストウィンドウ (目安) | 特徴 | 備考 |
|---|---|---|---|---|
| GPT-4o (Omni) | OpenAI | 128,000トークン | 最新のフラッグシップモデル。GPT-4 Turboと同等の長いコンテキストウィンドウ。テキスト、画像、音声入出力に対応したマルチモーダルモデル。処理速度とコスト効率が向上 11。 | GPT-4 Turboから置き換わる形で提供開始 11。 |
| GPT-4 Turbo | OpenAI | 128,000トークン | 以前のフラッグシップモデル 11。 | プレビュー版は順次廃止予定 11。 |
| Gemini 1.5 Pro | 1,000,000トークン | 極めて長いコンテキストウィンドウを誇るモデル。長編コンテンツや大量の情報を扱うタスクに強み 。 | 2025年2月5日よりGemini 2.0 Pro実験版が公開 11。 | |
| Gemini 2.0 Flash | 1,000,000トークン | Gemini 1.5 Proと比較して2倍の応答速度を実現。同等の超長コンテキストウィンドウを持ちながら、低遅延・低コストに特化したモデル 11。 | 新モデルとして登場 11。 | |
| Claude 3 Opus | Anthropic | 200,000トークン | 高性能なClaude 3シリーズ最上位モデル。非常に長いコンテキストウィンドウを持ち、複雑な分析や創造的なタスクに最適 11。 | |
| Claude 3.7 Sonnet | Anthropic | 200,000トークン | Claude 3 Opusと同様の長いコンテキストウィンドウを持ちながら、高速・低コスト 11。 | |
| Claude 3.5 Haiku | Anthropic | 200,000トークン | Claude 3シリーズ最速・低コストモデル。リアルタイムに近い応答速度が特徴 11。 | |
| Command R+ | Cohere | 128,000トークン | 企業向け高性能モデル。長いコンテキストウィンドウ、RAGに強み 11。 | |
| StableLM 2 160K | Stability AI | 160,000トークン | オープンソースモデル。非常に長いコンテキストウィンドウ、研究用途で期待 11。 |
市場での位置づけと期待
DeepSeekは、事前の告知なしに最新モデルである「DeepSeek-V3.2」とその最適推論特化版「DeepSeek-V3.2-Speciale」をリリースし、AI市場に大きなインパクトを与えました1。これらのモデルは、その高性能から「オープンソース最強」と評されており、特にDeepSeek-V3.2は「思考プロセス」と「ツール呼び出し」を深く融合させ、スマートエージェントの公開評価ランキングで他を圧倒しています1。また、DeepSeek-V3.2-Specialeは、DeepSeek-Math-V2の数学定理証明能力を継承し、30ステップ以上の深い推論タスクにおいて既存のオープンソースモデルを大幅に上回る正確性を示し、推論能力の限界を押し広げています1。
このDeepSeekのモデル群は、卓越した性能に加えて、そのコストパフォーマンスの高さも特筆すべき点です。API利用料は競合するOpenAIのChatGPTなどと比較して約1/20と非常に低く設定されており、「知能の価格破壊」と評されています15。これは、大規模言語モデルの活用における経済的障壁を大幅に引き下げ、より多くの企業や開発者が高性能なAIを利用できる可能性を広げるものです。この戦略は、AI市場におけるDeepSeekの競争優位性を確立し、普及を加速させる重要な要因となっています。
DeepSeek V3系列のアーキテクチャはMixture-of-Experts(MoE)を採用しており、総パラメータ数671Bのうち、各トークンの処理時には37Bのみを活性化することで効率的な運用を実現しています。このような技術的基盤が、高性能と低コストの両立を可能にしていると言えるでしょう。
現在のDeepSeekのモデルは、100万トークンのコンテキストウィンドウを実現しているわけではありませんが、次期フラッグシップモデル「DeepSeek V4」には、その実現が強く期待されています。DeepSeek V4は2026年2月中旬(中国の春節)に公開が予定されており、Sparse Attentionメカニズムを活用して100万トークンを超える、または「無限」に近いコンテキスト処理能力を達成する可能性が指摘されています3。この100万トークンコンテキストウィンドウは、Gemini 1.5 Proなどが既に提供しているレベルに匹敵し、AIが一度に処理できる情報量を劇的に拡大させ、複雑な文書の分析、長期間にわたる対話、あるいは広範な知識ベースからの学習といった、これまでLLMでは困難だったタスクの精度と効率を飛躍的に向上させるでしょう。
| サービス/モデル | 提供元 | 最大コンテキストウィンドウ (目安) | 特徴 | 備考 |
|---|---|---|---|---|
| DeepSeek V4 (予測) | DeepSeek | 1,000,000トークン超 (または「無限」に近い) 3 | Sparse Attentionメカニズムを活用し忠実度を保つ 3。 | 2026年2月にリリース予想される未発表モデル 。 |
| Gemini 1.5 Pro | 1,000,000トークン | 極めて長いコンテキストウィンドウを誇るモデル。長編コンテンツや大量の情報を扱うタスクに強み 。 | 2025年2月5日よりGemini 2.0 Pro実験版が公開 11。 | |
| Gemini 2.0 Flash | 1,000,000トークン 11 | Gemini 1.5 Proと比較して2倍の応答速度を実現。同等の超長コンテキストウィンドウを持ちながら、低遅延・低コストに特化 11。 | 新モデルとして登場 11。 | |
| Claude 3 Opus | Anthropic | 200,000トークン 11 | 高性能なClaude 3シリーズ最上位モデル。非常に長いコンテキストウィンドウを持ち、複雑な分析や創造的なタスクに最適 11。 | |
| Claude 3.7 Sonnet | Anthropic | 200,000トークン 11 | Claude 3 Opusと同様の長いコンテキストウィンドウを持ちながら、高速・低コスト 11。 | |
| Claude 3.5 Haiku | Anthropic | 200,000トークン 11 | Claude 3シリーズ最速・低コストモデル。リアルタイムに近い応答速度が特徴 11。 | |
| DeepSeek-V3.2 / DeepSeek-V3.2-Speciale | DeepSeek | 163.8Kトークン 2 | V3.2:「思考プロセス」と「ツール呼び出し」を深く融合、2モードサポート。V3.2-Speciale: 推論能力を極限まで高めた強化版、数学定理証明能力を継承 1。 | 「オープンソース最強」評価 1。最新の正式リリースモデル 1。 |
| StableLM 2 160K | Stability AI | 160,000トークン 11 | オープンソースモデル。非常に長いコンテキストウィンドウ、研究用途で期待 11。 | |
| DeepSeek-R1 | DeepSeek | 128Kトークン 6 | 推論能力に特化 。 | 2025年1月20日リリース 。DeepSeek V3系列の重要なモデル 。 |
| GPT-4o (Omni) | OpenAI | 128,000トークン 11 | 最新のフラッグシップモデル。GPT-4 Turboと同等の長いコンテキストウィンドウ。テキスト、画像、音声入出力に対応したマルチモーダルモデル。処理速度とコスト効率が向上 11。 | GPT-4 Turboから置き換わる形で提供開始 11。 |
| GPT-4 Turbo | OpenAI | 128,000トークン 11 | 以前のフラッグシップモデル 11。 | プレビュー版は順次廃止予定 11。 |
| Command R+ | Cohere | 128,000トークン 11 | 企業向け高性能モデル。長いコンテキストウィンドウ、RAGに強み 11。 | |
| DeepSeek V3 (API: deepseek-chat) | DeepSeek | 64,000トークン | MoEアーキテクチャ (671Bパラメータ中37B活性化)。FP8混合精度トレーニング、DualPipeアルゴリズム、知識蒸留 。 | 高性能、低API利用料 (競合の約1/20)、「知能の価格破壊」と評される 。 |
今後のAI業界において、DeepSeekは「オープンソース最強」の性能と「価格破壊」という強力な武器、そして将来的な超長コンテキストウィンドウの実現によって、既存のプレイヤーとの競争をさらに激化させると予想されます。特に、高性能なオープンソースモデルの提供と、先進的な技術革新への継続的な取り組みは、AI技術の民主化と新たな応用領域の開拓を促進し、今後のAIエコシステムにおけるDeepSeekの存在感を一層高めることとなるでしょう。
まとめ
ユーザー様、DeepSeekの最新モデルに関するお問い合わせをいただきありがとうございます。本レポートでは、ご関心をお寄せいただいたDeepSeekの新しいモデル、特に「DeepSeek-V3.2」および「DeepSeek-V3.2-Speciale」の主な特徴と、100万トークンコンテキストウィンドウに関する現状と将来の展望について詳細をまとめました。
DeepSeekは事前の告知なく「DeepSeek-V3.2」と、推論能力に特化した「DeepSeek-V3.2-Speciale」をリリースしました1。これらのモデルは「オープンソース最強」と評価されており1、特にDeepSeek-V3.2は「思考プロセス」と「ツール呼び出し」を深く融合させ、スマートエージェントの公開評価ランキングを圧倒する性能を示しています1。DeepSeek-V3.2-Specialeは、30ステップ以上の深い推論が必要なタスクで既存のオープンソースモデルを大幅に上回る正確性を実現しています1。これらDeepSeek V3系列のモデルは、Mixture-of-Experts(MoE)アーキテクチャを採用し、高性能と効率性を両立しています。
ご質問の100万トークンコンテキストウィンドウについては、現在の「DeepSeek-V3.2」および「DeepSeek-V3.2-Speciale」では163.8Kトークン2、DeepSeek-R1では128Kトークン6、DeepSeek V3では64,000トークン(APIバージョン)が確認されており、100万トークンは導入されていません。この超長コンテキストウィンドウは、2026年2月に公開が噂される未発表の次期フラッグシップモデル「DeepSeek V4」で導入されると予想されています。
長大なコンテキストウィンドウは、長文の読解・要約精度の向上、複雑な指示や複数タスクの同時処理、文脈を維持した自然な対話の実現など、ユーザーに多大なメリットをもたらします。法務・知財、研究開発、ソフトウェア開発、カスタマーサポート、財務分析といった知識集約型の分野でその真価を発揮し、AIによる高度な業務自動化と意思決定支援を可能にします。これらの技術的側面は、FlashAttentionのようなAttention機構の効率化、RoPEスケーリングなどの位置エンコーディング改良、MambaやJambaといったハイブリッドアーキテクチャ、そしてPagedAttentionなどのメモリ管理最適化技術によって支えられています。
一方で、長大なコンテキストウィンドウには、計算コストとメモリ使用量の増大、「Lost in the Middle」問題、応答速度の低下、ハルシネーション(幻覚)発生のリスクといった課題も存在します。今後の展望としては、RAGとロングコンテキストLLMを組み合わせたハイブリッドアプローチ、GraphRAGやAgentic RAGといった次世代アーキテクチャ16、高度なコンテキスト圧縮技術、そしてHBM4のようなハードウェアの進化14が、これらの課題克服とさらなる性能向上に貢献すると期待されます。
特にDeepSeekのモデルは、高性能でありながらAPI利用料が非常に低く、競合他社の約1/20の価格で利用できるとされており、「知能の価格破壊」と評されています15。これは、AI技術の普及と活用を加速する上で非常に重要な要素です。
DeepSeekは、その革新的なモデルリリースとコストパフォーマンスで、LLM業界に大きな影響を与え続けています。今後のDeepSeek V4での100万トークンコンテキストウィンドウの実現、そしてさらなる技術発展と応用展開に大いに期待が寄せられます。
主要なモデルのコンテキストウィンドウ比較を以下に示します。
| モデルの名称 | 提供元 | 最大コンテキストウィンドウ(目安) | 特徴 | 備考 |
|---|---|---|---|---|
| DeepSeek V3 | DeepSeek | 64,000トークン | 高性能でありながらAPI利用料が非常に低く、競合の約1/20の価格 。 | APIバージョンはdeepseek-chat (V3)とdeepseek-reasoner (R1)。一部で128Kトークンの長文処理能力と記載 。 |
| DeepSeek-R1 | DeepSeek | 128Kトークン | 推論能力に特化。DeepSeek V3系列の重要なモデル 。 | 2025年1月20日リリース 。 |
| DeepSeek-V3.2 | DeepSeek | 163.8Kトークン | 「思考プロセス」と「ツール呼び出し」を深く融合、2つのモードをサポート。スマートエージェント公開評価ランキングを圧倒 1。 | 事前告知なしにリリース。Mixture-of-Experts(MoE)アーキテクチャ採用 。 |
| DeepSeek-V3.2-Speciale | DeepSeek | 163.8Kトークン | オープンソースモデルの推論能力を極限まで高めた強化版。深い推論が必要なタスクで高い正確性 1。 | 事前告知なしにリリース。Mixture-of-Experts(MoE)アーキテクチャ採用 。 |
| DeepSeek V4 (噂) | DeepSeek | 100万トークンを超える、または「無限」に近い | Sparse Attentionメカニズムを活用 3。 | 2026年2月中旬(中国の春節)に公開予定 。 |
| GPT-4o (Omni) | OpenAI | 128,000トークン | 最新のフラッグシップモデル。テキスト、画像、音声入出力対応マルチモーダル。処理速度とコスト効率向上 11。 | GPT-4 Turboから置き換わる形で提供開始 11。 |
| GPT-4 Turbo | OpenAI | 128,000トークン | 以前のフラッグシップモデル 11。 | プレビュー版は順次廃止予定 11。 |
| Gemini 1.5 Pro | 1,000,000トークン | 極めて長いコンテキストウィンドウ。長編コンテンツや大量情報タスクに強み 。 | 2025年2月5日よりGemini 2.0 Pro実験版が公開 11。 | |
| Gemini 2.0 Flash | 1,000,000トークン | Gemini 1.5 Proと比較して2倍の応答速度。低遅延・低コストに特化 11。 | 新モデルとして登場 11。 | |
| Claude 3 Opus | Anthropic | 200,000トークン | Claude 3シリーズ最上位。非常に長いコンテキスト。複雑な分析や創造的タスクに最適 11。 | |
| Claude 3.7 Sonnet | Anthropic | 200,000トークン | Claude 3 Opusと同様の長いコンテキスト。高速・低コスト 11。 | |
| Claude 3.5 Haiku | Anthropic | 200,000トークン | Claude 3シリーズ最速・低コスト。リアルタイムに近い応答速度 11。 | |
| Command R+ | Cohere | 128,000トークン | 企業向け高性能モデル。長いコンテキストウィンドウ、RAGに強み 11。 | |
| StableLM 2 160K | Stability AI | 160,000トークン | オープンソースモデル。非常に長いコンテキスト、研究用途で期待 11。 |