GLM 5 重磅发布:硬核性能直指 Claude Opus 4.5?
引言:GLM 5横空出世,AI大模型格局再添新星
在AI大模型领域日益激烈的竞争中,智谱AI于2026年2月11日深夜或2月12日凌晨正式发布了其新一代旗舰模型GLM-51。这款模型被官方定位为“新一代旗舰模型”或“新一代基座模型”1。其完整的官方名称为“GLM-5: From Vibe Coding to Agentic Engineering”2。GLM-5旨在面向Agentic Engineering(智能体工程)打造,特别擅长处理复杂系统工程与长程Agent任务1。
此次发布不仅标志着智谱AI在AI大模型领域迈出了重要一步,更预示着它将与现有顶尖模型(如Claude Opus 4.5)展开正面竞争,有望重新定义AI大模型的技术巅峰与应用边界。
GLM 5核心亮点与技术革新:全面解析其“亮眼”之处
智谱AI于2026年2月11日正式发布并开源了新一代旗舰基座模型GLM-5,旨在面向复杂系统工程与长程Agent任务,在编程和智能体能力上取得了开源领域的领先水平(SOTA)。此前,OpenRouter平台上的神秘匿名模型“Pony Alpha”已被官方确认为GLM-5的匿名测试版本。
1. 核心技术与模型架构
GLM-5在模型架构和核心技术上实现了显著革新,奠定了其强大性能的基础:
(1) 参数规模与MoE架构革新
GLM-5的总参数量达到7440亿至7450亿,是上一代GLM-4.7的2倍。该模型采用混合专家(MoE)架构,包含78层隐藏层和256个专家,每次推理仅激活其中8个,使得激活参数约为400亿至440亿,稀疏度为5.9%。值得注意的是,模型前三层保留了稠密结构,以确保基础语言理解的稳定性。
| 指标 | 数值 |
|---|---|
| 总参数量 | 7440亿-7450亿 |
| MoE架构-隐藏层数 | 78 |
| MoE架构-专家数量 | 256 |
| MoE架构-激活专家数 | 8 |
| 激活参数量 | 400亿-440亿 |
| 稀疏度 | 5.9% |
| 预训练数据量 | 28.5T token |
| 上下文窗口 | 202K token |
| 最大输出长度 | 131072 token (128K) |
GLM-5核心模型参数一览
(2) 预训练与强化学习升级
模型预训练数据量从23T token大幅提升至28.5T token。此外,GLM-5引入了名为“Slime”的异步智能体强化学习框架,支持模型从长程交互中持续学习,显著提升了强化学习后训练流程的效率。
(3) 推理优化技术
- DeepSeek稀疏注意力(DSA):GLM-5复用DeepSeek-V3/V3.2架构的DSA机制,通过两阶段流程(Lightning Indexer快速扫描和Top-k token选择)大幅提升了长文本处理效率。该机制可在不损失核心任务性能(损失不到1%)的前提下,降低长文本推理成本40%至50%。
- 多Token预测(MTP):为提升模型生成效率,GLM-5采用了MTP技术,允许模型在前向计算中一次预测多个连续的词,从而减少迭代次数。在代码、JSON、SQL等结构化文本生成任务中,MTP可将token生成速度提升2-3倍。
2. 显著提升的关键能力
GLM-5在长文本处理、多模态能力和推理能力方面取得了显著提升,尤其在编程和Agent任务上表现突出。
(1) 超长文本处理能力
GLM-5支持最高达202K token的上下文窗口,最大输出长度达到131072 token(128K token)。DSA机制在保持长文本处理效果无损的同时,大幅降低了部署成本,显著提升了Token效率。
(2) 多模态能力现状与展望
GLM-5的首发版本主要处理文本输入和输出,社区测试指出其暂无直接的多模态处理能力(图像、音频等)。然而,智谱AI表示未来可能扩展到多模态能力3。值得一提的是,GLM-5家族中已包含专门的变体,如用于高保真图像生成的GLM-Image,以及用于高级多模态推理的GLM-4.5V/4.6V(其中GLM-4.5V作为基于MoE架构的视觉推理模型,在视觉多模态榜单中表现SOTA)。
(3) 领先的推理能力
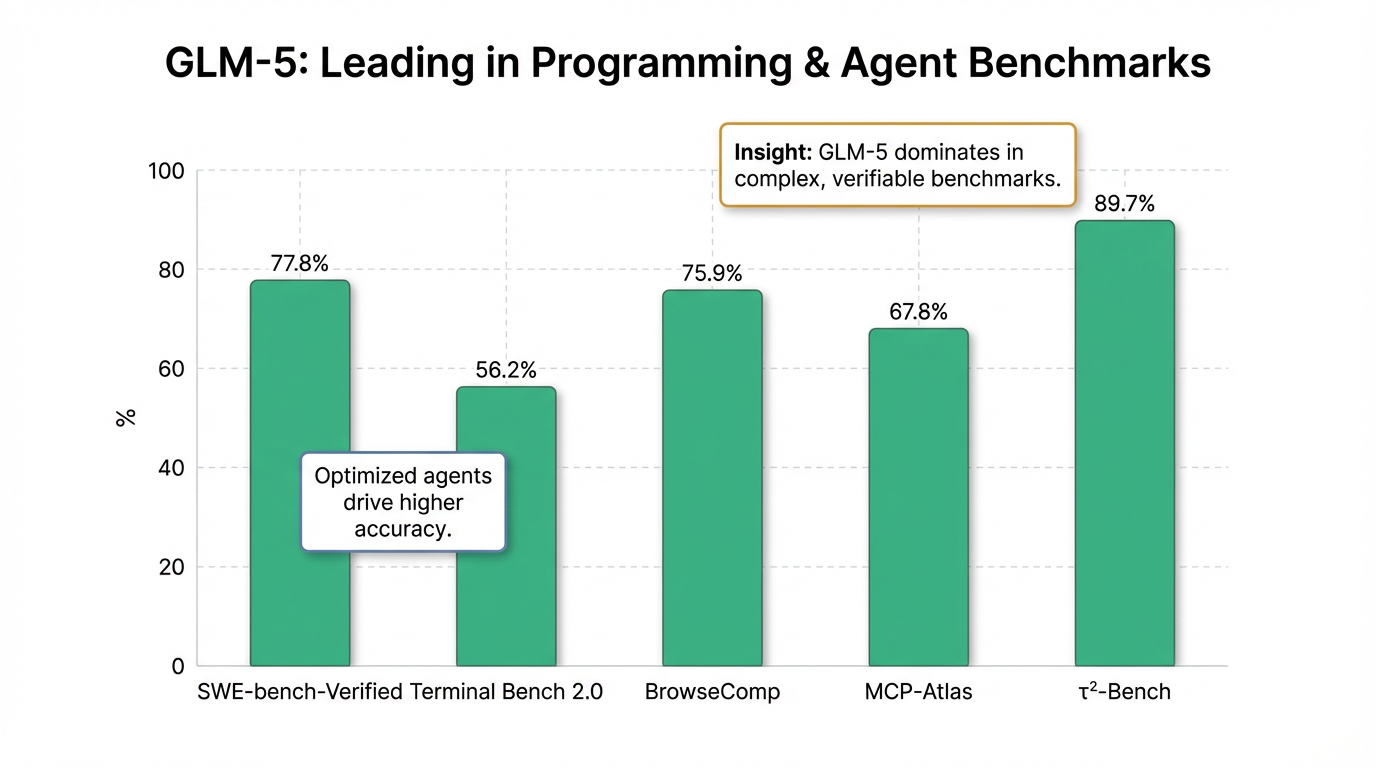
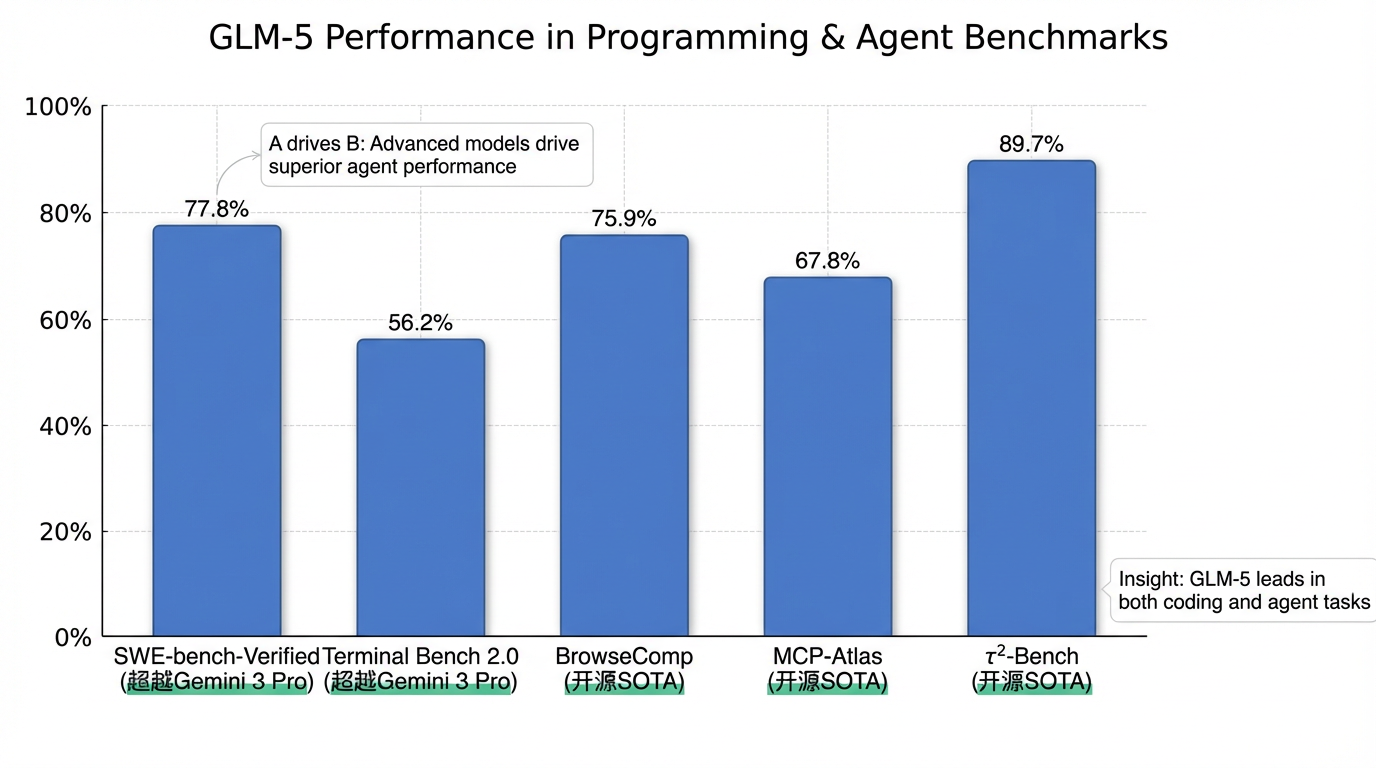
- 编程能力:GLM-5在业内主流基准测试中取得了开源模型的最高分数,例如SWE-bench-Verified达到77.8%,Terminal Bench 2.0达到56.2%,性能表现超越Gemini 3 Pro。在内部Claude Code评估中,GLM-5在前端、后端、长程任务等编程开发任务上显著超越GLM-4.7,平均增幅超过20%,使用体感逼近Claude Opus 4.5。
- Agent能力:该模型实现了开源SOTA,在BrowseComp(75.9%)、MCP-Atlas(67.8%)和τ²-Bench(89.7%)等多个评测基准中取得开源第一。在模拟商业运营长时程任务的Vending Bench 2中,GLM-5也获得了开源模型的最高分,经营表现接近Claude Opus 4.5。
- 深度思考模式:GLM-5提供了多种思考模式,通过启用
thinking参数,模型能够在生成最终输出前执行内部逻辑推导和规划,尤其适用于复杂的数学证明、逻辑谜题或多步骤策略规划。
3. 特别“亮眼”之处与创新功能
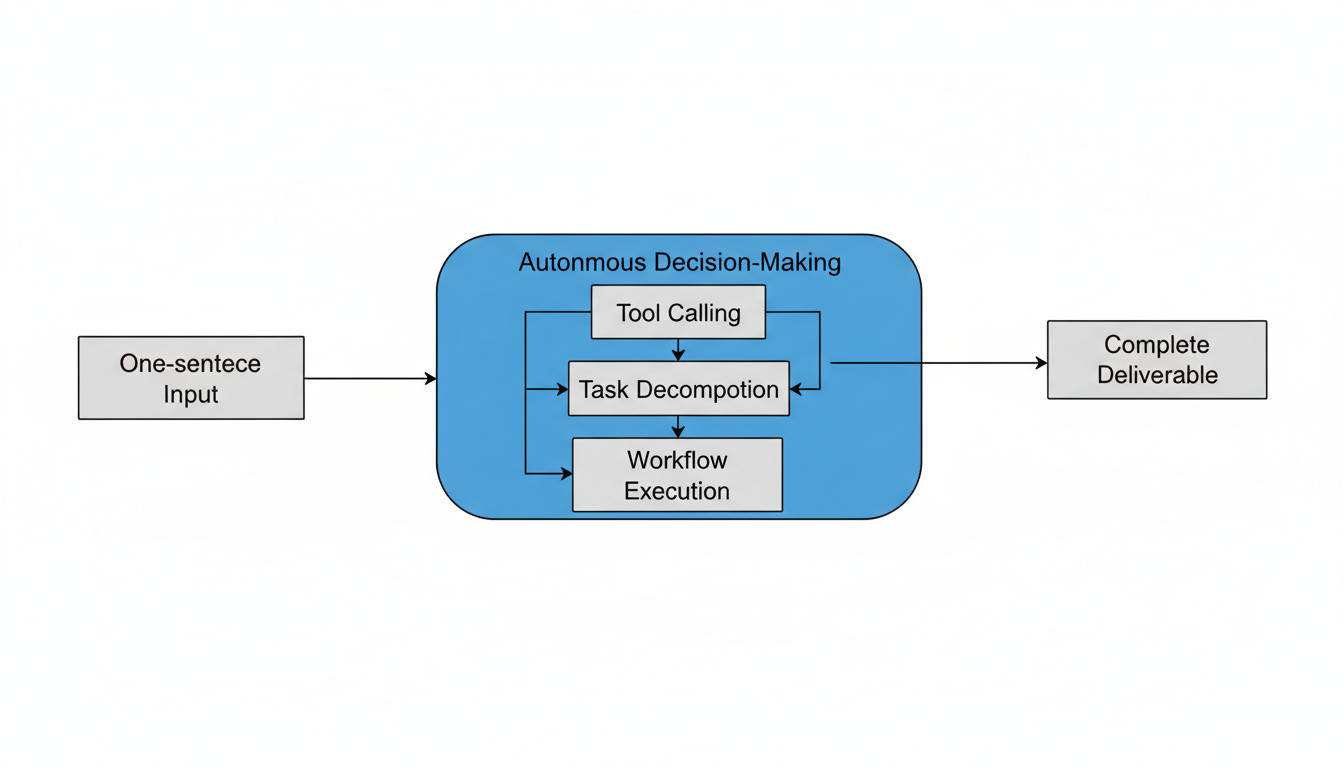
(1) Agentic Engineering核心定位
GLM-5被明确定义为“面向Agentic Engineering打造”,专注于解决复杂系统工程和长程Agent任务。它支持自主决策、工具调用、任务分解和工作流执行,旨在实现“一句话输入到完整交付物”的目标,大幅提升开发与交付效率。
(2) 硬件自主性
GLM-5完全在华为昇腾芯片上训练,并采用MindSpore框架,实现了对美国制造半导体硬件的完全独立。同时,该模型已完成与华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光等主流国产芯片平台的深度推理适配与算子级优化,确保在国产算力集群上实现高吞吐、低延迟的稳定运行4。
(3) 高效部署与可访问性
得益于复用DeepSeek架构,GLM-5可以直接受益于vLLM、SGLang等推理框架的优化,从而降低了部署门槛。模型提供了BF16、FP8和INT4等多种精度版本,以适应不同硬件环境的部署需求3。目前,GLM-5已通过GitHub、Hugging Face开源,并提供API服务(如chat.z.ai、OpenRouter),同时为新用户提供免费试用额度,极大地提升了可访问性。
(4) 实用应用场景
GLM-5在多个实用应用场景中展现出强大潜力,包括软件开发辅助(如自动化前后端代码生成、项目重构)、AI代理开发、技术文档生成(可直接转换为.docx、.pdf和.xlsx文件)、办公自动化和数据分析等。
(5) 市场定位
GLM-5旨在缩小与国际闭源模型(如GPT-5.2和Claude Opus 4.5)的差距,并在保持高性能的同时极致优化推理成本,提供高性价比的开源选择,为用户带来更为经济高效的解决方案。
4. 局限性与展望
(1) 当前局限
尽管GLM-5表现出色,但其首发版本在多模态能力方面有所欠缺。此外,模型输出有时可能较为冗长,速度中等(约52tokens/秒),在某些非推理版本中智能指数较低3。有评论指出,GLM-5更适合专业的程序员,而非编程基础薄弱的用户。
(2) 研发路径与行业影响
智谱AI选择开源集成技术,而非“闭源+自研”,反映了其务实的研发路径。这预示着AI行业将告别过去参数规模的“军备竞赛”,转而聚焦于推理效率的精细化运营,以提供更具成本效益和实用价值的AI解决方案。
模型能力与权威基准数据:数据说话,彰显卓越性能
智谱AI最新发布的GLM-5在模型能力上实现了显著飞跃,特别是在面向复杂系统工程与长程Agent任务的编程和智能体(Agent)能力方面,其表现已达到开源领域的领先水平(SOTA)5。通过一系列权威基准测试数据,GLM-5展现出强大的竞争力,甚至在某些关键指标上超越了顶尖的闭源模型。
编程能力卓越,超越Gemini 3 Pro,逼近Claude Opus 4.5
GLM-5在编程能力方面取得了开源模型的最高分数。例如,在业界主流的SWE-bench-Verified基准测试中,GLM-5达到了77.8%的优异成绩5。在Terminal Bench 2.0测试中,其得分高达56.2%5,这两项表现均超越了Google的Gemini 3 Pro5。智谱AI内部进行的Claude Code评估显示,GLM-5在前端、后端和长程任务等编程开发任务上的表现显著超越了上一代GLM-4.7,平均增幅超过20%,其使用体验已能逼近Anthropic的Claude Opus 4.55。
智能体能力领跑开源赛道,商业运营表现接近Claude Opus 4.5
在智能体能力方面,GLM-5同样实现了开源领域的SOTA地位5。在多项重要评测基准中,GLM-5均取得了开源模型第一的佳绩,包括BrowseComp(75.9%)、MCP-Atlas(67.8%)和τ²-Bench(89.7%)5。特别是在模拟商业运营长时程任务的Vending Bench 2测试中,GLM-5获得了开源模型的最高分,其经营表现接近Claude Opus 4.5,进一步印证了其在复杂智能体任务上的强大实力5。
长文本处理能力显著提升
GLM-5在长文本处理方面也取得了突破性进展,支持高达202K token的超长上下文窗口6,最大输出长度达到131072 token(128K token)3。结合DeepSeek稀疏注意力(DSA)机制,模型能够在保持长文本处理效果无损的同时,大幅降低部署成本并显著提升Token效率5。
此外,GLM-5还引入了深度思考模式,通过启用thinking参数,模型能够在生成最终输出前进行内部逻辑推导和规划,这对于复杂的数学证明、逻辑谜题或多步骤策略规划等任务至关重要7。
综合来看,GLM-5旨在缩小与国际闭源模型(如GPT-5.2和Claude Opus 4.5)的差距5,并在保持高性能的同时,提供高性价比的开源选择。
与顶尖模型(如Claude Opus 4.5)的正面交锋:谁是新一代AI之王?
随着人工智能技术迭代加速,大语言模型(LLM)的竞争格局日趋白热化。由中国智谱AI推出的GLM-5与Anthropic的Claude Opus 4.5,作为各自阵营的旗舰产品,正展开一场能力与市场的全面对决。本节将深入剖析这两款模型在性能、功能、竞争优势及商业策略上的异同,旨在揭示当前AI模型格局的动态演变,并探讨谁更有潜力成为新一代AI之王。
1. 模型概览
1.1 GLM-5 (智谱AI)
GLM-5是智谱AI于2026年2月11日发布的第五代旗舰模型,专为复杂系统工程和长程智能体任务设计 。
在架构上,GLM-5采用混合专家(MoE)架构,总参数规模从GLM-4.5的355B扩展至744B,激活参数提升至40B 。预训练数据量增至28.5T 。该模型首次引入DeepSeek稀疏注意力机制(DSA),在保证长文本处理效果的同时,有效降低部署成本并提升Token利用效率 。值得注意的是,GLM-5完全基于华为昇腾芯片和MindSpore框架训练,实现了对美国制造硬件的零依赖,标志着中国在AI基础设施自主可控方面的重要突破 。
GLM-5作为开源模型发布,遵循MIT许可证,其权重可在HuggingFace和ModelScope上获取 。用户可通过chat.z.ai、Z.ai开放平台或OpenRouter访问,并兼容Claude Code用户通过GLM Coding Plan使用 。其核心能力聚焦于创意写作、编码、高级推理、智能体智能和长上下文处理,尤其在编码和智能体能力上达到开源领域的SOTA(State-of-the-Art)水平 。
1.2 Claude Opus 4.5 (Anthropic)
Claude Opus 4.5是Anthropic于2025年11月25日推出的最新AI模型,旨在成为在编码、智能体以及计算机操作方面表现领先的通用模型 。
该模型采用混合推理模型,并引入了独特的“思考模式”(thinking mode),使其能够在生成最终答案前进行内部推理和规划,从而提升任务处理的准确性 8。Claude Opus 4.5可通过Anthropic应用程序、API以及Google Cloud的Vertex AI等主流云平台开放使用 。
其核心能力包括在深度研究、演示文稿处理以及电子表格任务上的显著提升 。尤其在软件工程相关测试中表现卓越,并通过“Claude Code”工具链为开发者提供强大的集成能力,达到当前最先进水平 9。Anthropic强调Claude Opus 4.5是其迄今为止“对齐”程度最高的模型,推测其对齐水平在行业前沿模型中处于领先地位,并在防御提示注入攻击方面取得了实质性进展 。
2. 性能基准对比
GLM-5与Claude Opus 4.5在多项关键基准测试中展开激烈竞争,尤其在通用推理、软件工程和智能体任务上。
下表展示了GLM-5、Claude Opus 4.5以及其他顶尖模型在多个基准测试中的表现:
| 基准测试 | GLM-5 | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|---|
| Humanity's Last Exam (带工具) | 50.4 | 43.4 | 45.8 | 45.5 |
| SWE-bench Verified | 77.8% | 80.9% | 76.2% | 80.0% |
| SWE-bench Multilingual | 73.3% | 77.5% | 65.0% | 72.0% |
| Terminal-Bench 2.0 | 56.2% | 59.3% | 54.2% | 54.0% |
| BrowseComp | 75.9 (🥇) | 67.8 | 59.2 | 65.8 |
| MCP-Atlas | 67.8 | 65.2 | 66.6 | 68.0 |
| τ²-Bench | 89.7 | 91.6 | 90.7 | 85.5 |
| Vending Bench 2 | $4,432.12 (🥇OS) | $4,967.06 | $5,478.16 | $3,591.33 |
- 通用推理能力: 在衡量人类级别通用推理能力的“Humanity's Last Exam (带工具)”中,GLM-5以50.4分领先Claude Opus 4.5的43.4分 。
- 软件工程任务: 在“SWE-bench Verified”软件工程任务解决验证集中,Claude Opus 4.5以80.9%的成绩略高于GLM-5的77.8% 。在“SWE-bench Multilingual”多语言软件工程任务中,Claude Opus 4.5同样以77.5%的表现优于GLM-5的73.3% 。
- 智能体任务: 在“Terminal-Bench 2.0”终端环境智能体任务中,Claude Opus 4.5以59.3%的成绩稍胜GLM-5的56.2% 。然而,在“BrowseComp”网页浏览与信息理解任务中,GLM-5以75.9分夺冠,显著领先Claude Opus 4.5的67.8分 。在“MCP-Atlas”大规模端到端工具调用中,GLM-5和Claude Opus 4.5的表现较为接近 。在“τ²-Bench”复杂场景下自动代理工具规划与执行中,Claude Opus 4.5的91.6分略高于GLM-5的89.7分 。
- 长期运营能力: “Vending Bench 2”衡量长期运营能力,GLM-5在开源模型中排名第一 。
GLM-5与GLM-4.7内部评估对比 (CC-Bench-V2) 智谱AI的内部工程评估套件CC-Bench-V2显示,GLM-5相较于前代GLM-4.7有显著提升,并且已能与Claude Opus 4.5在多个指标上缩小差距,甚至有所超越 。
| 评估指标 | GLM-5 | Claude Opus 4.5 |
|---|---|---|
| 前端构建成功率 | 98.0% | 93.0% |
| 端到端正确性 | 74.8% | 75.7% |
| 后端端到端正确性 | 25.8% | 26.9% |
| 长周期大型仓库 | 65.6% | 64.5% |
| 多步骤任务 | 52.3% | 61.6% |
其他特定对比:
- 人工智能分析智能指数(Intelligence Index): GLM-5在开源模型中得分50,成为新的开源领导者,相较GLM-4.7的42分有8点提升,主要归功于智能体性能和知识/幻觉方面的改进。在经济价值工作任务的代理基准测试GDPval-AA中,GLM-5的ELO分数达1412,在开源模型中排名第三,仅次于Claude Opus 4.6和GPT-5.2 (xhigh) 10。
- 幻觉率: GLM-5在AA-Omniscience指数上得分-1,相较GLM-4.7的-36有显著改善,幻觉率降低了56个百分点 10。
3. 核心功能与能力对比
3.1 编程能力
- GLM-5: 被智谱AI描述为从“随性编码(vibe coding)到智能体工程(agentic engineering)的飞跃” 。它在系统工程和全栈开发方面表现出色,特别是在CC-Bench-V2中的前端构建成功率高达98.0% 11。GLM-5能够以极少人工干预,自主完成Agentic长程规划与执行、后端重构、深度调试等复杂系统工程任务 12,并兼容Python、Java、C++等主流语言及Rust、Go等小众语言 13。
- Claude Opus 4.5: 被誉为“全球编码王座”的“编程之王”,在SWE-bench Verified上以80.9%的准确率位居世界第一 。其在真实世界的软件工程测试中,得分超过了历来所有人类候选人 。内部评估显示,Opus 4.5与Claude Code联动使用,平均生产效率暴增220% 14。即使面对模糊信息和复杂多系统漏洞,它也能权衡利弊并找出修复方法 14。通过Claude Code提供原生VS Code插件、优化的终端界面和Claude Agent SDK,支持更深度的代码辅助和自主开发 。
3.2 智能体能力
- GLM-5: 构建了全新的“Slime”训练框架,支持更大规模模型架构与更复杂的强化学习任务,显著提升强化学习后训练流程效率 。它引入异步智能体强化学习算法,使模型具备从长程交互中持续学习的能力 12。其Agent Mode(Beta版)能自动分解任务、编排工具和执行工作流,以生成即用型结果 。在MCP-Atlas和BrowseComp等智能体基准测试中表现出色 11。
- Claude Opus 4.5: 通过其独特的“思考模式”在内部进行更彻底的推理,特别是在智能体工作流中,能够进行“思考-行动-思考-行动”的交错式思考,从而大幅降低幻觉与错误传递 8。
该模型拥有强大的工具调用能力,如“Tool Search Tool”可按需发现工具以减少上下文消耗,以及“Programmatic Tool Calling”允许模型在代码执行环境中调用工具,进一步提高效率和降低Token使用 。它还能有效管理子智能体团队,构建复杂、协调良好的多智能体系统 。
3.3 推理与长上下文处理
- GLM-5: 上下文窗口支持最高200K token,最大输出可达131K token,处于行业最高水平 。在“Humanity's Last Exam”等推理基准测试中取得领先成绩 。它具备深度思考模式,可用于复杂的数学证明、逻辑谜题或多步骤战略规划 15。
- Claude Opus 4.5: 上下文窗口支持200K输入token和64K输出token 16。其“思考模式”是核心优势,允许模型在生成响应前进行内部推理,提升复杂任务处理的准确性 8。通过
effort参数,开发者可以在速度、成本与能力之间进行调节,在中等投入度下,可大幅减少Token使用量 。
3.4 多模态能力
- GLM-5: GLM-5家族包括专门的变体,如GLM-Image(高保真图像生成)和GLM-4.6V/4.5V(高级多模态推理,结合视觉和语言理解) 。它能够处理文本、图像,并可能扩展到视频输入 17。
- Claude Opus 4.5: 支持文本、代码、图片、文档作为输入模态 16。在视觉、推理与数学方面也取得了显著进步 。
4. 竞争优势与独特卖点
4.1 GLM-5 的竞争优势
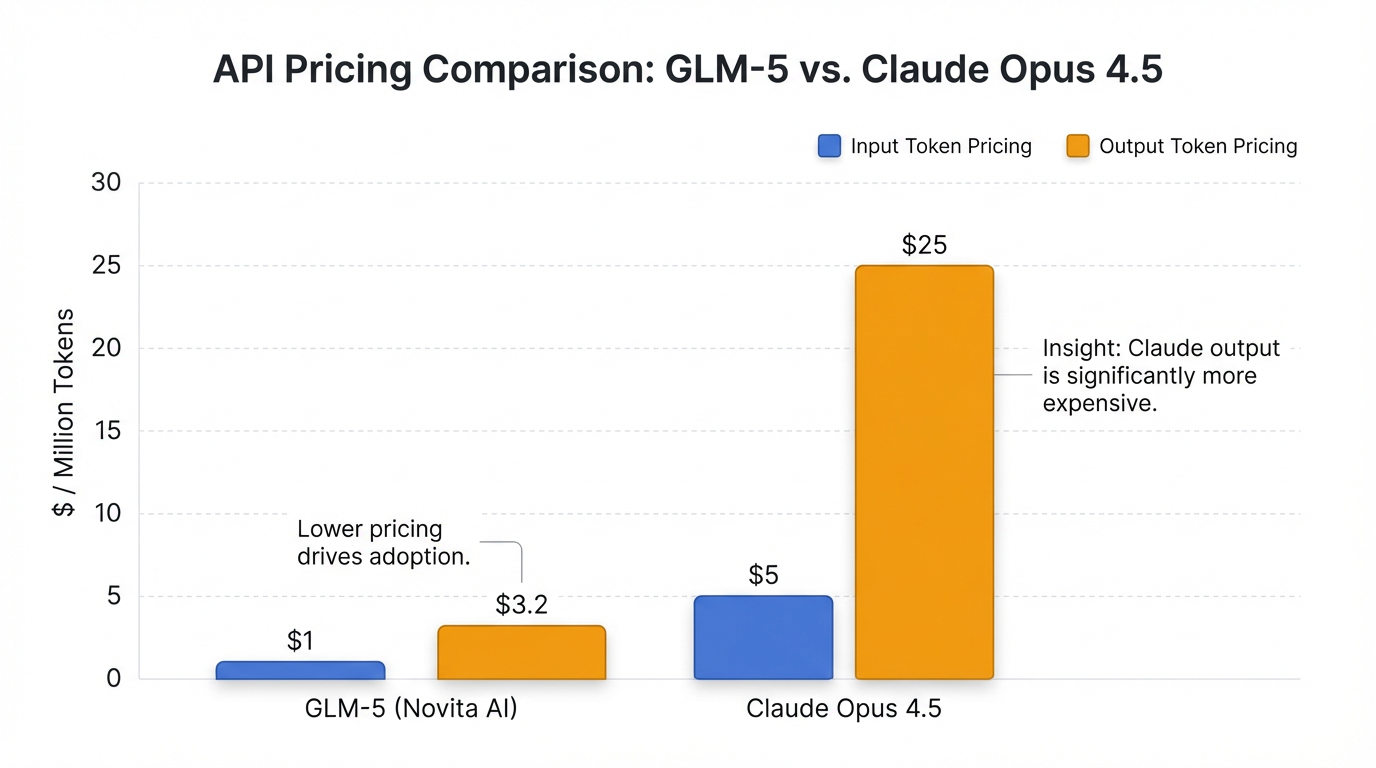
- 开源与成本效益: GLM-5的开放权重和MIT许可证使其对开发者社区极具吸引力 。第三方API定价远低于Claude Opus 4.5的官方定价,例如Novita AI上每百万输入/输出Token分别为$1/$3.2,甚至有报道称比Claude Opus 4.6便宜46倍 。这使得GLM-5成为高性价比的选择,尤其对于需要大规模推理的应用程序 18。
- 国产自主与硬件独立性: GLM-5完全在华为昇腾芯片上训练,采用MindSpore框架,体现了中国在AI领域实现硬件自给自足的能力,具有重要的地缘战略意义 。这使得GLM-5在面临国际技术限制时,能够提供一个独立可靠的AI算力栈 11。
- Agentic Engineering与前端能力: 在前端构建成功率上表现优异(CC-Bench-V2,98.0%),且通过“Slime”训练框架在智能体能力上实现突破,擅长Agentic Engineering 。
- 用户体验: 即使在早期用户测试中,GLM-5在处理复杂任务时也能提供比上一代GLM-4.7更强的体感 19。
4.2 Claude Opus 4.5 的竞争优势
- 顶尖编程精度与人类级表现: 在SWE-bench Verified基准上稳居世界第一,并在人类软件工程测试中超越所有人类候选者 。其代码编写质量和解决复杂漏洞的能力备受赞誉 14。
- 深度推理与“思考模式”: 独特的“思考模式”使其在处理复杂、模糊的任务(如科学研究、新型架构设计)时表现卓越,能够进行有效的自我校正和规划 8。
- 企业级成熟度与生态系统: 围绕Claude Code构建的工具链(如VS Code插件、Agent SDK、Checkpoint功能)和API特性(如结构化输出、Tool Search Tool、Programmatic Tool Calling)使其在企业级研发场景中具有强大的生产力 。Anthropic致力于将其模型对齐高安全标准(ASL-3),并在减少误报率上做出了努力 20。
- 商业模式转型与定价调整: 尽管历史价格昂贵,但Opus 4.5发布时,其API定价有所下降,以吸引更多用户 。Anthropic也明确将战略重点转向企业市场,提供长期可靠的企业级服务 21。
- 地缘政治影响: 鉴于Anthropic对特定地区(如中国资本持有的公司)施加的服务限制,使得Claude Opus 4.5在某些市场可能面临接入挑战,但这同时也巩固了其在美国及其盟友中的战略地位 。
5. 接入与商业化
在API接入和商业化策略上,GLM-5和Claude Opus 4.5展现出截然不同的路径。
- GLM-5: 智谱AI采取了开放共享的策略,其API服务可通过Novita AI、GMI Cloud等第三方提供商接入,定价相对较低,例如Novita AI每百万输入/输出Token分别为$1/$3.2 。智谱AI积极通过“Claude API用户特别搬家计划”吸引受Claude限制影响的用户,提供兼容协议和优惠资源,以降低国内企业和开发者使用顶尖AI编程能力的门槛 。
- Claude Opus 4.5: 可通过Anthropic官网、API及主要云平台(如Google Cloud Vertex AI)访问 。其API定价为每百万输入Token$5,每百万输出Token$25,虽然较之前有所下降,但仍高于GLM-5的第三方定价 。Anthropic致力于将其服务推向全球企业市场 21。然而,出于法律、监管和安全风险考虑,Anthropic已停止向多数股权由中国资本持有的公司提供服务,这为GLM-5等国产模型提供了市场机遇 22。
以下图表展示了主要大模型API的定价对比,直观反映了GLM-5在成本效益方面的优势:
6. 结论与战略意义
GLM-5的推出清晰表明,中国AI模型在技术能力上正迅速追赶并挑战国际顶尖水平。在一些特定基准测试中(如BrowseComp、Humanity's Last Exam带工具),GLM-5已展现出超越Claude Opus 4.5的潜力 11。其开源、高性价比以及完全国产硬件支持的特点,使其成为中国乃至全球开源社区的重要力量,有力地挑战了西方在AI领域的传统主导地位,具有重要的地缘战略意义 。智谱AI通过“平替”和“搬家计划”的策略,积极应对国际竞争,为国内企业和开发者提供了顶尖AI编程能力的可及性 。
与此同时,Claude Opus 4.5凭借其卓越的编程精度、创新的“思考模式”以及成熟的企业级生态系统,继续巩固其在商业化和高复杂度任务解决方面的领先地位 。Anthropic在AI安全和合规性方面的投入,以及其战略性地转向企业市场,都体现了其在构建可持续商业模式上的努力 21。然而,其受地缘政治影响而实施的服务限制,也为GLM-5等其他模型进入特定市场提供了重要机遇,加速了全球AI格局的多元化 22。
总体而言,GLM-5与Claude Opus 4.5的竞争不仅是技术能力的较量,更是商业模式、生态构建和地缘战略的深度博弈。GLM-5的崛起,预示着全球AI格局的多元化趋势,为开发者和企业提供了更广泛的选择,并加速了AI编程和智能体工程的普及。