1. Executive Summary: The Paradigm Shift in Deep Research Agents
1.1 Overview
Atoms Deep Research (internally “MGX-DeepResearch”) is a Multi-Agent System (MAS) for autonomous research and report generation. The system uses an orchestrator that coordinates multiple specialized sub-agents. This multi-subagent architecture improves context management and ensures reliable task execution.
The multi-subagent system handles two core scenarios:
- Resolving specific queries through iterative search and tool application
- Producing comprehensive research reports with structured outputs
Key innovations of the multi-subagent framework include:
- Dynamic plan refinement via guard mechanisms
- Multi-strategy information retrieval for breadth and depth
- Information compression inspired by Information Bottleneck (IB) Theory (discussed in Section 4)
The multi-subagent system addresses challenges like context overload, memory management, and logical inconsistencies. Specialized agents (Deep Search Agent, Browser Agent, Report Writer Agent, Guard Agent) collaborate to refine intermediate results and maintain consistency, leading to more reliable and insightful research outputs over time.
1.2 Key Architectural Differentiators
The core architectural innovation lies in the Orchestrator-led MAS, which directly addresses the inherent challenges of monolithic Large Language Models (LLMs), such as persistent context overload and premature failure in long-horizon tasks. By distributing tasks and specialized knowledge across dedicated sub-agents, the system achieves implicit context compression at the strategic level, allowing the central planner to maintain global consistency throughout extensive execution chains. This modular design provides the necessary structural flexibility to handle the complexity and duration required for PhD-level research tasks.
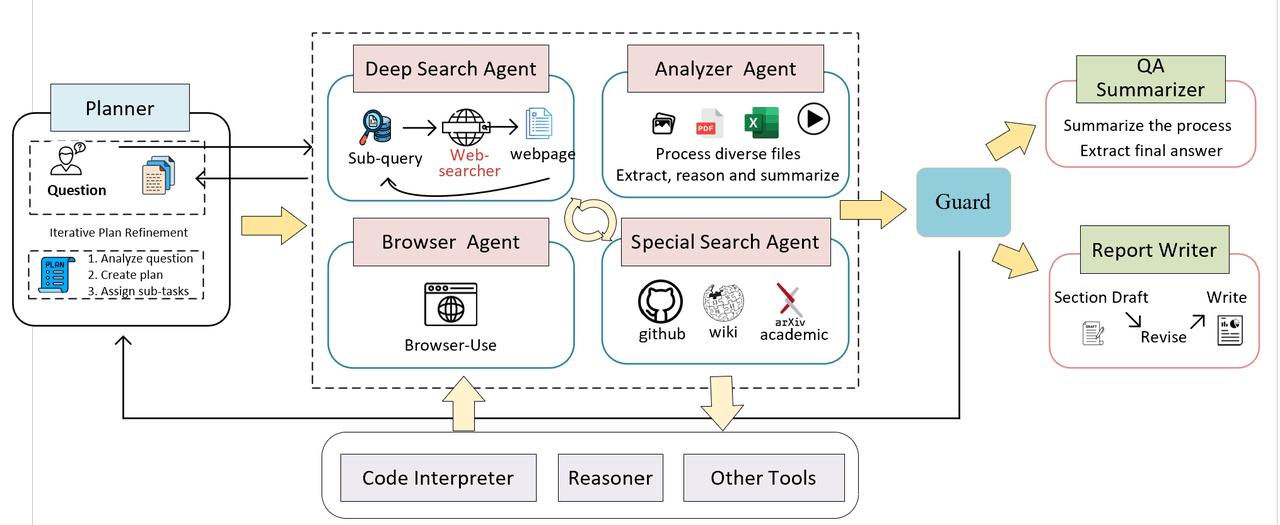
2. Foundational Architecture: Orchestrator-led Multi-Agent System
2.1 Core MAS Architecture and Evolving Capabilities
The Atoms Deep Research system is built around a dynamic, flexible Multi-Agent System coordinated by a central Orchestrator. This architecture is the foundational element that enables efficient execution across lengthy, complex tasks.
The Orchestrator is responsible for global coordination, initiating problem decomposition, formulating plans, and dynamically adjusting strategy based on execution feedback. The system addresses the Orchestrator’s primary challenge (the extensive contextual demands of long-range tasks) by delegating detailed execution and environmental inputs to specialized sub-agents. This mechanism significantly reduces central cognitive load, mitigating the risk of decision-making errors and challenges with context information inherent to traditional single-LLM systems over long sequences.
- Deep Search for Informed Planning: Before finalizing an initial plan, the Orchestrator conducts a round of "deep search" to proactively explore various facets of the problem. This initial exploration phase enriches its understanding, allowing it to formulate a more robust, contextually aware plan that incorporates a greater degree of global information.
- Dynamic Guarding and Plan Refinement: Once the Orchestrator identifies a potential solution, a "Guard Agent" is activated to review the entire reasoning process. This agent identifies inconsistencies or logical flaws, prompting the Orchestrator to refine its plan based on the feedback. This mechanism effectively corrects execution-phase errors, thereby enhancing the plan's overall robustness.
2.2 Specialized Agent Modularity and Collaboration
The modular design relies on a specialized, collaborative suite of sub-agents:
- DeepSearch Agent: The critical component for intensive research and report generation, dedicated to conducting broad, in-depth searches across the web.
- Browser Agent: Handles deep, stateful interactions with specific websites, including autonomous navigation of webpages, structured data extraction, and form interaction, which are essential for accessing information in real-world web environments.
- Special Search Agent: Used to access data sources not readily available through general search engines, such as academic databases like arxiv, historical wiki archives, and specialized information from GitHub repositories.
- Analyzer Agent: Processes diverse input files, performing tasks such as information extraction, reasoning, and summarization of user-provided data.
- Report Writer Agent: Dedicated to transforming gathered information into a coherent, structured output, focusing primarily on the creation and revision of the Section Draft.
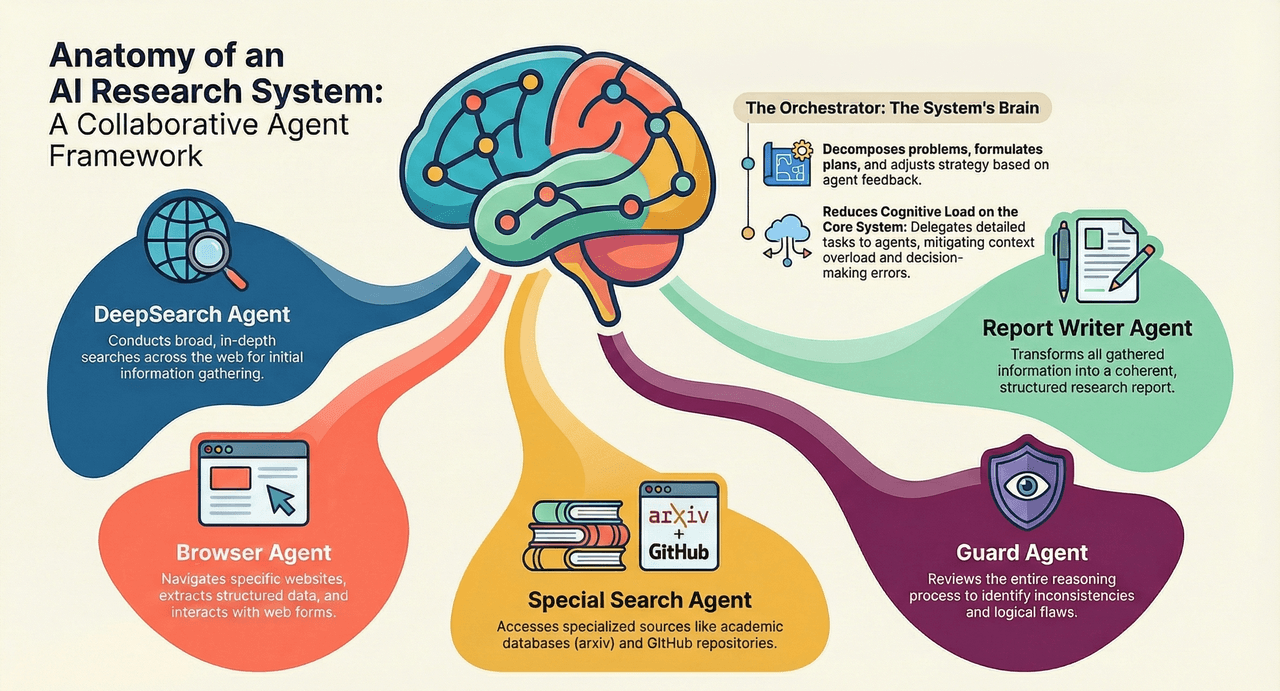
3. Deep Search Innovation: Test-Time Diffusion and Iterative Denoising
3.1 Iterative Search Plan Refinement (Breadth Strategy)
The DeepSearch Agent employs a dual Breadth and Depth strategy to ensure comprehensive coverage and precise focus. The Breadth strategy centers on maximizing the agent’s receptive field and improving memory efficiency.
The initial search plan, based on the user query, undergoes dynamic refinement and continuous optimization as intermediate results are generated. The system focuses on enhancing information density: from a large initial pool of approximately 60 candidate pages, an internal LLM selects only the most critical and relevant sources. These selected references are then synthesized to form intermediate answers, thereby counteracting the typical problem of information loss in sequential RAG systems by maximizing the retrieved signal-to-noise ratio.
3.2 Reasoning with Sub-query Decomposition (Depth Strategy)
The Depth strategy provides a structured, verifiable approach to deep reasoning for highly complex problems. The process begins with systematic Query Decomposition, where complex questions are broken down into a manageable sequence of sub-queries, creating an explicit "Checklist".
The Deep Search Agent mandates verification of each intermediate step to ensure informational completeness before proceeding. After the search associated with a Checklist item concludes, the process explicitly identifies and notes "Missing Information Point out" points. Search strategies are then dynamically optimized based on intermediate results, involving sophisticated query rewriting to refine search terms when initial attempts yield insufficient data.
3.3 Self-Optimizing Reasoning: Quality-aware Reward via Cross-Fusion Reasoning
The collaboration among Deep Search, Browser, and Special Search Agent ensures comprehensive, fault-tolerant retrieval. This agent complementarity means the system accesses disparate information channels:
- The Deep Search Agent for the broad web
- The Browser Agent for handling stateful, interactive web data (autonomous webpage navigation)
- The Special Search Agent for specialized archives
A key differentiator of Atoms Deep Research is its iterative enhancement of agent memory information density. Through sophisticated memory management techniques, the system:
- Increases information density in agent memory, allowing for more efficient storage and retrieval of critical knowledge
- Integrates multi-source information seamlessly, creating a unified knowledge base with enhanced coherence
- Executes reverse sampling processes on memory, enabling the system to synthesize the most probable answers from dense information clusters
3.4 Multi-Source Verification and Denoising
The system employs a verifier-based quality assessment and conflict detection mechanism that performs alternating cross-validation across multiple retrieval results:
- Quality Judgment: The verifier evaluates the reliability and relevance of information retrieved from diverse sources, filtering out low-quality data through explicit quality metrics
- Conflict Detection: Identifies contradictory information across multiple search channels, enabling the system to resolve inconsistencies through iterative refinement
- Alternating Cross-Validation: Implements multi-path result verification where different agents (Deep Search and Browser Agent) work in harmony to cross-validate findings, creating a dynamic workflow that identifies and corrects conflicting information
- Iterative Denoising: Through the "Multi-source Search Iterative Denoising" process, contradictory or unreliable data is refined and corrected across multiple iterations, with each iteration incorporating explicit feedback to enhance precision
This approach uses a self-evolutionary mechanism to achieve consistent, reliable performance. The Deep Search and Browser Agent collaborate to identify conflicting information and verify low-quality data through multi-engine analysis. By employing iterative searches and cross-validation, unreliable data is refined, incorporating feedback to enhance precision. The Guard Agent ensures logical consistency, driving quality improvements, as evidenced by benchmark results such as XBench and GAIA.
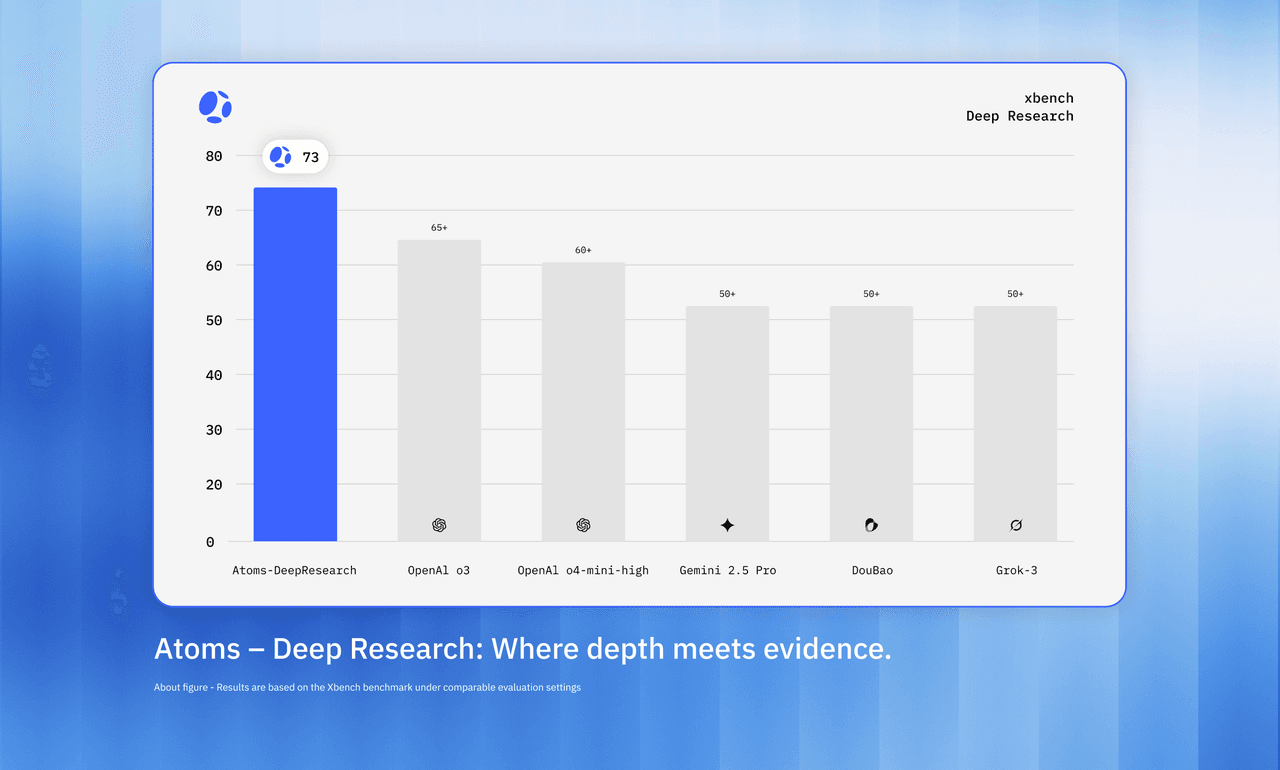
3.5 Information Retrieval Performance (XBench & GAIA)
The efficacy of the system's structured search methodology is quantified by the XBench-DeepSearch benchmark, which evaluates performance on intensive search and retrieval tasks. Atoms Deep Research achieved a score of 73 on the XBench-DeepSearch benchmark, demonstrating a substantial performance advantage over other market competitors. This definitive lead validates the effectiveness of our dual-strategy search methodology in complex, real-world retrieval tasks.
Moreover, through iterative enhancement of the agent’s memory information density, integration of multi-source information, and execution of a reverse sampling process on memory, the system can synthesize the most probable answer.
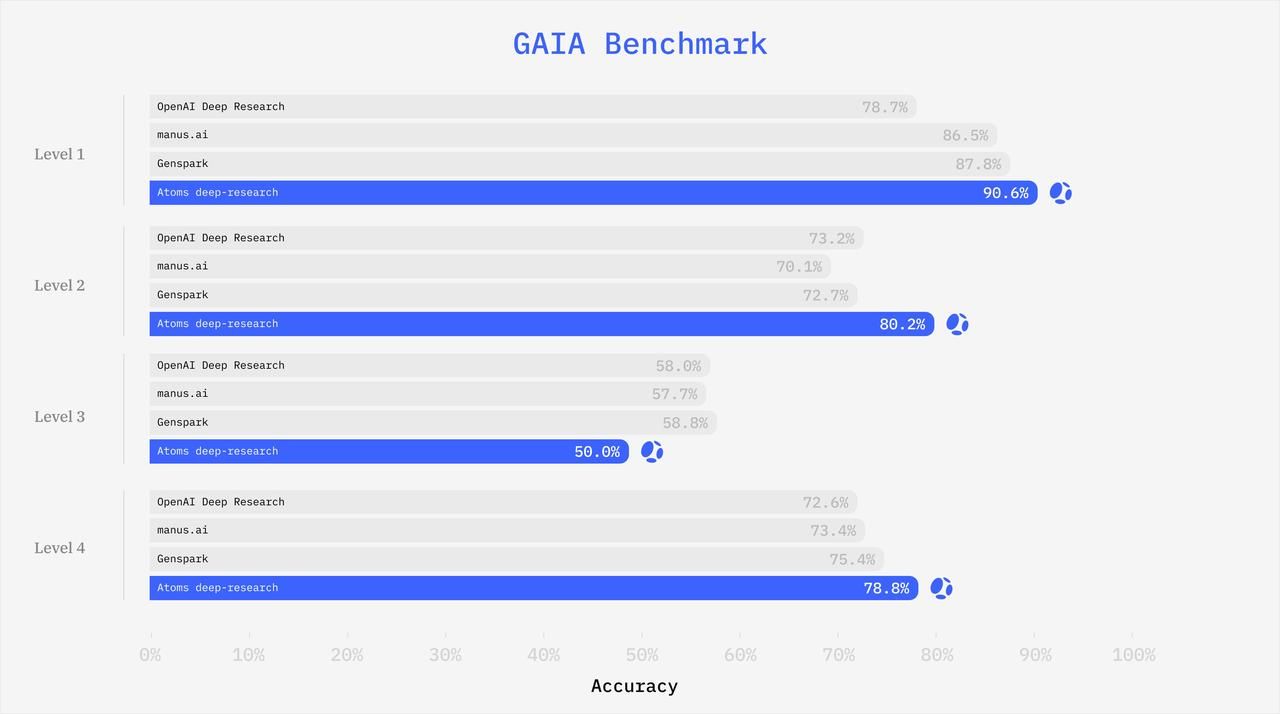
The Atoms Deep Research system's high performance on the GAIA benchmark directly validates its capacity for complex, multi-channel information cross-fusion reasoning. GAIA questions require reasoning, multi-modal handling, web browsing, and comprehensive tool-use proficiency, often involving synthesizing information from disparate sources such as the general web, specialized academic databases, and user-provided files.
The GAIA benchmark results demonstrate Atoms Deep Research’s proficiency as a General AI Assistant, particularly in high-complexity tasks:
4. Knowledge Synthesis: Information Bottleneck for Insightful Report Generation
The primary function of the Report Writer Agent is to transform the vast and unstructured information gathered by the Deep Search Agent into a coherent, well-structured, and insightful report. The main challenge is to avoid simple information stacking, which leads to a lack of depth, and poor information organization, which impairs readability. These issues arise from cognitive overload in processing massive amounts of raw data, hindering global understanding and deeper analysis.
Inspired by the Information Bottleneck (IB) Theory, we emphasize compressing information before organizing content, recognizing AI's limited "channel bandwidth" or cognitive capacity to process raw data, which can cause cognitive overload. Our approach compels the system to focus on identifying structural relationships within data rather than merely summarizing facts. This limitation allows the creation of reports that perform well on qualitative metrics like "Insight."
The process begins with a preliminary Section Draft that functions as an updatable, evolving skeleton guiding research direction. This draft undergoes iterative "denoising" where new retrieval results dynamically inform revisions, ensuring global structural coherence across lengthy documents. This draft undergoes multiple revisions in a process we call "test-time scaling" to sharpen its arguments and structure. The final, insightful report is then generated from this highly refined, information-dense guide, ensuring superior organization and logical flow.
By focusing architectural effort on generating a highly refined, high-density draft before the final write-out, the system minimizes the computational and contextual burden of generation. The quality and structural integrity are established at the draft stage, allowing the final report generation to be primarily a stylistic rendering of an already perfected structure.
4.1 Enhancing Quality: The Report Generation Performance (DeepResearch Bench)
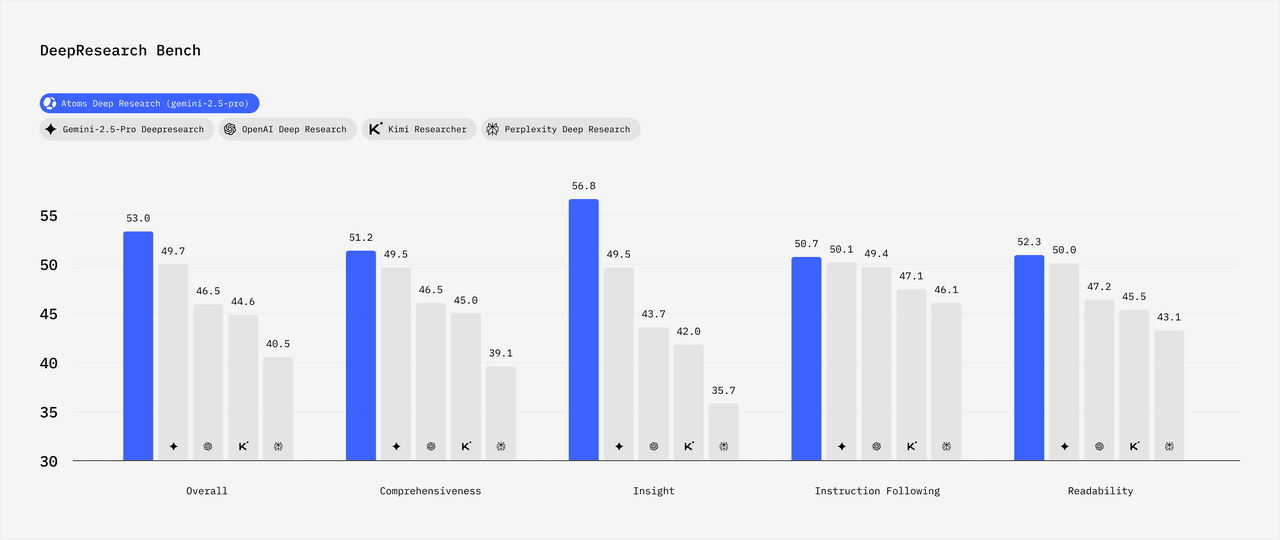
Atoms Deep Research achieves state-of-the-art performance on the DeepResearch Bench, with overall scores outperforming Gemini-2.5-pro and OpenAI DeepResearch by 4.1% and 7.3%, respectively. The architecture is grounded in Information Bottleneck theory, specifically benefiting metrics such as Insight and Readability. Atoms Deep Research provides a strong structural support for coherence and integrity across lengthy reports, which is critical for both Comprehensiveness and Readability.
4.2 Frequently Asked Questions
Q1. What kinds of tasks is Atoms Deep Research best suited for, and where does it still struggle
Atoms Deep Research is optimized for long-horizon, multi-step research tasks: questions that require web searches, browsing, cross-checking multiple sources, and synthesizing a structured report rather than a single-paragraph answer. It is less suitable for tasks that require real-time data with strict latency constraints, tasks dominated by private/internal tools it cannot access, or domains where no credible public sources exist and expert human judgment is essential.
Q2. How reproducible are the results, given that the system uses stochastic LLMs?
Individual LLM calls are stochastic, but the system constrains this variability through explicit plans, checklists, Section Drafts, and verifier feedback. For a fixed query and configuration, repeated runs tend to converge to structurally similar reports, even if wording differs. For high-stakes use cases, we recommend treating Atoms Deep Research as a collaborator: run multiple drafts when needed, inspect cited sources, and preserve the intermediate artefacts (plans, checklists, drafts) as part of your review process.
Q3. How does Atoms Deep Research relate to general-purpose LLMs and other “deep research” products?
Atoms Deep Research is a multi-agent orchestration layer built on top of frontier LLMs; it does not replace base models such as GPT-4-class or Gemini models, but coordinates them. Compared with single-model “ask a question, get an answer” setups, it adds explicit planning, tool use, browsing, multi-source verification, and an Information Bottleneck–style report-writing pipeline. In our internal benchmarks (XBench-DeepSearch, GAIA, and DeepResearch Bench), this architecture delivers higher accuracy and insight quality than strong general-purpose baselines under comparable settings.
Q4. How does the system respond to conflicting or low-quality information?
When sources disagree, the verifier and Guard Agent explicitly flag conflicts and low-confidence segments. The DeepSearch, Browser, and Special Search Agents then re-query, re-rank, or discard problematic sources through the multi-source iterative denoising process described in Section 3. This does not eliminate the need for human judgment, but it makes contradictions visible rather than silently averting them.
Q5. How can I use Atoms Deep Research in practice?
Atoms Deep Research is exposed in the product as the research agent “Iris”. You interact with it in natural language: define the research goal, refine the scope and constraints, and then inspect and iterate on the generated report. For teams with existing stacks, Iris can serve as a front-end to Atoms Deep Research for exploration, early-stage analysis, and draft report generation, with critical outputs reviewed and incorporated into your own processes.
Try Atoms Deep Research in Atoms today.
