1. Overview
In Atoms Deep Research v2.0, we implemented a series of system-level optimizations on top of the v1 architecture (for an introduction to Atoms Deep Research itself, see the v1.0 technical report). These changes brought measurable improvements in report quality, search efficiency, and overall time cost, without a significant increase in API spending.
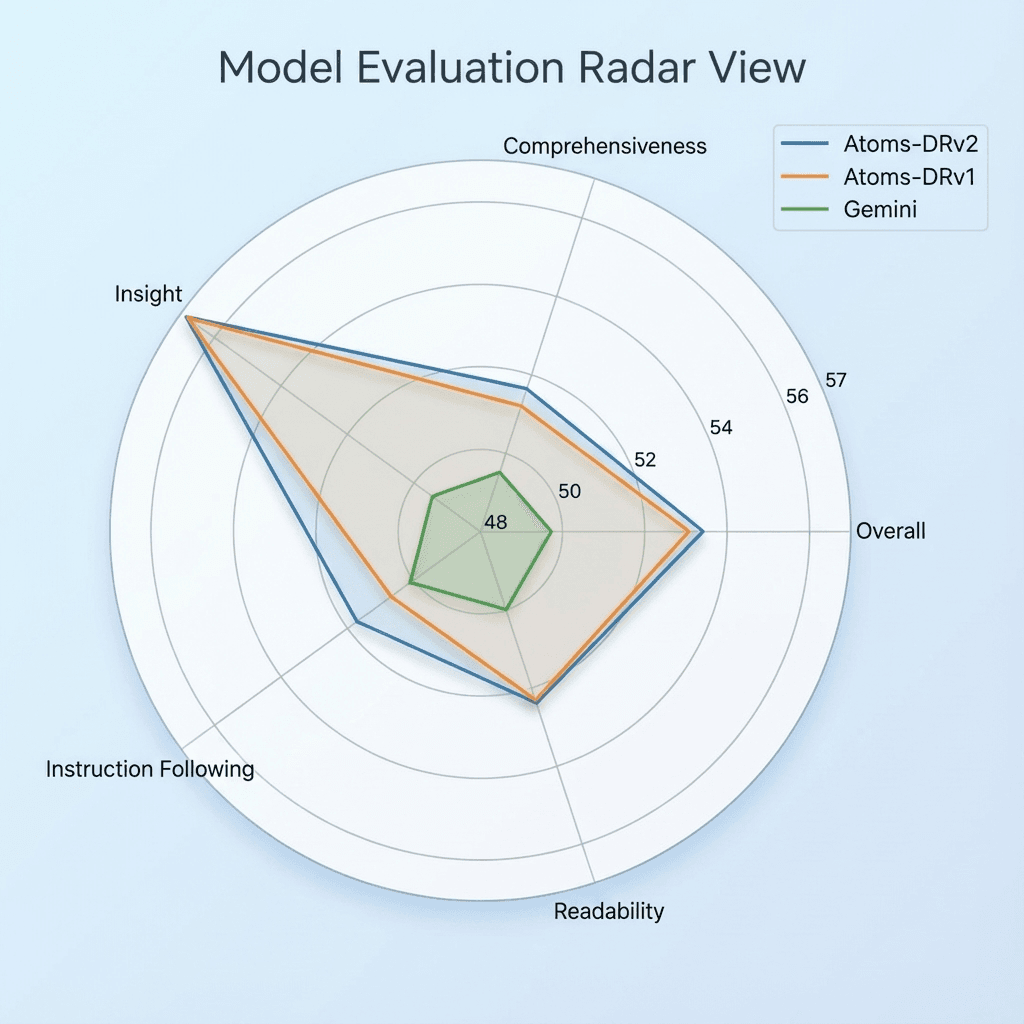
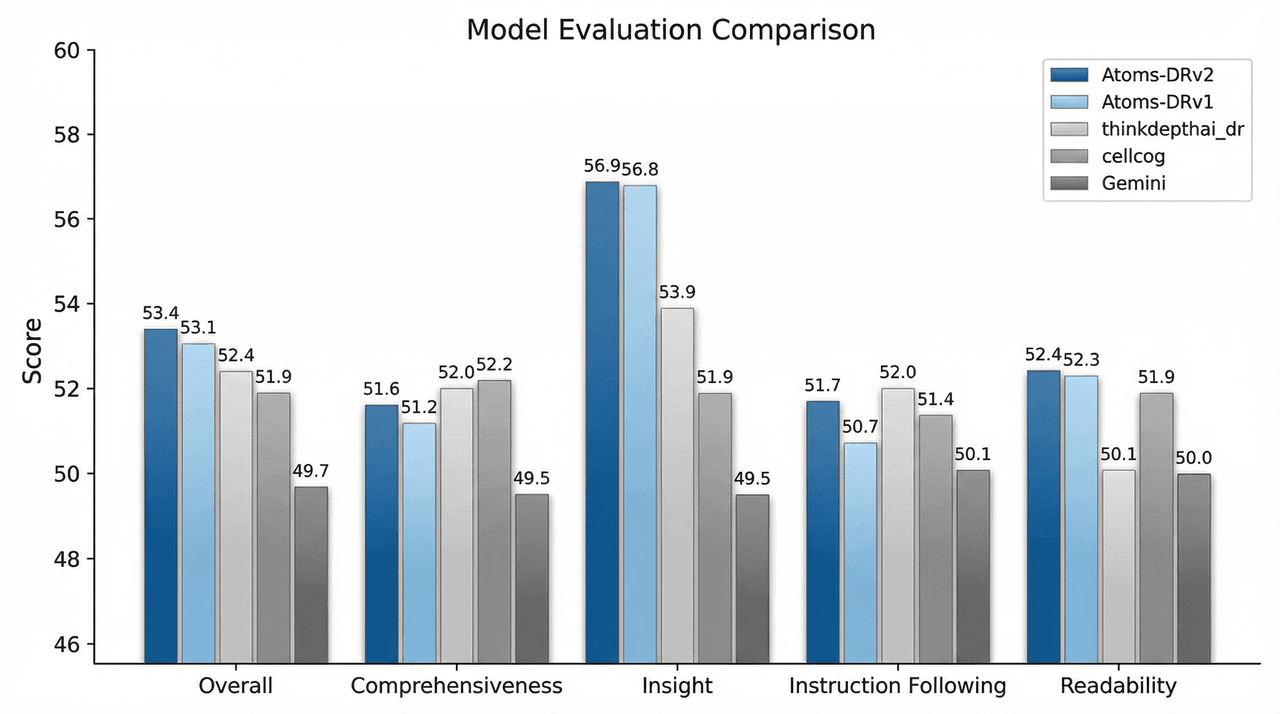
On the quality side, we evaluate report generation using DeepResearch Bench. Overall, Atoms Deep Research v2.0 achieves a modest but consistent improvement of about +0.3% over v1.0, while the Instruction Following dimension improves by about +1%, indicating that v2 is more stable and reliable when interpreting and executing complex instructions.
In resource-constrained settings, where we limit the number of generation rounds and search depth, v2.0 maintains system stability while increasing report quality from 0.30 to 0.379 (+26%). In the same regime, the Instruction Following score rises from 0.31 to 0.45 (+42%), suggesting that the multi-agent system’s decision consistency during report writing has improved substantially.
On the performance side, information collection efficiency scales with the degree of parallelism. At the same time, search diversity improves: the average pairwise Levenshtein distance between sub-queries increases, the number of unique URLs in search results grows by 17%, and the number of unique domains by 12%. Retry counts drop, and overall system stability improves.
On the cost side, when we fix the number of generation rounds and search depth, average end-to-end latency decreases by about 11%. This is mainly due to multi-source and multi-query parallelism in DeepSearch. API costs remain roughly flat: LeadAgent’s context compression significantly reduces input tokens, but the additional control logic in DeepSearch SubAgents adds some overhead. Overall, spending remains approximately the same as v1.0.
These gains do not come from a single trick. Instead, they are the result of four complementary lines of system design work:
- Context optimization
- Semantic-guided search
- Multi-source fusion strategies
- Parallel query generation
2. What Is DeepResearch?
DeepResearch is an agent system that can reason over and integrate large volumes of online information to complete multi-step research tasks. Unlike tools that simply aggregate search results, DeepResearch actively discovers, reasons about, and synthesizes insights from across the web. It is designed for use cases where research depth and precision matter: financial and investment analysis, scientific literature reviews, policy research, engineering design evaluations, and even complex personal decisions such as choosing a car or a major purchase. Each output includes a traceable reasoning process and source citations, making the result auditable rather than opaque.
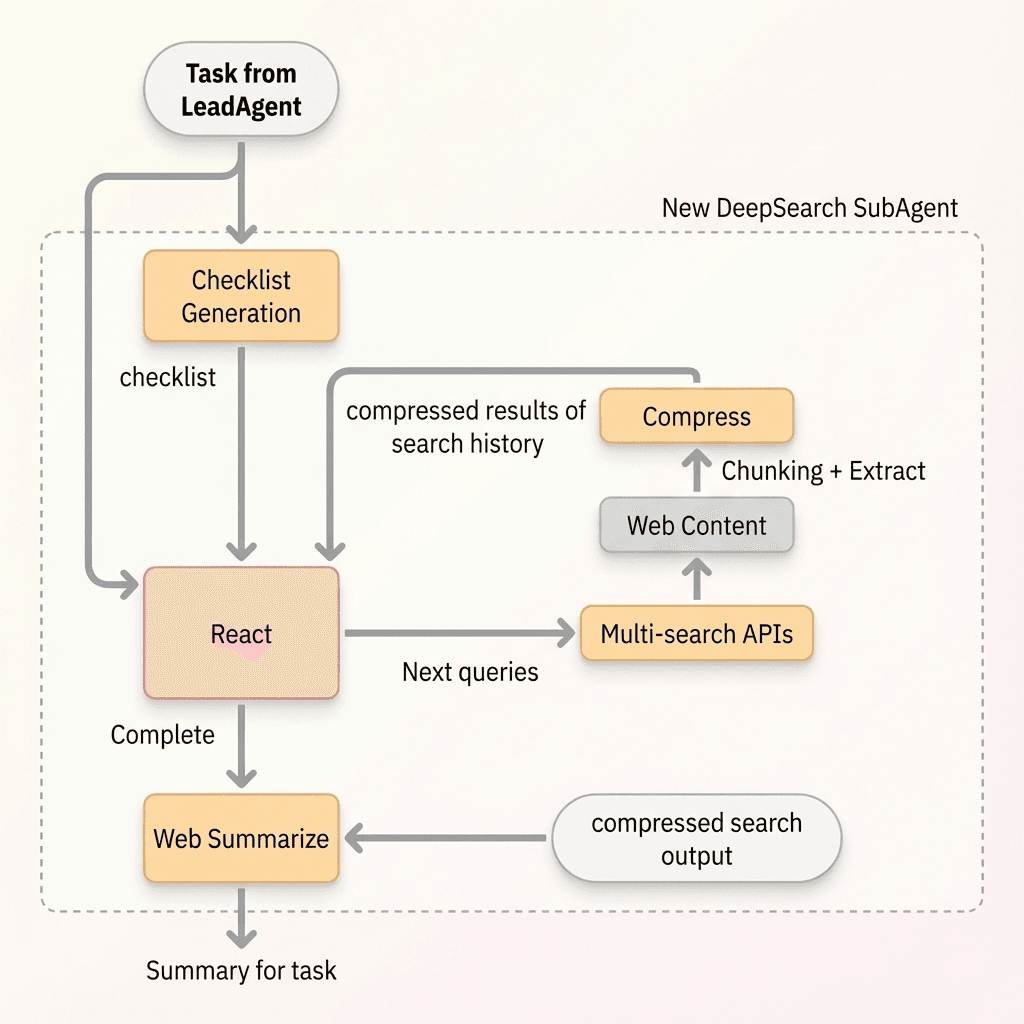
Technically, Atoms Deep Research adopts a distributed LeadAgent + multi-SubAgent architecture. The LeadAgent is responsible for global research planning and decision-making. Specialized SubAgents such as DeepSearch and SectionWriter handle information retrieval, multimodal understanding, and content generation. This architecture is flexible and extensible, but it also introduces new challenges in long-horizon reasoning, coordination, and search efficiency.
3. Core Challenges in Long-Horizon DeepResearch
From a systems perspective, DeepResearch is essentially a long-horizon recursive task of “information expansion → deep reasoning and distillation.” As interaction rounds and context size grow, the system faces serious degradation risks. Two core bottlenecks emerge: LLM decision stability deteriorates under high information load, and the marginal information gain from each additional search step quickly plateaus.
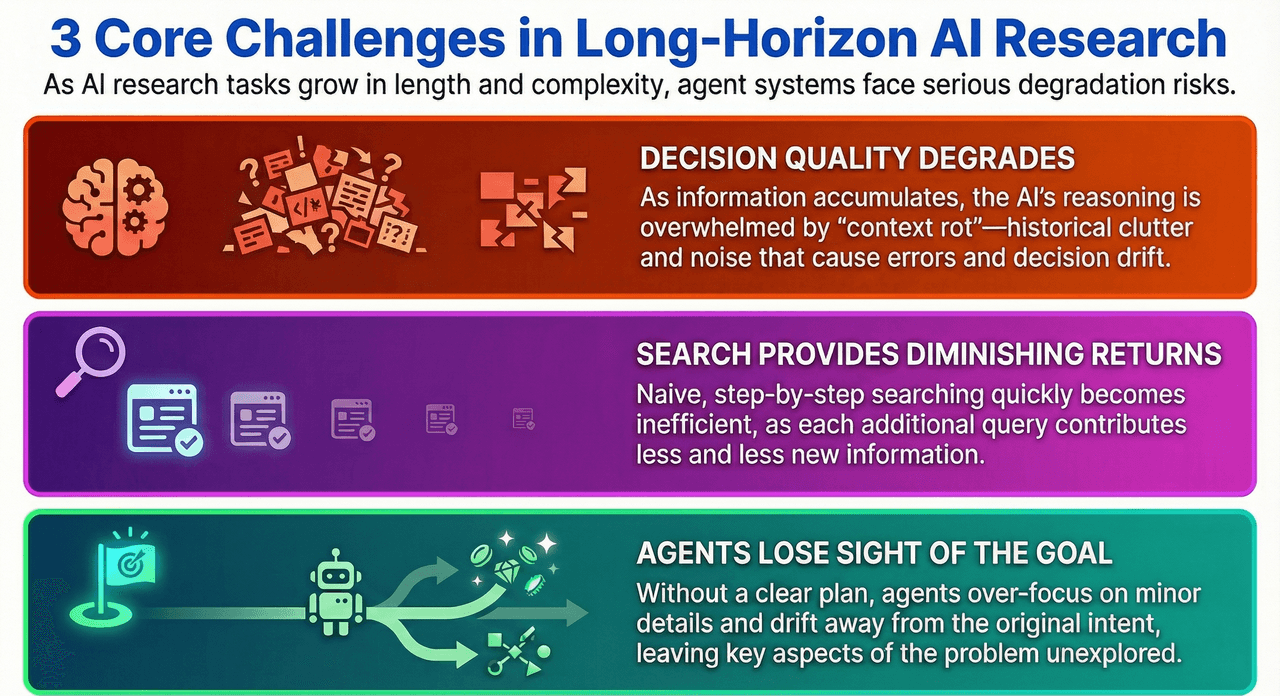
Concretely, we frame the challenge as three sub-problems.
3.1 Problem 1: Decision Quality Degrades as the Information Chain Grows Longer
In prolonged tasks, the LeadAgent operates as the "central brain," integrating diverse information sources such as search fragments, reasoning states, and draft sections. The challenge arises not merely from increasing token counts but from a sharp rise in contextual entropy. As unstructured fragments accumulate, the attention mechanism struggles to prioritize relevant constraints, leading to decision drift, formatting errors, or hallucinated outputs.
This phenomenon, known as context rot, occurs when historical clutter and execution noise overwhelm the agent’s reasoning, collapsing the signal-to-noise ratio and impairing performance.
3.2 Problem 2: Diminishing Information Gain from Search
DeepResearch requires broad and deep support from external information, but a naive SearchAgent design quickly runs into diminishing returns. Relying on a single search engine limits information density and coverage because of that engine’s index and ranking biases. Using a single query per step is also insufficient: complex research goals cannot be fully captured by a single query phrase.
If the agent follows a serial “one query at a time” process to expand coverage, it must increase the number of interactions and incur high latency. At the same time, each additional search contributes less and less new information.
3.3 Problem 3: Completeness in Open-Ended Complex Search Tasks
In high-complexity, high-ambiguity search tasks, a linear pipeline that directly converts the user’s query into search actions is often incomplete. Without decomposing the task into explicit dimensions in advance, the agent cannot establish clear definitions of search coverage and depth. It tends to over-focus on local details and drift away from the original intent over long chains of decisions.
Lacking an explicit notion of completeness, its search actions become fragmented, and key aspects of the problem may never be explored.
In Atoms Deep Research v2.0, we explore several practical strategies to address these problems and record their trade-offs through experiments.
4. Method 1: Context Compression and Content Normalization for Decision Quality
4.1 Problem Observation
In the Atoms Deep Research multi-agent framework, performance issues arise as task chains lengthen. The LeadAgent’s planning drifts due to accumulated intermediate artifacts, leading to reduced focus and decision quality. Similarly, the DeepSearch SubAgent struggles with instruction adherence as context windows fill with unstructured noise, resulting in parsing failures.
These challenges, common in long-context agent systems, are mitigated in some frameworks through methods like content pruning, structured progress tracking, and LLM-based summarization to preserve critical reasoning space.
4.2 Layered Design: Structured Communication and Dynamic Compression
To address these issues, we introduce a two-layer optimization approach that spans cross-agent communication and internal processing within SubAgents.
4.2.1 Structured Communication Between Agents
At the communication layer, we define a structured interaction protocol so that SubAgents only exchange dense, high-value information.
Each SubAgent generates outputs in a fixed schema that makes it easy to extract:
- Titles and high-level conclusions
- Key parameters and signals
- Minimal metadata required for downstream agents
Detailed logs, intermediate reasoning, and raw search traces are stored externally rather than kept in the active context. Agents only pass around compact, structured summaries of what they have found. This keeps cross-agent communication high-signal and low-noise and prevents execution traces from polluting the LeadAgent’s working context.
4.2.2 Dynamic Compression Strategies Inside SubAgents
At the algorithmic layer, we design and evaluate three compression strategies with different granularities. All of them share a common preprocessing step: we recursively segment raw search results into smaller text chunks using NLTK-style splitting, and then apply one of three approaches.
- Direct Summarization: Concatenate all search results and ask an LLM to generate a detailed summary. This preserves almost all information (around 92% information retention), but incurs 8×–10× the latency of a baseline filter and greatly increases the number of output tokens.
- Fact-Centric Compression: Instruct the LLM to extract “Fact–Chunk_ID” pairs, keeping key facts and their original references. This achieves a medium information retention rate (around 85%), with 3×–5× latency and a higher risk of format errors in the Fact–ID schema.
- Chunk-Filtering (selected as default): Use the LLM to quickly scan all chunks and output only the IDs of those strongly related to the current query, discarding irrelevant chunks without any generative rewriting. This retains roughly 71% of information, but runs at about 3 seconds per step (our baseline), with very low token output and almost no format noncompliance.
Information Retention Rate and Information Coverage Rate are measured using “information points” from the RACE test set in DeepResearch Bench, offering a structured way to evaluate compression methods. While Chunk-Filtering preserves less information per step, it is the default strategy in Atoms Deep Research v2.0 due to its stability and efficiency in long-horizon tasks.
Fact-Centric compression often struggles with format adherence under complex conditions, increasing retry costs, whereas Chunk-Filtering completes in seconds with minimal errors. Its ability to inject low-noise, relevant content ensures effective accumulation across search rounds, enabling sharper reasoning and better signal capture in extended contexts.
4.3 Experimental Results: Shorter Context, Better Instruction Following
In resource-constrained ablations where we cap the number of generation rounds and search depth, we introduce the structured compression protocol into cross-agent communication and enable Chunk-Filtering inside DeepSearch.
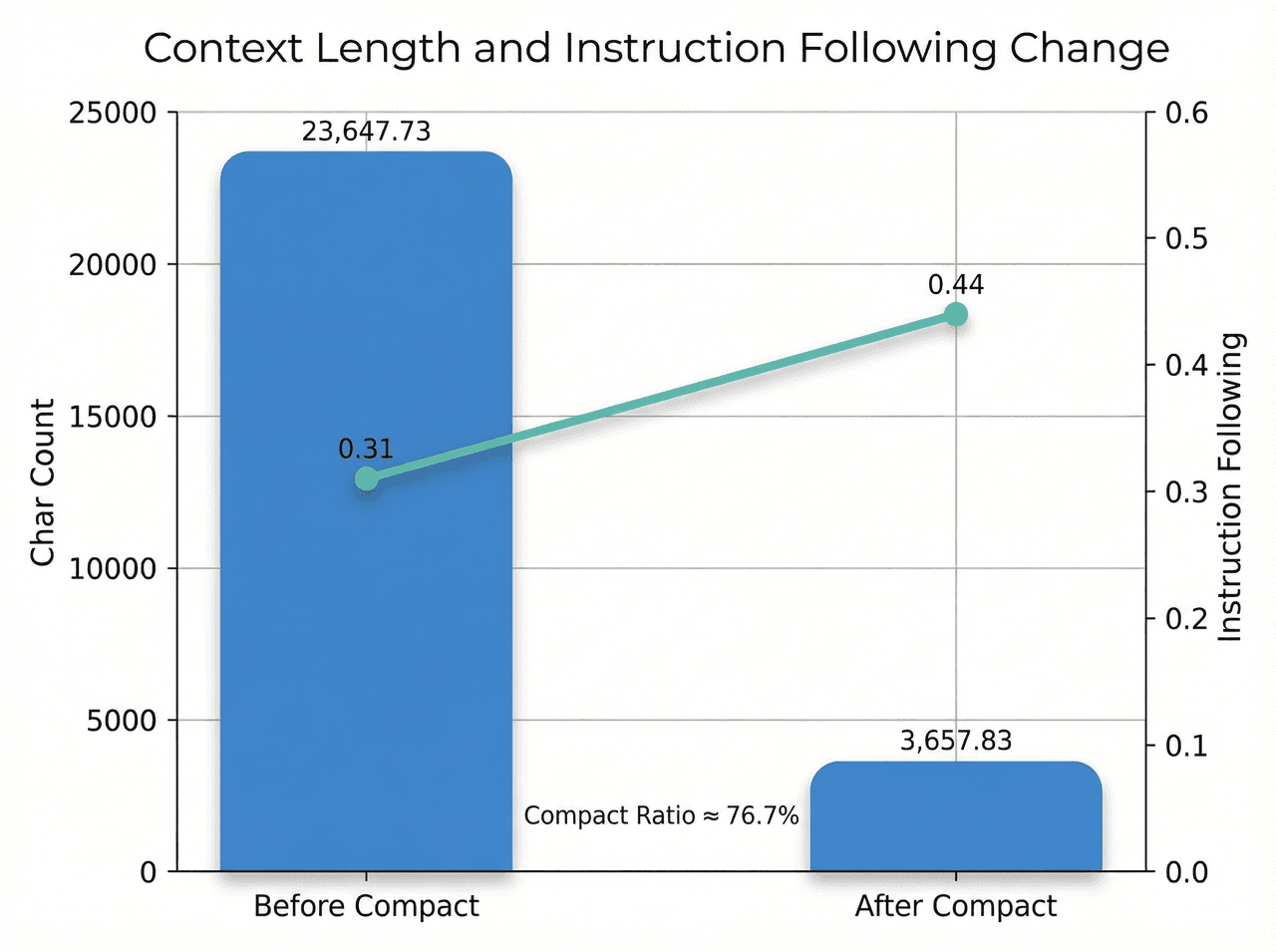
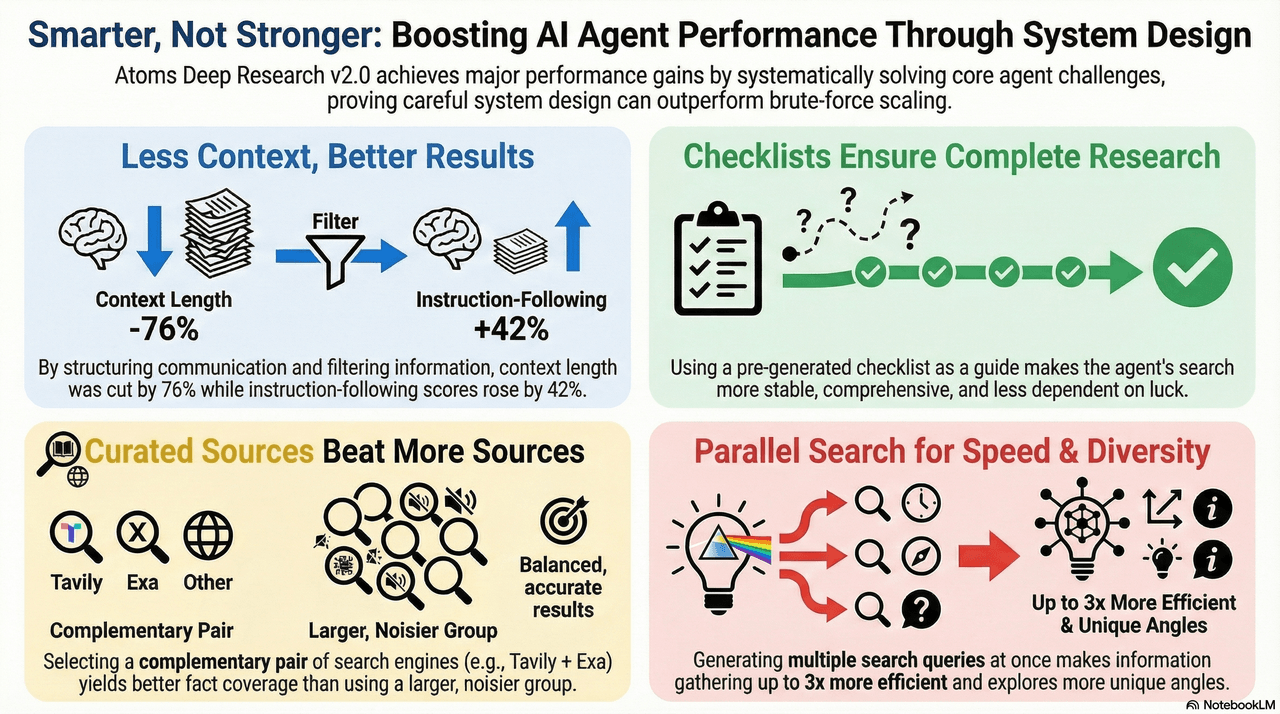
The results are clear. For the LeadAgent’s ReAct component, the average context length (excluding static instructions) drops from about 23.64k tokens to 3.6k tokens, a reduction of roughly 76.7%. At the same time, the Instruction Following score on the RACE-style DeepResearch Bench increases from 0.35 to 0.42. This shows that we can dramatically shrink the context while making adherence to instructions more stable rather than worse.
For DeepSearch, enabling Chunk-Filtering yields significant improvements across metrics. Overall comprehensiveness increases by about 3%, the insight dimension improves by about 4%, and the total score increases by about 2%, all while keeping Instruction Following roughly flat. In other words, compressing information in a structure-aware way improves long-chain performance rather than harming it.
4.4 Design Insight
This is not a complicated design, but it highlights an often-overlooked principle in multi-agent system design: it is not enough to optimize context length; we must optimize context structure. Chaotic but abundant information is less valuable than concise and well-structured information.
When defining communication protocols between agents or inside an agent’s internal memory, we should prefer inherently compressible formats: structures that separate core conclusions from reconstructible details. This design choice is cheap, but its benefits compound in complex long-horizon tasks.
5. Method 2: Multi-Search-Engine Fusion and Parallel Sub-Query Generation
5.1 Why Naive Multi-Engine Fusion Fails
Addressing the challenge of diminishing information gain in search requires two key approaches:
- Each search step should focus on maximizing effective information output by integrating results from multiple search engines.
- Successive queries should emphasize diversity, reducing redundancy through varied sub-queries.
While combining search engine results may seem simple, it demands adaptation to differing algorithms and the strategic use of complementary strengths across diverse SERPs.

The search module in DeepResearch utilizes a “Multi-Source Retrieval → Rank Fusion → Top-K Selection” pipeline, but including too many engines often results in diminishing returns and even regressions. Experiments showed that secondary engines sometimes introduce low-quality, SEO-driven pages, displacing valuable content like official documentation in Top-K rankings.
This issue arises from a fixed Top-K window, where noisy sources compete for limited slots, often pushing out high-relevance results. To optimize, the focus should shift from refining fusion algorithms to strategically selecting which engines to query based on the intent, maximizing the signal-to-noise ratio before fusion.
5.2 Experimental Results: Choosing the Right Engine Combination
To quantify these effects, we build a fact-coverage-based evaluation on DeepResearch Bench. For each Criterion in the dataset, we convert its Explanation into a fact checklist and use a lexical similarity method (LasJ) to measure how well search results cover these facts. We then apply a Weighted Reciprocal Rank Fusion (WRRF) strategy to fuse results from different engines and compare engine combinations at the same search depth.
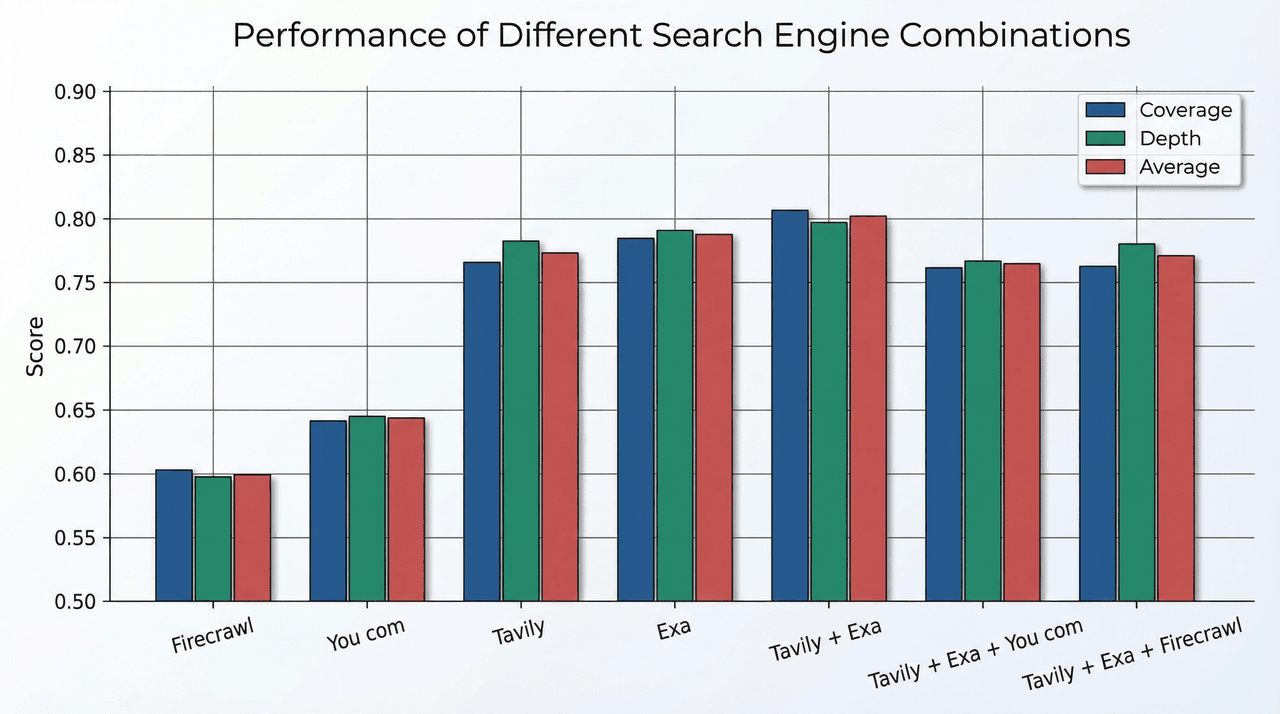
The key finding is that the combination of Tavily and Exa yields the best performance. This pair reaches an average score of 0.802, compared with 0.773 for Tavily alone, an improvement of about 3.8%. It also achieves the highest values in both “comprehensiveness” and “depth,” indicating that the two engines are strongly complementary.
However, when we add third-party APIs such as Serper or Firecrawl on top of Tavily + Exa, overall performance declines. The extra engines introduce noise that competes for Top-K slots and hurts coverage of high-quality sources.
In Atoms Deep Research v2.0, we therefore prefer a carefully selected combination of engines over an “all engines all the time” strategy.
5.3 Parallel Sub-Query Generation for Diverse and Efficient Search
The second angle of the search problem concerns the diversity and efficiency of sub-queries. In a standard sequential ReAct process, the search system in each round executes a sub-query, gathers results, and then uses those results to generate the next sub-query. This iterative refinement can help correct early mistakes, but it also produces two issues:
- Intermediate results tend to guide the LLM into deepening a single dimension of analysis rather than exploring new ones, creating a “local well” of attention.
- Each iteration must wait for the previous one to complete, which limits the throughput of information gathering.
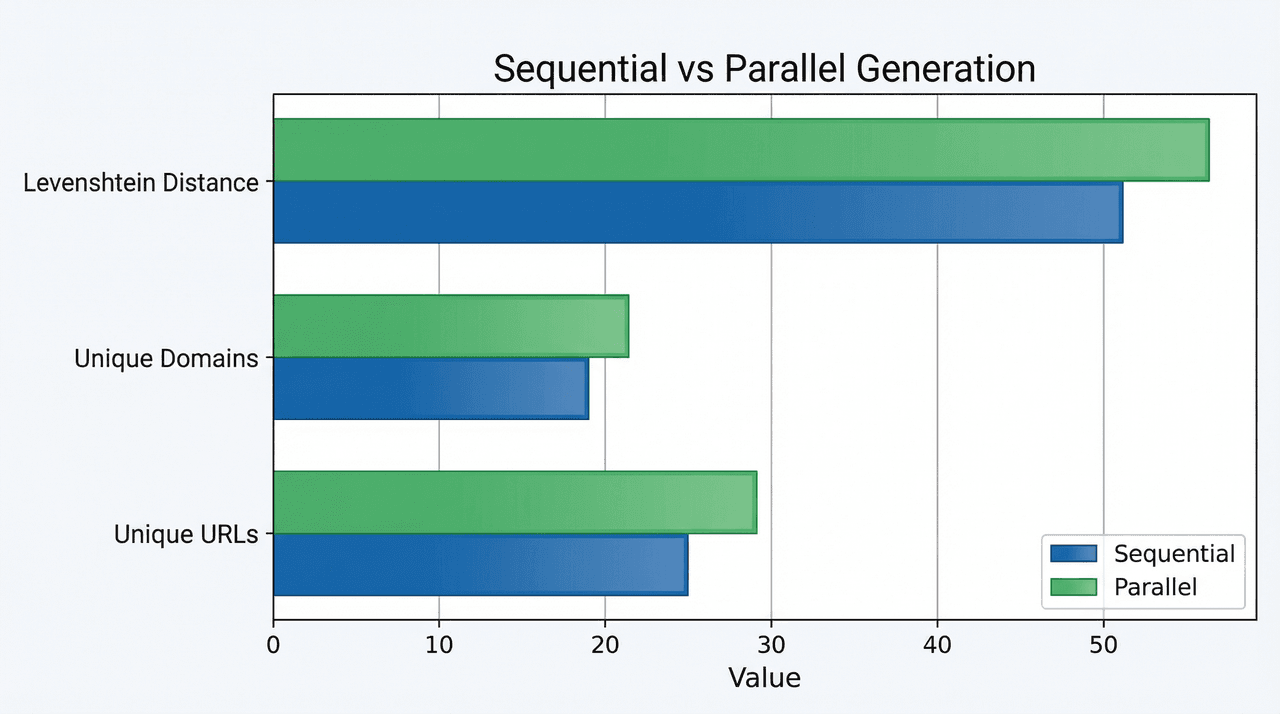
In Atoms Deep Research v2.0, we instead generate multiple sub-queries in parallel. The LLM produces a set of distinct query angles in a single shot, and the system executes them concurrently. This change has two main benefits:
- Qualitatively, it forces the model to consider “from which distinct angles should I look at this problem,” rather than following a single, narrow path guided by the first round of results.
- Quantitatively, we observe increased pairwise Levenshtein distances between sub-queries and higher counts of unique URLs and domains in the aggregated search results. The diversity of the search footprint improves.
On the performance side, parallel sub-query generation naturally enables parallel retrieval. Information acquisition throughput scales roughly with the number of parallel queries. In practice, we see multi-fold improvements in characters retrieved per second, with Atoms Deep Research v2.0 reaching around 16k characters per second in our benchmarks.
6. Method 3: Checklist-Based Semantic Guidance for Complex Search
6.1 Instability in Open-Ended Search
The DeepSearch SubAgent has a straightforward mandate: given an initial user query, it must use multi-round search to uncover information. In practice, however, we consistently observe instability across runs for the same query. Sometimes the search covers many relevant dimensions of the question; other times it gets stuck in a single narrow angle. Sometimes it discovers heterogeneous, high-value sources; other times, it returns near-duplicates of earlier results.
At first glance, this might be a prompt-engineering issue. But careful tuning of prompts produces only limited gains. The diversity and coverage of search remain noisy from run to run.
The underlying reason is that sub-query generation operates in an unconstrained space. Given a complex, multi-dimensional research question, the LLM must implicitly guess all relevant aspects on its own. It tends to focus on a few “obvious” dimensions and omit less salient but important ones. It also repeats existing angles more often than it discovers new ones.
6.2 Checklists as Semantic Scaffolding
Our solution is to generate a checklist before DeepSearch begins.
This checklist explicitly enumerates the dimensions that a satisfactory answer should cover. For example, for a query about the impact of a specific policy, the checklist might include items such as:
- The policy’s content and background
- Stances of different stakeholders (supporters and opponents)
- Quantitative economic impact data where available
- Social impact (public opinion and behavioral changes)
- Comparisons with historical policies
- Unintended consequences or side effects
- International comparisons to how other countries handle similar issues
Once the checklist is in place, DeepSearch refers to it when generating sub-queries in each round, explicitly targeting dimensions that have not yet been explored. The checklist does not prescribe the exact wording of queries, but it constrains the semantic space by saying “you must cover these aspects somewhere.”
From a cognitive perspective, this is a form of structured constraint. In complex benchmarks such as GAIA and XBench-DeepResearch, we repeatedly observe that this pattern is effective. It makes implicit dimensions explicit, reduces the LLM’s cognitive burden by limiting the search space to a clear set of tasks, and encourages diversity by focusing each new query on uncovered checklist items.
6.2.1 Experimental Evidence: Higher Coverage, Lower Variance
In resource-limited ablations on the RACE-style DeepResearch Bench, we compare Atoms Deep Research with and without the checklist generation module, under constraints on both the number of generation rounds and search depth. This setup isolates the checklist's impact on performance under restricted conditions.
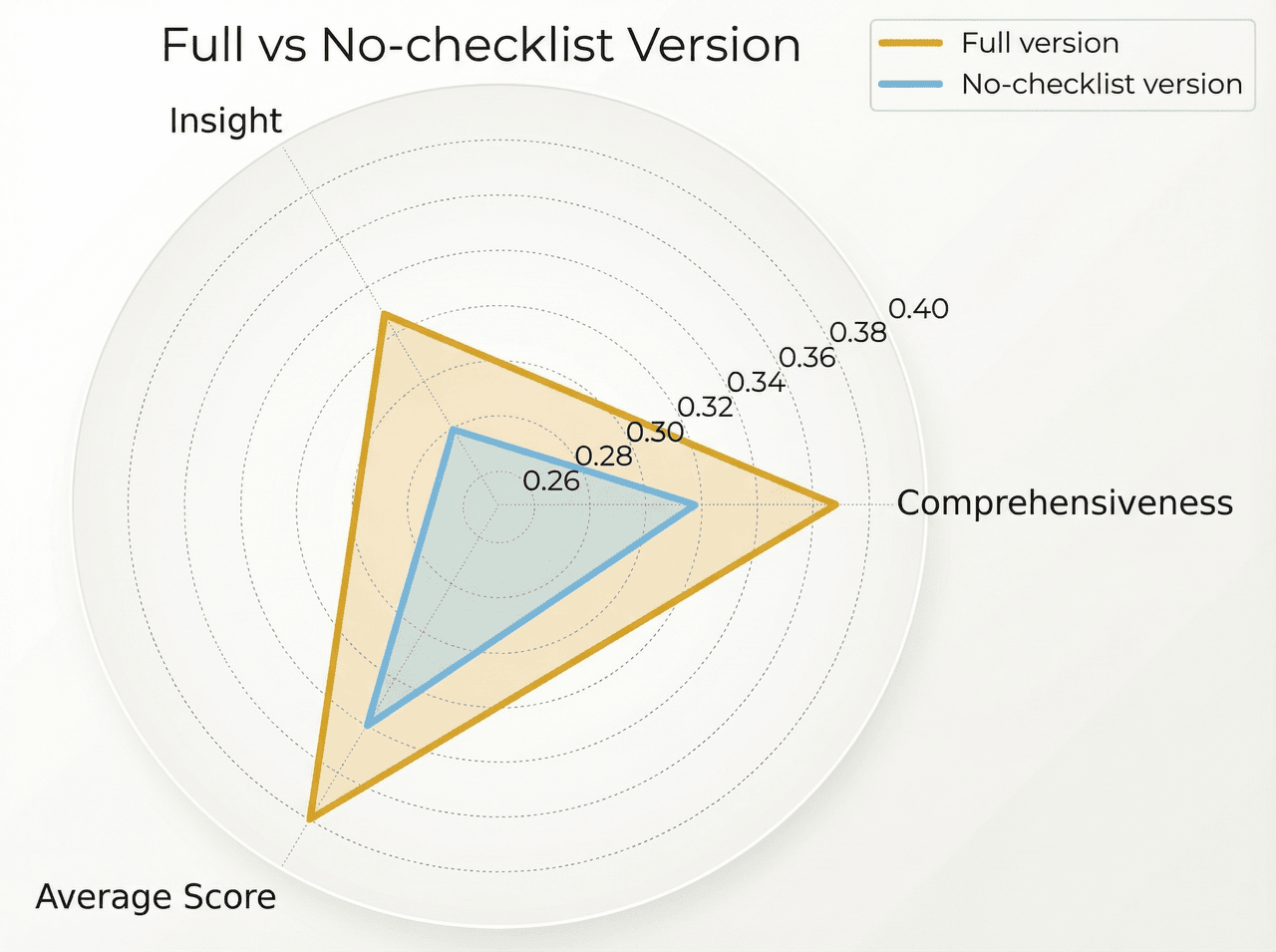
When using checklists, the comprehensiveness score rises from about 27.52 to 28.97, and the variance drops from 0.59 to 0.34. In other words, not only does average coverage improve, but the system’s behavior becomes much more stable across runs.
Without checklists, performance is more “luck-driven”: sometimes the LLM happens to explore the right dimensions; other times it under-explores and yields mediocre coverage. With checklists, the same configuration run multiple times yields much more consistent results. In our experiments, the variance in comprehensiveness without checklists is about 74.29% higher than with checklists.
7. Summary and Key Takeaways
Atoms Deep Research v2.0 focuses on systematically addressing two core challenges faced by long-horizon LLM agents: context asphyxiation and decision drift under heavy information load. Rather than relying on a stronger base model, we achieve improvements through four interlocking architectural changes.
- Context structuring. By adopting a structured communication protocol between agents and a Chunk-Filtering strategy in DeepSearch, we inject high-signal-to-noise snippets into the active context. This reduces the LeadAgent’s average context length by about 76% while increasing Instruction Following scores on the RACE-style benchmark by around 42% in resource-constrained settings. The experiments validate a “less is more” principle in information design for long tasks.
- Semantic navigation. The introduction of checklists makes implicit mental models explicit. By giving the DeepSearch agent a semantic scaffold to follow, we reduce coverage and depth variance and improve stability across runs. The system becomes less sensitive to “good luck vs bad luck” in exploration.
- Source selection. Instead of blindly combining all available search engines, we choose the most complementary subset (e.g., Tavily + Exa) for each task. This avoids “bad money driving out good”, a noisy general-purpose page overshadowing high-value vertical resources in the Top-K ranking window—and improves fact coverage on DeepResearch Bench.
- Parallel execution. By replacing serial sub-query generation with parallel generation and retrieval, we significantly increase both search diversity and throughput. Information collection becomes up to three times more efficient, reaching around 16k characters per second in our tests, and the agent explores more angles per unit of time.
Taken together, these changes allow Atoms Deep Research v2.0 to reduce average time cost by about 11% while still improving report quality, especially on depth and comprehensiveness, under constrained resources. This suggests that careful system design can push the capability frontier of agentic LLM systems without simply scaling model size or API budgets.
8. Frequently Asked Questions
Q1. How is Atoms Deep Research v2.0 different from v1.0 in practice?
v2.0 keeps the core LeadAgent + multi-SubAgent architecture from v1.0, but strengthens it along four dimensions: context structuring, semantic guidance, source selection, and parallel execution. In DeepResearch Bench, this yields a small but consistent improvement in overall quality (+0.3%) and a clearer gain in Instruction Following (+1%) under standard conditions, with much larger gains in constrained settings (report score +26%, Instruction Following +42%).
Q2. Does context compression in v2.0 trade off information for speed?
At the level of a single search step, Chunk-Filtering does retain less information than full summarization. However, because it greatly reduces noise and latency, the system can perform more steps reliably. The net effect over a long chain is positive: LeadAgent context becomes shorter and cleaner, instruction following improves, and overall comprehensiveness and insight scores rise rather than fall.
Q3. Why not always use as many search engines as possible?
Adding more engines increases recall, but Top-K selection at the output forces a competition for limited ranking slots. Noisy general-purpose results from multiple engines can easily outvote a smaller number of high-quality vertical results. Our experiments on DeepResearch Bench show that carefully chosen combinations—such as Tavily + Exa—outperform larger, noisier sets that include additional engines like Serper or Firecrawl.
Q4. What kinds of research tasks benefit most from these v2.0 improvements?
The v2.0 optimizations target long, multi-step research tasks that require iterative search, reasoning, and synthesis: policy and market analysis, technical comparisons, literature reviews, and structured “pros and cons” investigations for major decisions. In these settings, decision stability, search diversity, and end-to-end latency all matter. Short single-shot Q&A tasks see less relative benefit.
Try Atoms Deep Research in Atoms today.
