
Based on the paper: “AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration” by Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, Yuyu Luo, and Jiayi Zhang.
TL;DR
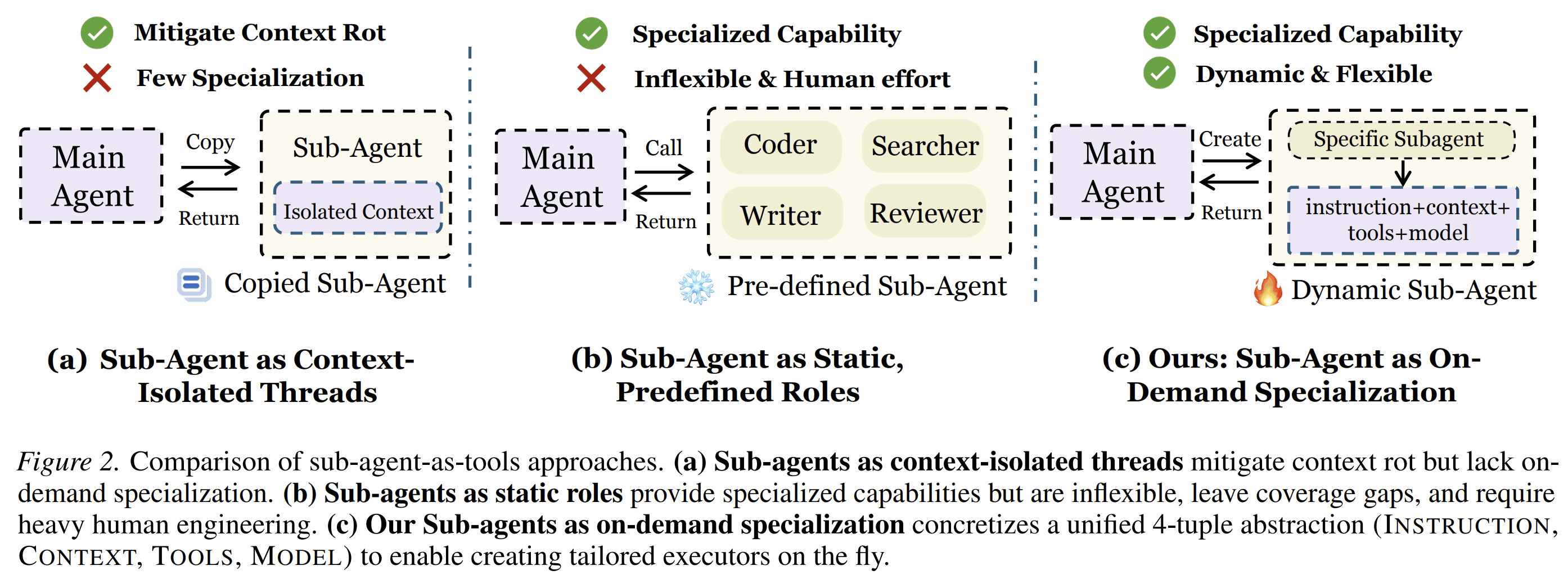
Complex tasks rarely fit a single fixed agent. A coding task may need a repository inspector, a test runner, and a patch writer. A research task may need a web searcher, a file reader, and a verifier. Existing systems usually handle this in one of two ways: they either spawn generic isolated threads, or they rely on manually defined specialist agents.
AOrchestra proposes a cleaner design. It treats every sub-agent as a runtime object defined by four fields:
$$ \Phi = (Instruction, Context, Tools, Model) $$
The orchestrator does not execute tasks directly. Instead, it repeatedly creates task-specific sub-agents by filling in this four-tuple: what the sub-agent should do, what context it should see, what tools it may use, and which model should run it.
This makes sub-agent creation dynamic rather than manually preconfigured. It also makes orchestration learnable: the system can improve how it decomposes tasks, routes context, selects tools, and chooses models.
Across GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified, AOrchestra outperforms several common agent frameworks. The paper also shows that careful context routing and cost-aware model selection are important for long-horizon task solving.
The Problem: Fixed Agents Do Not Scale Cleanly to Long-Horizon Work
A single agent can solve simple tasks. It can read the prompt, reason through the steps, call tools, and produce an answer.
But long-horizon tasks are different. They often require multiple forms of work:
- decomposing a broad goal;
- searching for missing evidence;
- inspecting files;
- running commands;
- editing code;
- verifying results;
- recovering from errors;
- deciding when enough work has been done.
Putting all of this inside one context window creates several problems.
First, the context becomes noisy. The agent accumulates instructions, tool outputs, failed attempts, partial observations, and intermediate reasoning. Important details can be buried under irrelevant history.
Second, the required capabilities vary across subtasks. A browser-heavy subtask should not have the same tool access as a code-editing subtask. A simple lookup may not need the same model as a difficult debugging step.
Third, manually designing a fixed set of specialists is brittle. A fixed “researcher,” “coder,” and “reviewer” may work for some tasks, but open-ended environments produce subtasks that were not anticipated by the designer.
This is the setting AOrchestra targets: complex tasks where the system must decide not only what to do next, but also what kind of executor should do it.
The Main Idea
AOrchestra’s central idea is simple:
A sub-agent should not be a fixed role. It should be created on demand for the current subtask.
To make this possible, the paper defines a unified abstraction for agents:
$$ \Phi = (I, C, T, M) $$
where:
- Instruction defines the subtask and success criteria.
- Context contains the task-relevant information the sub-agent should condition on.
- Tools define what actions the sub-agent is allowed to take.
- Model defines which language model executes the subtask.
This abstraction separates two things that are often mixed together:
- Working memory: instruction and context.
- Capabilities: tools and model.
That separation is important. A sub-agent should receive enough context to solve its subtask, but not the entire conversation history. It should have the tools required for the job, but not every tool in the system. It should use a model appropriate for the task, not necessarily the most expensive model every time.
AOrchestra turns these choices into explicit orchestration decisions.
How AOrchestra Works
AOrchestra has one central orchestrator. The orchestrator does not directly act in the environment. It has only two actions:
- Delegate: create a sub-agent using a four-tuple and assign it a subtask.
- Finish: stop and return the final answer.
At each step, the orchestrator decides whether the task is complete. If not, it constructs a new sub-agent:
$$ \Phi_t = (I_t, C_t, T_t, M_t) $$
The sub-agent then executes the assigned subtask with the selected model, selected tools, and curated context. It returns a structured result to the orchestrator, including the outcome, relevant artifacts, and any error messages or logs.
The orchestrator reads the returned observation and decides the next step. This process repeats until the orchestrator has enough evidence to finish.
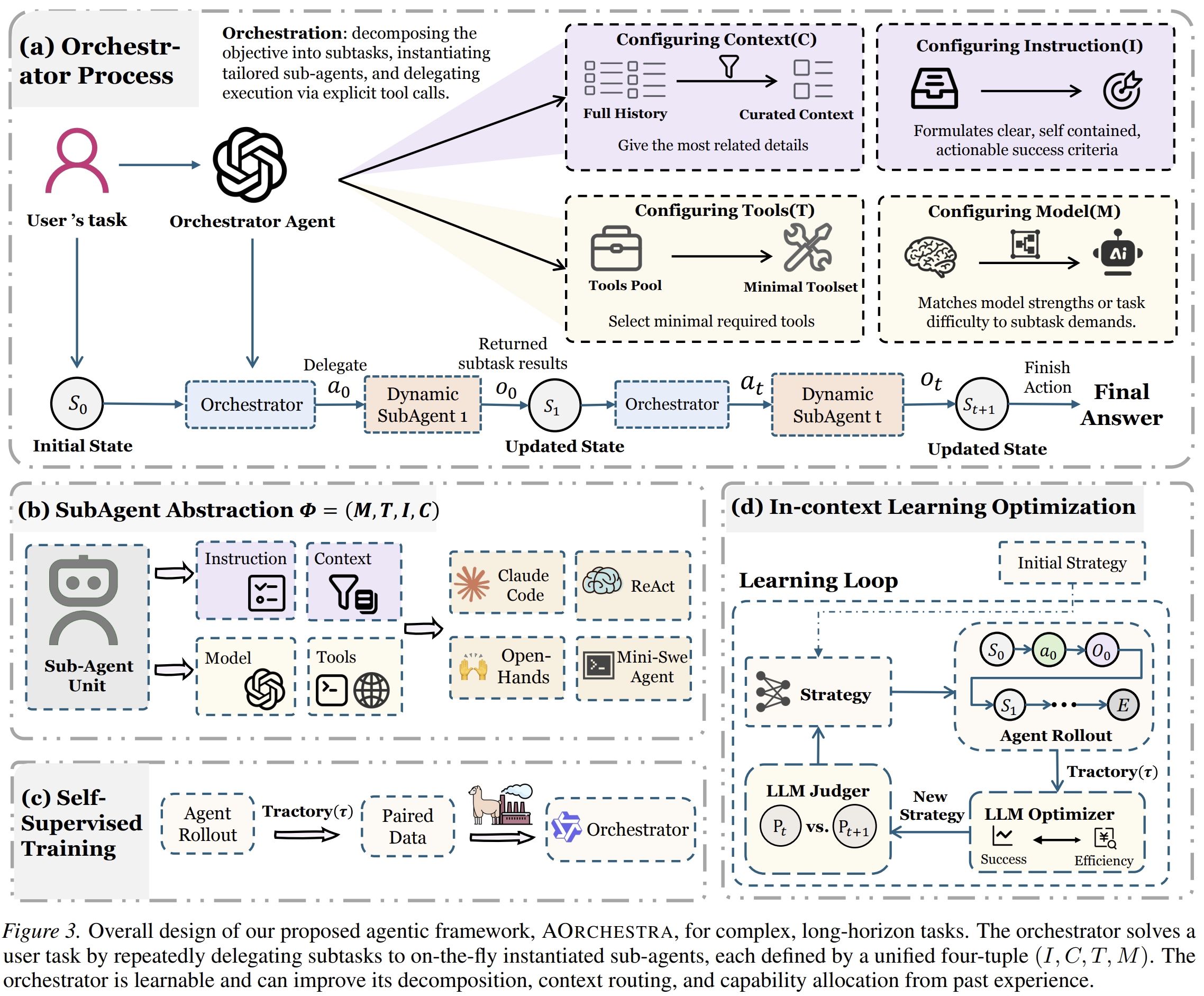
This design creates a clear division of labor:
- The orchestrator handles decomposition, context routing, tool selection, model selection, and stopping.
- The sub-agents handle execution.
That division is the main architectural contribution of the paper.
Why the Four-Tuple Matters
The four-tuple is useful because it makes sub-agent creation concrete.
Without this abstraction, “create a sub-agent” is vague. The system must still decide what the sub-agent should know, what it should do, what tools it can use, and which model should run it. AOrchestra makes these fields explicit.
Instruction
The instruction defines the local goal. It should be specific enough that the sub-agent can execute without needing to infer the entire global task.
For example, instead of telling a sub-agent:
“Solve the user’s request.”
the orchestrator might say:
“Inspect the repository and identify which files are relevant to the failing authentication test. Do not modify files yet. Return the file paths and a short explanation.”
This reduces ambiguity and limits unnecessary work.
Context
The context field controls what information the sub-agent sees.
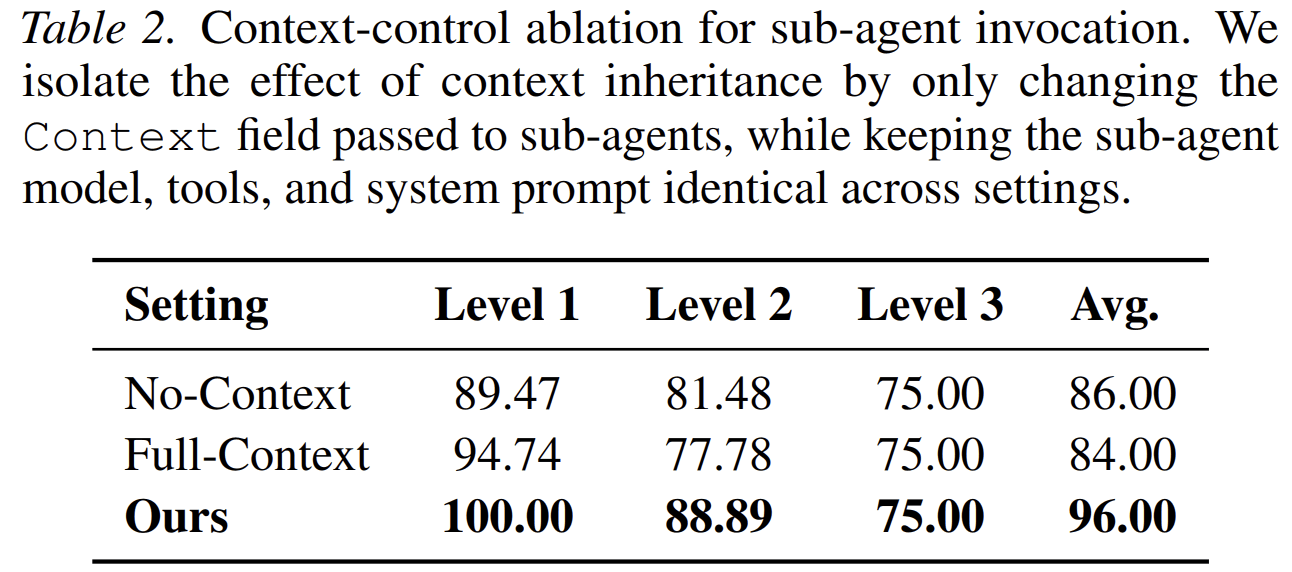
This is one of the most important parts of the paper. Passing no context can omit critical evidence. Passing the full context can introduce noise and degrade performance. AOrchestra uses curated context: the orchestrator selects the task-relevant information needed for the current subtask.
The paper’s ablation confirms this. On a sampled GAIA evaluation, the curated-context setting outperforms both no-context and full-context variants.
Tools
The tools field defines the sub-agent’s action space.
This gives the orchestrator control over capability allocation. A sub-agent that only needs to inspect files should not necessarily receive code-editing tools. A sub-agent that needs to verify a result should have access to the relevant evaluator or execution environment.
Tool selection also reduces accidental misuse. It narrows the sub-agent’s scope to what the subtask requires.
Model
The model field allows the orchestrator to choose different models for different subtasks.
This matters because not every step requires the same model. Some subtasks are simple and cheap. Others require stronger reasoning or more reliable tool use. AOrchestra treats model selection as part of orchestration rather than a fixed system-wide decision.
The paper shows that this enables cost-aware routing. The orchestrator can improve the performance-cost trade-off by deciding when to use stronger or cheaper models.
What Is Different from Existing Sub-Agent Designs
The paper contrasts AOrchestra with two common patterns.
Pattern 1: Sub-Agents as Isolated Threads
Some systems spawn sub-agents mainly to isolate context. This can reduce context degradation because each sub-agent works in a separate window.
But isolation alone is not specialization. A generic thread may still lack the right tools, the right model, or the right task framing.
AOrchestra keeps the benefit of isolation but adds explicit specialization.
Pattern 2: Sub-Agents as Static Roles
Other systems define fixed sub-agent roles in advance. For example, a system might include a “researcher,” “coder,” and “critic.”
This can work when the task distribution is known. But it does not adapt cleanly to open-ended tasks. The required subtask may not match any predefined role. Maintaining many hand-written specialists also increases engineering cost.
AOrchestra avoids this by creating sub-agents at runtime. The orchestrator does not choose from a fixed role list. It constructs the executor needed for the next step.
The Orchestrator Is Learnable
A key point in the paper is that orchestration is not only a prompt design problem. It can be learned.
AOrchestra exposes structured orchestration actions: each delegation contains instruction, context, tools, and model. Because these decisions are explicit, the orchestrator can be trained to make them better.
The paper explores two approaches.
Supervised Fine-Tuning for Task Orchestration
The authors fine-tune a Qwen3-8B orchestrator using expert orchestration trajectories. The goal is to improve decomposition and four-tuple synthesis: what subtask to assign, what context to include, and which tools to provide.
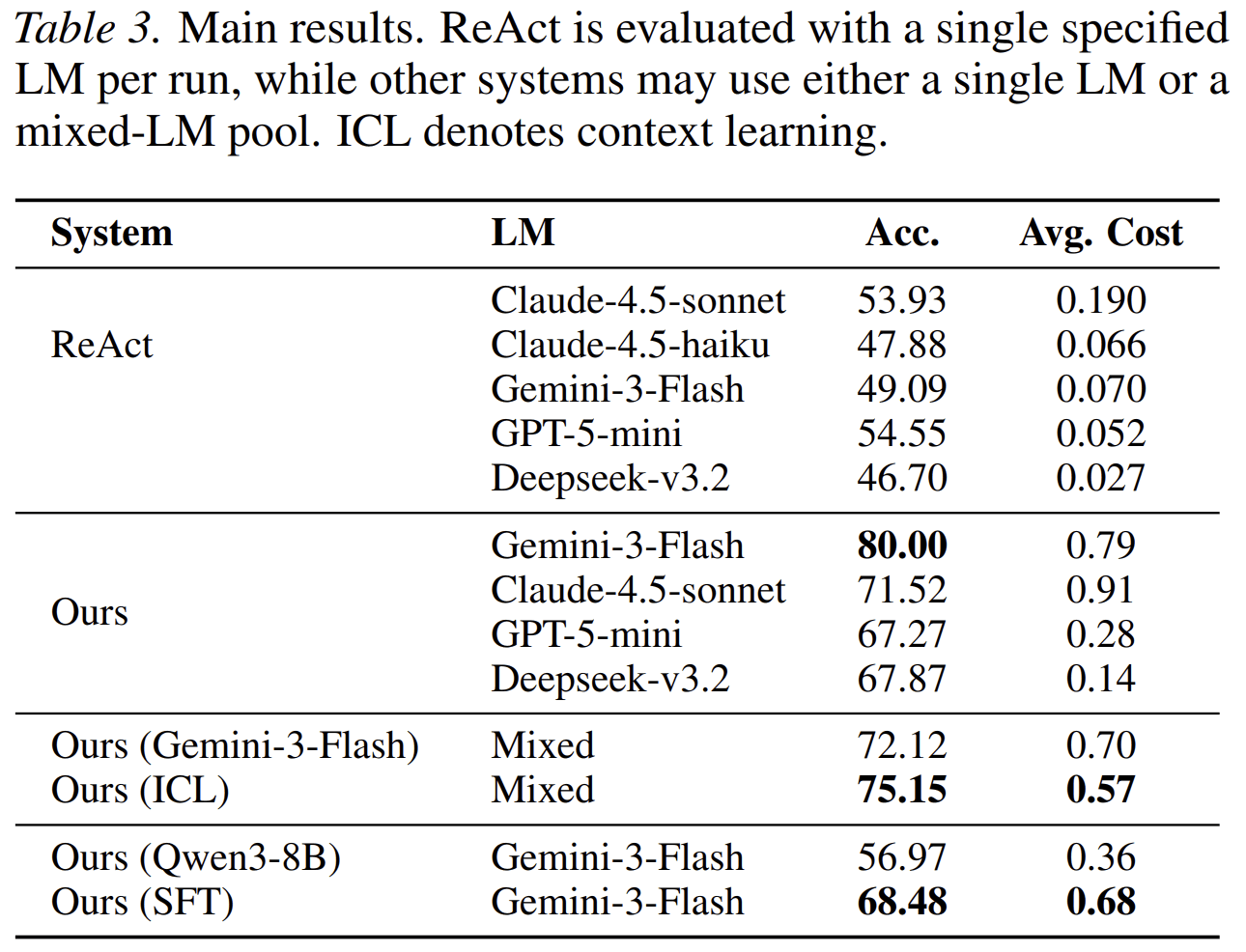
The result is significant. In the GAIA setting reported in the paper, the base Qwen3-8B orchestrator reaches 56.97 accuracy, while the SFT version reaches 68.48.
This suggests that orchestration is a learnable skill. A smaller model can improve its ability to manage sub-agents when trained on structured delegation examples.
In-Context Learning for Cost-Aware Orchestration
The second approach does not update model weights. Instead, it iteratively improves the orchestrator instruction using trajectory feedback, including both task performance and cost.
The goal is to improve model routing: when to use a stronger model, when to use a cheaper one, and how to balance the two.
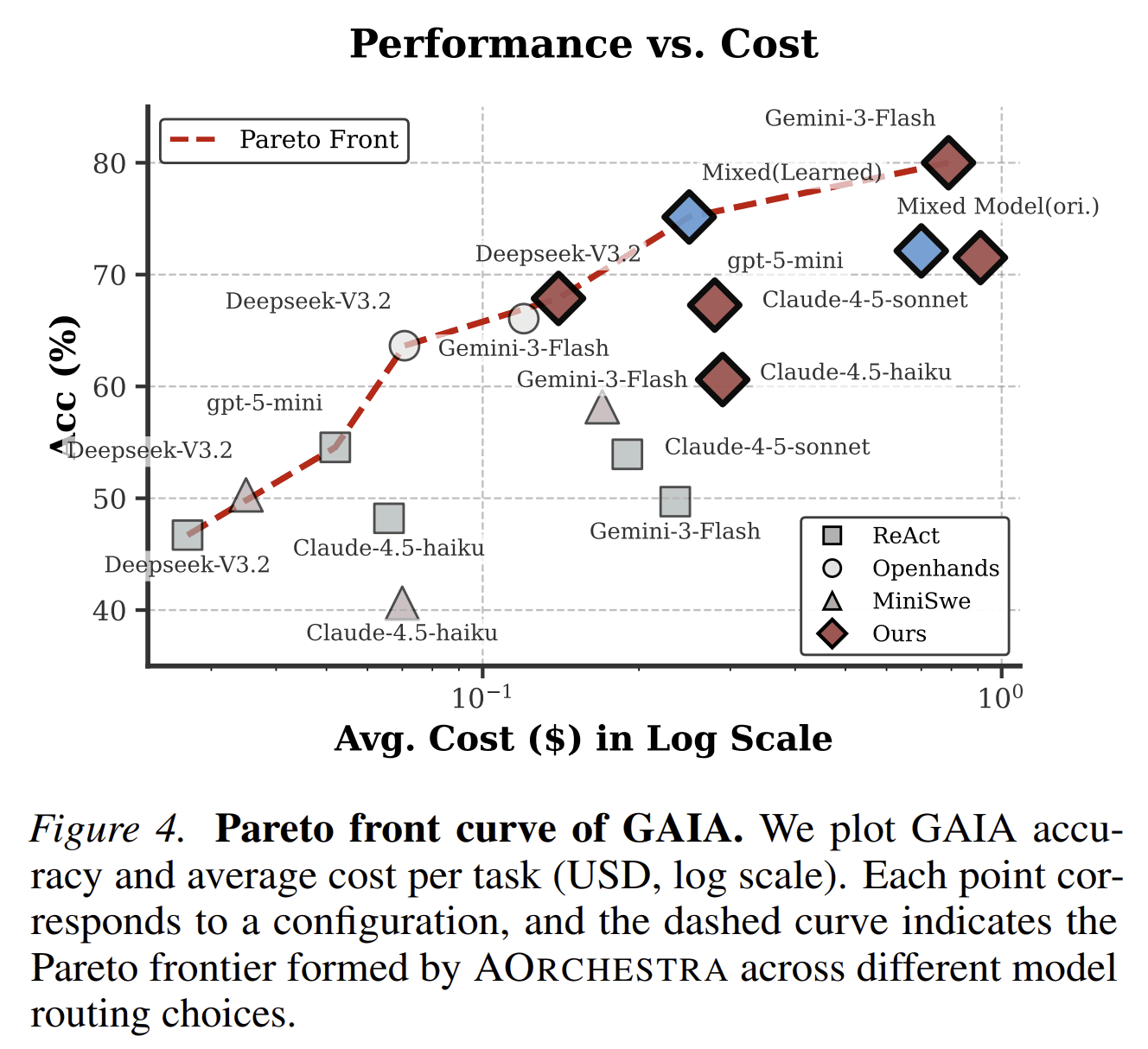
In the mixed-model GAIA setting, the paper reports that instruction optimization improves accuracy from 72.12 to 75.15 while reducing average cost from 0.70 to 0.57 dollars per task.
That result matters because it shows the four-tuple abstraction is not only a performance mechanism. It also gives the system a handle for cost control.
Experimental Results
The paper evaluates AOrchestra on three benchmarks:
-
GAIA
A benchmark for general-purpose assistants requiring multi-step reasoning, tool use, file handling, and web-based tasks. -
Terminal-Bench 2.0
A benchmark for agents operating in Linux terminal environments. -
SWE-Bench-Verified
A benchmark for resolving real GitHub issues by producing patches that pass tests.
The paper compares AOrchestra against several baselines, including ReAct, OpenHands, Mini-SWE-Agent, and Claude Code.
With Gemini-3-Flash, AOrchestra reports:
- 80.00 pass@1 on GAIA
- 52.86 pass@1 on Terminal-Bench 2.0
- 82.00 pass@1 on SWE-Bench-Verified
- 71.62 average pass@1 across the three benchmarks
These results are stronger than the reported baselines under the same or comparable model settings.
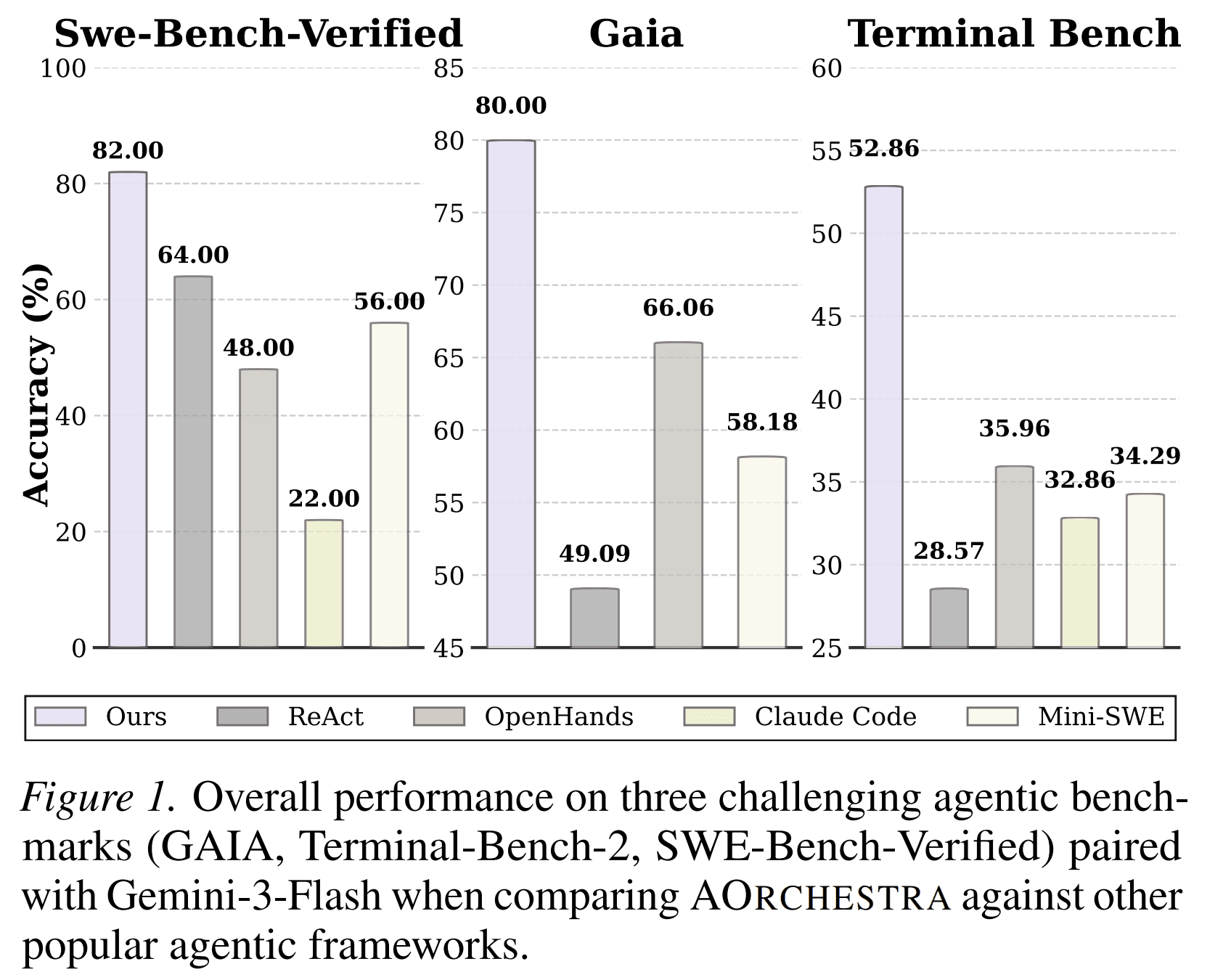
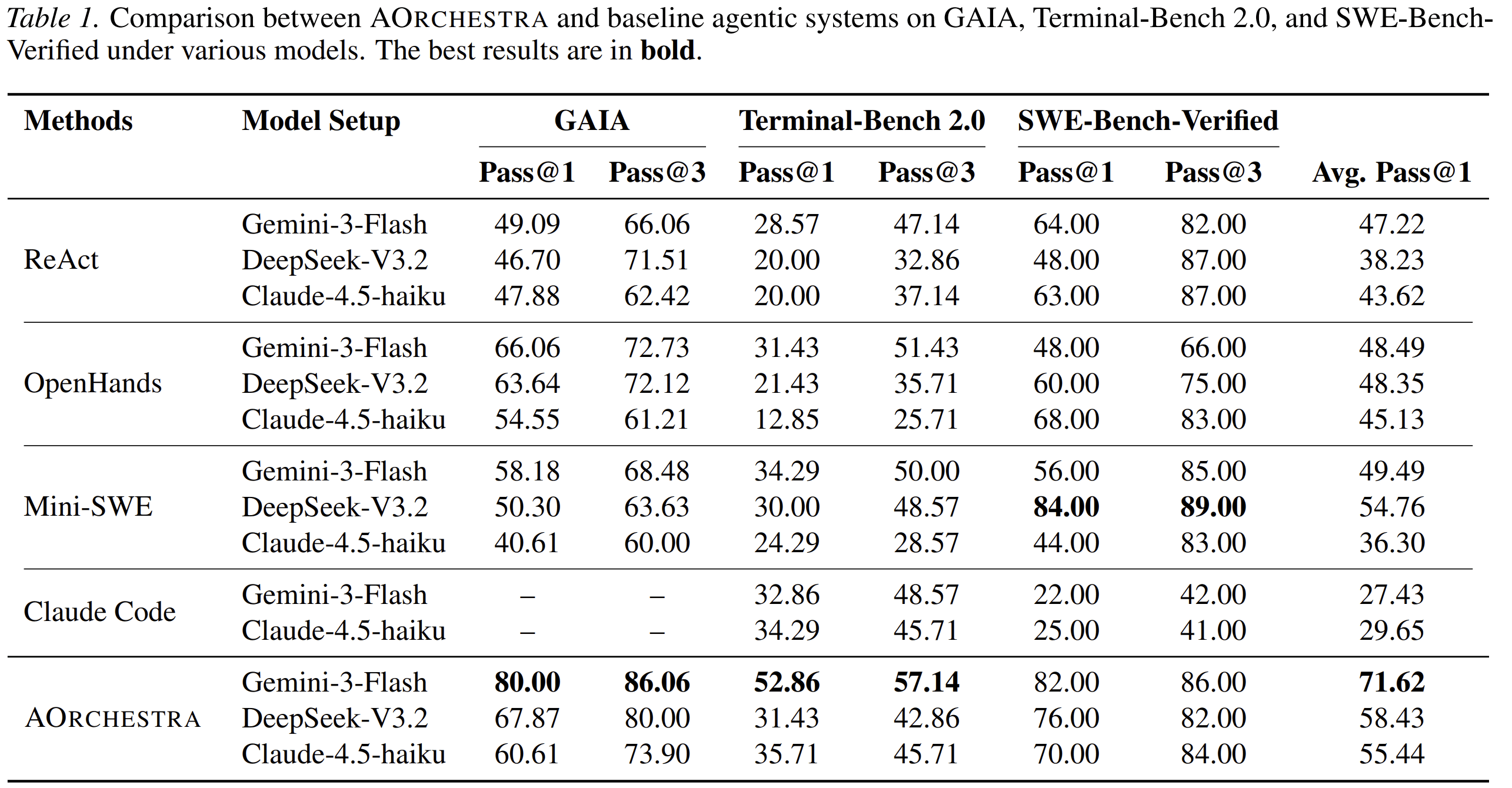
The strongest result is not just that AOrchestra performs better. The more important result is that the gains are consistent across different environments: general question answering, terminal operation, and software engineering.
That consistency supports the paper’s main claim: dynamic sub-agent creation is a general orchestration mechanism, not a benchmark-specific trick.
Plug-and-Play Sub-Agents
AOrchestra is designed to be independent of the internal implementation of a sub-agent. The orchestrator only needs to construct the four-tuple. The executor can be implemented in different ways.
The paper tests this by replacing the sub-agent backend with different agent styles, including ReAct-style and Mini-SWE-style sub-agents. With a fixed orchestrator, AOrchestra still improves over the standalone versions of those agents on Terminal-Bench.
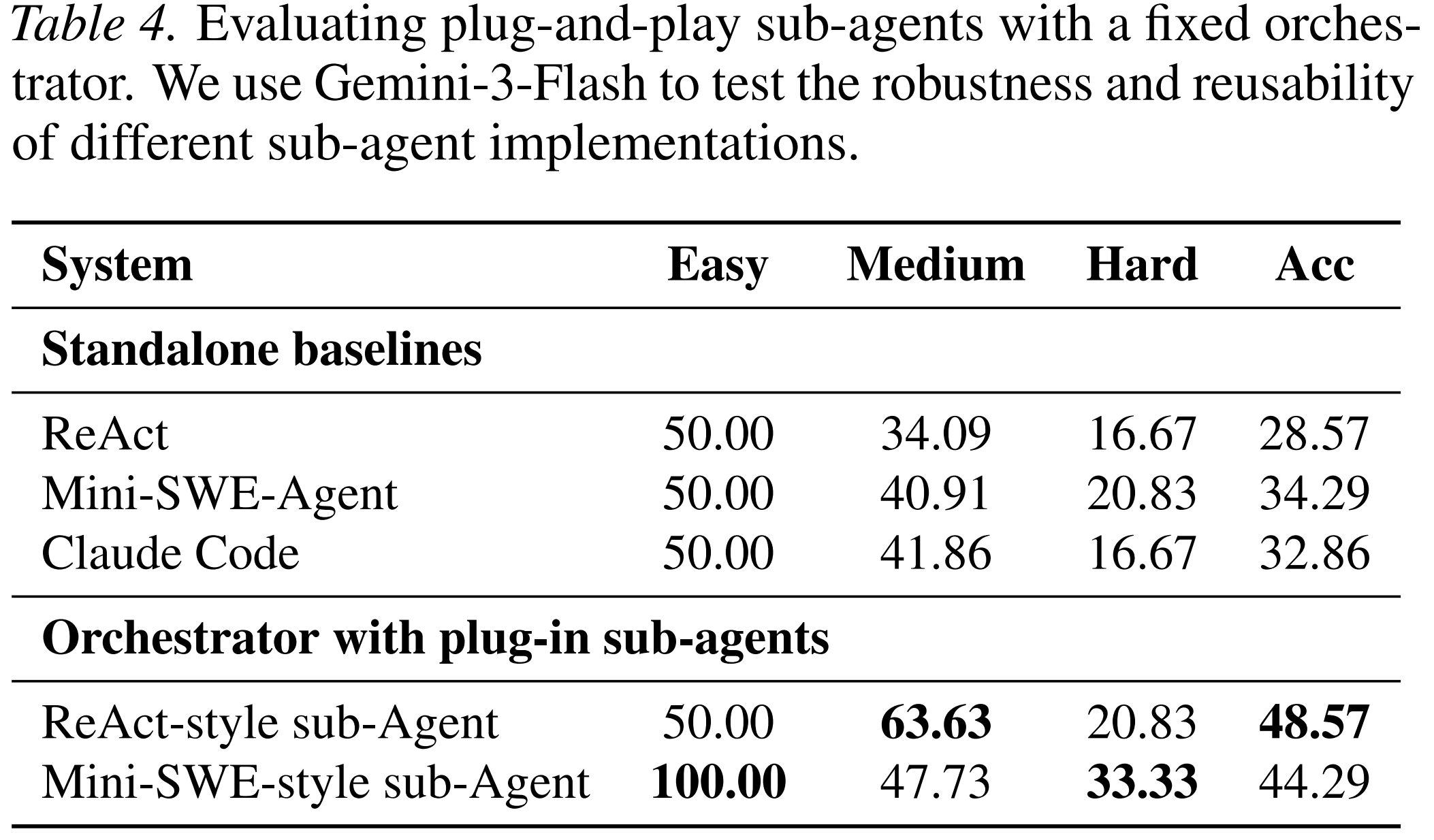
This is important for product systems. A practical agent platform will not rely on one executor forever. It may need to integrate different agents for browsing, coding, data work, document processing, and internal tools. A framework-agnostic orchestration layer makes that possible.
Why This Matters for Product Agents
In a product environment, users do not ask benchmark-shaped questions. They ask broad, ambiguous, multi-step requests:
“Help me turn this idea into a launch plan.”
“Analyze this market and create a product brief.”
“Find what is wrong with this workflow and fix it.”
“Compare these competitors and tell me what we should build.”
These tasks require different forms of work. A single agent can attempt to do everything, but it will often mix planning, evidence collection, execution, and verification in one long context. That makes the system harder to control and harder to debug.
AOrchestra points to a better structure.
For Atoms, the implication is clear: a product agent should not only generate answers. It should allocate work. It should decide what kind of sub-agent is needed, what evidence that sub-agent should see, what tools it should use, and which model is appropriate for the step.
This is especially relevant for business-building workflows, where the user’s request may involve:
- market research;
- product positioning;
- user segmentation;
- landing page copy;
- financial modeling;
- launch planning;
- competitor analysis;
- technical scoping.
These are not the same task. They should not necessarily be handled by the same executor with the same context and tools.
AOrchestra gives a precise way to structure this type of system.
A Concrete Example
Suppose a user asks:
“Help me evaluate whether we should build a customer support AI agent for Shopify merchants.”
A single-agent system may try to answer directly. It may produce a market analysis, feature list, and go-to-market plan in one pass.
An AOrchestra-style system would handle the request differently.
The orchestrator might create a first sub-agent:
- Instruction: Identify the main customer support pain points for Shopify merchants.
- Context: The user’s business goal and any known constraints.
- Tools: Web search and source collection.
- Model: A cost-effective model suitable for research.
Then a second sub-agent:
- Instruction: Analyze existing competitors and summarize their positioning.
- Context: The research findings from the first sub-agent.
- Tools: Web search, table extraction, citation collection.
- Model: A stronger model if the task requires judgment across many sources.
Then a third sub-agent:
- Instruction: Draft a product concept and identify the minimum viable feature set.
- Context: Pain points, competitor summary, and the user’s constraints.
- Tools: Document generation tools.
- Model: A model optimized for structured writing.
Finally, the orchestrator reviews the outputs and decides whether the answer is complete.
The value is not just parallelism. The value is control. Each sub-agent receives a narrow task, relevant context, appropriate tools, and an appropriate model.
What AOrchestra Does Not Claim
AOrchestra is not a guarantee that any decomposition will be correct. The quality of the system still depends on the orchestrator’s decisions.
If the orchestrator gives the wrong instruction, removes necessary context, selects weak tools, or chooses an unsuitable model, the sub-agent can fail. The paper addresses this by showing that orchestration can be trained and improved, but the problem does not disappear.
AOrchestra also introduces overhead. Delegation requires additional model calls, context construction, and result summarization. For simple tasks, a single agent may be cheaper and sufficient.
The method is most relevant when tasks are complex enough that context control, tool control, and decomposition become more valuable than the cost of delegation.
From Paper to System Design
AOrchestra suggests several design principles for building user-facing agents.
1. Separate Orchestration from Execution
The system should distinguish between deciding what work needs to be done and doing the work. These are different skills.
2. Make Sub-Agent Configuration Explicit
A sub-agent should be defined by its instruction, context, tools, and model. These fields should be visible, controllable, and learnable.
3. Route Context, Do Not Dump It
Passing the full history to every sub-agent is not safe. Passing no history is also not safe. The orchestrator should provide task-sufficient context.
4. Treat Model Selection as a Step-Level Decision
Different subtasks justify different model choices. The system should be able to spend more on hard steps and less on simple ones.
5. Keep Executors Pluggable
The orchestrator should not depend on one sub-agent implementation. Different domains may require different executors.
6. Train the Orchestrator
Good orchestration is not only prompt engineering. It can be learned from trajectories, errors, costs, and outcomes.
Conclusion
AOrchestra reframes sub-agents as dynamically created executors rather than fixed roles or generic context-isolated threads.
Its core abstraction is the four-tuple:
$$ (Instruction, Context, Tools, Model) $$
This gives the orchestrator explicit control over what each sub-agent should do, what it should know, what it can use, and which model should run it.
The paper shows that this design improves performance across general assistant tasks, terminal tasks, and software engineering tasks. It also shows that orchestration can be learned, context routing matters, and model selection can improve the cost-performance trade-off.
For product agents, the broader lesson is direct: complex work should be delegated with structure. A useful agent should not simply continue the conversation inside one growing context. It should create the right executor for the next step, pass the right context, choose the right tools, and stop when the work is complete.
