
Based on the paper: “InteractComp: Evaluating Search Agents With Ambiguous Queries” by Mingyi Deng, Lijun Huang, Yani Fan, Jiayi Zhang, Fashen Ren, Jinyi Bai, Fuzhen Yang, Dayi Miao, Zhaoyang Yu, Yifan Wu, Yanfei Zhang, Fengwei Teng, Yingjia Wan, Song Hu, Yude Li, Xin Jin, Conghao Hu, Haoyu Li, Qirui Fu, Tai Zhong, Xinyu Wang, Xiangru Tang, Nan Tang, Chenglin Wu, and Yuyu Luo.
TL;DR
Search agents are usually evaluated as if user queries are complete. Real users rarely behave that way.
A user may ask for “the paper about agent workflows,” “the tool that helps founders validate ideas,” or “the company that launched the AI browser.” Each query can point to several plausible answers. A search agent that does not ask for clarification will often search confidently in the wrong direction.
InteractComp introduces a benchmark for this exact failure mode. It tests whether search agents can recognize ambiguous queries, ask clarifying questions, and use the answers to reach a verifiable result.
The benchmark contains 210 expert-curated questions across 9 domains. Each question is designed so that the answer is easy to verify once the missing context is known, but difficult to identify without interaction.
The main result is stark: among 17 evaluated models, the best model reaches only 13.73% accuracy when interaction is available, even though models can reach 71.50% accuracy when given complete disambiguating context. The problem is not only search or reasoning. The problem is that current agents often fail to notice when they should ask.
The Problem: Search Agents Assume Too Much
Most search agents are built around a simple loop:
- Receive a user query.
- Search the web.
- Read retrieved pages.
- Produce an answer.
This works when the query is complete. It breaks when the query is ambiguous.
The ambiguity is not always obvious. A query can be long, detailed, and still underspecified. It may contain many true attributes, but those attributes may describe several possible targets.
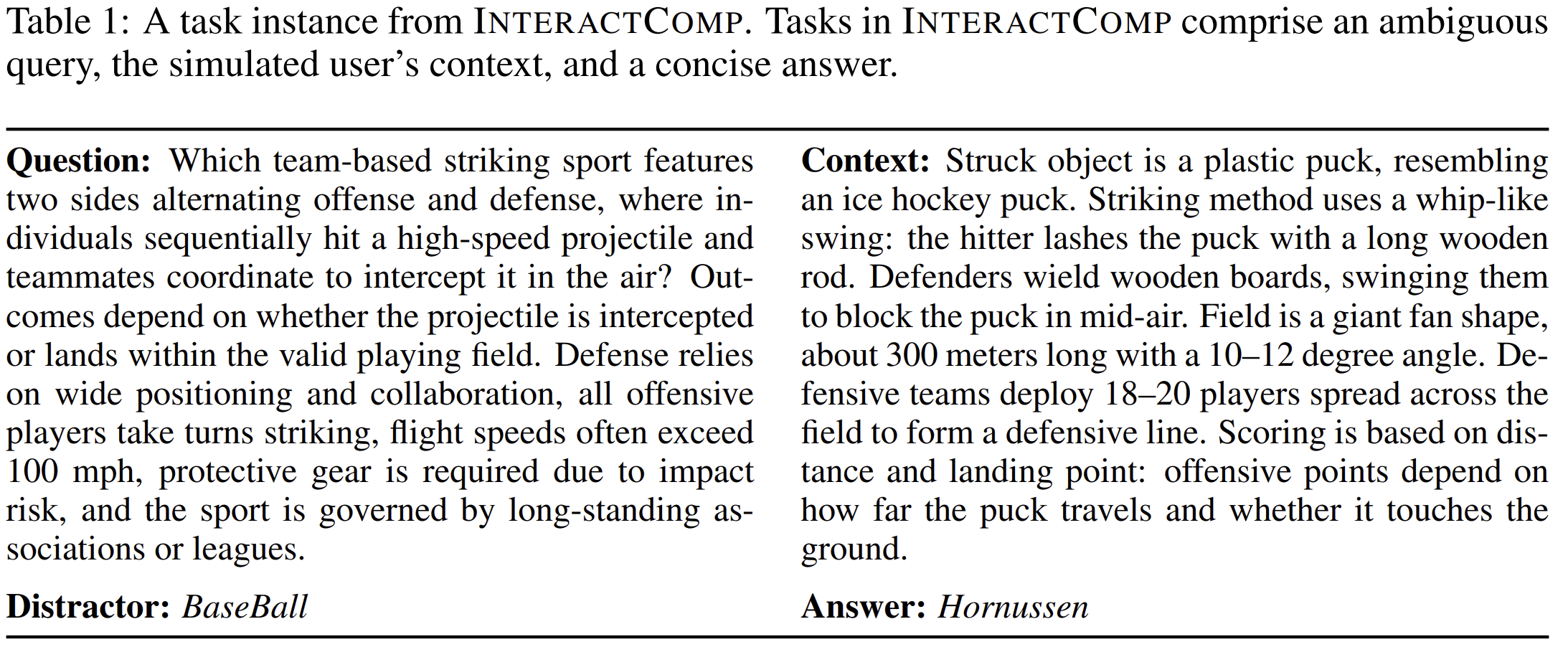
For example, a user may describe a “team-based striking sport” involving offense, defense, high-speed projectiles, and protective gear. A search agent may infer baseball. But if the hidden context includes a plastic puck, a whip-like swing, wooden boards used by defenders, and a fan-shaped field, the correct answer is Hornussen.
The initial query is not false. It is incomplete.
That distinction matters. A search agent that treats incomplete queries as complete queries will not merely fail to retrieve enough information. It will retrieve information for the wrong interpretation.
The Main Idea
InteractComp evaluates a specific capability:
Can a search agent recognize that a query is ambiguous, ask for missing context, and then answer correctly?
The benchmark follows the principle:
Easy to verify, interact to disambiguate.
Each task has a concise, verifiable answer. But the initial query is intentionally constructed so that search alone is unreliable. The agent must interact with a simulated user to uncover the missing information.
This creates a clean evaluation setting. If the agent asks good questions, it can resolve the ambiguity. If it does not, it is likely to answer a popular but wrong distractor.
How InteractComp Constructs Ambiguous Queries
The benchmark uses a target-distractor design.
Each task starts with two entities:
- a lesser-known target entity;
- a more popular distractor entity with overlapping attributes.
Annotators then split attributes into two groups:
-
Shared attributes
Properties that apply to both the target and the distractor. -
Distinctive attributes
Properties that separate the target from the distractor.
The ambiguous question is written using only shared attributes. The distinctive attributes are hidden in the user context.
This design ensures that the question is not random or vague. It is deliberately underdetermined. The ambiguity is controlled.
The agent receives only the ambiguous question. It can take three types of actions:
-
Search: Retrieve external information.
-
Interact: Ask the simulated user a closed-ended clarification question.
-
Answer: Provide the final answer with a confidence score.
The simulated user answers only with “yes,” “no,” or “I don’t know,” based on the hidden context.
Dataset Design
InteractComp contains 210 expert-curated questions across 9 domains, including science and engineering, humanities, entertainment, business and economics, law and politics, sports, medicine and life science, academic and research topics, and general knowledge.
The dataset is bilingual:
- 139 English samples;
- 71 Chinese samples.
The paper reports two levels of verification.
First, annotators check that the target satisfies both the question and the hidden context, and that the question-context pair uniquely identifies the correct answer.
Second, the authors verify that the question cannot be solved reliably through search alone. They manually inspect direct search results and test strong models under search-only settings. If a question can be answered without interaction by multiple capable models, it is revised.
This is important because the benchmark is not testing obscure trivia. It is testing whether the agent knows when it lacks enough information.
The Core Failure: Overconfidence
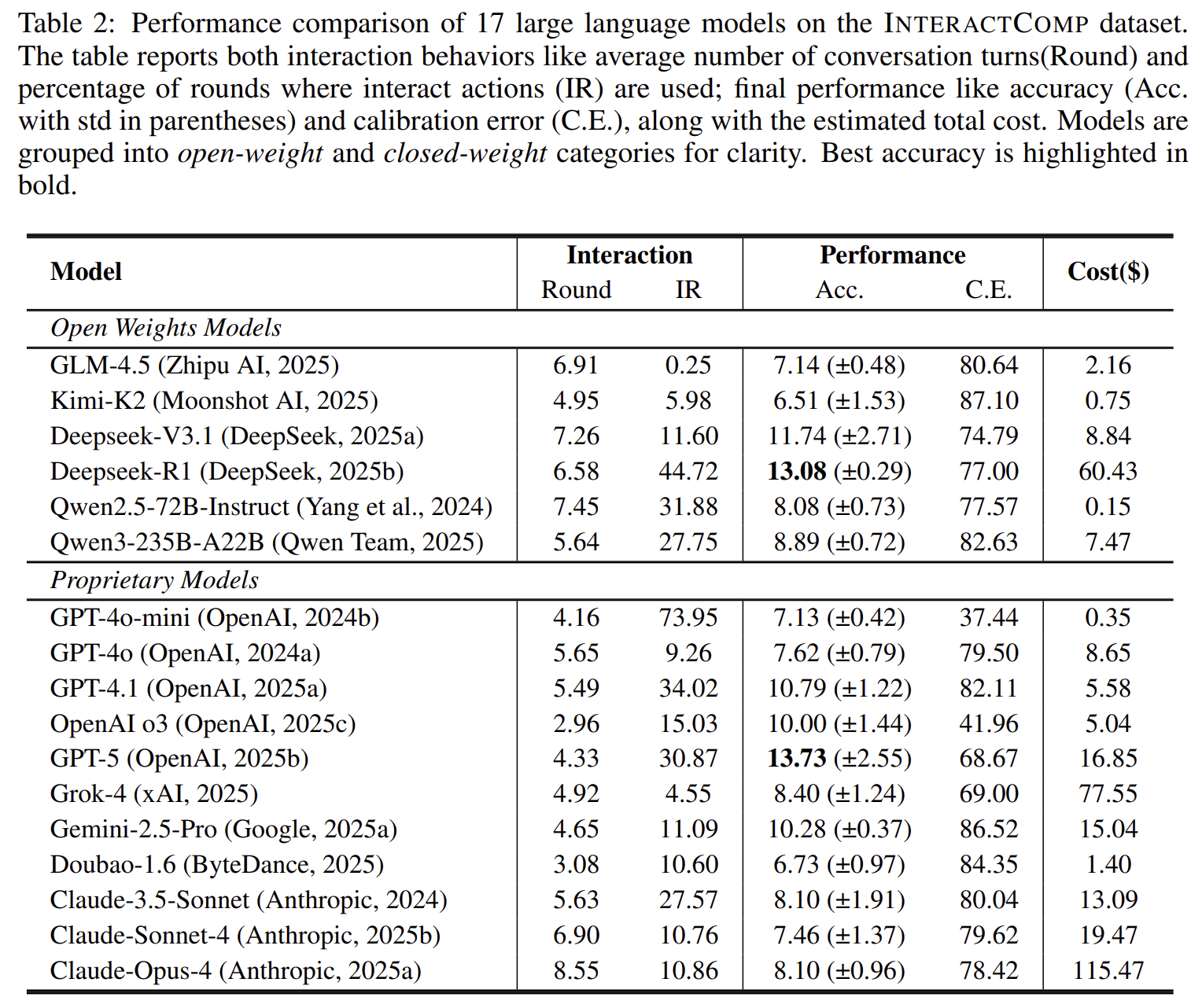
The main experiment evaluates 17 models under an interaction-enabled search setting.
The best model reaches only 13.73% accuracy.
This number is low, but the more important result is the contrast with the with-context setting. When models are given the complete disambiguating context, the best accuracy rises to 71.50%.
This gap shows that the tasks are answerable. The models can reason once they have the missing information. The failure occurs before reasoning: the agent does not reliably ask for the information it needs.
The paper describes this as systematic overconfidence. Agents often proceed as if the initial query were sufficient, even when the benchmark is explicitly designed so that it is not.
Search Alone Does Not Solve the Problem
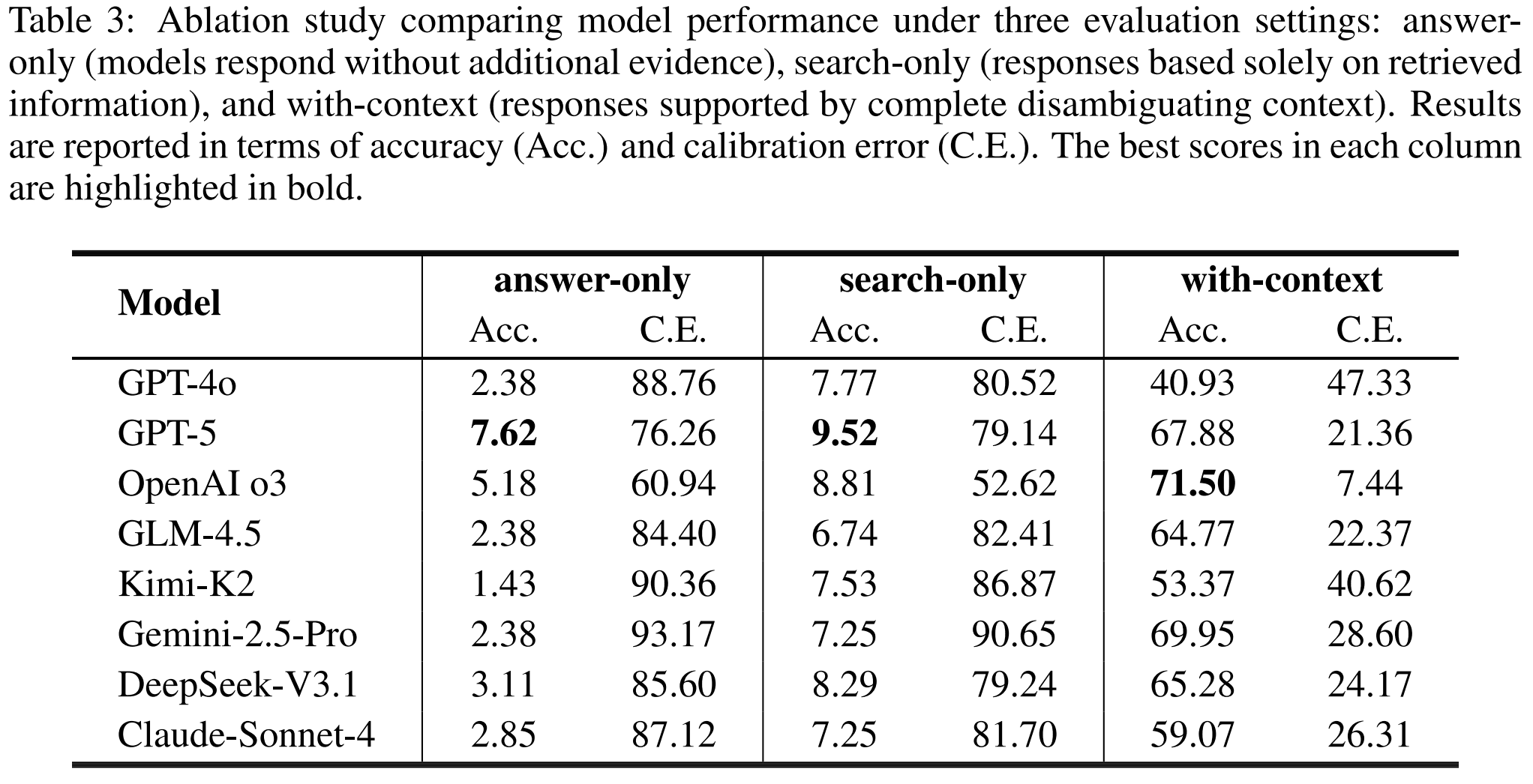
The paper compares three settings:
-
Answer-only
The model answers directly from internal knowledge. -
Search-only
The model can search, but cannot interact. -
With-context
The model receives the missing disambiguating context.
Search-only improves little over answer-only. For example, GPT-5 increases from 7.62% accuracy in answer-only mode to 9.52% in search-only mode. OpenAI o3 increases from 5.18% to 8.81%.
But with full context, performance changes sharply. OpenAI o3 reaches 71.50%, and GPT-5 reaches 67.88%.
This is the key diagnostic result. The missing capability is not retrieval alone. It is knowing what to ask before retrieval becomes meaningful.
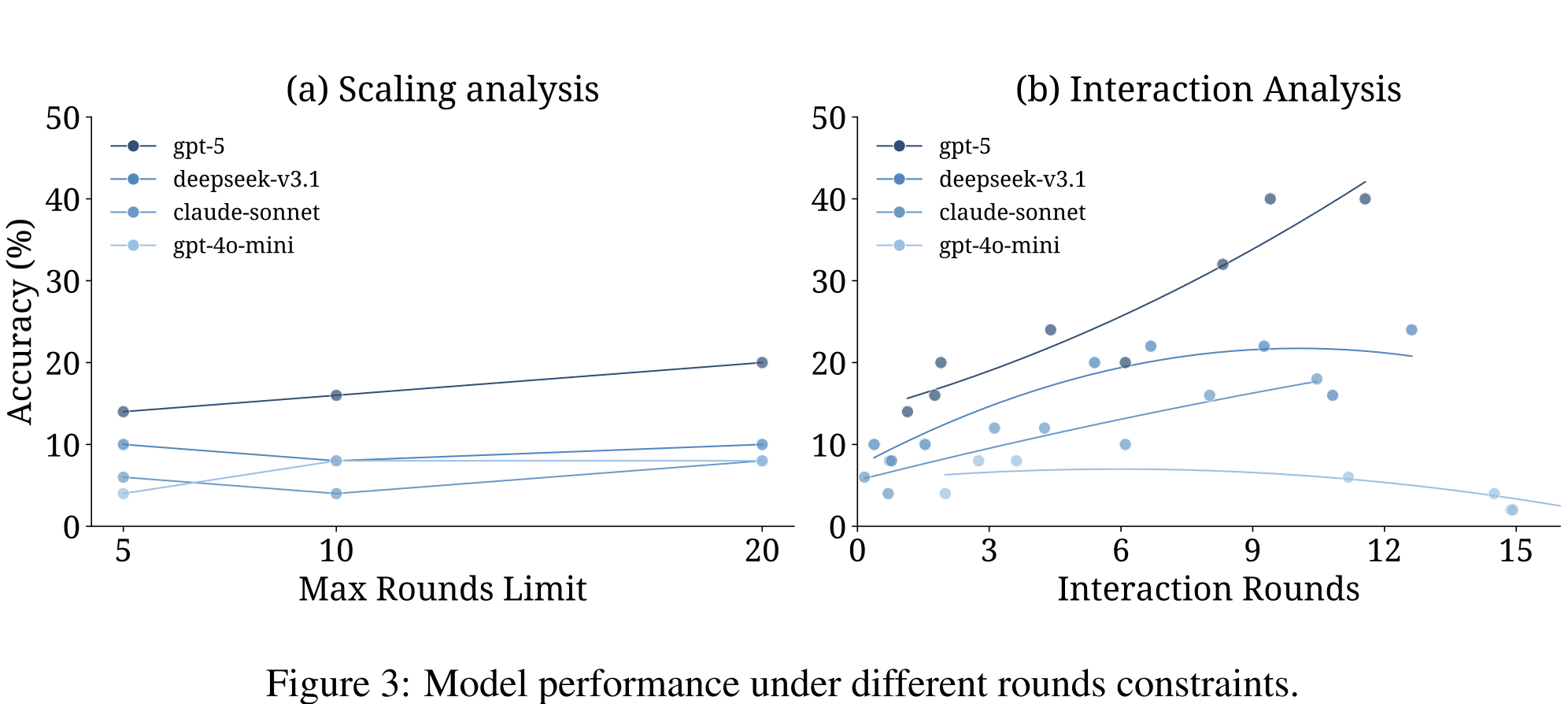
More Rounds Are Not Enough
A natural question is whether agents would ask more if given more time.
The paper tests this by increasing the allowed number of rounds from 5 to 10 to 20.
The result is limited. GPT-5 improves from 14% to 20% accuracy as its number of interactions rises, but most models do not substantially increase their questioning behavior. Claude-Sonnet-4, for example, remains below one average interaction even when given 20 rounds.
This suggests that simply giving agents more opportunities does not fix the issue. The agent must have a policy that recognizes ambiguity and decides to interact.
Forced Interaction Reveals Latent Ability
The strongest evidence comes from forced interaction experiments.
When GPT-5 is required to ask clarifying questions before answering, its accuracy rises substantially. In the reported setting, GPT-5 improves from 20% to 40% accuracy when compelled to ask enough questions.
This does not mean agents should always be forced to ask many questions. In a product, unnecessary questions can be harmful. But the experiment proves an important point: some models have the capacity to use clarification well, yet fail to choose it voluntarily.
The bottleneck is strategic. The model does not reliably decide that it should ask.
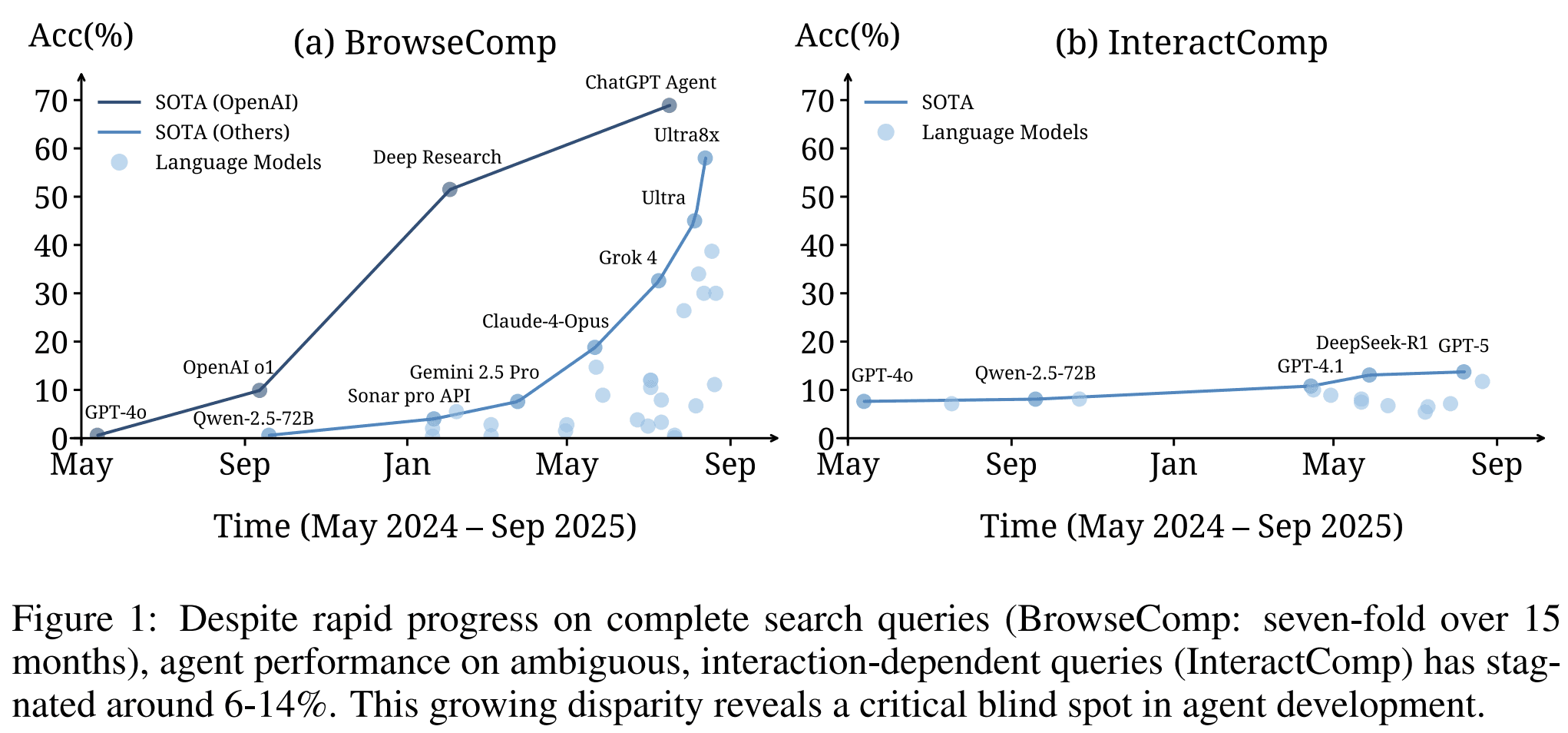
Progress in Search Has Not Become Progress in Interaction
The paper also includes a longitudinal comparison.
Over 15 months, performance on complete search queries, represented by BrowseComp, improved roughly seven-fold. During the same period, performance on InteractComp stayed around 6% to 14%.
This is a useful warning. Better web search, longer context windows, and stronger reasoning do not automatically produce better interaction behavior.
A search agent can become better at finding answers to complete questions while remaining poor at handling incomplete questions.
Why This Matters for Product Agents
Many product agents are search agents in disguise.
They may search documents, inspect websites, compare tools, analyze markets, or gather information from internal systems. But they still face the same input problem: the user often does not specify enough constraints.
For Atoms, this matters directly. Users may begin with requests such as:
- “Find competitors for my AI idea.”
- “Help me validate this market.”
- “Search for similar products.”
- “Tell me if this business idea is worth building.”
- “Find customers for this product.”
Each request can be ambiguous. “Competitor” may mean direct product competitor, workflow substitute, distribution competitor, or incumbent vendor. “Market” may mean user segment, budget category, regulatory environment, or go-to-market channel. “Similar product” may refer to interface, technical method, target customer, or pricing model.
A search agent that does not clarify will often optimize for the wrong interpretation.
InteractComp gives a concrete way to measure whether an agent has the right behavior:
- Does it detect ambiguity?
- Does it ask a useful clarification question?
- Does it use the answer to change its search path?
- Does it stop asking once the target is identifiable?
- Does it answer with calibrated confidence?
These are not interface details. They are core agent capabilities.
A Concrete Product Example
Suppose a user says:
“Find the best AI tools for sales teams.”
This query is underspecified. It could mean:
- tools for outbound prospecting;
- tools for CRM data entry;
- tools for call transcription;
- tools for sales coaching;
- tools for lead scoring;
- tools for proposal generation;
- tools for account research.
A weak agent searches immediately and returns a generic list.
A better agent asks:
“Are you looking for tools that help sales teams generate new leads?”
If the answer is “no,” the search space changes. The question was useful because the answer changes the next action.
This is the same principle tested by InteractComp. The agent must learn that search should sometimes follow clarification, not replace it.
What InteractComp Does Not Claim
InteractComp is a benchmark, not a training method.
It does not claim that forced interaction is the final product behavior. It also does not claim that more questions are always better. In fact, the paper shows that high interaction rates do not necessarily produce high accuracy. GPT-4o-mini asks questions frequently but still performs poorly.
The benchmark separates two abilities:
- willingness to interact;
- ability to ask useful questions.
Both are required. An agent that never asks will fail. An agent that asks irrelevant questions will also fail.
The practical target is not maximum interaction. It is necessary interaction.
From Benchmark to System Design
InteractComp suggests several design principles for user-facing search agents.
1. Ambiguity detection should be evaluated directly
It is not enough to test whether an agent can answer complete questions. Products should test whether the agent notices incomplete ones.
2. Search should not always be the first action
If the query has multiple plausible interpretations, searching immediately can reinforce the wrong one. A clarification question may be the cheaper and more accurate first step.
3. Interaction quality matters more than interaction count
The benchmark shows that high interaction frequency alone does not guarantee better results. The agent must ask questions that reduce the candidate set.
4. Confidence calibration is part of search quality
A search agent should know when its answer depends on an assumption. If the query is ambiguous, high confidence can be a failure mode.
5. Training needs clean signals for clarification
Search tasks are useful because the final answer is verifiable. This makes InteractComp a promising setting for training agents to ask better questions, not just evaluating them.
Conclusion
InteractComp identifies a clear weakness in current search agents: they often answer ambiguous queries instead of resolving them.
The benchmark is carefully constructed. Each task has a verifiable answer, but the initial query is missing distinctive context. The only reliable path is to ask. Across 17 models, current agents largely fail to do this. They can reason with complete context, but they do not reliably seek that context on their own.
For product agents, this is a central lesson. Users do not always know how to write complete specifications. A useful agent must not treat every query as ready for execution. It must know when the problem is underspecified, ask for the missing constraint, and then proceed.
Search is not only about finding information. It is also about knowing which information is missing.
