
Based on the paper: “InfoPO: Information-Driven Policy Optimization for User-Centric Agents” by Fanqi Kong, Jiayi Zhang, Mingyi Deng, Chenglin Wu, Yuyu Luo, and Bang Liu.
TL;DR
Real user requests are often incomplete. A user may say “book me a flight next week” without giving a city, date, budget, airline preference, or flexibility. A useful agent must know when to act and when to ask.
InfoPO proposes a training method for user-centric agents that rewards interaction turns based on how much useful information they obtain. Instead of only rewarding final task success, InfoPO gives turn-level credit when user feedback changes the agent’s next decision. This helps agents learn to clarify intent early, avoid premature execution, and complete tasks more reliably.
Across intent clarification, collaborative coding, and tool-based decision tasks, InfoPO improves over prompting and multi-turn reinforcement learning baselines. The central lesson is simple: for user-facing agents, asking the right question is not a side behavior. It is part of the task.
The Problem: Most User Requests Are Underspecified
A large part of agent failure comes from missing information.
When a user asks an agent to “find the best option,” “fix this issue,” or “help me plan this,” the instruction is rarely complete. The user often knows parts of the goal but leaves out key constraints. The agent has two choices:
- Guess and execute too early.
- Ask for more information before committing.
The first option often looks efficient but fails. The second option can solve the task, but only if the agent asks useful questions rather than adding unnecessary conversation.
This is the core setting of InfoPO: user-centric agents operating under partial information. The agent must reduce uncertainty about the user’s intent while still moving the task toward completion.
This is hard to train with standard reinforcement learning. In many multi-turn tasks, the reward arrives only at the end. If the task fails, the training signal often treats the whole trajectory as bad. That creates a credit assignment problem: the agent may have asked the right clarification question but failed later during execution. Standard trajectory-level rewards cannot easily separate these two cases.
The paper calls this kind of case an “honorable failure”: the agent made useful progress in understanding the user, but the final outcome was still unsuccessful. A training method that only sees terminal success may fail to reward that progress.
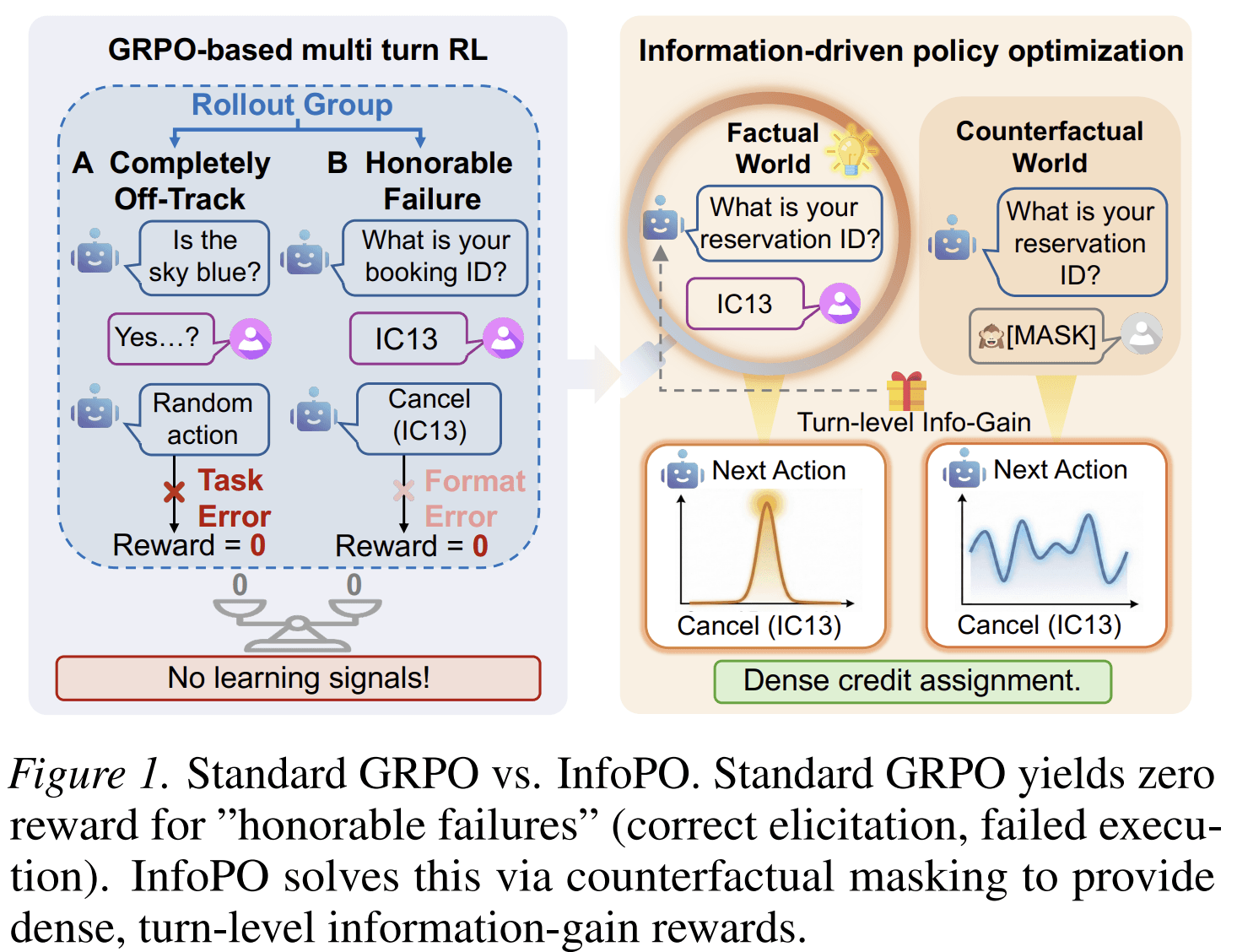
The Main Idea
InfoPO stands for Information-Driven Policy Optimization.
The method treats interaction as a process of uncertainty reduction. A turn is useful if the feedback from that turn changes what the agent would do next.
That definition is important. InfoPO does not reward questions just because they are questions. It rewards a turn when the user’s response provides information that measurably affects the agent’s next action.
In plain terms:
If the user’s answer changes the agent’s next decision, then the previous turn obtained useful information.
This gives the model a dense, turn-level learning signal without requiring a manually designed process reward model.
How InfoPO Measures Useful Information
InfoPO uses a counterfactual comparison.
For each interaction turn, the agent takes an action and receives feedback from the user or environment. The method then compares two versions of the history:
- Factual history: the actual transcript, including the feedback.
- Counterfactual history: the same transcript, but with the feedback replaced by a placeholder such as “No information found.”
Then InfoPO asks: under each history, how likely is the agent to produce the same next action?
If the actual feedback makes the next action much more likely than the masked version, the feedback contained useful information. The turn that produced that feedback receives a higher information-gain reward.
Formally, the paper defines a turn-level information reward as the average shift in log probability assigned to the next action tokens under the factual versus masked-feedback histories.
The practical effect is straightforward: InfoPO rewards turns that cause meaningful downstream changes in behavior.
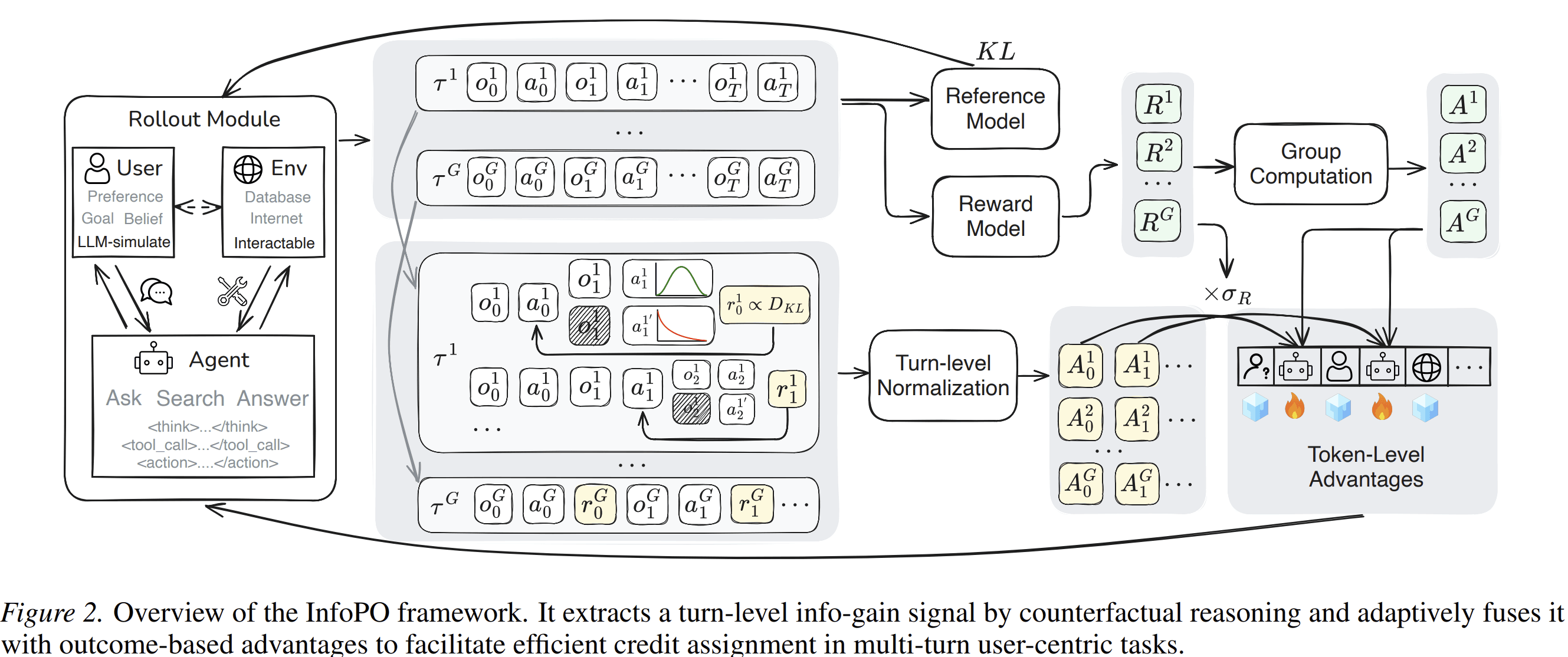
Why This Is Better Than Only Using Final Rewards
Final task rewards are necessary, but they are often too sparse.
Consider two failed trajectories:
- The agent asks the right clarification questions, understands the user, but makes a tool-use error at the end.
- The agent never clarifies the user’s intent and guesses incorrectly.
Both may receive the same terminal reward: failure. But they are not equally useful for learning.
InfoPO separates these cases by adding a second signal: information gain. This signal tells the model which turns helped reduce uncertainty, even when the final result was imperfect.
The method then combines this information-gain signal with the external task reward. It does not replace the task objective. This matters because information seeking alone can become unproductive. An agent should not ask questions forever. It should ask enough to act correctly.
InfoPO handles this through variance-gated fusion.
When outcome rewards within a rollout group are not informative — for example, when all sampled trajectories fail and receive similar rewards — InfoPO increases the weight of the information-gain signal. This gives the model something useful to learn from.
When outcome rewards become more discriminative, the method shifts weight back toward the task reward. This keeps the policy grounded in completion rather than conversation length.
The result is a training objective with two pressures:
- Ask when information is needed.
- Act when the task is sufficiently specified.
What the Agent Learns
One of the strongest findings in the paper is behavioral.
InfoPO-trained agents tend to develop a “clarify-then-act” pattern. In early turns, they ask questions that reduce uncertainty. After key constraints are resolved, they move into execution.
This is different from simply making agents more verbose. The paper analyzes interaction turns and response lengths during training. In UserGym and ColBench, InfoPO initially increases the number of turns to gather information, while reducing response length. Later, as the model learns better policies, interaction becomes more concise.
That distinction is important. The goal is not longer conversations. The goal is better-timed information gathering.
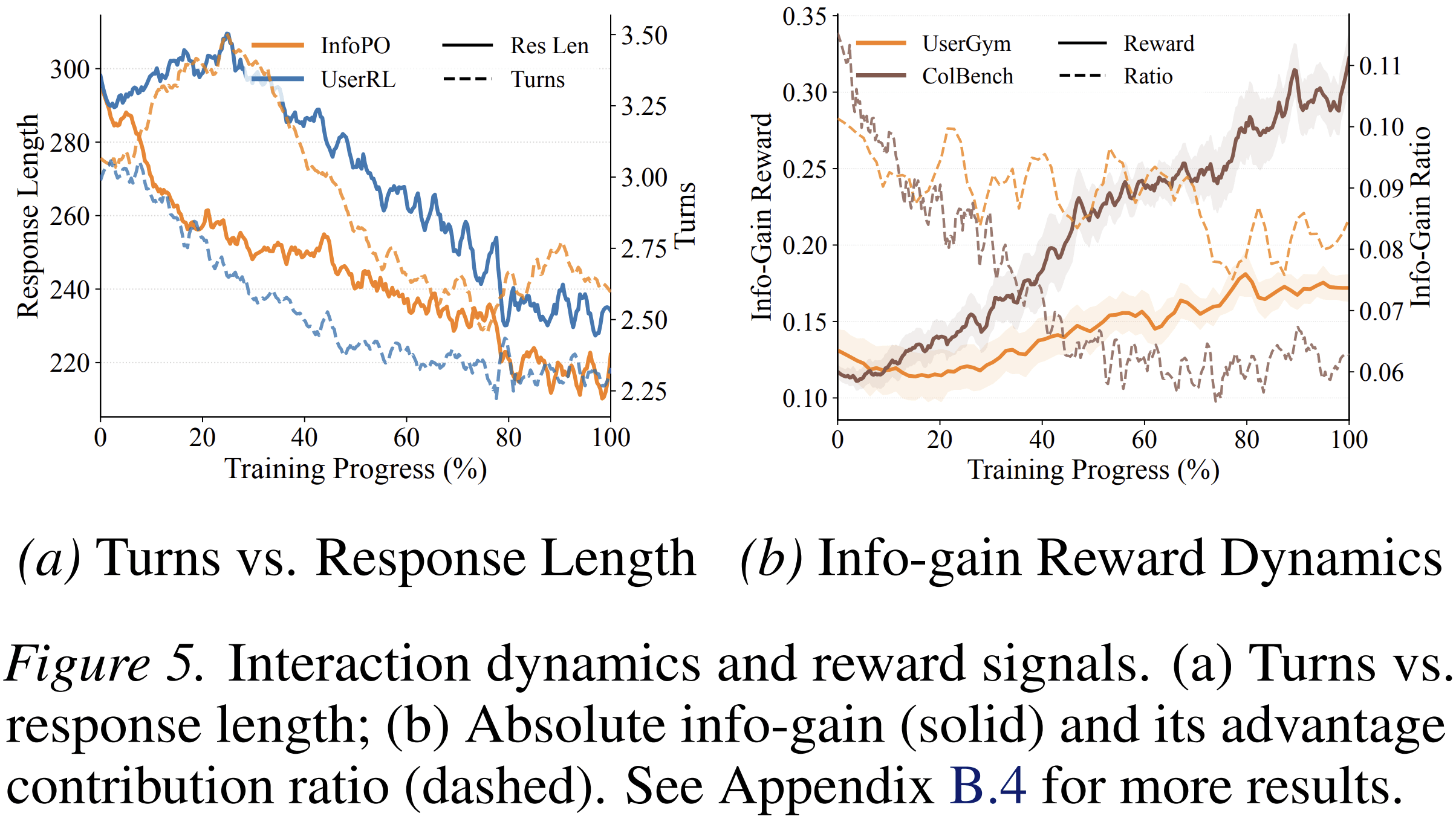
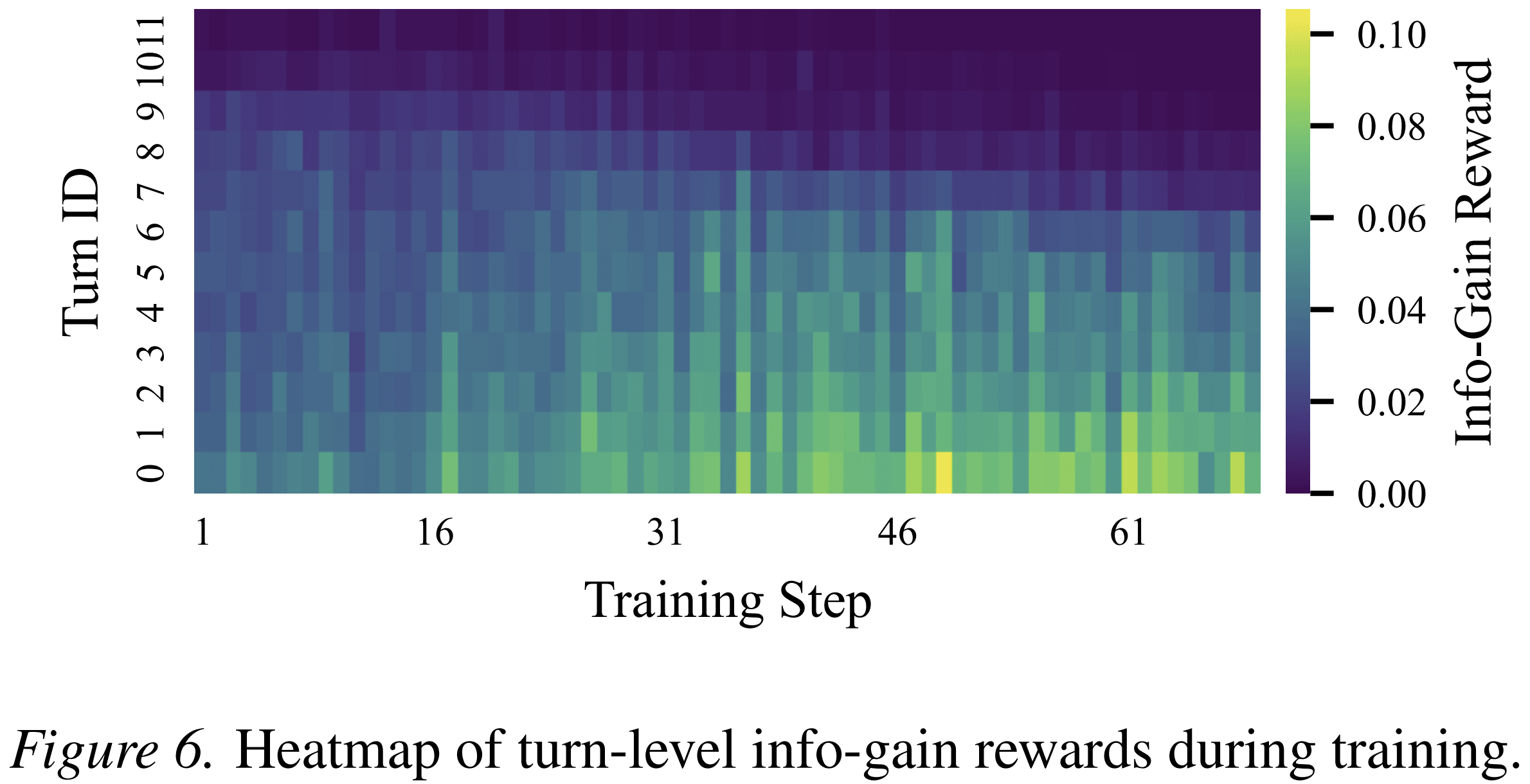
The paper also shows that information-gain rewards become concentrated in the early turns over training. This suggests that the model learns to resolve ambiguity before making downstream commitments.
Experimental Results
The paper evaluates InfoPO on three types of interactive tasks:
-
UserGym
A suite of user-centric environments covering travel planning, persuasion, intent inference, search, and related tasks. -
ColBench
A collaborative coding benchmark where the agent must clarify requirements and produce Python code through interaction. -
τ²-Bench
A long-horizon environment involving tool-based decision making across telecom, retail, and airline domains.
InfoPO is tested against prompting methods such as ReAct and Reflexion, as well as reinforcement learning baselines including UserRL, RAGEN, and Search-R1.
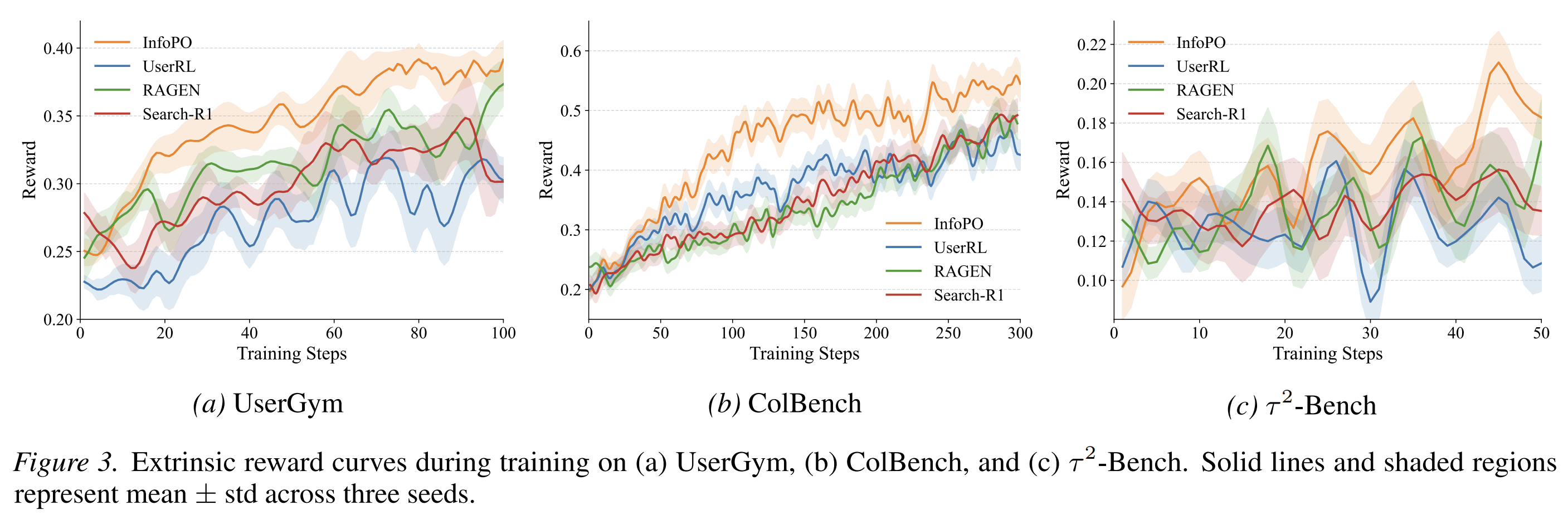
On Qwen2.5-7B-Instruct, InfoPO achieves the best overall average among the open-source RL methods reported in the paper. It improves performance in most UserGym sub-environments and shows clear gains on ColBench. On Qwen3-4B, InfoPO also produces the strongest average result among the compared open-source methods.
The paper reports that InfoPO exceeds GRPO-based methods by roughly 14% to 16% across the evaluated settings.
The authors also analyze why the method helps. In the early phase of training, many rollout groups have zero outcome variance. In other words, all sampled trajectories receive similar final rewards, often because they all fail. Standard group-relative training has little useful signal in this case. InfoPO still provides a turn-level signal through information gain, which helps optimization start earlier and remain more stable.
Why This Matters for Atoms
For Atoms, the user interface is not just a chat box. It is a decision process.
A good agent must decide:
- whether the user has provided enough information;
- which missing constraint matters most;
- when to ask a clarification question;
- when to use a tool;
- when to stop asking and execute.
InfoPO gives a principled way to train this behavior. It makes useful interaction measurable.
For Atoms, this is directly relevant. Users often begin with incomplete business ideas, vague product goals, or loosely specified execution needs. A system that immediately generates a plan may look fast, but it can easily optimize for the wrong target. A better system should identify what is missing, ask for the highest-value clarification, and then proceed.
InfoPO points to a practical design principle:
The agent should not maximize conversation. It should maximize task-relevant information.
That distinction is central to building user-facing agents that feel competent rather than talkative.
A Concrete Example
Suppose a user says:
“Help me launch an AI tool for sales teams.”
A weak agent may immediately produce a generic launch plan.
A better agent should notice missing constraints:
- Is the target customer startup sales teams or enterprise sales teams?
- Is the product a CRM assistant, outbound automation tool, call analysis tool, or sales coaching tool?
- Is the goal validation, landing page copy, competitive research, or go-to-market execution?
- What region, budget, and timeline matter?
InfoPO-style training would reward the agent when its questions produce answers that change its next decision. If the answer reveals that the user is targeting small B2B SaaS teams rather than enterprise sales organizations, the next action should change. That change is evidence that the question mattered.
This is the kind of interaction policy product agents need.
What InfoPO Does Not Claim
It is also useful to state the boundary clearly.
InfoPO is not a new user interface. It is not a prompt template. It is not a replacement for outcome rewards. It is a training method for multi-turn agents.
The method depends on being able to compare the model’s next-action probabilities under factual and masked histories. It also introduces additional computation through counterfactual forward passes, although the paper reports that this remains practical, with average wall-clock cost below 2× in their runs.
The important contribution is not that agents should ask more questions. The contribution is a way to train agents to value information that changes future decisions.
From Paper to System Design
The paper suggests several design directions for user-facing agent systems:
-
Treat clarification as part of task execution
Asking the right question should be trained and evaluated, not treated as a conversational accessory. -
Use turn-level signals where terminal rewards are too sparse
Multi-turn tasks often fail late. A useful training signal should still identify productive intermediate behavior. -
Avoid rewarding interaction length directly
The goal is not longer dialogue. The goal is information that changes decisions. -
Keep information seeking tied to final outcomes
InfoPO’s fusion with task reward prevents the agent from optimizing curiosity without completion. -
Evaluate behavior, not just final answers
For real products, the path matters. A user-facing agent should be judged by how it handles ambiguity, not only by whether it eventually returns an answer.
Conclusion
InfoPO addresses a basic but undertrained skill in agent systems: knowing what information is missing and learning how to obtain it.
The method gives agents turn-level credit when user feedback changes their next decision, then combines that signal with task success. This helps agents learn a more reliable interaction pattern: clarify early, execute once the goal is specified, and avoid unnecessary conversation.
For product agents, this is a practical step toward more dependable collaboration. Users rarely arrive with complete instructions. A useful agent must bridge the gap between vague intent and executable action.
InfoPO offers a rigorous way to train that bridge.
