
Based on the paper: “AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines” by Yifan Wu, Yiran Peng, Yiyu Chen, Jianhao Ruan, Zijie Zhuang, Cheng Yang, Jiayi Zhang, Man Chen, Yenchi Tseng, Zhaoyang Yu, Liang Chen, Yuyao Zhai, Bang Liu, Chenglin Wu, and Yuyu Luo.
TL;DR
Training web GUI agents requires interaction trajectories: the agent sees a webpage, takes an action, observes the result, and continues until the task is complete. The problem is that reliable trajectories are expensive to collect from real websites and difficult to verify.
AutoWebWorld addresses this by generating synthetic web environments whose state transitions are explicitly defined by finite state machines. Instead of treating the website as a black box, AutoWebWorld defines the internal states, valid actions, transition rules, and goal states before generating the website. This makes correctness programmatically verifiable.
The result is a pipeline that generates runnable websites, searches their state graphs for valid task trajectories, replays those trajectories in the browser, and filters out execution failures. The paper reports 29 synthetic web environments, 11,663 verified trajectories, and an average cost of $0.04 per trajectory. Training on this data improves real-world web navigation and GUI grounding performance.
The main contribution is not simply synthetic data. It is synthetic data with intrinsic verification.
The Problem: Web Agent Data Is Hard to Verify
A web GUI agent must operate through an interface designed for humans. It clicks buttons, fills forms, changes filters, opens pages, and checks results. To train such agents, researchers need trajectories that show correct multi-step behavior.
The obvious solution is to collect data from real websites. But real websites have a structural problem: their internal state is hidden.
After an agent clicks “Add to cart,” the webpage may visually update. But the screenshot alone does not fully reveal whether the internal cart state is correct. The item, quantity, price, discount, session state, or checkout eligibility may have changed in ways that are not directly observable.
This creates a verifier bottleneck. Existing pipelines often rely on human annotators, LLM judges, or post-hoc scripts to decide whether each step was correct. These verifiers are costly and inconsistent. They also evaluate behavior from surface observations, not from the true environment state.
AutoWebWorld starts from a different premise:
If the goal is to train agents on correct web interactions, the environment should expose the rules that define correctness.
That means the website should not be treated as an opaque artifact. It should be generated from a formal state-transition model.
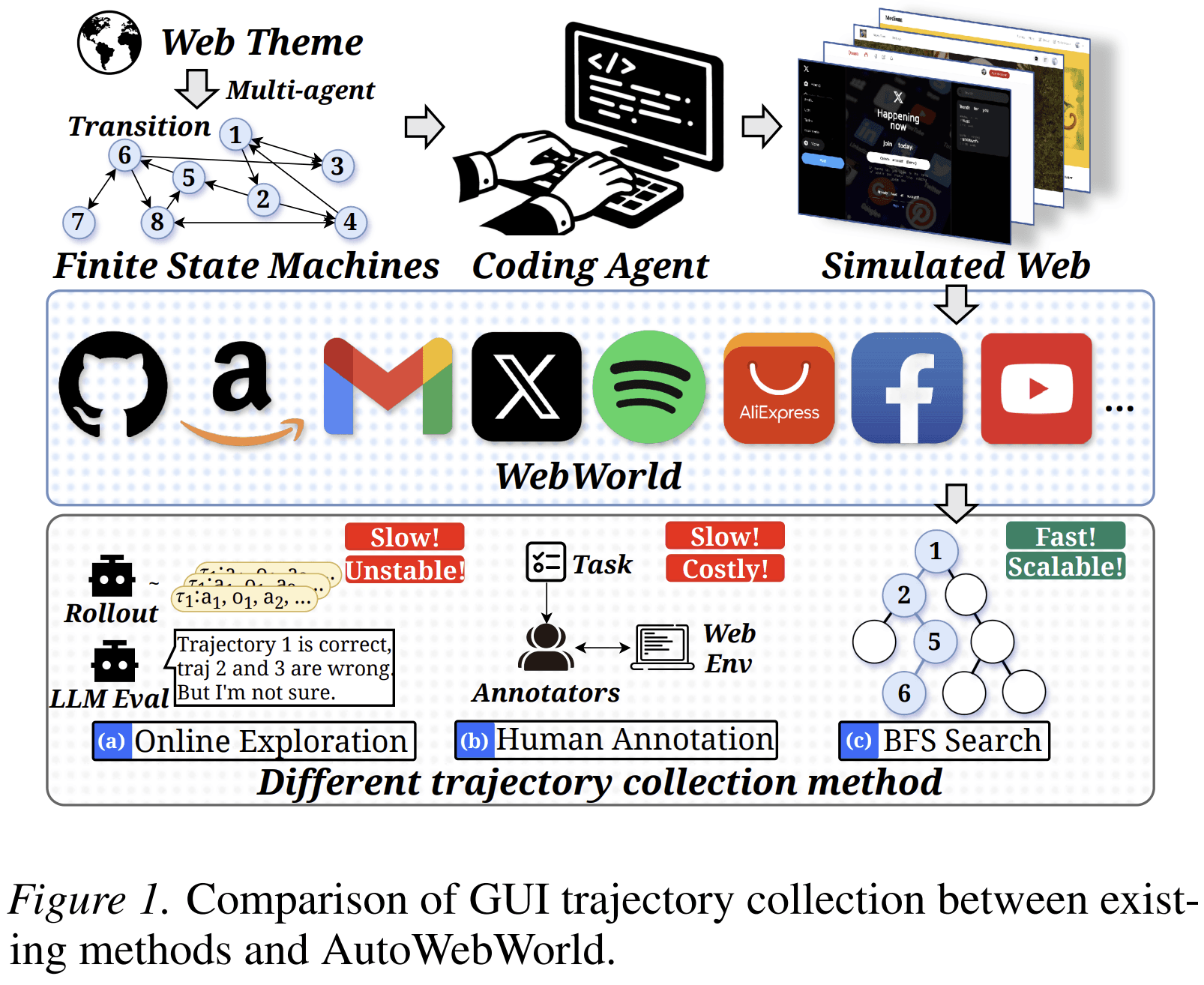
The Main Idea
AutoWebWorld builds web environments from finite state machines.
A finite state machine defines:
- a set of states;
- a set of actions;
- transition rules from one state to another;
- preconditions that determine whether an action is valid;
- terminal states that define task success.
In AutoWebWorld, each website is represented as an internal state:
$$ s = (p, \sigma) $$
where p is the current page and σ is a structured page signature. The signature captures task-relevant variables such as query text, selected filters, form values, pagination, cart contents, or selected items.
The transition function is deterministic:
$$ s_{t+1} = \mathcal{T}(s_t, a_t) $$
Given the current state and an action, the next state is uniquely determined. This is the key design choice. Once transitions are explicit, the system can verify whether an action is valid and whether a trajectory reaches a goal state without asking a human or an LLM judge.
The AutoWebWorld Pipeline
AutoWebWorld has four main stages.
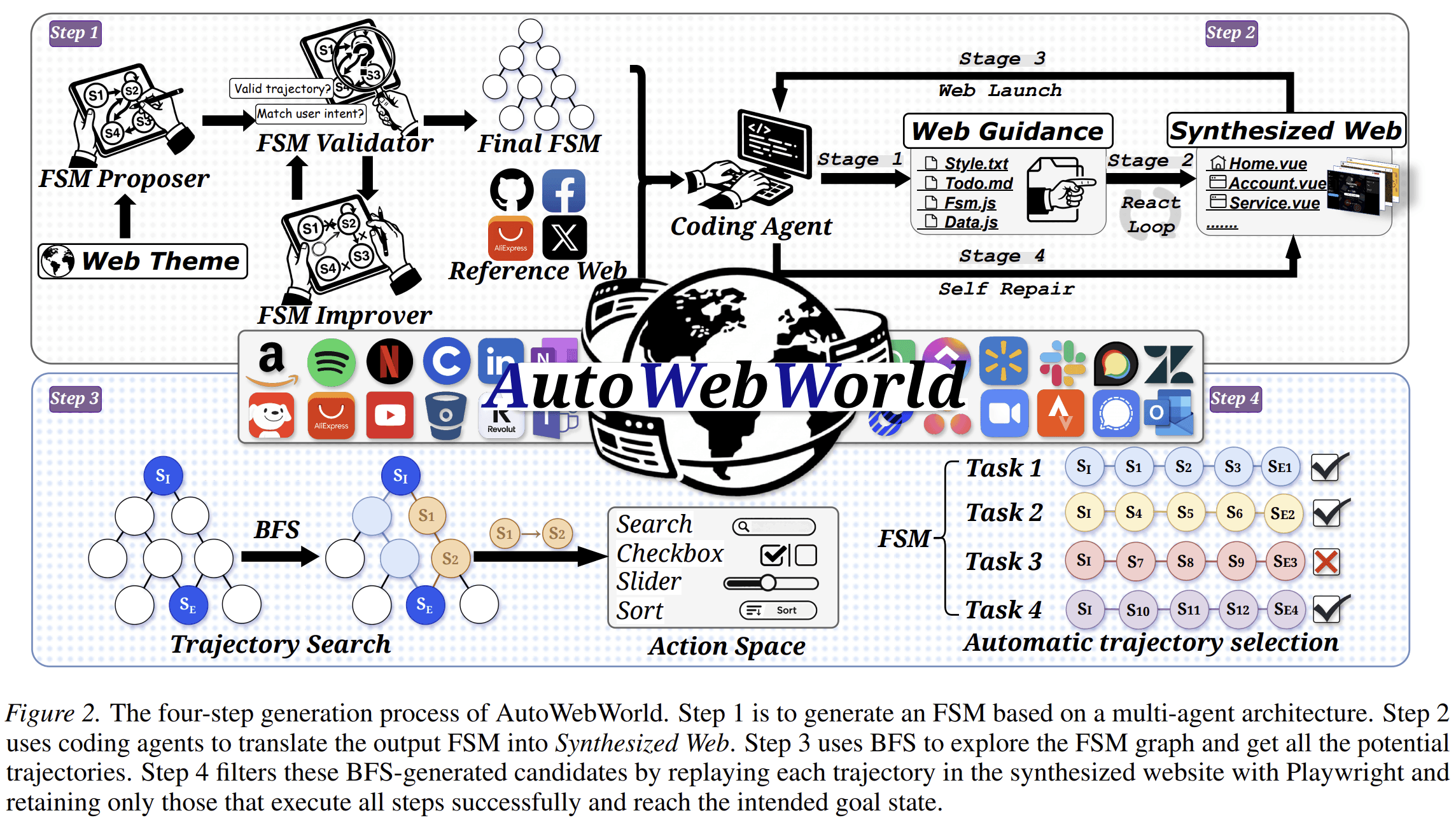
1. Generate a Finite State Machine
The pipeline begins with a web theme, such as a GitHub-like site, a Quora-like site, or another interactive web domain. A multi-agent generation process produces an FSM specification. The FSM includes pages, state signatures, actions, preconditions, effects, navigation rules, and terminal states.
A validator checks whether the FSM is valid. For example, it verifies that terminal states are reachable, actions have well-defined preconditions, and transitions are deterministic. If the FSM fails validation, an improver revises it. This validate-and-revise loop continues until the FSM passes.
2. Generate a Runnable Website
Once the FSM is accepted, coding agents translate it into a working front-end website. The paper describes a four-stage website generation process:
- generate project guidelines and scaffolding;
- synthesize web pages as Vue components;
- build and run the project;
- repair build failures through an automated loop.
The generated website is not just a visual mockup. Its interactive behavior is intended to follow the FSM semantics.
3. Search the FSM for Valid Trajectories
Because the FSM defines all valid transitions, AutoWebWorld can search the state graph directly. The paper uses breadth-first search to enumerate goal-reaching paths.
This matters because the search happens over the known internal state graph, not over screenshots. The system can expand only actions whose preconditions are satisfied and can stop when a terminal goal state is reached.
4. Replay and Filter in the Browser
FSM-level correctness is not enough. The generated website may still have implementation mismatches. A selector may be missing, a button may not function, or a page may not render as expected.
To handle this, AutoWebWorld replays each candidate trajectory in the actual generated website using Playwright. A trajectory is retained only if every GUI operation executes successfully and the intended goal state is reached.
This final step connects symbolic correctness to browser-level execution.
Why Finite State Machines Matter Here
A finite state machine is useful because it gives the environment a precise operational structure.
For web agents, this structure solves three problems.
First, it makes state explicit. The system does not need to infer whether the cart, filter, or form state is correct from the screenshot alone.
Second, it makes action validity checkable. An action can be allowed only when its preconditions are satisfied.
Third, it makes task success decidable. A trajectory succeeds if it reaches a goal state in the FSM graph and executes correctly in the generated website.
This is different from generating arbitrary synthetic webpages. Without explicit state transitions, synthetic websites may look realistic but remain hard to verify. AutoWebWorld’s contribution is that each website is paired with a formal transition model.
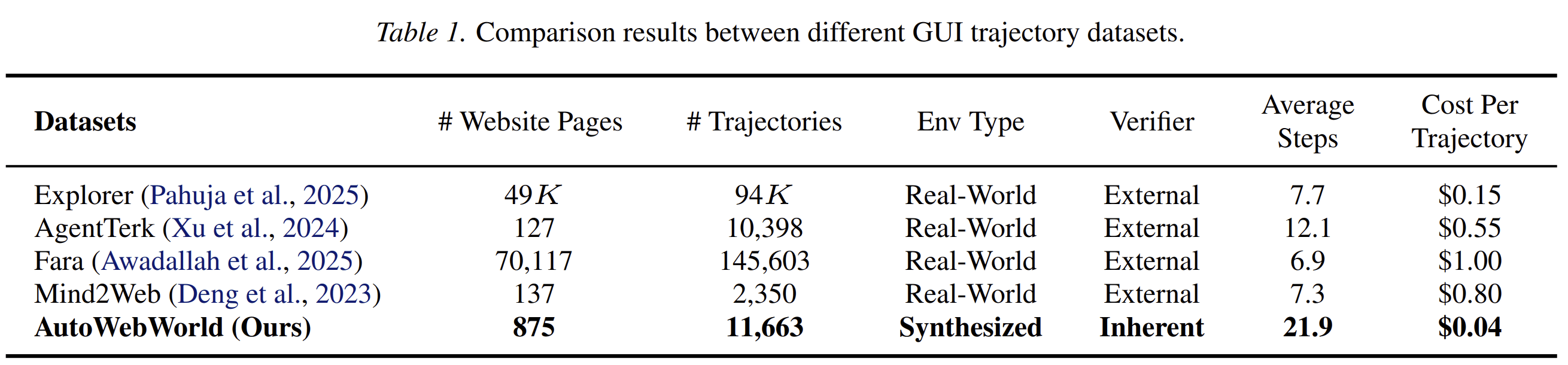
Dataset Scale and Cost
The paper reports:
- 29 generated web environments;
- 875 website pages;
- 11,663 verified trajectories;
- average trajectory length of 21.9 steps;
- average cost of $0.04 per trajectory.
The comparison with existing GUI trajectory datasets is important. Real-world datasets often depend on external verification and have higher per-trajectory costs. AutoWebWorld uses intrinsic verification and reports lower cost per trajectory than several real-world collection pipelines.
The longer average trajectory length is also relevant. Web agents often fail in long-horizon tasks because errors compound. A dataset with longer verified trajectories can train agents on planning, state tracking, and recovery across multiple steps.
Experimental Results
The paper evaluates whether AutoWebWorld data transfers to real-world web tasks.
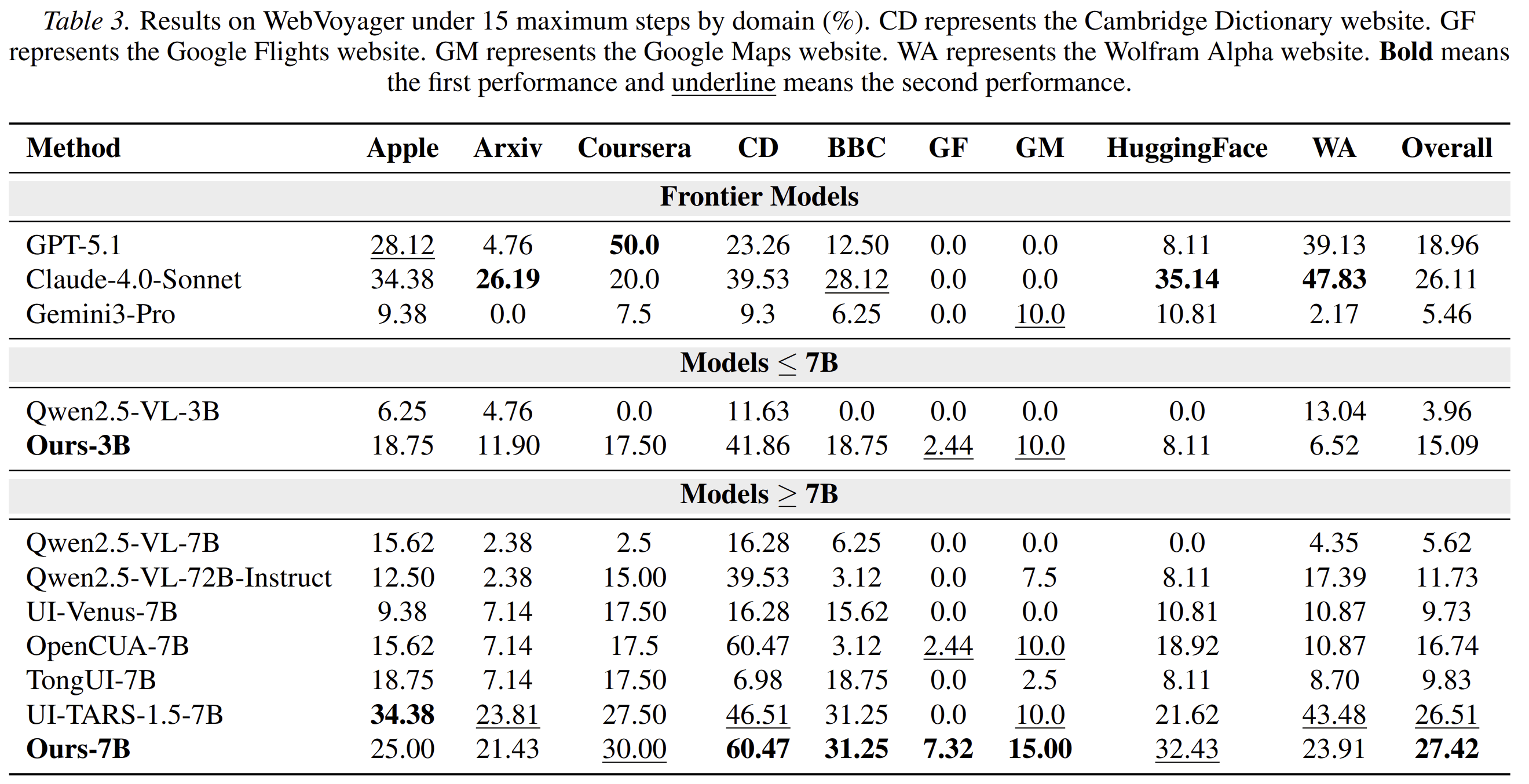
The main navigation benchmark is WebVoyager. The authors train agents using about 16K synthesized training steps and evaluate under a 15-step limit.
The strongest reported AutoWebWorld-trained 7B agent reaches 27.42% overall success on WebVoyager. This outperforms the open-source baselines reported in the paper under the same setting, including UI-TARS-1.5-7B at 26.51% and Qwen2.5-VL-7B at 5.62%.
The 3B model also improves substantially, reaching 15.09% overall. This is notable because the improvement comes from a relatively small amount of verified synthetic data.
AutoWebWorld also improves GUI grounding. On ScreenSpot-V2 and ScreenSpot-Pro, the paper reports gains for both 3B and 7B models after training with AutoWebWorld-derived grounding data.
This matters because navigation and grounding are linked. A web agent cannot reliably complete a task if it cannot identify where to click or type. The paper’s grounding results suggest that the generated trajectories provide useful supervision not only for high-level navigation but also for lower-level UI localization.
Scaling Behavior
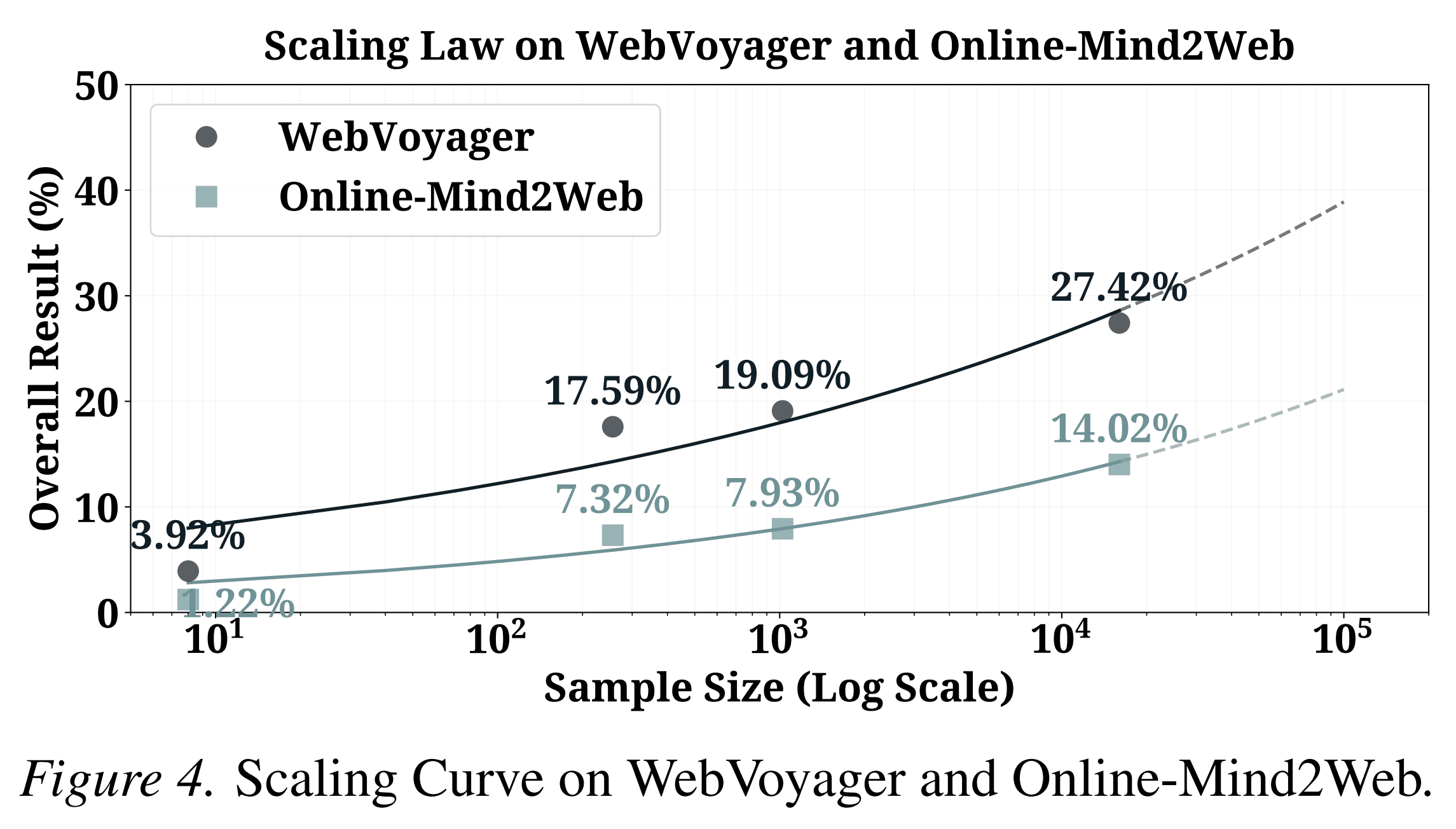
One of the paper’s central empirical findings is that more AutoWebWorld data improves real-world performance.
The authors train with increasing amounts of synthesized data: 8, 256, 1,024, and 16,253 samples. Performance on WebVoyager increases from 3.92% to 27.42%. Performance on Online-Mind2Web increases from 1.22% to 14.02%.
This result is important because it supports a practical claim: verified synthetic data can scale.
The paper does not argue that synthetic websites replace real websites. Instead, it shows that carefully verified synthetic environments can produce training signals that generalize to real web navigation benchmarks.
The Role of Grounding Data
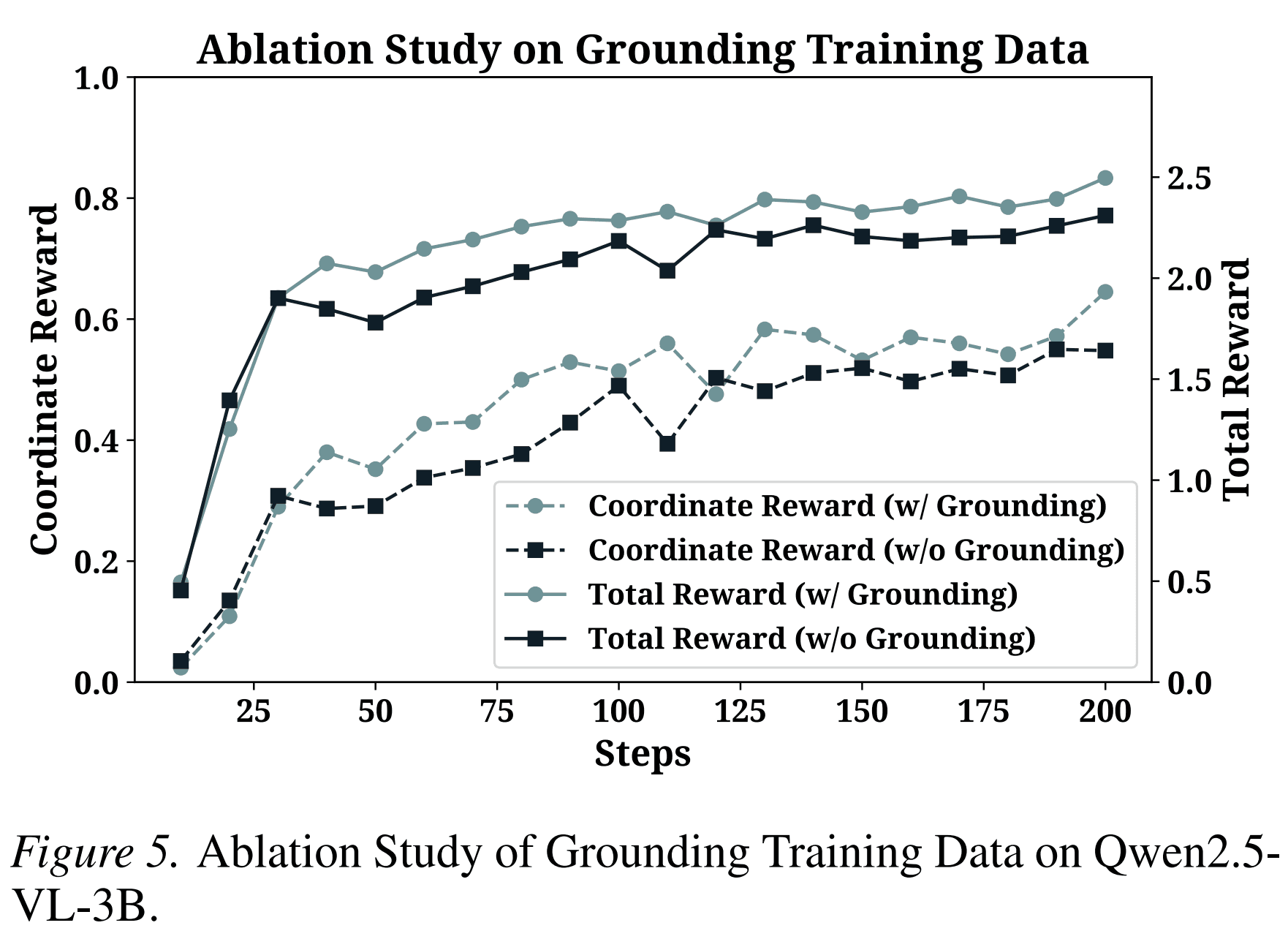
The paper also studies the effect of grounding supervision during training.
Without grounding data, training may appear easier at the beginning because harder grounding examples are removed. But this advantage disappears quickly. With grounding data, coordinate rewards improve more steadily and reach a higher level.
This supports a straightforward conclusion: web agents need both decision-making trajectories and precise action grounding. A correct plan is not enough if the agent cannot execute the click or type operation at the right location.
Why This Matters for Product Agents
Product-facing agents increasingly need to operate across websites and software interfaces. They may need to research competitors, fill forms, compare products, update dashboards, manage campaigns, or complete multi-step workflows.
For these tasks, training data quality matters more than surface diversity. A trajectory is useful only if the system knows whether each step is valid.
AutoWebWorld suggests a product-relevant principle:
To train reliable interface agents, build environments where correctness is part of the environment, not an external guess.
This principle is directly relevant to Atoms. Many user tasks in Atoms require an agent to move from an abstract goal to concrete execution. That may involve generating assets, checking web pages, collecting structured information, or coordinating tools. If the agent is trained only on noisy or weakly verified trajectories, it may learn plausible behavior without dependable execution.
AutoWebWorld offers a way to create controlled training environments for such behavior. Instead of waiting for expensive real-world demonstrations, we can define task logic, generate interactive environments, verify trajectories automatically, and train agents on reproducible examples.
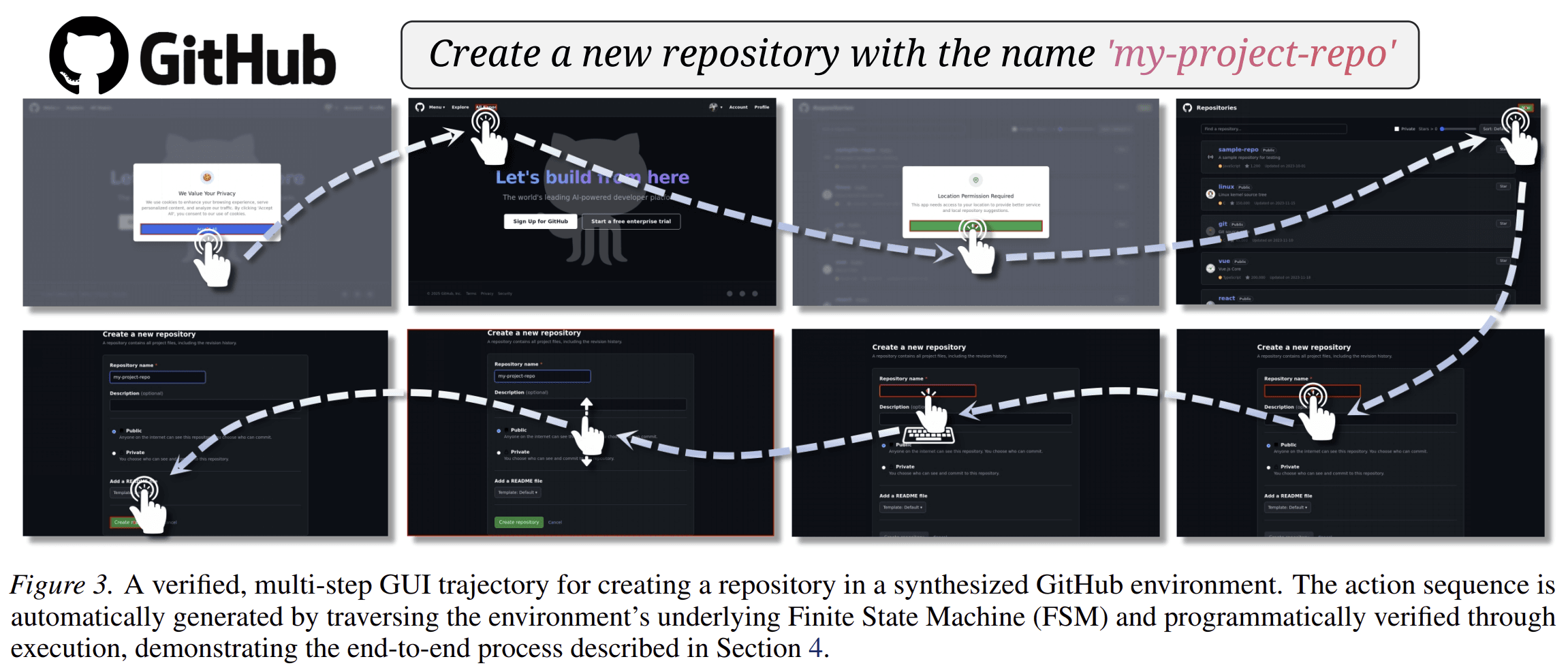
A Concrete Example
Consider a task:
“Create a new repository, add a README, and make it public.”
On a real website, collecting and verifying this trajectory is difficult. The UI may change. The session may expire. Permissions may differ. A human or model may need to judge whether the repository was actually created.
In an AutoWebWorld-style environment, the task can be represented by explicit states:
- homepage;
- login state;
- repository creation page;
- form fields filled;
- visibility setting selected;
- repository created;
- README added;
- terminal success state.
Each action has preconditions. For example, “click create repository” is valid only if required fields are filled. The terminal state is reached only when the repository exists with the required properties.
The resulting trajectory is not merely a recording. It is a verified path through a state graph, replayed in a browser and checked for execution correctness.
That is the difference between demonstration data and verifiable interaction data.
What AutoWebWorld Does Not Claim
The paper is careful about the scope of the contribution.
AutoWebWorld does not claim that synthetic websites perfectly match real websites. It also does not remove the need for real-world evaluation. The paper still evaluates on WebVoyager and Online-Mind2Web to test transfer.
The method also depends on the quality of the generated FSM and generated website. If the FSM is too simple, the environment may not train useful behavior. If the generated website does not match the FSM, trajectories must be filtered out. The paper addresses this through validation and replay-based filtering, but environment quality remains a central factor.
The strongest claim is narrower and more useful: if synthetic web environments are generated from explicit state machines and verified through execution, they can produce low-cost training data that improves real-world GUI agents.
From Paper to System Design
AutoWebWorld points to several system design lessons.
1. Verification should be built into the environment
External judges are useful, but they are not enough. For training data, correctness should be defined by the environment whenever possible.
2. Synthetic data needs structure
Synthetic webpages alone are insufficient. The important part is the state-transition model behind them.
3. Long-horizon behavior requires state tracking
Agents fail when they lose track of intermediate decisions. FSM-defined environments force trajectories to preserve state across many steps.
4. Browser execution should remain part of validation
A symbolic trajectory may be valid but still fail in the rendered interface. AutoWebWorld’s replay-and-filter stage is necessary because agents ultimately act in the GUI, not in the FSM.
5. Training data should connect planning and grounding
The results show that both trajectory-level navigation and coordinate-level grounding matter. A practical GUI agent needs both.
Conclusion
AutoWebWorld addresses a central bottleneck in web agent training: the lack of scalable, verifiable interaction data.
By generating web environments from finite state machines, it makes internal state, action validity, and task success explicit. By searching the FSM and replaying trajectories in the browser, it produces interaction data that is both symbolically valid and executable.
The reported results show that this data transfers to real-world web navigation and grounding benchmarks. More importantly, the paper provides a clear method for scaling GUI agent training without relying entirely on costly human demonstrations or inconsistent external verifiers.
For product agents, the lesson is direct. Reliable execution requires reliable training signals. AutoWebWorld shows how to build those signals into the environment itself.
